
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format.
While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal format to a text one whereas voice recognition just seeks to identify an individual user’s voice.
IBM has had a prominent role within speech recognition since its inception, releasing of “Shoebox” in 1962. This machine had the ability to recognize 16 different words, advancing the initial work from Bell Labs from the 1950s. However, IBM didn’t stop there, but continued to innovate over the years, launching VoiceType Simply Speaking application in 1996. This speech recognition software had a 42,000-word vocabulary, supported English and Spanish, and included a spelling dictionary of 100,000 words.
While speech technology had a limited vocabulary in the early days, it is utilized in a wide number of industries today, such as automotive, technology, and healthcare. Its adoption has only continued to accelerate in recent years due to advancements in deep learning and big data. Research (link resides outside ibm.com) shows that this market is expected to be worth USD 24.9 billion by 2025.
Explore the free O'Reilly ebook to learn how to get started with Presto, the open source SQL engine for data analytics.
Register for the guide on foundation models
Many speech recognition applications and devices are available, but the more advanced solutions use AI and machine learning . They integrate grammar, syntax, structure, and composition of audio and voice signals to understand and process human speech. Ideally, they learn as they go — evolving responses with each interaction.
The best kind of systems also allow organizations to customize and adapt the technology to their specific requirements — everything from language and nuances of speech to brand recognition. For example:
- Language weighting: Improve precision by weighting specific words that are spoken frequently (such as product names or industry jargon), beyond terms already in the base vocabulary.
- Speaker labeling: Output a transcription that cites or tags each speaker’s contributions to a multi-participant conversation.
- Acoustics training: Attend to the acoustical side of the business. Train the system to adapt to an acoustic environment (like the ambient noise in a call center) and speaker styles (like voice pitch, volume and pace).
- Profanity filtering: Use filters to identify certain words or phrases and sanitize speech output.
Meanwhile, speech recognition continues to advance. Companies, like IBM, are making inroads in several areas, the better to improve human and machine interaction.
The vagaries of human speech have made development challenging. It’s considered to be one of the most complex areas of computer science – involving linguistics, mathematics and statistics. Speech recognizers are made up of a few components, such as the speech input, feature extraction, feature vectors, a decoder, and a word output. The decoder leverages acoustic models, a pronunciation dictionary, and language models to determine the appropriate output.
Speech recognition technology is evaluated on its accuracy rate, i.e. word error rate (WER), and speed. A number of factors can impact word error rate, such as pronunciation, accent, pitch, volume, and background noise. Reaching human parity – meaning an error rate on par with that of two humans speaking – has long been the goal of speech recognition systems. Research from Lippmann (link resides outside ibm.com) estimates the word error rate to be around 4 percent, but it’s been difficult to replicate the results from this paper.
Various algorithms and computation techniques are used to recognize speech into text and improve the accuracy of transcription. Below are brief explanations of some of the most commonly used methods:
- Natural language processing (NLP): While NLP isn’t necessarily a specific algorithm used in speech recognition, it is the area of artificial intelligence which focuses on the interaction between humans and machines through language through speech and text. Many mobile devices incorporate speech recognition into their systems to conduct voice search—e.g. Siri—or provide more accessibility around texting.
- Hidden markov models (HMM): Hidden Markov Models build on the Markov chain model, which stipulates that the probability of a given state hinges on the current state, not its prior states. While a Markov chain model is useful for observable events, such as text inputs, hidden markov models allow us to incorporate hidden events, such as part-of-speech tags, into a probabilistic model. They are utilized as sequence models within speech recognition, assigning labels to each unit—i.e. words, syllables, sentences, etc.—in the sequence. These labels create a mapping with the provided input, allowing it to determine the most appropriate label sequence.
- N-grams: This is the simplest type of language model (LM), which assigns probabilities to sentences or phrases. An N-gram is sequence of N-words. For example, “order the pizza” is a trigram or 3-gram and “please order the pizza” is a 4-gram. Grammar and the probability of certain word sequences are used to improve recognition and accuracy.
- Neural networks: Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. Each node is made up of inputs, weights, a bias (or threshold) and an output. If that output value exceeds a given threshold, it “fires” or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent. While neural networks tend to be more accurate and can accept more data, this comes at a performance efficiency cost as they tend to be slower to train compared to traditional language models.
- Speaker Diarization (SD): Speaker diarization algorithms identify and segment speech by speaker identity. This helps programs better distinguish individuals in a conversation and is frequently applied at call centers distinguishing customers and sales agents.
A wide number of industries are utilizing different applications of speech technology today, helping businesses and consumers save time and even lives. Some examples include:
Automotive: Speech recognizers improves driver safety by enabling voice-activated navigation systems and search capabilities in car radios.
Technology: Virtual agents are increasingly becoming integrated within our daily lives, particularly on our mobile devices. We use voice commands to access them through our smartphones, such as through Google Assistant or Apple’s Siri, for tasks, such as voice search, or through our speakers, via Amazon’s Alexa or Microsoft’s Cortana, to play music. They’ll only continue to integrate into the everyday products that we use, fueling the “Internet of Things” movement.
Healthcare: Doctors and nurses leverage dictation applications to capture and log patient diagnoses and treatment notes.
Sales: Speech recognition technology has a couple of applications in sales. It can help a call center transcribe thousands of phone calls between customers and agents to identify common call patterns and issues. AI chatbots can also talk to people via a webpage, answering common queries and solving basic requests without needing to wait for a contact center agent to be available. It both instances speech recognition systems help reduce time to resolution for consumer issues.
Security: As technology integrates into our daily lives, security protocols are an increasing priority. Voice-based authentication adds a viable level of security.
Convert speech into text using AI-powered speech recognition and transcription.
Convert text into natural-sounding speech in a variety of languages and voices.
AI-powered hybrid cloud software.
Enable speech transcription in multiple languages for a variety of use cases, including but not limited to customer self-service, agent assistance and speech analytics.
Learn how to keep up, rethink how to use technologies like the cloud, AI and automation to accelerate innovation, and meet the evolving customer expectations.
IBM watsonx Assistant helps organizations provide better customer experiences with an AI chatbot that understands the language of the business, connects to existing customer care systems, and deploys anywhere with enterprise security and scalability. watsonx Assistant automates repetitive tasks and uses machine learning to resolve customer support issues quickly and efficiently.

Speech Recognition: Everything You Need to Know in 2024
We adhere to clear ethical standards and follow an objective methodology . The brands with links to their websites fund our research.
Speech recognition, also known as automatic speech recognition (ASR) , enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications , including customer service, healthcare, finance and sales.
In this comprehensive guide, we will explain speech recognition, exploring how it works, the algorithms involved, and the use cases of various industries.
If you require training data for your speech recognition system, here is a guide to finding the right speech data collection services.
What is speech recognition?
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text.
Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents, dialects, and speech patterns.
What are the features of speech recognition systems?
Speech recognition systems have several components that work together to understand and process human speech. Key features of effective speech recognition are:
- Audio preprocessing: After you have obtained the raw audio signal from an input device, you need to preprocess it to improve the quality of the speech input The main goal of audio preprocessing is to capture relevant speech data by removing any unwanted artifacts and reducing noise.
- Feature extraction: This stage converts the preprocessed audio signal into a more informative representation. This makes raw audio data more manageable for machine learning models in speech recognition systems.
- Language model weighting: Language weighting gives more weight to certain words and phrases, such as product references, in audio and voice signals. This makes those keywords more likely to be recognized in a subsequent speech by speech recognition systems.
- Acoustic modeling : It enables speech recognizers to capture and distinguish phonetic units within a speech signal. Acoustic models are trained on large datasets containing speech samples from a diverse set of speakers with different accents, speaking styles, and backgrounds.
- Speaker labeling: It enables speech recognition applications to determine the identities of multiple speakers in an audio recording. It assigns unique labels to each speaker in an audio recording, allowing the identification of which speaker was speaking at any given time.
- Profanity filtering: The process of removing offensive, inappropriate, or explicit words or phrases from audio data.
What are the different speech recognition algorithms?
Speech recognition uses various algorithms and computation techniques to convert spoken language into written language. The following are some of the most commonly used speech recognition methods:
- Hidden Markov Models (HMMs): Hidden Markov model is a statistical Markov model commonly used in traditional speech recognition systems. HMMs capture the relationship between the acoustic features and model the temporal dynamics of speech signals.
- Estimate the probability of word sequences in the recognized text
- Convert colloquial expressions and abbreviations in a spoken language into a standard written form
- Map phonetic units obtained from acoustic models to their corresponding words in the target language.
- Speaker Diarization (SD): Speaker diarization, or speaker labeling, is the process of identifying and attributing speech segments to their respective speakers (Figure 1). It allows for speaker-specific voice recognition and the identification of individuals in a conversation.
Figure 1: A flowchart illustrating the speaker diarization process

- Dynamic Time Warping (DTW): Speech recognition algorithms use Dynamic Time Warping (DTW) algorithm to find an optimal alignment between two sequences (Figure 2).
Figure 2: A speech recognizer using dynamic time warping to determine the optimal distance between elements

5. Deep neural networks: Neural networks process and transform input data by simulating the non-linear frequency perception of the human auditory system.
6. Connectionist Temporal Classification (CTC): It is a training objective introduced by Alex Graves in 2006. CTC is especially useful for sequence labeling tasks and end-to-end speech recognition systems. It allows the neural network to discover the relationship between input frames and align input frames with output labels.
Speech recognition vs voice recognition
Speech recognition is commonly confused with voice recognition, yet, they refer to distinct concepts. Speech recognition converts spoken words into written text, focusing on identifying the words and sentences spoken by a user, regardless of the speaker’s identity.
On the other hand, voice recognition is concerned with recognizing or verifying a speaker’s voice, aiming to determine the identity of an unknown speaker rather than focusing on understanding the content of the speech.
What are the challenges of speech recognition with solutions?
While speech recognition technology offers many benefits, it still faces a number of challenges that need to be addressed. Some of the main limitations of speech recognition include:
Acoustic Challenges:
- Assume a speech recognition model has been primarily trained on American English accents. If a speaker with a strong Scottish accent uses the system, they may encounter difficulties due to pronunciation differences. For example, the word “water” is pronounced differently in both accents. If the system is not familiar with this pronunciation, it may struggle to recognize the word “water.”
Solution: Addressing these challenges is crucial to enhancing speech recognition applications’ accuracy. To overcome pronunciation variations, it is essential to expand the training data to include samples from speakers with diverse accents. This approach helps the system recognize and understand a broader range of speech patterns.
- For instance, you can use data augmentation techniques to reduce the impact of noise on audio data. Data augmentation helps train speech recognition models with noisy data to improve model accuracy in real-world environments.
Figure 3: Examples of a target sentence (“The clown had a funny face”) in the background noise of babble, car and rain.

Linguistic Challenges:
- Out-of-vocabulary words: Since the speech recognizers model has not been trained on OOV words, they may incorrectly recognize them as different or fail to transcribe them when encountering them.
Figure 4: An example of detecting OOV word
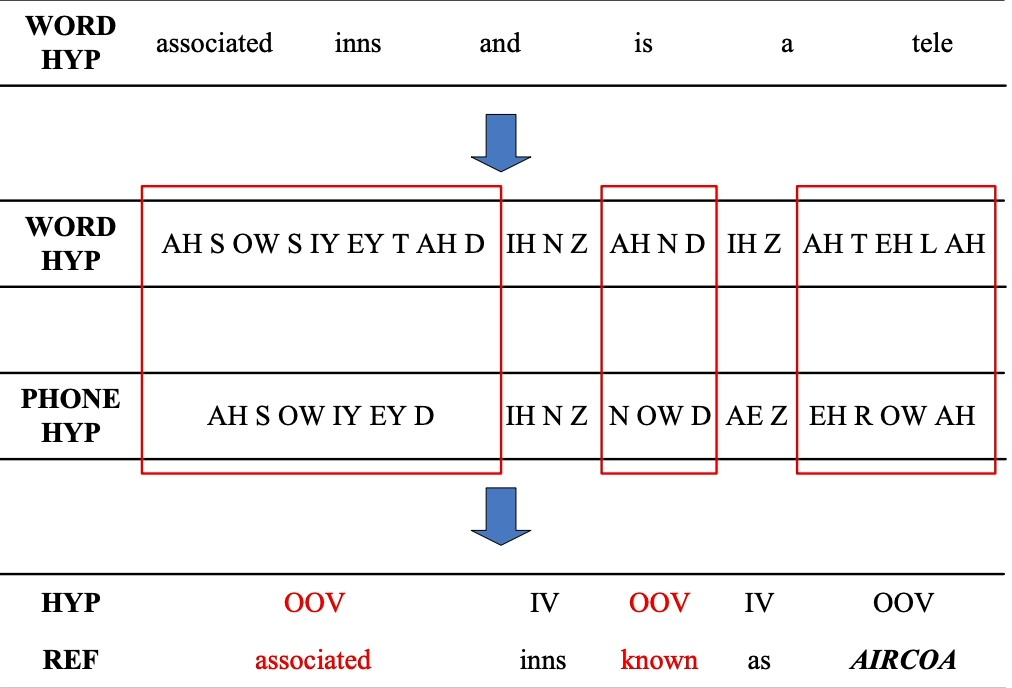
Solution: Word Error Rate (WER) is a common metric that is used to measure the accuracy of a speech recognition or machine translation system. The word error rate can be computed as:
Figure 5: Demonstrating how to calculate word error rate (WER)

- Homophones: Homophones are words that are pronounced identically but have different meanings, such as “to,” “too,” and “two”. Solution: Semantic analysis allows speech recognition programs to select the appropriate homophone based on its intended meaning in a given context. Addressing homophones improves the ability of the speech recognition process to understand and transcribe spoken words accurately.
Technical/System Challenges:
- Data privacy and security: Speech recognition systems involve processing and storing sensitive and personal information, such as financial information. An unauthorized party could use the captured information, leading to privacy breaches.
Solution: You can encrypt sensitive and personal audio information transmitted between the user’s device and the speech recognition software. Another technique for addressing data privacy and security in speech recognition systems is data masking. Data masking algorithms mask and replace sensitive speech data with structurally identical but acoustically different data.
Figure 6: An example of how data masking works

- Limited training data: Limited training data directly impacts the performance of speech recognition software. With insufficient training data, the speech recognition model may struggle to generalize different accents or recognize less common words.
Solution: To improve the quality and quantity of training data, you can expand the existing dataset using data augmentation and synthetic data generation technologies.
13 speech recognition use cases and applications
In this section, we will explain how speech recognition revolutionizes the communication landscape across industries and changes the way businesses interact with machines.
Customer Service and Support
- Interactive Voice Response (IVR) systems: Interactive voice response (IVR) is a technology that automates the process of routing callers to the appropriate department. It understands customer queries and routes calls to the relevant departments. This reduces the call volume for contact centers and minimizes wait times. IVR systems address simple customer questions without human intervention by employing pre-recorded messages or text-to-speech technology . Automatic Speech Recognition (ASR) allows IVR systems to comprehend and respond to customer inquiries and complaints in real time.
- Customer support automation and chatbots: According to a survey, 78% of consumers interacted with a chatbot in 2022, but 80% of respondents said using chatbots increased their frustration level.
- Sentiment analysis and call monitoring: Speech recognition technology converts spoken content from a call into text. After speech-to-text processing, natural language processing (NLP) techniques analyze the text and assign a sentiment score to the conversation, such as positive, negative, or neutral. By integrating speech recognition with sentiment analysis, organizations can address issues early on and gain valuable insights into customer preferences.
- Multilingual support: Speech recognition software can be trained in various languages to recognize and transcribe the language spoken by a user accurately. By integrating speech recognition technology into chatbots and Interactive Voice Response (IVR) systems, organizations can overcome language barriers and reach a global audience (Figure 7). Multilingual chatbots and IVR automatically detect the language spoken by a user and switch to the appropriate language model.
Figure 7: Showing how a multilingual chatbot recognizes words in another language
- Customer authentication with voice biometrics: Voice biometrics use speech recognition technologies to analyze a speaker’s voice and extract features such as accent and speed to verify their identity.
Sales and Marketing:
- Virtual sales assistants: Virtual sales assistants are AI-powered chatbots that assist customers with purchasing and communicate with them through voice interactions. Speech recognition allows virtual sales assistants to understand the intent behind spoken language and tailor their responses based on customer preferences.
- Transcription services : Speech recognition software records audio from sales calls and meetings and then converts the spoken words into written text using speech-to-text algorithms.
Automotive:
- Voice-activated controls: Voice-activated controls allow users to interact with devices and applications using voice commands. Drivers can operate features like climate control, phone calls, or navigation systems.
- Voice-assisted navigation: Voice-assisted navigation provides real-time voice-guided directions by utilizing the driver’s voice input for the destination. Drivers can request real-time traffic updates or search for nearby points of interest using voice commands without physical controls.
Healthcare:
- Recording the physician’s dictation
- Transcribing the audio recording into written text using speech recognition technology
- Editing the transcribed text for better accuracy and correcting errors as needed
- Formatting the document in accordance with legal and medical requirements.
- Virtual medical assistants: Virtual medical assistants (VMAs) use speech recognition, natural language processing, and machine learning algorithms to communicate with patients through voice or text. Speech recognition software allows VMAs to respond to voice commands, retrieve information from electronic health records (EHRs) and automate the medical transcription process.
- Electronic Health Records (EHR) integration: Healthcare professionals can use voice commands to navigate the EHR system , access patient data, and enter data into specific fields.
Technology:
- Virtual agents: Virtual agents utilize natural language processing (NLP) and speech recognition technologies to understand spoken language and convert it into text. Speech recognition enables virtual agents to process spoken language in real-time and respond promptly and accurately to user voice commands.
Further reading
- Top 5 Speech Recognition Data Collection Methods in 2023
- Top 11 Speech Recognition Applications in 2023
External Links
- 1. Databricks
- 2. PubMed Central
- 3. Qin, L. (2013). Learning Out-of-vocabulary Words in Automatic Speech Recognition . Carnegie Mellon University.
- 4. Wikipedia

Next to Read
Top 10 text to speech software analysis in 2024, top 5 speech recognition data collection methods in 2024, top 4 speech recognition challenges & solutions in 2024.
Your email address will not be published. All fields are required.
Related research

Why Should You Use Cloud Inference (Inference as a Service) in 2024?
How Does Speech Recognition Work? (9 Simple Questions Answered)
- by Team Experts
- July 2, 2023 July 3, 2023
Discover the Surprising Science Behind Speech Recognition – Learn How It Works in 9 Simple Questions!
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing , audio inputs, machine learning , and voice recognition . Speech recognition systems analyze speech patterns to identify phonemes , the basic units of sound in a language. Acoustic modeling is used to match the phonemes to words , and word prediction algorithms are used to determine the most likely words based on context analysis . Finally, the words are converted into text.
What is Natural Language Processing and How Does it Relate to Speech Recognition?
How do audio inputs enable speech recognition, what role does machine learning play in speech recognition, how does voice recognition work, what are the different types of speech patterns used for speech recognition, how is acoustic modeling used for accurate phoneme detection in speech recognition systems, what is word prediction and why is it important for effective speech recognition technology, how can context analysis improve accuracy of automatic speech recognition systems, common mistakes and misconceptions.
Natural language processing (NLP) is a branch of artificial intelligence that deals with the analysis and understanding of human language. It is used to enable machines to interpret and process natural language, such as speech, text, and other forms of communication . NLP is used in a variety of applications , including automated speech recognition , voice recognition technology , language models, text analysis , text-to-speech synthesis , natural language understanding , natural language generation, semantic analysis , syntactic analysis, pragmatic analysis, sentiment analysis, and speech-to-text conversion. NLP is closely related to speech recognition , as it is used to interpret and understand spoken language in order to convert it into text.
Audio inputs enable speech recognition by providing digital audio recordings of spoken words . These recordings are then analyzed to extract acoustic features of speech, such as pitch, frequency, and amplitude. Feature extraction techniques , such as spectral analysis of sound waves, are used to identify and classify phonemes . Natural language processing (NLP) and machine learning models are then used to interpret the audio recordings and recognize speech. Neural networks and deep learning architectures are used to further improve the accuracy of voice recognition . Finally, Automatic Speech Recognition (ASR) systems are used to convert the speech into text, and noise reduction techniques and voice biometrics are used to improve accuracy .
Machine learning plays a key role in speech recognition , as it is used to develop algorithms that can interpret and understand spoken language. Natural language processing , pattern recognition techniques , artificial intelligence , neural networks, acoustic modeling , language models, statistical methods , feature extraction , hidden Markov models (HMMs), deep learning architectures , voice recognition systems, speech synthesis , and automatic speech recognition (ASR) are all used to create machine learning models that can accurately interpret and understand spoken language. Natural language understanding is also used to further refine the accuracy of the machine learning models .
Voice recognition works by using machine learning algorithms to analyze the acoustic properties of a person’s voice. This includes using voice recognition software to identify phonemes , speaker identification, text normalization , language models, noise cancellation techniques , prosody analysis , contextual understanding , artificial neural networks, voice biometrics , speech synthesis , and deep learning . The data collected is then used to create a voice profile that can be used to identify the speaker .
The different types of speech patterns used for speech recognition include prosody , contextual speech recognition , speaker adaptation , language models, hidden Markov models (HMMs), neural networks, Gaussian mixture models (GMMs) , discrete wavelet transform (DWT), Mel-frequency cepstral coefficients (MFCCs), vector quantization (VQ), dynamic time warping (DTW), continuous density hidden Markov model (CDHMM), support vector machines (SVM), and deep learning .
Acoustic modeling is used for accurate phoneme detection in speech recognition systems by utilizing statistical models such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs). Feature extraction techniques such as Mel-frequency cepstral coefficients (MFCCs) are used to extract relevant features from the audio signal . Context-dependent models are also used to improve accuracy . Discriminative training techniques such as maximum likelihood estimation and the Viterbi algorithm are used to train the models. In recent years, neural networks and deep learning algorithms have been used to improve accuracy , as well as natural language processing techniques .
Word prediction is a feature of natural language processing and artificial intelligence that uses machine learning algorithms to predict the next word or phrase a user is likely to type or say. It is used in automated speech recognition systems to improve the accuracy of the system by reducing the amount of user effort and time spent typing or speaking words. Word prediction also enhances the user experience by providing faster response times and increased efficiency in data entry tasks. Additionally, it reduces errors due to incorrect spelling or grammar, and improves the understanding of natural language by machines. By using word prediction, speech recognition technology can be more effective , providing improved accuracy and enhanced ability for machines to interpret human speech.
Context analysis can improve the accuracy of automatic speech recognition systems by utilizing language models, acoustic models, statistical methods , and machine learning algorithms to analyze the semantic , syntactic, and pragmatic aspects of speech. This analysis can include word – level , sentence- level , and discourse-level context, as well as utterance understanding and ambiguity resolution. By taking into account the context of the speech, the accuracy of the automatic speech recognition system can be improved.
- Misconception : Speech recognition requires a person to speak in a robotic , monotone voice. Correct Viewpoint: Speech recognition technology is designed to recognize natural speech patterns and does not require users to speak in any particular way.
- Misconception : Speech recognition can understand all languages equally well. Correct Viewpoint: Different speech recognition systems are designed for different languages and dialects, so the accuracy of the system will vary depending on which language it is programmed for.
- Misconception: Speech recognition only works with pre-programmed commands or phrases . Correct Viewpoint: Modern speech recognition systems are capable of understanding conversational language as well as specific commands or phrases that have been programmed into them by developers.
Speech Recognition

What Is Speech Recognition?
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It’s also known as automatic speech recognition ( ASR ), speech-to-text, or computer speech recognition.
Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger samples of speech, including different languages, accents, and dialects. AI is used to identify patterns of speech, words, and language to transcribe them into a written format.
In this blog post, we’ll take a deeper dive into speech recognition and look at how it works, its real-world applications, and how platforms like aiOla are using it to change the way we work.

Basic Speech Recognition Concepts
To start understanding speech recognition and all its applications, we need to first look at what it is and isn’t. While speech recognition is more than just the sum of its parts, it’s important to look at each of the parts that contribute to this technology to better grasp how it can make a real impact. Let’s take a look at some common concepts.
Speech Recognition vs. Speech Synthesis
Unlike speech recognition, which converts spoken language into a written format through a computer, speech synthesis does the same in reverse. In other words, speech synthesis is the creation of artificial speech derived from a written text, where a computer uses an AI-generated voice to simulate spoken language. For example, think of the language voice assistants like Siri or Alexa use to communicate information.
Phonetics and Phonology
Phonetics studies the physical sound of human speech, such as its acoustics and articulation. Alternatively, phonology looks at the abstract representation of sounds in a language including their patterns and how they’re organized. These two concepts need to be carefully weighed for speech AI algorithms to understand sound and language as a human might.
Acoustic Modeling
In acoustic modeling , the acoustic characteristics of audio and speech are looked at. When it comes to speech recognition systems, this process is essential since it helps analyze the audio features of each word, such as the frequency in which it’s used, the duration of a word, or the sounds it encompasses.
Language Modeling
Language modeling algorithms look at details like the likelihood of word sequences in a language. This type of modeling helps make speech recognition systems more accurate as it mimics real spoken language by looking at the probability of word combinations in phrases.
Speaker-Dependent vs. Speaker-Independent Systems
A system that’s dependent on a speaker is trained on the unique voice and speech patterns of a specific user, meaning the system might be highly accurate for that individual but not as much for other people. By contrast, a system that’s independent of a speaker can recognize speech for any number of speakers, and while more versatile, may be slightly less accurate.
How Does Speech Recognition Work?
There are a few different stages to speech recognition, each one providing another layer to how language is processed by a computer. Here are the different steps that make up the process.
- First, raw audio input undergoes a process called preprocessing , where background noise is removed to enhance sound quality and make recognition more manageable.
- Next, the audio goes through feature extraction , where algorithms identify distinct characteristics of sounds and words.
- Then, these extracted features go through acoustic modeling , which as we described earlier, is the stage where acoustic and language models decide the most accurate visual representation of the word. These acoustic modeling systems are based on extensive datasets, allowing them to learn the acoustic patterns of different spoken words.
- At the same time, language modeling looks at the structure and probability of words in a sequence, which helps provide context.
- After this, the output goes into a decoding sequence, where the speech recognition system matches data from the extracted features with the acoustic models. This helps determine the most likely word sequence.
- Finally, the audio and corresponding textual output go through post-processing , which refines the output by correcting errors and improving coherence to create a more accurate transcription.
When it comes to advanced systems, all of these stages are done nearly instantaneously, making this process almost invisible to the average user. All of these stages together have made speech recognition a highly versatile tool that can be used in many different ways, from virtual assistants to transcription services and beyond.
Types of Speech Recognition Systems
Speech recognition technology is used in many different ways today, transforming the way humans and machines interact and work together. From professional settings to helping us make our lives a little easier, this technology can take on many forms. Here are some of them.
Virtual Assistants
In 2022, 62% of US adults used a voice assistant on various mobile devices. Siri, Google Assistant, and Alexa are all examples of speech recognition in our daily lives. These applications respond to vocal commands and can interact with humans through natural language in order to complete tasks like sending messages, answering questions, or setting reminders.
Voice Search
Search engines like Google can be searched using voice instead of typing in a query, often with voice assistants. This allows users to conveniently search for a quick answer without sorting through content when they need to be hands-free, like when driving or multitasking. This technology has become so popular over the last few years that now 50% of US-based consumers use voice search every single day.
Transcription Services
Speech recognition has completely changed the transcription industry. It has enabled transcription services to automate the process of turning speech into text, increasing efficiency in many fields like education, legal services, healthcare, and even journalism.
Accessibility
With speech recognition, technologies that may have seemed out of reach are now accessible to people with disabilities. For example, for people with motor impairments or who are visually impaired, AI voice-to-text technology can help with the hands-free operation of things like keyboards, writing assistance for dictation, and voice commands to control devices.
Automotive Systems
Speech recognition is keeping drivers safer by giving them hands-free control over in-car features. Drivers can make calls, adjust the temperature, navigate, or even control the music without ever removing their hands from the wheel and instead just issuing voice commands to a speech-activated system.
How Does aiOla Use Speech Recognition?
aiOla’s AI-powered speech platform is revolutionizing the way certain industries work by bringing advanced speech recognition technology to companies in fields like aviation, fleet management, food safety, and manufacturing.
Traditionally, many processes in these industries were manual, forcing organizations to use a lot of time, budget, and resources to complete mission-critical tasks like inspections and maintenance. However, with aiOla’s advanced speech system, these otherwise labor and resource-intensive tasks can be reduced to a matter of minutes using natural language.
Rather than manually writing to record data during inspections, inspectors can speak about what they’re verifying and the data gets stored instantly. Similarly, through dissecting speech, aiOla can help with predictive maintenance of essential machinery, allowing food manufacturers to produce safer items and decrease downtime.
Since aiOla’s speech recognition platform understands over 100 languages and countless accents, dialects, and industry-specific jargon, the system is highly accurate and can help turn speech into action to go a step further and automate otherwise manual tasks.
Embracing Speech Recognition Technology
Looking ahead, we can only expect the technology that relies on speech recognition to improve and become more embedded into our day-to-day. Indeed, the market for this technology is expected to grow to $19.57 billion by 2030 . Whether it’s refining virtual assistants, improving voice search, or applying speech recognition to new industries, this technology is here to stay and enhance our personal and professional lives.
aiOla, while also a relatively new technology, is already making waves in industries like manufacturing, fleet management, and food safety. Through technological advancements in speech recognition, we only expect aiOla’s capabilities to continue to grow and support a larger variety of businesses and organizations.
Schedule a demo with one of our experts to see how aiOla’s AI speech recognition platform works in action.
What is speech recognition software? Speech recognition software is a technology that enables computers to convert speech into written words. This is done through algorithms that analyze audio signals along with AI, ML, and other technologies. What is a speech recognition example? A relatable example of speech recognition is asking a virtual assistant like Siri on a mobile device to check the day’s weather or set an alarm. While speech recognition can complete a lot more advanced tasks, this exemplifies how this technology is commonly used in everyday life. What is speech recognition in AI? Speech recognition in AI refers to how artificial intelligence processes are used to aid in recognizing voice and language using advanced models and algorithms trained on vast amounts of data. What are some different types of speech recognition? A few different types of speech recognition include speaker-dependent and speaker-independent systems, command and control systems, and continuous speech recognition. What is the difference between voice recognition and speech recognition? Speech recognition converts spoken language into text, while voice recognition works to identify a speaker’s unique vocal characteristics for authentication purposes. In essence, voice recognition is more tied to identity rather than transcription.
Ready to put your speech in motion? We’re listening.

Share your details to schedule a call
We will contact you soon!
Essential Guide to Automatic Speech Recognition Technology

Over the past decade, AI-powered speech recognition systems have slowly become part of our everyday lives, from voice search to virtual assistants in contact centers, cars, hospitals, and restaurants. These speech recognition developments are made possible by deep learning advancements.
Developers across many industries now use automatic speech recognition (ASR) to increase business productivity, application efficiency, and even digital accessibility. This post discusses ASR, how it works, use cases, advancements, and more.
What is automatic speech recognition?
Speech recognition technology is capable of converting spoken language (an audio signal) into written text that is often used as a command.
Today’s most advanced software can accurately process varying language dialects and accents. For example, ASR is commonly seen in user-facing applications such as virtual agents, live captioning, and clinical note-taking. Accurate speech transcription is essential for these use cases.
Developers in the speech AI space also use alternative terminologies to describe speech recognition such as ASR, speech-to-text (STT), and voice recognition.
ASR is a critical component of speech AI , which is a suite of technologies designed to help humans converse with computers through voice.
Why natural language processing is used in speech recognition
Developers are often unclear about the role of natural language processing (NLP) models in the ASR pipeline. Aside from being applied in language models, NLP is also used to augment generated transcripts with punctuation and capitalization at the end of the ASR pipeline.
After the transcript is post-processed with NLP, the text is used for downstream language modeling tasks:
- Sentiment analysis
- Text analytics
- Text summarization
- Question answering
Speech recognition algorithms
Speech recognition algorithms can be implemented in a traditional way using statistical algorithms or by using deep learning techniques such as neural networks to convert speech into text.
Traditional ASR algorithms
Hidden Markov models (HMM) and dynamic time warping (DTW) are two such examples of traditional statistical techniques for performing speech recognition.
Using a set of transcribed audio samples, an HMM is trained to predict word sequences by varying the model parameters to maximize the likelihood of the observed audio sequence.
DTW is a dynamic programming algorithm that finds the best possible word sequence by calculating the distance between time series: one representing the unknown speech and others representing the known words.
Deep learning ASR algorithms
For the last few years, developers have been interested in deep learning for speech recognition because statistical algorithms are less accurate. In fact, deep learning algorithms work better at understanding dialects, accents, context, and multiple languages, and they transcribe accurately even in noisy environments.
Some of the most popular state-of-the-art speech recognition acoustic models are Quartznet , Citrinet , and Conformer . In a typical speech recognition pipeline, you can choose and switch any acoustic model that you want based on your use case and performance.
Implementation tools for deep learning models
Several tools are available for developing deep learning speech recognition models and pipelines, including Kaldi , Mozilla DeepSpeech, NVIDIA NeMo , NVIDIA Riva , NVIDIA TAO Toolkit , and services from Google, Amazon, and Microsoft.
Kaldi, DeepSpeech, and NeMo are open-source toolkits that help you build speech recognition models. TAO Toolkit and Riva are closed-source SDKs that help you develop customizable pipelines that can be deployed in production.
Cloud service providers like Google, AWS, and Microsoft offer generic services that you can easily plug and play with.
Deep learning speech recognition pipeline
An ASR pipeline consists of the following components:
- Spectrogram generator that converts raw audio to spectrograms.
- Acoustic model that takes the spectrograms as input and outputs a matrix of probabilities over characters over time.
- Decoder (optionally coupled with a language model) that generates possible sentences from the probability matrix.
- Punctuation and capitalization model that formats the generated text for easier human consumption.
A typical deep learning pipeline for speech recognition includes the following components:
- Data preprocessing
- Neural acoustic model
- Decoder (optionally coupled with an n-gram language model)
- Punctuation and capitalization model
Figure 1 shows an example of a deep learning speech recognition pipeline:.

Datasets are essential in any deep learning application. Neural networks function similarly to the human brain. The more data you use to teach the model, the more it learns. The same is true for the speech recognition pipeline.
A few popular speech recognition datasets are
- LibriSpeech
- Fisher English Training Speech
- Mozilla Common Voice (MCV)
- 2000 HUB 5 English Evaluation Speech
- AN4 (includes recordings of people spelling out addresses and names)
- Aishell-1/AIshell-2 Mandarin speech corpus
Data processing is the first step. It includes data preprocessing and augmentation techniques such as speed/time/noise/impulse perturbation and time stretch augmentation, fast Fourier Transformations (FFT) using windowing, and normalization techniques.
For example, in Figure 2, the mel spectrogram is generated from a raw audio waveform after applying FFT using the windowing technique.

We can also use perturbation techniques to augment the training dataset. Figures 3 and 4 represent techniques like noise perturbation and masking being used to increase the size of the training dataset in order to avoid problems like overfitting.

The output of the data preprocessing stage is a spectrogram/mel spectrogram, which is a visual representation of the strength of the audio signal over time.
Mel spectrograms are then fed into the next stage: a neural acoustic model . QuartzNet, CitriNet, ContextNet, Conformer-CTC, and Conformer-Transducer are examples of cutting-edge neural acoustic models. Multiple ASR models exist for several reasons, such as the need for real-time performance, higher accuracy, memory size, and compute cost for your use case.
However, Conformer-based models are becoming more popular due to their improved accuracy and ability to comprehend. The acoustic model returns the probability of characters/words at each time stamp.
Figure 5 shows the output of the acoustic model, with time stamps.

The acoustic model’s output is fed into the decoder along with the language model. Decoders include beam search and greedy decoders, and language models include n-gram language, KenLM, and neural scoring. When it comes to the decoder, it helps to generate top words, which are then passed to language models to predict the correct sentence.
In Figure 6, the decoder selects the next best word based on the probability score. Based on the final highest score, the correct word or sentence is selected and sent to the punctuation and capitalization model.

The ASR pipeline generates text with no punctuation or capitalization.
Finally, a punctuation and capitalization model is used to improve the text quality for better readability. Bidirectional Encoder Representations from Transformers (BERT) models are commonly used to generate punctuated text.
Figure 7 shows a simple example of a before-and-after punctuation and capitalization model.

Speech recognition industry impact
There are many unique applications for ASR . For example, speech recognition could help industries such as finance, telecommunications, and unified communications as a service (UCaaS) to improve customer experience, operational efficiency, and return on investment (ROI).
Speech recognition is applied in the finance industry for applications such as call center agent assist and trade floor transcripts. ASR is used to transcribe conversations between customers and call center agents or trade floor agents. The generated transcriptions can then be analyzed and used to provide real-time recommendations to agents. This adds to an 80% reduction in post-call time.
Furthermore, the generated transcripts are used for downstream tasks:
- Intent and entity recognition
Telecommunications
Contact centers are critical components of the telecommunications industry. With contact center technology, you can reimagine the telecommunications customer center, and speech recognition helps with that.
As previously discussed in the finance call center use case, ASR is used in Telecom contact centers to transcribe conversations between customers and contact center agents to analyze them and recommend call center agents in real time. T-Mobile uses ASR for quick customer resolution , for example.
Unified communications as a software
COVID-19 increased demand for UCaaS solutions, and vendors in the space began focusing on the use of speech AI technologies such as ASR to create more engaging meeting experiences.
For example, ASR can be used to generate live captions in video conferencing meetings. Captions generated can then be used for downstream tasks such as meeting summaries and identifying action items in notes.
Future of ASR technology
Speech recognition is not as easy as it sounds. Developing speech recognition is full of challenges, ranging from accuracy to customization for your use case to real-time performance. On the other hand, businesses and academic institutions are racing to overcome some of these challenges and advance the use of speech recognition capabilities.
ASR challenges
Some of the challenges in developing and deploying speech recognition pipelines in production include the following:
- Lack of tools and SDKs that offer state-of-the-art (SOTA) ASR models makes it difficult for developers to take advantage of the best speech recognition technology.
- Limited customization capabilities that enable developers to fine-tune on domain-specific and context-specific jargon, multiple languages, dialects, and accents to have your applications understand and speak like you
- Restricted deployment support; for example, depending on the use case, the software should be capable of being deployed in any cloud, on-premises, edge, and embedded.
- Real-time speech recognition pipelines; for instance, in a call center agent assist use case, we cannot wait several seconds for conversations to be transcribed before using them to empower agents.
For more information about the major pain points that developers face when adding speech-to-text capabilities to applications, see Solving Automatic Speech Recognition Deployment Challenges .
ASR advancements
Numerous advancements in speech recognition are occurring on both the research and software development fronts. To begin, research has resulted in the development of several new cutting-edge ASR architectures, E2E speech recognition models, and self-supervised or unsupervised training techniques.
On the software side, there are a few tools that enable quick access to SOTA models, and then there are different sets of tools that enable the deployment of models as services in production.
Key takeaways
Speech recognition continues to grow in adoption due to its advancements in deep learning-based algorithms that have made ASR as accurate as human recognition. Also, breakthroughs like multilingual ASR help companies make their apps available worldwide, and moving algorithms from cloud to on-device saves money, protects privacy, and speeds up inference.
NVIDIA offers Riva , a speech AI SDK, to address several of the challenges discussed above. With Riva, you can quickly access the latest SOTA research models tailored for production purposes. You can customize these models to your domain and use case, deploy on any cloud, on-premises, edge, or embedded, and run them in real-time for engaging natural interactions.
Learn how your organization can benefit from speech recognition skills with the free ebook, Building Speech AI Applications .
Related resources
- GTC session: Speech AI Demystified
- GTC session: Mastering Speech AI for Multilingual Multimedia Transformation
- GTC session: Human-Like AI Voices: Exploring the Evolution of Voice Technology
- NGC Containers: Domain Specific NeMo ASR Application
- NGC Containers: MATLAB
- Webinar: How Telcos Transform Customer Experiences with Conversational AI
About the Authors

Related posts

Video: Exploring Speech AI from Research to Practical Production Applications
Deep learning is transforming asr and tts algorithms.

Making an NVIDIA Riva ASR Service for a New Language
Exploring Unique Applications of Automatic Speech Recognition Technology

An Easy Introduction to Speech AI

Automating Telco Network Design using NVIDIA NIM and NVIDIA NeMo

Improving Video Quality with the NVIDIA Video Codec SDK 12.2 for HEVC

Introducing Grouped GEMM APIs in cuBLAS and More Performance Updates

Spotlight: Cisco Enhances Workload Security and Operational Efficiency with NVIDIA BlueField-3 DPUs

Seamlessly Deploying a Swarm of LoRA Adapters with NVIDIA NIM
- Random article
- Teaching guide
- Privacy & cookies

Speech recognition software
by Chris Woodford . Last updated: August 17, 2023.
I t's just as well people can understand speech. Imagine if you were like a computer: friends would have to "talk" to you by prodding away at a plastic keyboard connected to your brain by a long, curly wire. If you wanted to say "hello" to someone, you'd have to reach out, chatter your fingers over their keyboard, and wait for their eyes to light up; they'd have to do the same to you. Conversations would be a long, slow, elaborate nightmare—a silent dance of fingers on plastic; strange, abstract, and remote. We'd never put up with such clumsiness as humans, so why do we talk to our computers this way?
Scientists have long dreamed of building machines that can chatter and listen just like humans. But although computerized speech recognition has been around for decades, and is now built into most smartphones and PCs, few of us actually use it. Why? Possibly because we never even bother to try it out, working on the assumption that computers could never pull off a trick so complex as understanding the human voice. It's certainly true that speech recognition is a complex problem that's challenged some of the world's best computer scientists, mathematicians, and linguists. How well are they doing at cracking the problem? Will we all be chatting to our PCs one day soon? Let's take a closer look and find out!
Photo: A court reporter dictates notes into a laptop with a noise-cancelling microphone and speech-recogition software. Photo by Micha Pierce courtesy of US Marine Corps and DVIDS .
What is speech?
Language sets people far above our creeping, crawling animal friends. While the more intelligent creatures, such as dogs and dolphins, certainly know how to communicate with sounds, only humans enjoy the rich complexity of language. With just a couple of dozen letters, we can build any number of words (most dictionaries contain tens of thousands) and express an infinite number of thoughts.
Photo: Speech recognition has been popping up all over the place for quite a few years now. Even my old iPod Touch (dating from around 2012) has a built-in "voice control" program that let you pick out music just by saying "Play albums by U2," or whatever band you're in the mood for.
When we speak, our voices generate little sound packets called phones (which correspond to the sounds of letters or groups of letters in words); so speaking the word cat produces phones that correspond to the sounds "c," "a," and "t." Although you've probably never heard of these kinds of phones before, you might well be familiar with the related concept of phonemes : simply speaking, phonemes are the basic LEGO™ blocks of sound that all words are built from. Although the difference between phones and phonemes is complex and can be very confusing, this is one "quick-and-dirty" way to remember it: phones are actual bits of sound that we speak (real, concrete things), whereas phonemes are ideal bits of sound we store (in some sense) in our minds (abstract, theoretical sound fragments that are never actually spoken).
Computers and computer models can juggle around with phonemes, but the real bits of speech they analyze always involves processing phones. When we listen to speech, our ears catch phones flying through the air and our leaping brains flip them back into words, sentences, thoughts, and ideas—so quickly, that we often know what people are going to say before the words have fully fled from their mouths. Instant, easy, and quite dazzling, our amazing brains make this seem like a magic trick. And it's perhaps because listening seems so easy to us that we think computers (in many ways even more amazing than brains) should be able to hear, recognize, and decode spoken words as well. If only it were that simple!
Why is speech so hard to handle?
The trouble is, listening is much harder than it looks (or sounds): there are all sorts of different problems going on at the same time... When someone speaks to you in the street, there's the sheer difficulty of separating their words (what scientists would call the acoustic signal ) from the background noise —especially in something like a cocktail party, where the "noise" is similar speech from other conversations. When people talk quickly, and run all their words together in a long stream, how do we know exactly when one word ends and the next one begins? (Did they just say "dancing and smile" or "dance, sing, and smile"?) There's the problem of how everyone's voice is a little bit different, and the way our voices change from moment to moment. How do our brains figure out that a word like "bird" means exactly the same thing when it's trilled by a ten year-old girl or boomed by her forty-year-old father? What about words like "red" and "read" that sound identical but mean totally different things (homophones, as they're called)? How does our brain know which word the speaker means? What about sentences that are misheard to mean radically different things? There's the age-old military example of "send reinforcements, we're going to advance" being misheard for "send three and fourpence, we're going to a dance"—and all of us can probably think of song lyrics we've hilariously misunderstood the same way (I always chuckle when I hear Kate Bush singing about "the cattle burning over your shoulder"). On top of all that stuff, there are issues like syntax (the grammatical structure of language) and semantics (the meaning of words) and how they help our brain decode the words we hear, as we hear them. Weighing up all these factors, it's easy to see that recognizing and understanding spoken words in real time (as people speak to us) is an astonishing demonstration of blistering brainpower.
It shouldn't surprise or disappoint us that computers struggle to pull off the same dazzling tricks as our brains; it's quite amazing that they get anywhere near!
Photo: Using a headset microphone like this makes a huge difference to the accuracy of speech recognition: it reduces background sound, making it much easier for the computer to separate the signal (the all-important words you're speaking) from the noise (everything else).
How do computers recognize speech?
Speech recognition is one of the most complex areas of computer science —and partly because it's interdisciplinary: it involves a mixture of extremely complex linguistics, mathematics, and computing itself. If you read through some of the technical and scientific papers that have been published in this area (a few are listed in the references below), you may well struggle to make sense of the complexity. My objective is to give a rough flavor of how computers recognize speech, so—without any apology whatsoever—I'm going to simplify hugely and miss out most of the details.
Broadly speaking, there are four different approaches a computer can take if it wants to turn spoken sounds into written words:
1: Simple pattern matching

Ironically, the simplest kind of speech recognition isn't really anything of the sort. You'll have encountered it if you've ever phoned an automated call center and been answered by a computerized switchboard. Utility companies often have systems like this that you can use to leave meter readings, and banks sometimes use them to automate basic services like balance inquiries, statement orders, checkbook requests, and so on. You simply dial a number, wait for a recorded voice to answer, then either key in or speak your account number before pressing more keys (or speaking again) to select what you want to do. Crucially, all you ever get to do is choose one option from a very short list, so the computer at the other end never has to do anything as complex as parsing a sentence (splitting a string of spoken sound into separate words and figuring out their structure), much less trying to understand it; it needs no knowledge of syntax (language structure) or semantics (meaning). In other words, systems like this aren't really recognizing speech at all: they simply have to be able to distinguish between ten different sound patterns (the spoken words zero through nine) either using the bleeping sounds of a Touch-Tone phone keypad (technically called DTMF ) or the spoken sounds of your voice.
From a computational point of view, there's not a huge difference between recognizing phone tones and spoken numbers "zero", "one," "two," and so on: in each case, the system could solve the problem by comparing an entire chunk of sound to similar stored patterns in its memory. It's true that there can be quite a bit of variability in how different people say "three" or "four" (they'll speak in a different tone, more or less slowly, with different amounts of background noise) but the ten numbers are sufficiently different from one another for this not to present a huge computational challenge. And if the system can't figure out what you're saying, it's easy enough for the call to be transferred automatically to a human operator.
Photo: Voice-activated dialing on cellphones is little more than simple pattern matching. You simply train the phone to recognize the spoken version of a name in your phonebook. When you say a name, the phone doesn't do any particularly sophisticated analysis; it simply compares the sound pattern with ones you've stored previously and picks the best match. No big deal—which explains why even an old phone like this 2001 Motorola could do it.
2: Pattern and feature analysis
Automated switchboard systems generally work very reliably because they have such tiny vocabularies: usually, just ten words representing the ten basic digits. The vocabulary that a speech system works with is sometimes called its domain . Early speech systems were often optimized to work within very specific domains, such as transcribing doctor's notes, computer programming commands, or legal jargon, which made the speech recognition problem far simpler (because the vocabulary was smaller and technical terms were explicitly trained beforehand). Much like humans, modern speech recognition programs are so good that they work in any domain and can recognize tens of thousands of different words. How do they do it?
Most of us have relatively large vocabularies, made from hundreds of common words ("a," "the," "but" and so on, which we hear many times each day) and thousands of less common ones (like "discombobulate," "crepuscular," "balderdash," or whatever, which we might not hear from one year to the next). Theoretically, you could train a speech recognition system to understand any number of different words, just like an automated switchboard: all you'd need to do would be to get your speaker to read each word three or four times into a microphone, until the computer generalized the sound pattern into something it could recognize reliably.
The trouble with this approach is that it's hugely inefficient. Why learn to recognize every word in the dictionary when all those words are built from the same basic set of sounds? No-one wants to buy an off-the-shelf computer dictation system only to find they have to read three or four times through a dictionary, training it up to recognize every possible word they might ever speak, before they can do anything useful. So what's the alternative? How do humans do it? We don't need to have seen every Ford, Chevrolet, and Cadillac ever manufactured to recognize that an unknown, four-wheeled vehicle is a car: having seen many examples of cars throughout our lives, our brains somehow store what's called a prototype (the generalized concept of a car, something with four wheels, big enough to carry two to four passengers, that creeps down a road) and we figure out that an object we've never seen before is a car by comparing it with the prototype. In much the same way, we don't need to have heard every person on Earth read every word in the dictionary before we can understand what they're saying; somehow we can recognize words by analyzing the key features (or components) of the sounds we hear. Speech recognition systems take the same approach.
The recognition process
Practical speech recognition systems start by listening to a chunk of sound (technically called an utterance ) read through a microphone. The first step involves digitizing the sound (so the up-and-down, analog wiggle of the sound waves is turned into digital format, a string of numbers) by a piece of hardware (or software) called an analog-to-digital (A/D) converter (for a basic introduction, see our article on analog versus digital technology ). The digital data is converted into a spectrogram (a graph showing how the component frequencies of the sound change in intensity over time) using a mathematical technique called a Fast Fourier Transform (FFT) ), then broken into a series of overlapping chunks called acoustic frames , each one typically lasting 1/25 to 1/50 of a second. These are digitally processed in various ways and analyzed to find the components of speech they contain. Assuming we've separated the utterance into words, and identified the key features of each one, all we have to do is compare what we have with a phonetic dictionary (a list of known words and the sound fragments or features from which they're made) and we can identify what's probably been said. Probably is always the word in speech recognition: no-one but the speaker can ever know exactly what was said.)
Seeing speech
In theory, since spoken languages are built from only a few dozen phonemes (English uses about 46, while Spanish has only about 24), you could recognize any possible spoken utterance just by learning to pick out phones (or similar key features of spoken language such as formants , which are prominent frequencies that can be used to help identify vowels). Instead of having to recognize the sounds of (maybe) 40,000 words, you'd only need to recognize the 46 basic component sounds (or however many there are in your language), though you'd still need a large phonetic dictionary listing the phonemes that make up each word. This method of analyzing spoken words by identifying phones or phonemes is often called the beads-on-a-string model : a chunk of unknown speech (the string) is recognized by breaking it into phones or bits of phones (the beads); figure out the phones and you can figure out the words.
Most speech recognition programs get better as you use them because they learn as they go along using feedback you give them, either deliberately (by correcting mistakes) or by default (if you don't correct any mistakes, you're effectively saying everything was recognized perfectly—which is also feedback). If you've ever used a program like one of the Dragon dictation systems, you'll be familiar with the way you have to correct your errors straight away to ensure the program continues to work with high accuracy. If you don't correct mistakes, the program assumes it's recognized everything correctly, which means similar mistakes are even more likely to happen next time. If you force the system to go back and tell it which words it should have chosen, it will associate those corrected words with the sounds it heard—and do much better next time.
Screenshot: With speech dictation programs like Dragon NaturallySpeaking, shown here, it's important to go back and correct your mistakes if you want your words to be recognized accurately in future.
3: Statistical analysis
In practice, recognizing speech is much more complex than simply identifying phones and comparing them to stored patterns, and for a whole variety of reasons: Speech is extremely variable: different people speak in different ways (even though we're all saying the same words and, theoretically, they're all built from a standard set of phonemes) You don't always pronounce a certain word in exactly the same way; even if you did, the way you spoke a word (or even part of a word) might vary depending on the sounds or words that came before or after. As a speaker's vocabulary grows, the number of similar-sounding words grows too: the digits zero through nine all sound different when you speak them, but "zero" sounds like "hero," "one" sounds like "none," "two" could mean "two," "to," or "too"... and so on. So recognizing numbers is a tougher job for voice dictation on a PC, with a general 50,000-word vocabulary, than for an automated switchboard with a very specific, 10-word vocabulary containing only the ten digits. The more speakers a system has to recognize, the more variability it's going to encounter and the bigger the likelihood of making mistakes. For something like an off-the-shelf voice dictation program (one that listens to your voice and types your words on the screen), simple pattern recognition is clearly going to be a bit hit and miss. The basic principle of recognizing speech by identifying its component parts certainly holds good, but we can do an even better job of it by taking into account how language really works. In other words, we need to use what's called a language model .
When people speak, they're not simply muttering a series of random sounds. Every word you utter depends on the words that come before or after. For example, unless you're a contrary kind of poet, the word "example" is much more likely to follow words like "for," "an," "better," "good", "bad," and so on than words like "octopus," "table," or even the word "example" itself. Rules of grammar make it unlikely that a noun like "table" will be spoken before another noun ("table example" isn't something we say) while—in English at least—adjectives ("red," "good," "clear") come before nouns and not after them ("good example" is far more probable than "example good"). If a computer is trying to figure out some spoken text and gets as far as hearing "here is a ******* example," it can be reasonably confident that ******* is an adjective and not a noun. So it can use the rules of grammar to exclude nouns like "table" and the probability of pairs like "good example" and "bad example" to make an intelligent guess. If it's already identified a "g" sound instead of a "b", that's an added clue.
Virtually all modern speech recognition systems also use a bit of complex statistical hocus-pocus to help figure out what's being said. The probability of one phone following another, the probability of bits of silence occurring in between phones, and the likelihood of different words following other words are all factored in. Ultimately, the system builds what's called a hidden Markov model (HMM) of each speech segment, which is the computer's best guess at which beads are sitting on the string, based on all the things it's managed to glean from the sound spectrum and all the bits and pieces of phones and silence that it might reasonably contain. It's called a Markov model (or Markov chain), for Russian mathematician Andrey Markov , because it's a sequence of different things (bits of phones, words, or whatever) that change from one to the next with a certain probability. Confusingly, it's referred to as a "hidden" Markov model even though it's worked out in great detail and anything but hidden! "Hidden," in this case, simply means the contents of the model aren't observed directly but figured out indirectly from the sound spectrum. From the computer's viewpoint, speech recognition is always a probabilistic "best guess" and the right answer can never be known until the speaker either accepts or corrects the words that have been recognized. (Markov models can be processed with an extra bit of computer jiggery pokery called the Viterbi algorithm , but that's beyond the scope of this article.)
4: Artificial neural networks
HMMs have dominated speech recognition since the 1970s—for the simple reason that they work so well. But they're by no means the only technique we can use for recognizing speech. There's no reason to believe that the brain itself uses anything like a hidden Markov model. It's much more likely that we figure out what's being said using dense layers of brain cells that excite and suppress one another in intricate, interlinked ways according to the input signals they receive from our cochleas (the parts of our inner ear that recognize different sound frequencies).
Back in the 1980s, computer scientists developed "connectionist" computer models that could mimic how the brain learns to recognize patterns, which became known as artificial neural networks (sometimes called ANNs). A few speech recognition scientists explored using neural networks, but the dominance and effectiveness of HMMs relegated alternative approaches like this to the sidelines. More recently, scientists have explored using ANNs and HMMs side by side and found they give significantly higher accuracy over HMMs used alone.
Artwork: Neural networks are hugely simplified, computerized versions of the brain—or a tiny part of it that have inputs (where you feed in information), outputs (where results appear), and hidden units (connecting the two). If you train them with enough examples, they learn by gradually adjusting the strength of the connections between the different layers of units. Once a neural network is fully trained, if you show it an unknown example, it will attempt to recognize what it is based on the examples it's seen before.
Speech recognition: a summary
Artwork: A summary of some of the key stages of speech recognition and the computational processes happening behind the scenes.
What can we use speech recognition for?
We've already touched on a few of the more common applications of speech recognition, including automated telephone switchboards and computerized voice dictation systems. But there are plenty more examples where those came from.
Many of us (whether we know it or not) have cellphones with voice recognition built into them. Back in the late 1990s, state-of-the-art mobile phones offered voice-activated dialing , where, in effect, you recorded a sound snippet for each entry in your phonebook, such as the spoken word "Home," or whatever that the phone could then recognize when you spoke it in future. A few years later, systems like SpinVox became popular helping mobile phone users make sense of voice messages by converting them automatically into text (although a sneaky BBC investigation eventually claimed that some of its state-of-the-art speech automated speech recognition was actually being done by humans in developing countries!).
Today's smartphones make speech recognition even more of a feature. Apple's Siri , Google Assistant ("Hey Google..."), and Microsoft's Cortana are smartphone "personal assistant apps" who'll listen to what you say, figure out what you mean, then attempt to do what you ask, whether it's looking up a phone number or booking a table at a local restaurant. They work by linking speech recognition to complex natural language processing (NLP) systems, so they can figure out not just what you say , but what you actually mean , and what you really want to happen as a consequence. Pressed for time and hurtling down the street, mobile users theoretically find this kind of system a boon—at least if you believe the hype in the TV advertisements that Google and Microsoft have been running to promote their systems. (Google quietly incorporated speech recognition into its search engine some time ago, so you can Google just by talking to your smartphone, if you really want to.) If you have one of the latest voice-powered electronic assistants, such as Amazon's Echo/Alexa or Google Home, you don't need a computer of any kind (desktop, tablet, or smartphone): you just ask questions or give simple commands in your natural language to a thing that resembles a loudspeaker ... and it answers straight back.
Screenshot: When I asked Google "does speech recognition really work," it took it three attempts to recognize the question correctly.
Will speech recognition ever take off?
I'm a huge fan of speech recognition. After suffering with repetitive strain injury on and off for some time, I've been using computer dictation to write quite a lot of my stuff for about 15 years, and it's been amazing to see the improvements in off-the-shelf voice dictation over that time. The early Dragon NaturallySpeaking system I used on a Windows 95 laptop was fairly reliable, but I had to speak relatively slowly, pausing slightly between each word or word group, giving a horribly staccato style that tended to interrupt my train of thought. This slow, tedious one-word-at-a-time approach ("can – you – tell – what – I – am – saying – to – you") went by the name discrete speech recognition . A few years later, things had improved so much that virtually all the off-the-shelf programs like Dragon were offering continuous speech recognition , which meant I could speak at normal speed, in a normal way, and still be assured of very accurate word recognition. When you can speak normally to your computer, at a normal talking pace, voice dictation programs offer another advantage: they give clumsy, self-conscious writers a much more attractive, conversational style: "write like you speak" (always a good tip for writers) is easy to put into practice when you speak all your words as you write them!
Despite the technological advances, I still generally prefer to write with a keyboard and mouse . Ironically, I'm writing this article that way now. Why? Partly because it's what I'm used to. I often write highly technical stuff with a complex vocabulary that I know will defeat the best efforts of all those hidden Markov models and neural networks battling away inside my PC. It's easier to type "hidden Markov model" than to mutter those words somewhat hesitantly, watch "hiccup half a puddle" pop up on screen and then have to make corrections.
Screenshot: You an always add more words to a speech recognition program. Here, I've decided to train the Microsoft Windows built-in speech recognition engine to spot the words 'hidden Markov model.'
Mobile revolution?
You might think mobile devices—with their slippery touchscreens —would benefit enormously from speech recognition: no-one really wants to type an essay with two thumbs on a pop-up QWERTY keyboard. Ironically, mobile devices are heavily used by younger, tech-savvy kids who still prefer typing and pawing at screens to speaking out loud. Why? All sorts of reasons, from sheer familiarity (it's quick to type once you're used to it—and faster than fixing a computer's goofed-up guesses) to privacy and consideration for others (many of us use our mobile phones in public places and we don't want our thoughts wide open to scrutiny or howls of derision), and the sheer difficulty of speaking clearly and being clearly understood in noisy environments. Recently, I was walking down a street and overheard a small garden party where the sounds of happy laughter, drinking, and discreet background music were punctuated by a sudden grunt of "Alexa play Copacabana by Barry Manilow"—which silenced the conversation entirely and seemed jarringly out of place. Speech recognition has never been so indiscreet. What you're doing with your computer also makes a difference. If you've ever used speech recognition on a PC, you'll know that writing something like an essay (dictating hundreds or thousands of words of ordinary text) is a whole lot easier than editing it afterwards (where you laboriously try to select words or sentences and move them up or down so many lines with awkward cut and paste commands). And trying to open and close windows, start programs, or navigate around a computer screen by voice alone is clumsy, tedious, error-prone, and slow. It's far easier just to click your mouse or swipe your finger.
Photo: Here I'm using Google's Live Transcribe app to dictate the last paragraph of this article. As you can see, apart from the punctuation, the transcription is flawless, without any training at all. This is the fastest and most accurate speech recognition software I've ever used. It's mainly designed as an accessibility aid for deaf and hard of hearing people, but it can be used for dictation too.
Developers of speech recognition systems insist everything's about to change, largely thanks to natural language processing and smart search engines that can understand spoken queries. ("OK Google...") But people have been saying that for decades now: the brave new world is always just around the corner. According to speech pioneer James Baker, better speech recognition "would greatly increase the speed and ease with which humans could communicate with computers, and greatly speed and ease the ability with which humans could record and organize their own words and thoughts"—but he wrote (or perhaps voice dictated?) those words 25 years ago! Just because Google can now understand speech, it doesn't follow that we automatically want to speak our queries rather than type them—especially when you consider some of the wacky things people look for online. Humans didn't invent written language because others struggled to hear and understand what they were saying. Writing and speaking serve different purposes. Writing is a way to set out longer, more clearly expressed and elaborated thoughts without having to worry about the limitations of your short-term memory; speaking is much more off-the-cuff. Writing is grammatical; speech doesn't always play by the rules. Writing is introverted, intimate, and inherently private; it's carefully and thoughtfully composed. Speaking is an altogether different way of expressing your thoughts—and people don't always want to speak their minds. While technology may be ever advancing, it's far from certain that speech recognition will ever take off in quite the way that its developers would like. I'm typing these words, after all, not speaking them.
If you liked this article...
Don't want to read our articles try listening instead, find out more, on this website.
- Microphones
- Neural networks
- Speech synthesis
- Automatic Speech Recognition: A Deep Learning Approach by Dong Yu and Li Deng. Springer, 2015. Two Microsoft researchers review state-of-the-art, neural-network approaches to recognition.
- Theory and Applications of Digital Speech Processing by Lawrence R. Rabiner and Ronald W. Schafer. Pearson, 2011. An up-to-date review at undergraduate level.
- Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition by Daniel Jurafsky, James Martin. Prentice Hall, 2009. An up-to-date, interdisciplinary review of speech recognition technology.
- Statistical Methods for Speech Recognition by Frederick Jelinek. MIT Press, 1997. A detailed guide to Hidden Markov Models and the other statistical techniques that computers use to figure out human speech.
- Fundamentals of Speech Recognition by Lawrence R. Rabiner and Biing-Hwang Juang. PTR Prentice Hall, 1993. A little dated now, but still a good introduction to the basic concepts.
- Speech Recognition: Invited Papers Presented at the 1974 IEEE Symposium by D. R. Reddy (ed). Academic Press, 1975. A classic collection of pioneering papers from the golden age of the 1970s.
Easy-to-understand
- Lost voices, ignored words: Apple's speech recognition needs urgent reform by Colin Hughes, The Register, 16 August 2023. How speech recognition software ignores the needs of the people who need it most—disabled people with different accessibility needs.
- Android's Live Transcribe will let you save transcriptions and show 'sound events' by Dieter Bohn, The Verge, 16 May 2019. An introduction to Google's handy, 70-language transcription app.
- Hey, Siri: Read My Lips by Emily Waltz, IEEE Spectrum, 8 February 2019. How your computer can translate your words... without even listening.
- Interpol's New Software Will Recognize Criminals by Their Voices by Michael Dumiak, 16 May 2018. Is it acceptable for law enforcement agencies to store huge quantities of our voice samples if it helps them trap the occasional bad guy?
- Cypher: The Deep-Learning Software That Will Help Siri, Alexa, and Cortana Hear You : by Amy Nordrum. IEEE Spectrum, 24 October 2016. Cypher helps voice recognition programs to separate speech signals from background noise.
- In the Future, How Will We Talk to Our Technology? : by David Pierce. Wired, 27 September 2015. What sort of hardware will we use with future speech recognition software?
- The Holy Grail of Speech Recognition by Janie Chang: Microsoft Research, 29 August 2011. How neural networks are making a comeback in speech recognition research. [Archived via the Wayback Machine.]
- Audio Alchemy: Getting Computers to Understand Overlapping Speech by John R. Hershey et al. Scientific American, April 12, 2011. How can computers make sense of two people talking at once?
- How Siri Works: Interview with Tom Gruber by Nova Spivack, Minding the Planet, 26 January 2010. Gruber explains some of the technical tricks that allow Siri to understand natural language.
- A sound start for speech tech : by LJ Rich. BBC News, 15 May 2009. Cambridge University's Dr Tony Robinson talks us through the science of speech recognition.
- Speech Recognition by Computer by Stephen E. Levinson and Mark Y. Liberman, Scientific American, Vol. 244, No. 4 (April 1981), pp. 64–77. A more detailed overview of the basic concepts. A good article to continue with after you've read mine.
More technical
- An All-Neural On-Device Speech Recognizer by Johan Schalkwyk, Google AI Blog, March 12, 2019. Google announces a state-of-the-art speech recognition system based entirely on what are called recurrent neural network transducers (RNN-Ts).
- Improving End-to-End Models For Speech Recognition by Tara N. Sainath, and Yonghui Wu, Google Research Blog, December 14, 2017. A cutting-edge speech recognition model that integrates traditionally separate aspects of speech recognition into a single system.
- A Historical Perspective of Speech Recognition by Xuedong Huang, James Baker, Raj Reddy. Communications of the ACM, January 2014 (Vol. 57 No. 1), Pages 94–103.
- [PDF] Application Of Pretrained Deep Neural Networks To Large Vocabulary Speech Recognition by Navdeep Jaitly, Patrick Nguyen, Andrew Senior, Vincent Vanhoucke. Proceedings of Interspeech 2012. An insight into Google's use of neural networks for speech recognition.
- Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition by George Dahl et al. IEEE Transactions on Audio, Speech, and Language Processing, Vol. 20 No. 1, January 2012. A review of Microsoft's recent research into using neural networks with HMMs.
- Speech Recognition Technology: A Critique by Stephen E. Levinson, Proceedings of the National Academy of Sciences of the United States of America. Vol. 92, No. 22, October 24, 1995, pp. 9953–9955.
- Hidden Markov Models for Speech Recognition by B. H. Juang and L. R. Rabiner, Technometrics, Vol. 33, No. 3, August, 1991, pp. 251–272.
- A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition by Lawrence R. Rabiner. Proceedings of the IEEE, Vol 77 No 2, February 1989. A classic introduction to Markov models, though non-mathematicians will find it tough going.
- US Patent: 4,783,803: Speech recognition apparatus and method by James K. Baker, Dragon Systems, 8 November 1988. One of Baker's first Dragon patents. Another Baker patent filed the following year follows on from this. See US Patent: 4,866,778: Interactive speech recognition apparatus by James K. Baker, Dragon Systems, 12 September 1989.
- US Patent 4,783,804: Hidden Markov model speech recognition arrangement by Stephen E. Levinson, Lawrence R. Rabiner, and Man M. Sondi, AT&T Bell Laboratories, 6 May 1986. Sets out one approach to probabilistic speech recognition using Markov models.
- US Patent: 4,363,102: Speaker identification system using word recognition templates by John E. Holmgren, Bell Labs, 7 December 1982. A method of recognizing a particular person's voice using analysis of key features.
- US Patent 2,938,079: Spectrum segmentation system for the automatic extraction of formant frequencies from human speech by James L. Flanagan, US Air Force, 24 May 1960. An early speech recognition system based on formant (peak frequency) analysis.
- A Historical Perspective of Speech Recognition by Raj Reddy (an AI researcher at Carnegie Mellon), James Baker (founder of Dragon), and Xuedong Huang (of Microsoft). Speech recognition pioneers look back on the advances they helped to inspire in this four-minute discussion.
Text copyright © Chris Woodford 2007, 2020. All rights reserved. Full copyright notice and terms of use .
Rate this page
Tell your friends, cite this page, more to explore on our website....
- Get the book
- Send feedback
Resolve over 90.000 requests per minute by automating support processes with your AI assistant. Click to learn more!
Omni-channel Inbox
Gain wider customer reach by centralizing user interactions in an omni-channel inbox.
Workflow Management
Define rules and execute automated tasks to improve your workflow.
Build personalized action sequences and execute them with one click.
Communication
Collaboration
Let your agents collaborate privately by using canned responses, private notes, and mentions.
Tackle support challenges collaboratively, track team activity, and eliminate manual workload.
Website Channel
Embed Widget
Create pre-chat forms, customize your widget, and add fellow collaborators.
AI Superpowers
Knowledge-Based AI Assistant
Handle high-volume queries and ensure quick resolutions.
Rule-Based AI Assistant
Design custom conversation flows to guide users through personalized interactions.
Reports & Analysis
Get insightful reports to achieve a deeper understanding of customer behavior.
Integrations
Download apps from
Open ai chat gpt.
Let GPT handle your customer queries.
Documentations
For Customers
Feature Requests
User Feedback
Bug Reports
Platform Updates
Platform Status
Release Notes
What Is Speech Recognition and How Does It Work?

With modern devices, you can check the weather, place an order, make a call, and play your favorite song entirely hands-free. Giving voice commands to your gadgets makes it incredibly easy to multitask and handle daily chores. It’s all possible thanks to speech recognition technology.
Let’s explore speech recognition further to understand how it has evolved, how it works, and where it’s used today.
What Is Speech Recognition?
Speech recognition is the capacity of a computer to convert human speech into written text. Also known as automatic/automated speech recognition (ASR) and speech to text (STT), it’s a subfield of computer science and computational linguistics. Today, this technology has evolved to the point where machines can understand natural speech in different languages, dialects, accents, and speech patterns.
Speech Recognition vs. Voice Recognition
Although similar, speech and voice recognition are not the same technology. Here’s a breakdown below.
Speech recognition aims to identify spoken words and turn them into written text, in contrast to voice recognition which identifies an individual’s voice. Essentially, voice recognition recognizes the speaker, while speech recognition recognizes the words that have been spoken. Voice recognition is often used for security reasons, such as voice biometrics. And speech recognition is implemented to identify spoken words, regardless of who the speaker is.
History of Speech Recognition
You might be surprised that the first speech recognition technology was created in the 1950s. Browsing through the history of the technology gives us interesting insights into how it has evolved, gradually increasing vocabulary size and processing speed.
1952: The first speech recognition software was “Audrey,” developed by Bell Labs, which could recognize spoken numbers from 0 to 9.
1960s: At the Radio Research Lab in Tokyo, Suzuki and Nakata built a machine able to recognize vowels.
1962: The next breakthrough was IBM’s “Shoebox,” which could identify 16 different words.
1976: The “ Harpy ” speech recognition system at Carnegie-Mellon University could understand over 1,000 words.
Mid-1980s: Fred Jelinek's research team developed a voice-activated typewriter, Tangora, with an expanded bandwidth of 20,000 words.
1992: Developed at Bell Labs, AT&T’s Voice Recognition Call Processing service was able to route phone calls without a human operator.
2007: Google started working on its first speech recognition software, which led to the creation of Google Voice Search in 2012.
2010s: Apple’s Siri and Amazon Alexa came into the scene, making speech recognition software easily available to the masses.
How Does Speech Recognition Work?
We’re used to the simplicity of operating a gadget through voice, but we’re usually unaware of the complex processes taking place behind the scenes.
Speech recognition systems incorporate linguistics, mathematics, deep learning, and statistics to process spoken language. The software uses statistical models or neural networks to convert the speech input into word output. The role of natural language processing (NLP) is also significant, as it’s implemented to return relevant text to the given voice command.
Computers go through the following steps to interpret human speech:
- The microphone translates sound vibrations into electrical signals.
- The computer then digitizes the received signals.
- Speech recognition software analyzes digital signals to identify sounds and distinguish phonemes (the smallest units of speech).
- Algorithms match the signals with suitable text that represents the sounds.
This process gets more complicated when you account for background noise, context, accents, slang, cross talk, and other influencing factors. With the application of artificial intelligence and machine learning , speech recognition technology processes voice interactions to improve performance and precision over time.
Speech Recognition Key Features
Here are the key features that enable speech recognition systems to function:
- Language weighting: This feature gives weight to certain words and phrases over others to better respond in a given context. For instance, you can train the software to pay attention to industry or product-specific words.
- Speaker labeling: It labels all speakers in a group conversation to note their individual contributions.
- Profanity filtering: Recognizes and filters inappropriate words to disallow unwanted language.
- Acoustics training: Distinguishes ambient noise, speaker style, pace, and volume to tune out distractions. This feature comes in handy in busy call centers and office spaces.
Speech Recognition Benefits
Speech recognition has various advantages to offer to businesses and individuals alike. Below are just a few of them.
Faster Communication
Communicating through voice rather than typing every individual letter speeds up the process significantly. This is true both for interpersonal and human-to-machine communication. Think about how often you turn to your phone assistant to send a text message or make a call.
Multitasking
Completing actions hands-free gives us the opportunity to handle multiple tasks at once, which is a huge benefit in our busy, fast-paced lives. Voice search , for example, allows us to look up information anytime, anywhere, and even have the assistant read out the text for us.
Aid for Hearing and Visual Impairments
Speech-to-text and text-to-speech systems are of substantial importance to people with visual impairments. Similarly, users with hearing difficulties rely on audio transcription software to understand speech. Tools like Google Meet can even provide captions in different languages by translating the speech in real-time.
Real-Life Applications of Speech Recognition
The practical applications of speech recognition span various industries and areas of life. Speech recognition has become prominent both in personal and business use.
- Technology: Mobile assistants, smart home devices, and self-driving cars have ceased to be sci-fi fantasies thanks to the advancement of speech recognition technology. Apple, Google, Microsoft, Amazon, and many others have succeeded in building powerful software that’s now closely integrated into our daily lives.
- Education: The easy conversion between verbal and written language aids students in learning information in their preferred format. Speech recognition assists with many academic tasks, from planning and completing assignments to practicing new languages.
- Customer Service: Virtual assistants capable of speech recognition can process spoken queries from customers and identify the intent. Hoory is an example of an assistant that converts speech to text and vice versa to listen to user questions and read responses out loud.
Speech Recognition Summarized
Speech recognition allows us to operate and communicate with machines through voice. Behind the scenes, there are complex speech recognition algorithms that enable such interactions. As the algorithms become more sophisticated, we get better software that recognizes various speech patterns, dialects, and even languages.
Faster communication, hands-free operations, and hearing/visual impairment aid are some of the technology's biggest impacts. But there’s much more to expect from speech-activated software, considering the incredible rate at which it keeps growing.
Gnani.ai is now SOC 2 Type II accredited!
assist365 TM
armour365 TM

Speech Recognition AI: What is it and How Does it Work|Gnani

A Beginner’s Guide to Speech Recognition AI
AI speech recognition is a technology that allows computers and applications to understand human speech data . It is a feature that has been around for decades, but it has increased in accuracy and sophistication in recent years.
Speech recognition works by using artificial intelligence to recognize the words or language that a person speaks and then translate that content into text. It’s important to note that this technology is still in its infancy but is improving its accuracy rapidly.
What is Speech Recognition AI?
Speech recognition enables computers , applications and software to comprehend and translate human speech data into text for business solutions . The speech recognition model works by using artificial intelligence (AI) to analyze your voice and language , identify by learning the words you are saying, and then output those words with transcription accuracy as model content or text data on a screen.
Speech Recognition in AI
Speech recognition is a significant part of artificial intelligence (AI) applications . AI is a machine’s ability to mimic human behaviour by learning from its environment. Speech recognition enables computers and software applications to “understand” what people are saying, which allows them to process information faster and with high accuracy. Speech recognition is also used as models in voice assistants like Siri and Alexa, which allow users to interact with computers using natural transcription language data or content .
Thanks to recent advancements, speech recognition technology is now more precise and widely used than in the past. It is used in various fields, including healthcare, customer service, education, and entertainment. However, there are still challenges to overcome, such as better handling of accents and dialects and the difficulty of recognizing speech in noisy environments. Despite these challenges, speech recognition is an exciting area of artificial intelligence with great potential for future development.
How Does Speech Recognition AI Work?
Speech recognition or voice recognition is a complex process that involves audio accuracy over several steps and data or language solutions , including:
- Recognizing the words , models and content in the user’s speech or audio . This business accuracy step requires training the model to identify each word in your vocabulary or audio cloud .
- Converting those audios and language into text. This step involves converting recognized audios i nto letters or numbers (called phonemes) so that other parts of the AI software solutions system can process th ose models .
- Determining what was said. Next, AI looks at which content and words were spoken most often and how frequently they were used together to determine their meaning (this process is known as “predictive modelling”).
- Parsing out commands from the rest of your speech or audio content (also known as disambiguation).
Speech Recognition AI and Natural Language Processing
Natural Language Processing is a part of artificial intelligence that involves analyzing data related to natural language and converting it into a machine- comprehendible format. Speech recognition and AI play a pivotal role in NLPs in improving the accuracy and efficiency of human language recognition.
A lot of businesses now include speech-to-text software or speech recognition AI to enhance their business applications and improve customer experience. By using speech recognition AI and natural language processing together, companies can transcribe calls, meetings etc. Giant companies like Apple, Google, and Amazon are leveraging AI-based speech or voice recognition applications to provide a flawless customer experience.
Use Cases of Speech Recognition AI
Speech recognition AI is being used as business solutions in many industries and applications . From ATMs to call centers and voice-activated audio content assistants, AI is helping people interact with technology and software more naturally with better data transcription accuracy than ever before.
Call Centers
Speech recognition is one of the most popular uses of speech AI in call centers. This technology allows you to listen to what customers are saying and then use that information via cloud models to respond appropriately.
You can also use speech recognition technology for voice or audio biometrics, which means using voice patterns as proof of identity or authorization for access solutions or services without relying on passwords or other traditional methods or models like fingerprints or eye scans. This can eliminate business issues like forgotten passwords or compromised security codes in favor of something more secure: your voice!
Banking and financial institutions are using speech AI applications to help customers with their business queries. For example, you can ask a bank about your account balance or the current interest rate on your savings account. This cuts down on the time it takes for customer service representatives to answer questions they would typically have to research and look at cloud data , which means quicker response times and better customer service.
Telecommunications
Speech-enabled AI is a technology that’s gaining traction in the telecommunications industry. Speech recognition technology models enable calls to be analyzed and managed more efficiently. This allows agents to focus on their highest-value tasks to deliver better customer service.
Customers can now interact with businesses in real-time 24/7 via voice transcription solutions or text messaging applications , which makes them feel more connected with the company and improves their overall experience.
Speech AI is a learning technology used in many different areas as transcription solutions . Healthcare is one of the most important, as it can help doctors and nurses care for their patients better. Voice-activated devices use learning models that allow patients to communicate with doctors, nurses, and other healthcare professionals without using their hands or typing on a keyboard.
Doctors can use speech recognition AI via cloud data to help patients understand their feelings and why they feel that way. It’s much easier than having them read through a brochure or pamphlet—and it’s more engaging. Speech AI can also take down patient histories and help with medical transcriptions.
Media and Marketing
Tools such as dictation software use speech recognition and AI to help users type or write more in much less time. Roughly speaking, copywriters and content writers can transcribe as much as 3000-4000 words in as less as half an hour on an average.
Accuracy, though, is a factor. These tools don’t guarantee 100% foolproof transcription. Still, they are extremely beneficial in helping media and marketing people in composing their first drafts.
Challenges in Working with Speech Recognition AI
There are many challenges in working with speech AI. For example, both technology and cloud are new and developing rapidly. As a result, it isn’t easy to make accurate predictions about how long it will take for a company to build its speech-enabled product.
Another challenge with speech AI is getting the right tools to analyze your data. Most people need access to this technology or cloud , so finding the right tool for your requirements may take time and effort.
You must use the correct language and syntax when creating your algorithms on cloud . This can be difficult because it requires understanding how computers and humans communicate. Speech recognition still needs improvement, and it can be difficult for computers to understand every word you say.
If you use speech recognition software, you will need to train it on your voice before it can understand what you’re saying. This can take a long time and requires careful study of how your voice sounds different from other people’s.
The other concern is that there are privacy laws surrounding medical records. These laws vary from state to state, so you’ll need to check with your jurisdiction before implementing speech AI technology.
Educating your staff on the technology and how it works is important if you decide to use speech AI. This will help them understand what they’re recording and why they’re recording it.
Frequently Asked Questions
How does speech recognition work.
Speech recognition AI is the process of converting spoken language into text. The technology uses machine learning and neural networks to process audio data and convert it into words that can be used in businesses.
What is the purpose of speech recognition AI ?
Speech recognition AI can be used for various purposes, including dictation and transcription. The technology is also used in voice assistants like Siri and Alexa.
What is speech communication in AI?
Speech communication is using speech recognition and speech synthesis to communicate with a computer. Speech recognition can allow users to dictate text into a program, saving time compared to typing it out. Speech synthesis is used for chatbots and voice assistants like Siri and Alexa.
Which type of AI is used in speech recognition?
AI and machine learning are used in advanced speech recognition software, which processes speech through grammar, structure, and syntax.
What are the difficulties in voice recognition AI in artificial intelligence?
Related news, conversational voice ai for debt collection: unlocking new opportunities, why choose voice biometrics over passwords in the banking industry, armour365: highly secure & language independent voice authentication, why voice biometrics is becoming the leading choice for authentication, how can businesses utilize conversational ai to scale rapidly, trends in digital banking cx & the future of digital banking with voice ai, how conversational ai can reduce banking operational costs & improve customer-centric service, how conversational ai can help grow and retain customers in retail banking, top five factual conversational ai in insurance and banking use cases, voice biometrics in banking, how voice biometrics authentication method works | gnani, technology in banking: how ai can help prevent npas| gnani, comment (1), the power of natural language processing software.
[…] various applications such as machine translation, text summarization, text categorization, and speech recognition. Its utilization enables organizations to derive valuable insights from textual data, leading to […]
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
Recent Posts
- The Science Behind Chatbots: Exploring NLP
- Unravelling the Intricate Web of Biases in LLMs
- Linguistic Diversity in Conversational AI Models
- Conversational AI Transformation in Enterprises
- Driving Automotive Sales Through Generative AI
- Agent Assist 7
- Artificial Intelligence 68
- Automotive Industry 4
- Banking and Insurance 11
- Bot Builder 7
- Business Hacks 21
- Contact Center Automation 24
- Conversational AI 93
- Conversational Marketing 1
- Conversational UI 1
- Customer Experience 3
- Customer Service Automation 25
- customer service platform 9
- Ethics in AI 1
- Generative artificial intelligence 28
- Healthcare 5
- information security 1
- Natural Language Understanding 9
- News & Announcements 6
- News Roundup 2
- Omnichannel Analytics 13
- Omnichannel Strategies 6
- Research Papers 1
- security compliance 1
- Speech Recognition 4
- Speech To Text 3
- Text To Speech 4
- Uncategorized 4
- Voice Biometrics 16
- voice bots 2
- voice chatbots 1
- Voice Technology 8
Looking to partner with us?
Please fill the form given below and we will contact you as soon as possible.
Ultimate Guide To Speech Recognition Technology (2023)
- April 12, 2023
SpeakWrite Blog
Learn about speech recognition technology—how speech to text software works, benefits, limitations, transcriptions, and other real world applications..

Whether you’re a professional in need of more efficient transcription solutions or simply want your voice-enabled device to work smarter for you, this guide to speech recognition technology is here with all the answers.
Few technologies have evolved rapidly in recent years as speech recognition. In just the last decade, speech recognition has become something we rely on daily. From voice texting to Amazon Alexa understanding natural language queries, it’s hard to imagine life without speech recognition software.
But before deep learning was ever a word people knew, mid-century were engineers paving the path for today’s rapidly advancing world of automatic speech recognition. So let’s take a look at how speech recognition technologies evolved and speech-to-text became king.
What Is Speech Recognition Technology?
With machine intelligence and deep learning advances, speech recognition technology has become increasingly popular. Simply put, speech recognition technology (otherwise known as speech-to-text or automatic speech recognition) is software that can convert the sound waves of spoken human language into readable text. These programs match sounds to word sequences through a series of steps that include:
- Pre-processing: may consist of efforts to improve the audio of speech input by reducing and filtering the noise to reduce the error rate
- Feature extraction: this is the part where sound waves and acoustic signals are transformed into digital signals for processing using specialized speech technologies.
- Classification: extracted features are used to find spoken text; machine learning features can refine this process.
- Language modeling: considers important semantic and grammatical rules of a language while creating text.
How Does Speech Recognition Technology Work?
Speech recognition technology combines complex algorithms and language models to produce word output humans can understand. Features such as frequency, pitch, and loudness can then be used to recognize spoken words and phrases.
Here are some of the most common models for speech recognition, which include acoustic models and language models . Sometimes, several of these are interconnected and work together to create higher-quality speech recognition software and applications.
Natural Language Processing (NLP)
“Hey, Siri, how does speech-to-text work?”
Try it—you’ll likely hear your digital assistant read a sentence or two from a relevant article she finds online, all thanks to the magic of natural language processing.
Natural language processing is the artificial intelligence that gives machines like Siri the ability to understand and answer human questions. These AI systems enable devices to understand what humans are saying, including everything from intent to parts of speech.
But NLP is used by more than just digital assistants like Siri or Alexa—it’s how your inbox knows which spam messages to filter, how search engines know which websites to offer in response to a query, and how your phone knows which words to autocomplete.
Neural Networks
Neural networks are one of the most powerful AI applications in speech recognition. They’re used to recognize patterns and process large amounts of data quickly.
For example, neural networks can learn from past input to better understand what words or phrases you might use in a conversation. It uses those patterns to more accurately detect the words you’re saying.
Leveraging cutting-edge deep learning algorithms, neural networks are revolutionizing how machines recognize speech commands. By imitating neurons in our brains and creating intricate webs of electrochemical connections between them, these robust architectures can process data with unparalleled accuracy for various applications such as automatic speech recognition.
Hidden Markov Models (HMM)
The Hidden Markov Model is a powerful tool for acoustic modeling, providing strong analytical capabilities to accurately detect natural speech. Its application in the field of Natural Language Processing has allowed researchers to efficiently train machines on word generation tasks, acoustics, and syntax to create unified probabilistic models.
Speaker Diarization
Speaker diarization is an innovative process that segments audio streams into distinguishable speakers, allowing the automatic speech recognition transcript to organize each speaker’s contributions separately. Using unique sound qualities and word patterns, this technique pinpoints conversations accurately so every voice can be heard.
The History of Speech Recognition Technology
It’s hard to believe that just a few short decades ago, the idea of having a computer respond to speech felt like something straight out of science fiction. Yet, Fast-forward to today, and voice-recognition technology has gone from being an obscure concept to becoming so commonplace you can find it in our smartphones.
But where did this all start? First, let’s take a look at the history of speech recognition technology – from its uncertain early days through its evolution into today’s easy-to-use technology.
Speech recognition technology has existed since the 1950s when Bell Laboratory researchers first developed systems to recognize simple commands . However, early speech recognition systems were limited in their capabilities and could not identify more complex phrases or sentences.
In the 1980s, advances in computing power enabled the development of better speech recognition systems that could understand entire sentences. Today, speech recognition technology has become much more advanced, with some systems able to recognize multiple languages and dialects with high accuracy.
Timeline of Speech Recognition Programs
- 1952 – Bell Labs researchers created “Audrey,” an innovative system for recognizing individual digits. Early speech recognition systems were limited in their capabilities and could not identify more complex phrases or sentences.
- 1962 – IBM shook the tech sphere in 1962 at The World’s Fair, showcasing a remarkable 16-word speech recognition capability – nicknamed “Shoebox” —that left onlookers awestruck.
- 1980s – IBM revolutionized the typewriting industry in the 1980s with Tangora , a voice-activated system that could understand up to 20,000 words. Advances in computing power enabled the development of better speech recognition systems that could understand entire sentences.
- 1996 – IBM’s VoiceType Simply Speaking application recognized 42,000 English and Spanish words.
- 2007 – Google launched GOOG-411 as a telephone directory service, an endeavor that provided immense amounts of data for improving speech recognition systems over time. Now, this technology is available across 30 languages through Google Voice Search .
- 2017 – Microsoft made history when its research team achieved the remarkable goal of transcribing phone conversations utilizing various deep-learning models.
How is Speech Recognition Used Today?
Speech recognition technology has come a long way since its inception at Bell Laboratories.
Today, speech recognition technology has become much more advanced, with some systems able to recognize multiple languages and dialects with high accuracy and low error rates.
Speech recognition technology is used in a wide range of applications in our daily lives, including:
- Voice Texting: Voice texting is a popular feature on many smartphones that allow users to compose text messages without typing.
- Smart Home Automation: Smart home systems use voice commands technology to control lights, thermostats, and other household appliances with simple commands.
- Voice Search: Voice search is one of the most popular applications of speech recognition, as it allows users to quickly
- Transcription: Speech recognition technology can transcribe spoken words into text fast.
- Military and Civilian Vehicle Systems: Speech recognition technology can be used to control unmanned aerial vehicles, military drones, and other autonomous vehicles.
- Medical Documentation: Speech recognition technology is used to quickly and accurately transcribe medical notes, making it easier for doctors to document patient visits.
Key Features of Advanced Speech Recognition Programs
If you’re looking for speech recognition technology with exceptional accuracy that can do more than transcribe phonetic sounds, be sure it includes these features.
Acoustic training
Advanced speech recognition programs use acoustic training models to detect natural language patterns and better understand the speaker’s intent. In addition, acoustic training can teach AI systems to tune out ambient noise, such as the background noise of other voices.
Speaker labeling
Speaker labeling is a feature that allows speech recognition systems to differentiate between multiple speakers, even if they are speaking in the same language. This technology can help keep track of who said what during meetings and conferences, eliminating the need for manual transcription.
Dictionary customization
Advanced speech recognition programs allow users to customize their own dictionaries and include specialized terminology to improve accuracy. This can be especially useful for medical professionals who need accurate documentation of patient visits.
If you don’t want your transcript to include any naughty words, then you’ll want to make sure your speech recognition system consists of a filtering feature. Filtering allows users to specify which words should be filtered out of their transcripts, ensuring that they are clean and professional.
Language weighting
Language weighting is a feature used by advanced speech recognition systems to prioritize certain commonly used words over others. For example, this feature can be helpful when there are two similar words, such as “form” and “from,” so the system knows which one is being spoken.
The Benefits of Speech Recognition Technology
Human speech recognition technology has revolutionized how people navigate, purchase, and communicate. Additionally, speech-to-text technology provides a vital bridge to communication for individuals with sight and auditory disabilities. Innovations like screen readers, text-to-speech dictation systems, and audio transcriptions help make the world more accessible to those who need it most.
Limits of Speech Recognition Programs
Despite its advantages, speech recognition technology still needs to be improved.
- Accuracy rate and reliability – the quality of the audio signal and the complexity of the language being spoken can significantly impact the system’s ability to accurately interpret spoken words. For now, speech-to-text technology has a higher average error rate than humans.
- Formatting – Exporting speech recognition results into a readable format, such as Word or Excel, can be difficult and time-consuming—especially if you must adhere to professional formatting standards.
- Ambient noise – Speech recognition systems are still incapable of reliably recognizing speech in noisy environments. If you plan on recording yourself and turning it into a transcript later, make sure the environment is quiet and free from distractions.
- Translation – Human speech and language are difficult to translate word for word, as things like syntax, context, and cultural differences can lead to subtle meanings that are lost in direct speech-to-text translations.
- Security – While speech recognition systems are great for controlling devices, you don’t always have control over how your data is stored and used once recorded.
Using Speech Recognition for Transcriptions
Speech recognition technology is commonly used to transcribe audio recordings into text documents and has become a standard tool in business and law enforcement. There are handy apps like Otter.ai that can help you quickly and accurately transcribe and summarize meetings and speech-to-text features embedded in document processors like Word.
However, you should use speech recognition technology for transcriptions with caution because there are a number of limitations that could lead to costly mistakes.
If you’re creating an important legal document or professional transcription , relying on speech recognition technology or any artificial intelligence to provide accurate results is not recommended. Instead, it’s best to employ a professional transcription service or hire an experienced typist to accurately transcribe audio recordings.
Human typists have an accuracy level of 99% – 100%, can follow dictation instructions, and can format your transcript appropriately depending on your instructions. As a result, there is no need for additional editing once your document is delivered (usually in 3 hours or less), and you can put your document to use immediately.
Unfortunately, speech recognition technology can’t achieve these things yet. You can expect an accuracy of up to 80% and little to no professional formatting. Additionally, your dictation instructions will fall on deaf “ears.” Frustratingly, they’ll just be included in the transcription rather than followed to a T. You’ll wind up spending extra time editing your transcript for readability, accuracy, and professionalism.
So if you’re looking for dependable, accurate, fast transcriptions, consider human transcription services instead.
Frequently Asked Questions
Is speech recognition technology accurate.
The accuracy of speech recognition technology depends on several factors, including the quality of the audio signal, the complexity of the language being spoken, and the specific algorithms used by the system.
Some speech recognition software can withstand poor acoustic quality, identify multiple speakers, understand accents, and even learn industry jargon. Others are more rudimentary and may have limited vocabulary or may only be able to work with pristine audio quality.
Speaker identification vs. speech recognition: What’s the difference?
The two are often used interchangeably. However, there is a distinction. Speech recognition technology shouldn’t be confused with speech identification technology, which identifies who is speaking rather than what the speaker has to say.
What type of technology is speech recognition?
Speech recognition is a type of technology that allows computers to understand and interpret spoken words. It is a form of artificial intelligence (AI) that uses algorithms to recognize patterns in audio signals, such as the sound of speech. Speech recognition technology has been around for decades.
Is speech recognition AI technology?
Yes, speech recognition is a form of artificial intelligence (AI) that uses algorithms to recognize patterns in audio signals, such as the sound of speech. Speech recognition technology has been around for decades, but it wasn’t until recently that systems became sophisticated enough to accurately understand and interpret spoken words.
What are examples of speech recognition devices?
Examples of speech recognition devices include virtual assistants such as Amazon Alexa, Google Assistant, and Apple Siri. Additionally, many mobile phones and computers now come with built-in voice recognition software that can be used to control the device or issue commands. Speech recognition technology is also used in various other applications, such as automated customer service systems, medical transcription software, and real-time language translation systems.
See How Much Your Business Could Be Saving in Transcription Costs
With accurate transcriptions produced faster than ever before, using human transcription services could be an excellent decision for your business. Not convinced? See for yourself!
Try our cost savings calculator today and see how much your business could save in transcription costs.

Explore FAQs
Find answers to your questions about SpeakWrite.
Discover Blogs
Learn how SpeakWrite can help you!
Get Support
Get the online help you're looking for.

How Does Voice Recognition Work?

Your changes have been saved
Email is sent
Email has already been sent
Please verify your email address.
You’ve reached your account maximum for followed topics.
GPT-4 vs. GPT-4o vs. GPT-4o Mini: What's the Difference?
This new browser is a productivity miracle, how often should you upgrade your gpu.
Sometimes, we find ourselves speaking to our digital devices more than other people. The digital assistants on our devices use voice recognition to understand what we're saying. Because of this, we're able to manage many aspects of our lives just by having a conversation with our phone or smart speaker.
Even though voice recognition is such a large part of our lives, we don't usually think about what makes it work. A lot goes on behind the scenes with voice recognition, so here's a dive into what makes it work.
What Is Voice Recognition?
Modern devices usually come loaded with a digital assistant, a program that uses voice recognition to carry out certain tasks on your device. Voice recognition is a set of algorithms that the assistants use to convert your speech into a digital signal and ascertain what you're saying. Programs like Microsoft Word use voice recognition to help type down words.

The First Voice Recognition System
The first voice recognition system was called the Audrey system. The name was a contraction of "Automated Digit Recognition." Invented in 1952 by Bell Laboratories, Audrey was able to recognize numerical digits. The speaker would say a number, and Audrey would light up one of 10 corresponding lightbulbs.
As groundbreaking as this invention was, it wasn't well received. The computer system itself stood about six feet tall and took up a massive amount of space. Regardless of its size, it could only decipher numbers 0-9. Also, only a person with a specific type of voice could use Audrey, so it was manned primarily by one person.
While it had its faults, Audrey was the first step in a long journey to make voice recognition what it is today. It didn't take long before the next voice recognition system arose, which could understand sequences of words.
Related: How to Lock/Unlock an Android Phone With Your Voice Using Google Assistant
Voice Recognition Begins With Converting the Audio Into a Digital Signal
Voice recognition systems have to go through certain steps to figure out what we're saying. When your device's microphone picks up your audio, it's converted into an electrical current which travels down to the Analog to Digital Converter (ADC). As the name suggests, the ADC converts the electric current (AKA, the analog signal) into a digital binary signal.
As the current flows to the ADC, it takes samples of the current and deciphers its voltage at certain points in time. The voltage at a given point in time is called a sample. Each sample is only several thousandths of a second long. Based on the sample's voltage, the ADC will assign a series of eight binary digits (one byte of data).

The Audio Is Processed for Clarity
In order for the device to better understand the speaker, the audio needs to be processed to improve clarity. The device is sometimes tasked with deciphering speech in a noisy environment; thus, certain filters are placed on the audio to help eliminate background noise. For some voice recognition systems, frequencies that are higher and lower than the human's hearing range are filtered out.
The system doesn't only get rid of unwanted frequencies; certain frequencies in the audio are also emphasized so that the computer can better recognize the voice and separate it from background noise. Some voice recognition systems actually split the audio up into several discrete frequencies.
Related: How to Teach Google Assistant to Pronounce Your Name Correctly
Other aspects, such as the speed and volume of the audio, are adjusted to better match the references audio samples that the voice recognition system uses to compare. These filtration and denoising processes really help improve the overall accuracy.
The Voice Recognition System Then Starts Making Words
There are two popular ways that voice recognition systems analyze speech. One is called the hidden Markov model, and the other method is through neural networks.
The Hidden Markov Model Method
The hidden Markov model is the method employed in most voice recognition systems. An important part of this process is breaking down the spoken words into their phonemes (the smallest element of a language). There's a finite number of phonemes in each language, which is why the hidden Markov model method works so well.
There are around 40 phonemes in the English language. When the voice recognition system identifies one, it determines the probability of what the next one will be.
For example, if the speaker utters the sound "ta," there's a certain probability that the next phoneme will be "p" to form the word "tap." There's also the probability that the next phoneme will be "s," but that's far less likely. If the next phoneme does resemble "p," then the system can assume with high certainty that the word is "tap."

The Neural Network Method
A neural network is like a digital brain that learns much in the same way that a human brain does. Neural networks are instrumental in the progress of artificial intelligence and deep learning.
The type of neural network that voice recognition uses is called a Recurrent Neural Network (RNN). According to GeeksforGeeks , RNN is one where the "output from [the] previous step[s] are fed as input to the current step." This means that when an RNN processes a bit of data, it uses that data to influence what it does with the next bit of data— it essentially learns from experience.
The more an RNN is exposed to a certain language, the more accurate the voice recognition will be. If the system identifies the "ta" sound 100 times, and it's followed by the "p" sound 90 of those times, then the network can basically learn that "p" typically comes after "ta."
Because of this, when the voice recognition system identifies a phoneme, it uses the accrued data to predict which one will likely come next. Because RNNs continuously learn, the more it's used, the more accurate the voice recognition will be.
After the voice recognition system identifies the words (whether with the hidden Marvok model or with an RNN), that information is sent to the processor. The system then carries out the task that it's meant to do.
Voice Recognition Has Become a Staple in Modern Technology
Voice recognition has become a huge part of our modern technological landscape. It's been implemented into several industries and services worldwide; indeed, many people control their entire lives with voice-activated assistants. You can find assistants like Siri loaded onto your Apple watches. What was only a dream back in 1952 has become a reality, and it doesn't seem to be stopping anytime soon.
- Technology Explained
- Voice Commands
- Speech Recognition
- Tips & Tricks
- Website & Apps
- ChatGPT Blogs
- ChatGPT News
- ChatGPT Tutorial
What is Speech Recognition?
Speech recognition or speech-to-text recognition , is the capacity of a machine or program to recognize spoken words and transform them into text. Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. In this article, we are going to explore how speech recognition software work, speech recognition algorithms, and the role of NLP. See examples of how this technology is used in everyday life and various industries, making interactions with devices smarter and more intuitive.
Speech Recognition , also known as automatic speech recognition ( ASR ), computer speech recognition, or speech-to-text, focuses on enabling computers to understand and interpret human speech. Speech recognition involves converting spoken language into text or executing commands based on the recognized words. This technology relies on sophisticated algorithms and machine learning models to process and understand human speech in real-time , despite the variations in accents , pitch , speed , and slang .
Key Features of Speech Recognition
- Accuracy and Speed: They can process speech in real-time or near real-time, providing quick responses to user inputs.
- Natural Language Understanding (NLU): NLU enables systems to handle complex commands and queries , making technology more intuitive and user-friendly .
- Multi-Language Support: Support for multiple languages and dialects , allowing users from different linguistic backgrounds to interact with technology in their native language.
- Background Noise Handling: This feature is crucial for voice-activated systems used in public or outdoor settings.
Speech Recognition Algorithms
Speech recognition technology relies on complex algorithms to translate spoken language into text or commands that computers can understand and act upon. Here are the algorithms and approaches used in speech recognition:
1. Hidden Markov Models (HMM)
Hidden Markov Models have been the backbone of speech recognition for many years. They model speech as a sequence of states, with each state representing a phoneme (basic unit of sound) or group of phonemes. HMMs are used to estimate the probability of a given sequence of sounds, making it possible to determine the most likely words spoken. Usage : Although newer methods have surpassed HMM in performance, it remains a fundamental concept in speech recognition, often used in combination with other techniques.
2. Natural language processing (NLP)
NLP is the area of artificial intelligence which focuses on the interaction between humans and machines through language through speech and text. Many mobile devices incorporate speech recognition into their systems to conduct voice search. Example such as : Siri or provide more accessibility around texting.
3. Deep Neural Networks (DNN)
DNNs have improved speech recognition’s accuracy a lot. These networks can learn hierarchical representations of data, making them particularly effective at modeling complex patterns like those found in human speech. DNNs are used both for acoustic modeling , to better understand the sound of speech , and for language modeling, to predict the likelihood of certain word sequences.
4. End-to-End Deep Learning
Now, the trend has shifted towards end-to-end deep learning models , which can directly map speech inputs to text outputs without the need for intermediate phonetic representations. These models, often based on advanced RNNs , Transformers, or Attention Mechanisms , can learn more complex patterns and dependencies in the speech signal.
What is Automatic Speech Recognition?
Automatic Speech Recognition (ASR) is a technology that enables computers to understand and transcribe spoken language into text. It works by analyzing audio input, such as spoken words, and converting them into written text , typically in real-time. ASR systems use algorithms and machine learning techniques to recognize and interpret speech patterns , phonemes, and language models to accurately transcribe spoken words. This technology is widely used in various applications, including virtual assistants , voice-controlled devices , dictation software , customer service automation , and language translation services .
What is Dragon speech recognition software?
Dragon speech recognition software is a program developed by Nuance Communications that allows users to dictate text and control their computer using voice commands. It transcribes spoken words into written text in real-time , enabling hands-free operation of computers and devices. Dragon software is widely used for various purposes, including dictating documents , composing emails , navigating the web , and controlling applications . It also features advanced capabilities such as voice commands for editing and formatting text , as well as custom vocabulary and voice profiles for improved accuracy and personalization.
What is a normal speech recognition threshold?
The normal speech recognition threshold refers to the level of sound, typically measured in decibels (dB) , at which a person can accurately recognize speech. In quiet environments, this threshold is typically around 0 to 10 dB for individuals with normal hearing. However, in noisy environments or for individuals with hearing impairments , the threshold may be higher, meaning they require a louder volume to accurately recognize speech .
Uses of Speech Recognition
- Virtual Assistants: These are like digital helpers that understand what you say. They can do things like set reminders, search the internet, and control smart home devices, all without you having to touch anything. Examples include Siri , Alexa , and Google Assistant .
- Accessibility Tools: Speech recognition makes technology easier to use for people with disabilities. Features like voice control on phones and computers help them interact with devices more easily. There are also special apps for people with disabilities.
- Automotive Systems: In cars, you can use your voice to control things like navigation and music. This helps drivers stay focused and safe on the road. Examples include voice-activated navigation systems in cars.
- Healthcare: Doctors use speech recognition to quickly write down notes about patients, so they have more time to spend with them. There are also voice-controlled bots that help with patient care. For example, doctors use dictation tools to write down patient information quickly.
- Customer Service: Speech recognition is used to direct customer calls to the right place or provide automated help. This makes things run smoother and keeps customers happy. Examples include call centers that you can talk to and customer service bots .
- Education and E-Learning: Speech recognition helps people learn languages by giving them feedback on their pronunciation. It also transcribes lectures, making them easier to understand. Examples include language learning apps and lecture transcribing services.
- Security and Authentication: Voice recognition, combined with biometrics , keeps things secure by making sure it’s really you accessing your stuff. This is used in banking and for secure facilities. For example, some banks use your voice to make sure it’s really you logging in.
- Entertainment and Media: Voice recognition helps you find stuff to watch or listen to by just talking. This makes it easier to use things like TV and music services . There are also games you can play using just your voice.
Speech recognition is a powerful technology that lets computers understand and process human speech. It’s used everywhere, from asking your smartphone for directions to controlling your smart home devices with just your voice. This tech makes life easier by helping with tasks without needing to type or press buttons, making gadgets like virtual assistants more helpful. It’s also super important for making tech accessible to everyone, including those who might have a hard time using keyboards or screens. As we keep finding new ways to use speech recognition, it’s becoming a big part of our daily tech life, showing just how much we can do when we talk to our devices.
What is Speech Recognition?- FAQs
What are examples of speech recognition.
Note Taking/Writing: An example of speech recognition technology in use is speech-to-text platforms such as Speechmatics or Google’s speech-to-text engine. In addition, many voice assistants offer speech-to-text translation.
Is speech recognition secure?
Security concerns related to speech recognition primarily involve the privacy and protection of audio data collected and processed by speech recognition systems. Ensuring secure data transmission, storage, and processing is essential to address these concerns.
Is speech recognition and voice recognition same?
No, speech recognition and voice recognition are different. Speech recognition converts spoken words into text using NLP, focusing on the content of speech. Voice recognition, however, identifies the speaker based on vocal characteristics, emphasizing security and personalization without interpreting the speech’s content.
What is speech recognition in AI?
Speech recognition is the process of converting sound signals to text transcriptions. Steps involved in conversion of a sound wave to text transcription in a speech recognition system are: Recording: Audio is recorded using a voice recorder. Sampling: Continuous audio wave is converted to discrete values.
What are the type of Speech Recognition?
Dictation Systems: Convert speech to text. Voice Command Systems: Execute spoken commands. Speaker-Dependent Systems: Trained for specific users. Speaker-Independent Systems: Work for any user. Continuous Speech Recognition: Allows natural, flowing speech. Discrete Speech Recognition: Requires pauses between words. NLP-Integrated Systems: Understand context and meaning
How accurate is speech recognition technology?
The accuracy of speech recognition technology can vary depending on factors such as the quality of audio input , language complexity , and the specific application or system being used. Advances in machine learning and deep learning have improved accuracy significantly in recent years.
Please Login to comment...
Similar reads.
- Computer Networks
- Computer Subject
- tech-updates
Improve your Coding Skills with Practice
What kind of Experience do you want to share?

Voice Control
Command your products, devices, software, and applications.

Voice Dictation
Voice Dictation recognizes and transcribes spoken language into punctuated text.

Voice Synthesis
Voice Synthesis allows you to get instant audio feedback from devices.

Voice Biometrics
Voice Biometrics allows you to authenticate and identify users.

Speech Enhancement
Enhancing voice quality and facilitating smoother operation of voice-activated systems in professional noisy environments.

A word or a phrase that switches your device from standby to active listening mode.
Discover all our solutions

Allows users to trigger the speech recognition process.

Automatic Speech Recognition (ASR)
Transform human voice into text even with complex vocabulary.

Identify and/or authenticate users using a Voice Print.

Natural Language Understanding (NLU)
Enable users with flexible and natural voice commands.

Speech Synthesis (TTS)
Produce life-like voices able to humanize products and give audio feedback.

Audio Enhancement (AFE)
Make sure that the sound signal from voice is crystal clear to boost recognition’s accuracy.
Discover the Voice Development Kit
Smart Glasses & XR Wearables
Voice-enabled smart glasses & head-mounted displays…
Supply Chain & Industry 4.0
Productivity-oriented solutions like Voice Picking…
Field Services & Maintenance (MRO)
Using voice to fill maintenance and intervention reports…
Explore all the use cases
Why choose the VDK ?
Buidling Voice AIs with the VDK is nothing like other solutions, here’s why.
Documentation
Everything you need to know about the VDK in order to get started in the best possible way.
Start developing
Newsroom & Press
Learn more about Vivoka
Speech Recognition: How it works and what it is made of

Written by Aurélien Chapuzet
Discover | speech recognition, why voice data may no longer be centric in ai, natural language understanding: what you need to know before diving in, voice picking: still a relevant solution for supply chain.
Currently, we are in an era governed by cognitive technologies where we find for instance virtual or augmented reality, visual recognition and speech recognition!
However, even if the “Voice Generation” are the most apt to conceptualize this technology because they are born in the middle of its expansion, many people talk about it, but few really know how it works and what solutions are available.
And it is for this very reason that we propose you to discover speech recognition in detail through this article. Of course, this is just the basics to understand the field of speech technologies, other articles in our blog cover some topics in more detail.
“Strength in numbers”: the components of speech recognition
For the following explanations, we assume that “speech recognition” corresponds to a complete cycle of voice use.
Speech recognition is based on the complementarity between several technologies from the same field. To present all this, we will detail each of them chronologically, from the moment the individual speaks, until the order is carried out.
It should be noted that the technologies presented below can be used independently of each other and cover a wide range of applications. We will come back to this later.
The wake word, activate speech recognition, with voice
The first step that initiates the whole process is called the wake word. The main purpose of this first technology in the cycle is to activate the user’s voice to detect the voice command he or she wishes to perform.
Here, it is literally a matter of “waking up” the system. Although there are other ways of proceeding to trigger the listening, keeping the use of the voice throughout the cycle is, in our opinion, essential. Indeed, it allows us to propose a linear experience with voice as the only interface.
The trigger keyword inherently has several interests with respect to the design of voice assistants .
In our context, one of the main fears about speech recognition is the protection of personal data related to audio recording. With the recent appearance of the GDPR (General Data Protection Regulation) , this fear regarding privacy and intimacy has been further amplified, leading to the creation of a treaty to regulate it.
This is why the trigger word is so important. By conditioning the voice recording phase with this action, as long as the trigger word has not been clearly identified, nothing is recorded theoretically. Yes, theoretically, because depending on the company’s data policy, everything is relative. To prevent this, embedded (offline) speech recognition is an alternative.
Once the activation is confirmed, only the sentences carrying the intent of the action to be performed will be recorded and analyzed to ensure the use case works.
To learn more about the Wake-up Word, we invite you to read our article on Google’s Wake-up Word and the best practices to find your own!
Speech to Text (STT) , identifying and transcribing voice into text
Once speech recognition is initiated with the trigger word, it is necessary to exploit the voice. To do this, it is first essential to record and digitize it with Speech to Text technology (also known as automatic speech recognition ).
During this stage, the voice is captured in sound frequencies (in the form of audio files, like music or any other noise) that can be used later.
Depending on the listening environment, sound pollution may or may not be present. In order to improve the recording of these frequencies and therefore their reliability, different treatments can be applied.
- Normalization to remove peaks and valleys in the frequencies in order to harmonize the whole.
- The removal of background noise to improve audio quality.
- The cutting of segments into phonemes (which are distinctive units within frequencies, expressed in thousandths of a second, allowing words to be distinguished from one another.
The frequencies, once recorded, can be analyzed in order to associate each phoneme with a word or a group of words to constitute a text. This step can be done in different ways, but one method in particular is the state of the art today: Machine Learning.
A sub-part of this technology is called Deep Learning: an algorithm recreating a neural network, capable of analyzing a large amount of information and building a database listing the associations between frequencies and words. Thus, each association will create a neuron that will be used to deduce new correspondences.
Therefore, the more information there is, the more precise the model is statistically speaking and capable of taking into account the general context to assign the best word according to the others already defined.
Limiting STT errors is essential to obtain the most reliable information to proceed with the next steps.
NLP (Natural Language Processing), translating human language into machine language
Once the previous steps have been completed, the textual data is sent directly to the NLP (Natural Language Processing) module. The main purpose of this technology is to analyze the sentence and extract a maximum of linguistic data.
To do this, it starts by associating tags to the words of the sentence, this is called tokenization. These are actually “tags” that are applied to each word in order to characterize it. For example, “Open” will be defined as the verb defining an action, “the” as the determinant referring to “ Voice Development Kit ” which is a proper noun but also a COD etc… and this for each element of the sentence.
Once these first elements have been identified, it is necessary to give meaning to the orders resulting from the speech recognition. This is why two complementary analyses are performed.
First of all, syntactic analysis aims to model the structure of the sentence. It is a question here of identifying the place of the words within the whole but also their relative position compared to the others in order to understand their relations.
To complete and finish, the semantic analysis which, once the nature and the position of the words are found, will try to understand their meaning individually but also when they are assembled in the sentence in order to translate a general intention of the user.
The importance of NLP in speech recognition lies in its ability to translate textual elements (i.e. words and sentences) into normalized orders, including meaning and intent, that can be interpreted by the associated artificial intelligence and carried out.
Artificial intelligence, a necessary ally of speech recognition
First of all, artificial intelligence, although integrated in the process of the previous technologies, is not always essential to achieve the use cases. Indeed, if we are talking about connected technologies (i.e. Cloud), AI will be useful. Especially since the complexity of some use cases, especially the information to be correlated to produce them, makes it mandatory.
For example, it is sometimes necessary to compare several pieces of information with actions to be carried out, integrations of external or internal services or databases to be consulted.
In other words, artificial intelligence is the use case itself, the concrete action that will result from the voice interface. Depending on the context of use and the nature of the order, the elements requested and the results given will be different.
Let’s take a case in point. Vivoka has created a connected motorcycle helmet that allows to use functionalities with the voice. Different uses are available, such as using GPS or music.
The request “Take me to a gas station on the way” will return a normalized command to the artificial intelligence with the user’s intention:
- Context: Vehicle fuel type, Price preference (affects distance travelled)
- External services: Call the API of the GPS solution provider
- Action to be performed: Keep the current route, add a step on the route
Here, the intelligence used by our system will submit information and a request to an external service that has a specialized intelligence to send us back the result to operate on the user.
AI is therefore a key component in many situations. However, for embedded functionalities (i.e. offline), the needs are less, being closer to the realization of simple commands such as navigation on an interface or the reporting of actions . It is a question here of having specific use cases that do not require consulting multiple information.
TTS (Text to Speech) , voice to answer and inform the user
Finally, the TTS (Text-to-Speech) concludes the process. It corresponds to the feedback of the system which is expressed through a synthetic voice. In the same spirit as the Wake-up Word, it closes the speech recognition by answering vocally in order to keep the homogeneity of the conversational interface.
The voice synthesis is built from human voices and sounds diversified according to language, gender, age or mood. Synthetic voices are thus generated in real time to dictate words or sentences through a phonetic assembly.
This speech recognition technology is useful for communicating information to the user, a symbol of a complete human-machine interface and also of a well-designed user experience.
Similarly, it represents an important dimension of Voice Marketing because the synthesized voices can be customized to match the image of the brands that use it.
The different speech recognition solutions
The speech recognition market is a fast-moving environment. As use cases are constantly being born and reinvented with technological progress, the adoption of speech solutions is driving innovation and attracting many players.
Today on the market, we can count major categories of uses related to speech recognition. Among them, we can mention :
Voice assistants
We find the GAFAs and their multi-support virtual assistants (smart speaker, telephone, etc.) but also initiatives from other companies. The personalization of voice assistants is a trend on the fringe of the market domination by GAFA, where brands want to regain their technical governance.
For example, KSH and its connected motorcycle helmet are among those players with specific needs, both marketing and functional.
Professional voice interfaces
We are talking about productivity tools for employees. One of the fastest growing sectors is the supply chain with the pick-by-voice . This is a voice device that allows operators to use speech recognition to work more efficiently and safely (hands-free, concentration…). The voice commands are similar to reports of actions and confirmations of operations performed.
There are many possibilities for companies to gain in productivity. Some use cases already exist and others will be created.
Speech recognition software
Voice dictation, for example, is a tool that is already used by thousands of individuals, personally or professionally (DS Avocats for instance). It allows you to dictate text (whether emails or reports) at a rate of 180 words per minute, whereas manual input is on average 60 words per minute. The tool brings productivity and comfort to document creation through a voice transcription engine adapted to dictation.
Connected objects (Internet of Things IoT)
The IoT world is also fond of voice innovations. This often concerns navigation or device use functionalities. Whether it is home automation equipment or more specialized products such as connected mirrors, speech recognition promises great prospects.
As the more experienced among you will have understood, this article explains in a succinct and introductory way a complex technology and uses. Similarly, the tools we have presented are a specific design of speech technologies, not the norm, although they are the most common designs.
How Speech Recognition is Shaping the Future of Technology
How voice recognition is transforming technology and enhancing user experiences.
Voice recognition is now at the heart of a technological revolution, affecting a wide range of systems and devices, from personal assistants to complex enterprise applications. Thanks to major advances in machine learning models and natural language processing, companies like Vivoka have developed software capable of transforming voice into text with unparalleled accuracy and speed. Voice transcription and dictation offer unprecedented access to intuitive and personalized commands, allowing for more natural control of devices. Voice recognition technologies are becoming essential for improving accessibility and efficiency, offering a seamless user experience. With applications ranging from simple voice commands to sophisticated speaker recognition systems, this technology continues to push the boundaries of what our human-machine interactions can achieve.
Our voice recognition technology can be seamlessly integrated into everyday devices , enhancing user interaction across various platforms. The incorporation of voice-driven commands into mobile phones, computers, and smart home devices exemplifies the practicality of speech systems in everyday life. This evolution not only simplifies tasks but also enriches the user experience by enabling more personalized interactions through language models that understand context and user preferences. Furthermore, advancements in audio processing and model training techniques continue to refine the accuracy and responsiveness of these systems, making voice recognition an increasingly indispensable part of modern technology landscapes. This shift towards voice-enabled environments highlights the transformative potential of speech recognition in both personal and professional settings.
Enhancing Accessibility and Inclusivity Through Voice Recognition Technology
Moreover, the expansion of voice recognition capabilities is also opening new avenues for accessibility and inclusivity. By providing easier access to technology for individuals with physical or visual impairments, voice commands are becoming a vital tool in breaking down barriers. The adaptability of voice systems allows them to cater to a diverse range of languages and dialects, further broadening their impact. This inclusivity extends to educational environments and workplaces, where voice technology can offer alternative methods for interaction and engagement. As the technology continues to develop, it promises to enrich lives by making digital services more accessible and user-friendly for all segments of the population, thereby fostering a more inclusive digital world.
In addition to enhancing accessibility, voice recognition technology is also revolutionizing the business landscape by streamlining operations and facilitating smoother communication. Companies are leveraging these systems to automate customer service interactions, reducing response times and increasing satisfaction. Voice-driven analytics tools are enabling businesses to gain insights from customer interactions, helping to refine strategies and improve services. Moreover, the integration of voice commands in the workplace enhances productivity by allowing employees to perform tasks hands-free, thereby increasing efficiency. As industries continue to adopt voice technology, it is poised to transform traditional business models, offering innovative ways to interact with customers and manage operations more effectively.
How Voice Recognition Merges with AI for Enhanced Security and Intuitive Interactions
Furthermore, the continuous refinement of voice recognition technology is leading to more sophisticated applications in security and authentication . Voice biometrics are increasingly being used as a reliable method for verifying identities, offering a seamless yet secure alternative to traditional passwords and PINs. This technology is being integrated into banking, secure access to devices, and personalized user experiences, where voice patterns are as unique as fingerprints. The enhanced security protocols , combined with the convenience of voice commands, are setting new standards in both personal security and corporate data protection. As we move forward, the potential of voice recognition to bolster security measures while maintaining user convenience is likely to see even greater adoption across various sectors.
The proliferation of voice recognition technology is not just reshaping user interactions and security; it is also driving innovations in artificial intelligence. As these systems become more integrated with AI, they are learning to interpret not just words, but nuances of emotion and intent, enabling more empathetic and contextually aware interactions. This advancement heralds a new era of AI that can adapt to and predict user needs more effectively, creating a proactive rather than reactive technology landscape. As AI continues to evolve alongside voice recognition , the potential for truly intuitive digital assistants that anticipate and understand user preferences will further transform our interaction with technology, making it more natural and aligned with human behavior.
The Transformative Impact of Voice Recognition in Healthcare and Education
This ongoing evolution in voice recognition and AI is also fostering significant changes in healthcare, where it has the potential to revolutionize patient care. Voice-driven applications can facilitate more accurate patient documentation, reduce administrative burdens on healthcare providers, and enhance patient engagement by allowing for voice-activated health tracking and management tools. This technology offers a hands-free method to access vital information, making medical environments safer and more efficient. Additionally, speech recognition can support remote patient monitoring systems, providing healthcare professionals with real-time updates on patient conditions. As this technology becomes more sophisticated, its integration into the healthcare system promises to improve outcomes, increase accessibility, and personalize patient care like never before
Beyond healthcare , voice recognition is also making significant inroads in the educational sector. It transforms traditional learning environments by facilitating interactive and accessible educational experiences. Students can engage with learning materials through voice commands, making educational content more accessible to those with disabilities or learning difficulties. Moreover, language learning is particularly enhanced by speech recognition technologies, as they allow for real-time pronunciation feedback and interactive language practice, simulating natural conversational environments. As educational tools continue to integrate voice technology, we see a shift towards more inclusive and personalized learning paths that cater to a diverse student population, ultimately fostering a more engaging and effective educational experience.
How Voice Recognition Transforms Public Services and Urban Mobility
Additionally, the integration of voice recognition into public services and infrastructure is streamlining processes and enhancing public interaction with government entities. This technology enables citizens to access information and services through simple voice commands , reducing the complexity and time required for traditional bureaucratic processes. From renewing licenses to scheduling appointments and accessing public records, voice-enabled interfaces are making government services more user-friendly and accessible to all, including those with limited mobility or tech-savviness. This adoption not only improves efficiency and reduces administrative overhead but also promotes transparency and accessibility, making public services more accountable and responsive to citizen needs.
The scalability o f voice recognition technology also paves the way for its application in larger-scale systems, such as transportation and urban planning. Smart cities around the world are beginning to employ voice-activated systems to improve public transportation, manage traffic flow, and enhance public safety features. Commuters can interact with transit systems through voice commands to find route information, schedule updates, and ticketing options, all hands-free. This integration not only enhances the commuter experience but also contributes to the development of smarter, more responsive urban environments. As cities continue to grow and seek efficient solutions to complex logistical challenges, voice recognition technology stands as a key tool in the development of sustainable and intelligent urban ecosystems.
In the realm of entertainment and media, voice recognition technology is reshaping how consumers interact with content. Voice-activated systems are becoming integral to home entertainment setups, allowing users to search for movies, play music, and control smart home devices with simple spoken commands. This hands-free control is particularly advantageous during activities such as cooking or exercising, where manual interaction with devices is inconvenient. Additionally, gaming industries are adopting voice commands to provide more immersive experiences, allowing players to interact with the game environment and characters in innovative ways. As voice recognition technology continues to advance, it’s set to further personalize and enhance the entertainment experience, making it more interactive and accessible than ever before.
For developers, by developers
Try our voice solutions now
Sign up first on the console.
Before integrating with VDK, test our online playground: Vivoka Console.
Develop and test your use cases
Design, create and try all of your features.
Submit your project
Share your project and talk about it with our expert for real integration.

It's always the right time to learn more about voice technologies and their applications

Voice Technology: my voice is a risky personal data
Discover , Latest
Voice technology has become an integral part of modern life, embedded in everything from smartphones to home assistants and business usages. However, the conveniences it offers come with significant...

Christophe Couvreur, Esteemed AI and Voice Technology Executive, Named CEO of Vivoka
May 21, 2024 | Latest , Press Releases

Large Language Models and ChatGPT
Jun 19, 2023 | Discover , Latest

NLU model best practices to improve accuracy
Jun 5, 2023 | Adopt , Natural Language Understanding

The future of Warehousing: Voice Directed Warehouse Operations
May 23, 2023 | Adopt , Speech Recognition

5 business applications to leverage embedded NLU in your products & services
May 10, 2023 | Adopt , Natural Language Understanding , Technology
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
- IEEE Xplore Digital Library
- IEEE Standards
- IEEE Spectrum
- Subscribe to Newsletter
- Resource Center
- Create Account
What is Signal Processing?
- Board of Governors
- Executive Committee
- Awards Board
- Conferences Board
- Membership Board
- Publications Board
- Technical Directions Board
- Standing Committees
- Liaisons & Representatives
- Education Board
- Our Members
- Society History
- State of the Society
- SPS Branding Materials
- Publications & Resources
- IEEE Signal Processing Magazine
- IEEE Journal of Selected Topics in Signal Processing
- IEEE Signal Processing Letters
- IEEE/ACM Transactions on Audio Speech and Language Processing
- IEEE Transactions on Computational Imaging
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Signal and Information Processing over Networks
- IEEE Transactions on Signal Processing
- Data & Challenges
- Submit Manuscript
- Information for Authors
- Special Issue Deadlines
- Overview Articles
- Top Accessed Articles
- SPS Newsletter
- SPS Resource Center
- Publications Feedback
- Publications FAQ
- Dataset Papers
- Conferences & Events
- Conferences
- Attend an Event
- Conference Call for Papers
- Calls for Proposals
- Conference Sponsorship Info
- Conference Resources
- SPS Travel Grants
- Conferences FAQ
- Getting Involved
- Young Professionals
- Our Technical Committees
- Contact Technical Committee
- Technical Committees FAQ
- Data Science Initiative
- Join Technical Committee
- Young Professionals Resources
- Member-driven Initiatives
- Chapter Locator
- Award Recipients
- IEEE Fellows Program
- Call for Nominations
- Professional Development
- Distinguished Lecturers
- Past Lecturers
- Nominations
- DIS Nominations
- Seasonal Schools
- Industry Resources
- Job Submission Form
- IEEE Training Materials
- For Volunteers
- Board Agenda/Minutes
- Chapter Resources
- Governance Documents
- Membership Development Reports
- TC Best Practices
- SPS Directory
- Society FAQ
- Information for Authors-OJSP
dataport_5.jpg

Discover More About Your Free Subscription to IEEE DataPort(™)
Webinar_asi.jpg.

SPS Webinar: PhishSim: Aiding Phishing Website Detection With a Feature-Free Tool
Nominate_3.jpg.

Deadline Extended - Call for Nominations: Awards Board Chair
- Celebrating 75 Years of IEEE SPS
- Diversity, Equity, and Inclusion
- General SP Multimedia Content

- Submit a Manuscript
- Editorial Board Nominations
- Challenges & Data Collections
- Publication Guidelines
- Unified EDICS
- Signal Processing Magazine The premier publication of the society.
- SPS Newsletter Monthly updates in Signal Processing
- SPS Resource Center Online library of tutorials, lectures, and presentations.
- SigPort Online repository for reports, papers, and more.
- SPS Feed The latest news, events, and more from the world of Signal Processing.
- IEEE SP Magazine
- IEEE SPS Content Gazette
- IEEE SP Letters
- IEEE/ACM TASLP
- All SPS Publications
- SPS Entrepreneurship Forum
- Call for Papers
- Call for Proposals
- Request Sponsorship
- Conference Organizer Resources
- Past Conferences & Events
- Event Calendar
- Conferences Meet colleagues and advance your career.
- Webinars Register for upcoming webinars.
- Distinguished Lectures Learn from experts in signal processing.
- Seasonal Schools For graduate students and early stage researchers.
- All Events Browse all upcoming events.
- Join SPS The IEEE Signal Processing Magazine, Conference, Discounts, Awards, Collaborations, and more!
- Chapter Locator Find your local chapter and connect with fellow industry professionals, academics and students
- Women in Signal Processing Networking and engagement opportunities for women across signal processing disciplines
- Students Scholarships, conference discounts, travel grants, SP Cup, VIP Cup, 5-MICC
- Young Professionals Career development opportunities, networking
- Chapters & Communities
- Member Advocate
- Awards & Submit an Award Nomination
- Volunteer Opportunities
- Organize Local Initiatives
- Autonomous Systems Initiative
- Applied Signal Processing Systems
- Audio and Acoustic Signal Processing
- Bio Imaging and Signal Processing
- Computational Imaging
- Image Video and Multidimensional Signal Processing
- Information Forensics and Security
- Machine Learning for Signal Processing
- Multimedia Signal Processing
- Sensor Array and Multichannel
- Signal Processing for Communication and Networking
- Signal Processing Theory and Methods
- Speech and Language Processing
- Synthetic Aperture Technical Working Group
- Industry Technical Working Group
- Integrated Sensing and Communication Technical Working Group
- TC Affiliate Membership
- Co-Sponsorship of Non-Conference TC Events
- Mentoring Experiences for Underrepresented Young Researchers (ME-UYR)
- Micro Mentoring Experience Program (MiME)
- Distinguished Lecturer Program
- Distinguished Lecturer Nominations
- Distinguished Industry Speaker Program
- Distinguished Industry Speakers
- Distinguished Industry Speaker Nominations
- Jobs in Signal Processing: IEEE Job Site
- SPS Education Program Educational content in signal processing and related fields.
- Distinguished Lecturer Program Chapters have access to educators and authors in the fields of Signal Processing
- PROGRESS Initiative Promoting diversity in the field of signal processing.
- Job Opportunities Signal Processing and Technical Committee specific job opportunities
- Job Submission Form Employers may submit opportunities in the area of Signal Processing.
- Technical Committee Best Practices
- Conflict of Interest
- Policy and Procedures Manual
- Constitution
- Board Agenda/Minutes* Agendas, minutes and supporting documentation for Board and Committee Members
- SPS Directory* Directory of volunteers, society and division directory for Board and Committee Members.
- Membership Development Reports* Insight into the Society’s month-over-month and year-over-year growths and declines for Board and Committee Members
Popular Pages
- (ISBI 2025) 2025 IEEE International Symposium on Biomedical Imaging
- (ICASSP 2025) 2025 IEEE International Conference on Acoustics, Speech and Signal Processing
- Awards & Submit Award Nomination
- Information for Authors-SPL
- Signal Processing 101
Last viewed:
- IEEE TMM Special Issue on Large Multi-modal Models for Dynamic Visual Scene Understanding
- IEEE TCI Special Section on Computational Imaging using Synthetic Apertures
- IEEE JSTSP Special Issue on Distributed Signal Processing for Extremely Large-Scale Antenna Array Systems
- (MLSP 2024) 2024 IEEE International Workshop on Machine Learning for Signal Processing
- (DCC 2025) 2025 Data Compression Conference
- New MD Kit Portal - Custom Orders Now Available
What Are the Benefits of Speech Recognition Technology?
Search form, you are here.
- Publications
- Challenges & Data Collections Members
- Data Challenges
- Dataset Resources
- Challenge Papers
For Authors
- IEEE Author Center
- IEEE Copyright Form
Submit a Manuscript
Editorial Board Nominations

election_vote.jpg

Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine 2. Signal Processing Digital Library* 3. Inside Signal Processing Newsletter 4. SPS Resource Center 5. Career advancement & recognition 6. Discounts on conferences and publications 7. Professional networking 8. Communities for students, young professionals, and women 9. Volunteer opportunities 10. Coming soon! PDH/CEU credits Click here to learn more .
spoken_lang_1.jpg

Speech recognition technology allows computers to take spoken audio, interpret it and generate text from it. But how do computers understand human speech? The short answer is…the wonder of signal processing. Speech is simply a series of sound waves created by our vocal chords when they cause air to vibrate around them. These soundwaves are recorded by a microphone, and then converted into an electrical signal. The signal is then processed using advanced signal processing technologies, isolating syllables and words. Over time, the computer can learn to understand speech from experience, thanks to incredible recent advances in artificial intelligence and machine learning. But signal processing is what makes it all possible.
So, what are the benefits of speech recognition technology? Why, exactly, do we need computers to understand our speech when typing is usually faster (and quieter)? Speech is a natural interface for many programs that don’t run on computers, which are becoming more common. Here are some important ways in which speech recognition technology plays a vital role in people’s lives.
Talking to Robots : You might not think that speaking with robots is a common activity. But robots are increasingly being employed in roles once performed by humans, including in conversation and interface. For example, firms are already exploring using robots and software to perform initial job interviews. As interviews must be conversational, it’s essential that the robot can interpret what the interviewee is saying. That requires speech recognition technology.

Aiding the Visually- and Hearing-Impaired : There are many people with visual impairments who rely on screen readers and text-to-speech dictation systems. And converting audio into text can be a critical communication tool for the hearing-impaired.
Enabling Hands Free Technology: When your eyes and hands are busy, such as when you’re driving, speech is incredibly useful. Being able to communicate with Apple’s Siri or Google Maps to take you where you need to go reduces your chances of getting lost and removes the need to pull over and navigate a phone or read a map.
Why Speech Recognition Technology is a Growth Skillset: Speech recognition technology is already a part of our everyday lives, but for now is still limited to relatively simple commands. As the technology advances, researchers will be able to create more intelligent systems that understand conversational speech (remember the robot job interviewers?). One day, you will be able to talk to your computer the way you would talk to any human, and it will be able to transmit reasoned responses back to you. All this will be made possible by signal processing technologies. The number of specialists needed in this field are growing, and many companies are looking for talented people who want to be a part of it. Processing, interpreting and understanding a speech signal is the key to many powerful new technologies and methods of communication. Given current trends, speech recognition technology will be a fast-growing (and world-changing) subset of signal processing for years to come.
- THIS WEEK: Join NASA’s Dr. Jacqueline Le Moigne as she shares her journey through academia, the private sector, and pivotal roles at NASA, emphasizing her work in signal processing, computer vision, and related technologies. Register now! https://x.com/IEEEsps/status/1785057479606288505
- Join NASA’s Dr. Jacqueline Le Moigne for this interactive webinar as she shares her journey through the realms of signal processing, computer vision, and related technologies, including her pivotal roles at NASA. https://x.com/IEEEsps/status/1782468413551423536
- Great crowd at the Student Job Fair at #ICASSP2024! Thank you to our sponsors for furnishing an exciting, engaging event! https://x.com/IEEEsps/status/1780817453569687559
- Thank you to our Women in Signal Processing Luncheon panelists for their wisdom and insights during today’s event at #ICASSP2024! https://x.com/IEEEsps/status/1780458637338530252
- Free Machine Learning (ML) Lecture Series from IEEE SPS From basics to recent advances, unlock the secrets of ML with Prof. Sergios Theodoridis! https://x.com/IEEEsps/status/1779931297093222415
IEEE SPS Educational Resources

Home | Sitemap | Contact | Accessibility | Nondiscrimination Policy | IEEE Ethics Reporting | IEEE Privacy Policy | Terms | Feedback
© Copyright 2024 IEEE – All rights reserved. Use of this website signifies your agreement to the IEEE Terms and Conditions . A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity.

What is Voice Recognition?
By: Danielle Chazen

- Accessibility hub
- AI technology
- Education & eLearning
- Real-time (CART)
- Transcription
Popular posts
Related posts

Subscribe to our blog
Voice recognition technology can interpret speech and identify a single speaker. Like fingerprints, individual’s have unique markers in their voices that technology can use to identify them. Many companies are already using this tool to authenticate that a person is indeed the individual they claim to be when speaking.
Voice recognition differs from speech recognition, which only identifies the words a person says. Instead, voice recognition analyzes countless patterns and elements that distinguish one person’s voice from another. People are now using voice recognition in every facet of our lives, personally and professionally. Still not everyone understands the role that voice recognition software plays. Here is a basic background of voice recognition, how it works and few ways that we’re already tapping into this tool at work and in our day-to-day lives.
How does voice recognition work?
Voice recognition tools rely on artificial intelligence (AI) to differentiate between speakers. To achieve this identification, AI voice recognition software must first undergo training with an individual’s voice. The technology requires that a person read a statement multiple times, and it records their specific speech patterns. Next, the AI analyzes that statement and the idiosyncrasies of the speakers cadence, tone and other identifying markers. Using a process called “template matching,” the AI can then identify that individual’s voice.
Voice recognition is very accurate when it comes to identifying individual speakers. Developers have, therefore, found many uses for this technology.
What is an example of voice recognition?
Voice recognition products are quickly becoming part of everyday life. For example, Google’s smart home kit allows you to set your devices to begin working before you even get home. You can turn on the lights and heat, unlock your door, and monitor your spaces seamlessly and remotely.
Speech recognition identifies the words you use. You can search for a video on YouTube without typing or turn on a smart TV without clicking a button. Voice recognition takes it one step further, ensuring that only your voice can unlock your home. Since the technology identifies your specific voice, you can rely on its ability to do so to keep you safe.
Voice-enabled devices also recognize specific voices within a home. These recognition abilities prevent your kids from using devices to shop without your permission. They also help to differentiate from family members who are scheduling appointments with connected devices. There are a number of popular tools that tap into the useful abilities of voice recognition. There is a good chance that you’re already using some of these regularly.
Google voice recognition
Google voice recognition allows users to program their Android phones or tablets to detect their voice. By using “Voice Match,” users can train their devices to recognize their voice and commands. This tool allows users to go hands free and give directions to their phone, such as activating navigation, communicating with friends or family and changing their settings.
Apple voice recognition
Like Google, Apple allows individuals to program their phones and tablets to identify their voices . Using an iPhone or iPad, you can go to “settings” and select “Siri and Search,” and turn off and then on the “Listen” option for Siri. The “Set Up” screen for “Hey Siri” will appear and provide prompts for you to speak so that the device can recognize your voice.
Alexa voice recognition
Amazon also offers the option to personalize your devices to respond to your voice. Alexa voice recognition, or Alexa Voice ID , lets you program your device to identify you. As a result, Alexa can offer personalized responses, suggestions and updates to individual users.

Automatic Voice Recognition Is Empowering Students
In addition to its capabilities in the home, voice recognition is empowering universities to aid students with disabilities. Smart classrooms are now implementing advanced technologies like voice-activated academic transcription software . When campuses transcribe their classes, students who are Deaf and hard of hearing gain access to educational opportunities that they couldn’t access previously. AI-based transcription software makes it easy for them to differentiate between when a university professor is speaking and when its a peer speaking or asking a question. As a result, when a student returns to that recording, the transcript can name the different speakers, making it easier to read and follow. Voice recognition tools also empower the higher education industry with the ability to use voice dictation systems when students need to submit papers or other written assignments. Whether a student is blind, suffering from an injury or simply doesn’t type well, that individual can try using voice recognition as an alternative way of completing assignments. Leading educators realize that students have different strengths and learning styles, so adding another tool to their studying arsenal can be extremely beneficial.
How Voice Recognition Tools Improve the Justice System
When it comes to legal proceedings, such as court hearings and depositions, where many people are involved, recording and transcribing the process is often necessary. The industry is experiencing a shortage of stenographers and therefore turning to voice-activated legal transcription software. While AI transcription products help court reporting agencies train the software to recognize industry terms, automatic voice recognition engines can distinguish between the many speakers present in the same room and account for common interruptions. As the technology grows more sophisticated, court reporting agencies are able to leverage software to produce highly accurate transcriptions.
How Voice Recognition Products Keep Us Safe
In addition to recognizing a consumer’s specific voice to unlock his door, some banks are now allowing access to accounts via voice recognition instead of passwords. Voices are comprised of countless elements that make them unique. Therefore, it is much easier to hack an account by uncovering someone’s password, and much more challenging to hack a system that uses voice recognition.
Voice recognition software programs are also supporting law enforcement in the field. When officers are solving crimes, the documentation of everything that happens can make or break a case. The need to stop and jot notes down can be distracting and makes it possible to overlook something important. With voice recognition tools, officers can perform their jobs more efficiently while letting technology complete their transcriptions. Officers can also dictate notes to their devices and convert those notes into useful, searchable transcripts. When multiple officers use the same voice dictation system, or when they operate in busy environments with a lot of noise, automatic voice recognition is critical. This tool can help officers keep track of which officer said or did what on the scene.

Future Uses of Voice Recognition Technology
Voice recognition will continue to impact our future. As developers create more voice recognition software programs, we’re likely to see an increase in voice-enabled devices and third-party applications to enhance our usage.
Voice profiles will also grow more sophisticated. As a result, people will discover more personalized experiences that encourage deeper adoption. Voice ads will become more personalized too. Secure voice commands will also make purchases online easier and safer. It’s possible that voice recognition could eventually become a requirement for payment. As technology identifies voices, their tones, and their contexts more clearly, criminal acts and legal procedures will grow more transparent and higher education will become more personalized and accessible. Voice recognition usage will increase, and as it does, the question will no longer be who uses voice recognition software, but who doesn’t.
For more information about tools like voice recognition, AI captioning, transcription and other intelligent solutions, reach out to Verbit .
Sign up to get the latest news and updates from us.
The Future of Speech Recognition: Where Will We Be in 2030?
The last two years have been some of the most exciting and highly anticipated in Automatic Speech Recognition’s (ASR’s) long and rich history, as we saw multiple enterprise-level fully neural network-based ASR models go to market (e.g. Alexa , Rev , AssemblyAI , ASAPP , etc). The accelerated success of ASR deployments is due to many factors, including the growing ecosystem of freely available toolkits, more open source datasets, and a growing interest on the part of engineers and researchers in the ASR problem. This confluence of forces has produced an amazing momentum shift in commercial ASR. We truly are at the onset of big changes in the ASR field and of massive adoption of the technology.
These developments are not only improving existing uses of the technology, such as Siri’s and Alexa’s accuracies, but they are also expanding the market ASR technology serves. For example, as ASR gets better with very noisy environments, it can be used effectively in police body cams , to automatically record and transcribe interactions. Keeping a record of important interactions, and perhaps identifying interactions before they become dangerous, could save lives. We are seeing more companies offering automated captions to live videos, making live content accessible to more people. These new use-cases and customers are pushing the requirements for ASR, which is accelerating research.
What’s Next for ASR?

Source: Hannun, Awni, “ Speech Recognition is not Solved ”.
In 2016, 6 years ago already, Microsoft Research published an article announcing they had reached human performance (as measured using Word Error Rate , WER) on a 25-year old data set called Switchboard . As Zelasko et al. have pointed out, such optimistic results do not hold up on data reflecting natural human speech spoken by a diverse population. [1]
Nevertheless, ASR accuracy has continued to improve, reaching human parity on more datasets and in more use cases. On top of continuing to push the limits of accuracy for English systems, and, in doing so, redefining how we measure accuracy as we approach human-level accuracy, we foresee five important areas where research and commercial systems will evolve in the next ten years.
Truly Multilingual ASR Models

Source: Conneau, Alexis, et al. "Unsupervised cross-lingual representation learning for speech recognition." arXiv preprint arXiv:2006.13979 (2020).
Today's commercially available ASR models are primarily trained using English-language data sets and consequently exhibit higher accuracy for English-language input. Due to data availability and market demands, academia and industry have focused on English for a very long time. Accuracy for commercially popular languages like French, Spanish, Portuguese, and German is also reasonable, but there is clearly a long tail of languages for which limited training data exists and ASR output quality is correspondingly lower.
Furthermore, most commercial systems are monolingual, which doesn’t accommodate the multilingual scenarios characteristic of many societies. Multilinguality can take the form of back-to-back languages, for example in a bilingual country’s media programming. Amazon recently introduced a product integrating language identification (LID) and ASR that makes big strides toward handling this.In contrast, translanguaging (also known as code switching) involves individuals employing a linguistic system that incorporates both words and grammar from two languages potentially within the same sentence. This is an area where the research community continues to make interesting progress .
Just as the field of Natural Language Processing has taken up multilingual approaches, we see the world of ASR doing the same in the next decade. As we learn how to take advantage of emerging end-to-end techniques, we will be able to train massively multilingual models that can exploit transfer learning [2] between multiple languages. A good example of this is Facebook’s XLS-R : in one demo you can speak any of 21 languages without specifying which and it will translate to English. These smarter ASR systems, by understanding and applying similarities between languages, will enable high-quality ASR availability for both low-resource languages and mixed-language use cases, and they will do so at a commercial quality-level.
Rich Standardized Output Objects
While there is a long tradition of exploration into “rich transcription”, originally by NIST , there has not been much effort on standardized and extensible formats for incorporating it into ASR output. The notion of rich transcription originally involved capitalization, punctuation and diarization, but has expanded somewhat into speaker roles [3] and a range of non-linguistic human speech events. [4] Anticipated and desired innovations include the ability to transcribe potentially simultaneous and overlapping speech from different speakers, [5] emotions [6] and other paralinguistic [7] characterizations, [8] and a range of non-linguistic and even non-human speech scenes and events. [9] It would also be possible to include stylistic [10] or language variety-based information [11] . Tanaka et al. describe a scenario where a user might want to choose among transcription options at different levels of richness, [12] and clearly the amount and nature of the additional information we foresee would be specifiable, depending on the downstream application.
Traditional ASR systems are capable of generating a lattice of multiple hypotheses in their journey to identify spoken words, and these have proved useful in human-assisted transcription, [13] spoken dialog systems, [14] and information retrieval. [15] Clearly, including n-best information along with confidence in a rich output format will encourage more users to exploit it, improving user experiences. While no standard currently exists for structuring or storing the additional information currently generated or possible to generate during the speech decoding process, one promising step in this direction is CallMiner’s Open Voice Transcription Standard (OVTS) which makes it easier for enterprises to explore and use multiple ASR vendors.
We predict that in future, ASR systems will produce richer output in a standard format that will enable more powerful downstream applications. For example, an ASR system might return the whole lattice of possibilities as its output, and an application could use this additional data for intelligent auto-complete when editing the transcript. Similarly, ASR transcripts that include additional metadata (such as detected regional dialects, accents, environmental noise and/or emotions) could enable more powerful search applications.
ASR for All and At Scale

We are all consuming (and participating in) massive amounts of content: podcasts, social media streams, online videos, real-time group chats, Zoom meetings and many more. However, very little of this content is actually transcribed. Today, content transcription is already one of the largest markets for ASR APIs and is set to grow exponentially in the next decade, especially given how accurate and affordable they are becoming. Having said this, ASR transcription is currently used only in select applications (broadcast videos, some meetings, some podcasts, etc.). As a result, this media content is not accessible for many people and it is extremely difficult to find information after a broadcast or event is over.
In the future, this will change. As Matt Thompson predicted in 2010, at some point ASR will be so cheap and widespread that we will experience what he called “The Speakularity” . We will expect almost all audio and video content to be transcribed and become immediately accessible, storable and searchable at scale. And it won't stop there. We will want this content to be actionable. We will want additional context for each piece of content we consume or participate in, such as auto-generated insights from podcasts or meetings, or automatic summaries of key moments in videos… and we will expect our NLP systems to produce these for us as a matter of routine.
Human-Machine Collaboration

As ASR becomes more mainstream and covers an ever-increasing number of use cases, human-machine collaboration is set to play a key role. ASR model training is a good example of this. Today, open source data sets and pre-trained models have reduced the barriers to entry for ASR vendors. However, the training process is still fairly simplistic: collect data, annotate the data, train a model, evaluate results, repeat, to iteratively improve the model. This process is slow and, in many cases, error-prone due to difficulties in tuning or insufficient data. Garnerin et al. [16] have observed that a lack of metadata and inconsistency in representations across corpora have made it harder to provide equivalent accuracy to all communities in ASR performance; this is something that Reid & Walker [17] are also trying to address with the development of metadata standards.
In the future, humans will play an increasingly important role in accelerating machine learning through intelligent and efficient supervision of ASR training. The human-in-the-loop approach places human reviewers inside the machine learning/feedback cycle, allowing for ongoing review and tuning of model results. This results in faster and more efficient machine learning leading to higher-quality outputs. Earlier this year we discussed how ASR improvements have enabled Rev’s human transcriptionists (known as “Revvers”), who post-edit an ASR draft, to be even more productive. [18] Revver transcriptions feed right into improved ASR models, creating a virtuous cycle.
One area where human language experts are still indispensable in ASR is inverse text normalization (ITN), where recognized strings of words like “five dollars” are converted to expected written forms like “$5”. Pusateri et al. [19] describe a hybrid approach using “both handcrafted grammars and a statistical model”; Zhang et al. [20] continue along these lines by constraining an RNN with human-crafted FSTs.
Responsible ASR

ASR systems of the future will be expected to adhere to the four principles of responsible AI: fairness, explainability, accountability and respect for privacy.
Fairness: Fair ASR systems will recognize speech regardless of the speaker's background, socio-economic status or other traits. It is important to note that building such systems requires recognizing and reducing bias in our models and training data. Fortunately, governments, [21] non-governmental organizations [22] and businesses [23] have begun creating infrastructure for identifying and alleviating bias.
Explainability: ASR systems will no longer be "black boxes": they will provide, on request, explanations of how data is collected and analyzed and on a model's performance and outputs. This additional transparency will result in better human oversight of model training and performance. Along with Gerlings et al. [24] , we view explainability with respect to a constellation of stakeholders, including researchers, developers, customers and in Rev’s case, transcriptionists. Researchers may want to know why erroneous text was output so they can mitigate the problem, while transcriptionists may want some evidence why ASR thought that’s what was said, to help with their assessment of its validity, particularly in noisy cases where ASR may “hear” better than people do. Weitz et al. have taken important initial steps towards end-user explanations in the context of audio keyword spotting. [25] Laguarta & Subirana have incorporated clinician-directed explanations into a speech biomarker system for Alzheimer’s detection. [26]
Respect for privacy: "Voice" is considered "personal data" under various US and international laws, and the collection and processing of voice recordings is therefore subject to stringent personal privacy protections. At Rev, we already offer data security and control features , and future ASR systems will go even further to respect both the privacy of user data and the privacy of the model. Most likely, in many cases, this will involve pushing ASR models to the edge (on devices or browsers). The Voice Privacy Challenge is motivating research in this area, and many jurisdictions, such as the EU, have begun adopting guidelines [27] and legislation. [28] The field of Privacy Preserving Machine Learning promises to facilitate emphasis on this critical aspect of our technology so that it can be widely embraced and trusted by the general public.
Accountability: ASR systems will be monitored to ensure that they adhere to the previous three principles. This in turn will require a commitment of resources and infrastructure to design and develop the necessary monitoring systems and take actions on their findings. Companies that deploy ASR systems will be expected to be accountable for their use of the technology and in making specific efforts to adhere to responsible ASR principles.
It’s worthwhile mentioning that as the designers, maintainers and consumers of ASR systems, humans will be responsible for implementing and enforcing these principles - yet another example of human-machine collaboration.
Many of these advances are already well under way, and we fully expect the next ten years to be quite an exciting ride for ASR and related technologies. At Rev, we're excited to make progress in all these topics, starting with the release of our v2 model surpassing previous state of the art by 30% relative based on internal and external test suites. Those interested in watching these trends take form, and catching up on the incredible advances of our sister technologies like text-to-speech (TTS) and speaker recognition, are encouraged to attend the field’s upcoming technical conferences, Interspeech , ICASSP and SLT . For those with a more linguistic bent, COLING and ICPhS are recommended, and for a business-oriented overview, Voice Summit .
What do you think?
We'd love to hear your predictions as well.
Zelasko et al. (2020) ↩︎
See for example Bozinovski (2020) ↩︎
El Shafey et al. (2019) ↩︎
Tanaka et al. (2021) ↩︎
Yoshioka et al. (2018) ↩︎
https://www.w3.org/TR/emotionml/ might be a good starting point for emotions. ↩︎
Schuller & Batliner (2013) surveys computational paralinguistics in speech processing. ↩︎
Müller (2007) surveys speaker classification (also known as speaker characterization). ↩︎
https://research.google.com/audioset/ontology/index.html provides a very promising ontology of such sounds, while https://dcase.community/ is a set of workshops and challenges on acoustic scenes and events. ↩︎
Veiga et al. (2012) ↩︎
Biadsy (2011) ↩︎
Tanaka, ibid. ↩︎
Luz et al. (2008) ↩︎
Baumann et al. (2009) ↩︎
Saraclar & Sproat (2004) ↩︎
Garnerin et al. (2020) ↩︎
Reid & Walker (2022) ↩︎
Jetté (2022) ↩︎
Pusateri et al. (2017) ↩︎
Zhang et al. (2019) ↩︎
https://www.nist.gov/publications/towards-standard-identifying-and-managing-bias-artificial-intelligence ↩︎
https://www.faireva.org/ ↩︎
https://www.atexto.com/voice-data , https://orcaarisk.com/ ↩︎
Gerlings et al. (2022) ↩︎
Weitz et al. (2021) ↩︎
Laguarta & Subirana (2021) ↩︎
https://edpb.europa.eu/system/files/2021-07/edpb_guidelines_202102_on_vva_v2.0_adopted_en.pdf . ↩︎
https://ambiq.com/how-voice-recognition-technology-is-regulated/ ↩︎
For attribution in academic contexts or books, please cite this work as
Migüel Jetté and Corey Miller, "The Future of Speech Recognition: Where will we be in 2030?", The Gradient, 2022.
BibTeX citation:
@article{miller2021futureofowork, author = {Jetté, Migüel and Miller, Corey}, title = {The Future of Speech Recognition: Where will we be in 2030?}, journal = {The Gradient}, year = {2022}, howpublished = {\url{ https://thegradient.pub/the-future-of-speech-recognition/ } }, }
Migüel Jetté
Corey miller, recent posts, we need positive visions for ai grounded in wellbeing.
Financial Market Applications of LLMs
A Brief Overview of Gender Bias in AI
Mamba Explained
Car-GPT: Could LLMs finally make self-driving cars happen?
Speech Recognition in Artificial Intelligence

Speech recognition in artificial intelligence is a game-changing development for businesses. Speech recognition enables machines and computers to understand human voice or speech data and respond intelligently. This incredible capability has transformed the way we interact with technology, making tasks more convenient and accessible than ever before.
What is Speech Recognition in Artificial Intelligence?
Speech recognition in artificial intelligence is also known as automatic speech recognition (ASR). It converts spoken language into written text to understand and respond. Automatic Speech recognition works by analysing audio input and applying complex algorithms and cutting-edge technologies like machine learning (ML) and neural networks to recognize and interpret spoken words. Phonetics and linguistics are the foundations of this technology.
Speech recognition systems enable users to communicate with devices, applications, and services using their voice rather than traditional input methods like typing or clicking. Businesses develop these programs and technologies to integrate them into different hardware devices and identify speech.
How does speech recognition work?

Speech recognition AI is a complex process of intricate algorithms to convert spoken language into written text. The process of speech recognition takes place in the following stages:
- Sound Capturing: Speech recognition in artificial intelligence begins with capturing audio input using microphones or other audio recording devices.
- Sound Analysis: Sound analysis is also known as acoustic analysis in speech recognition AI. Sound analysis involves utilising AI techniques to interpret audio data by extracting valuable information from signals such as speech, music, or environmental sounds. In this stage, the computer converts the captured sound into a digital format by converting continuous sound waves into discrete data points, which can then be processed.
- Feature Extraction: The extraction process involves extracting various acoustic features from the digital audio data. These features include characteristics like pitches, tones, and lengths of the sounds and spectral patterns. These features help represent the distinct sound elements present in the spoken words.
- Acoustic Modeling: It involves training a machine learning model to recognize patterns in the extracted acoustic features and the individual sounds that make up words, called phonemes. It tries to match the patterns it sees with these known phonemes. Simply, the computer compares the extracted sounds to the words people say.
- Language Modeling: Using language models in speech recognition in artificial intelligence , the computer makes educated predictions about what words you might be saying based on the context of the conversation.
- Decoding: The speech recognition system predicts what words you speak based on the patterns it matches and the language knowledge it has. It considers all possible options and chooses the most likely ones. Decoding involves searching through a vast set of possible word combinations to find the one that best matches the audio features and context.
- Output Generation: The final outcome of the speech recognition process is a text transcription of the spoken audio. The recognized text is generated based on the decoded word sequence.
Also Read: How AI Voice Bots are Helping the Telecommunications Industry in Dormant Reactivation
Challenges in Speech Recognition
Speech recognition in artificial intelligence has made significant advancements. But, there are several challenges in ASR that impact the accuracy and usability of the technology. Some of the challenges in speech recognition AI are as follows:
- Accents and Dialects: Different accents and dialects can significantly affect the accuracy of speech recognition systems. Variations in pronunciation, intonation, and speech patterns make it challenging for systems to transcribe spoken words accurately.
- Background Noise and Ambient Conditions : Ambient noise, such as background conversations, machinery, or street noise, can interfere with the clarity of spoken input, making it difficult for systems to capture and transcribe the intended words accurately.
- Context Understanding: Speech recognition systems struggle to understand and interpret the context of spoken language accurately. Contextual understanding is crucial for correctly transcribing ambiguous phrases and understanding the meaning behind words.
- Vocabulary and Out-of-Vocabulary Words: Recognizing uncommon words, industry-specific jargon, or newly coined terms can be challenging for AI speech recognition which has yet to be trained on these terms.
- Lack of Training Data for Specific Use Cases: Developing accurate speech recognition in artificial intelligence requires vast training data. Obtaining sufficient training data can be challenging in specialized domains or languages with limited resources.
What are the Applications of Speech Recognition?
Speech recognition in artificial intelligence has the following applications:
- Voice Assistants: Virtual helpers like Siri, Google Assistant, and Alexa respond to voice commands, schedule tasks, and answer queries.
- Transcription Services: ASR aids in converting spoken content into written documents, from interviews to lectures. Professionals can use speech recognition to dictate reports, documents, emails, and notes, speeding up the process of content creation.
- Accessibility: Speech recognition technology empowers individuals with disabilities to interact with computers and perform tasks using their voice.
- Automotive Interfaces: Voice commands enable drivers to control various functions while keeping their hands on the wheel.
- E-Commerce: Voice-powered online shopping enables customers to search for products, add items to their cart, and complete purchases using their voice.
- Language Translation: Speech recognition in AI can help you translate and converse with people with different languages and accents.
- E-Learning: Speech recognition can be incorporated into e-learning platforms, allowing employees to use their voice to interact with training materials and assessments.
Also Read: How Voice-AI Is Transforming The Automobile BDC?
Use Cases of Speech Recognition in Businesses
Speech recognition technology has found numerous applications in the business world, offering efficiency, convenience, and improved customer interactions. Here are some key applications of speech recognition in business:
- Automated Customer Support: Speech recognition-powered IVR (Interactive Voice Response) systems allow customers to interact with automated menus using their voice, efficiently routing calls to appropriate departments.
- Virtual Agents: AI-powered virtual agents use speech recognition to understand and respond to customer inquiries, offering solutions and information 24/7 without human intervention.
- Call Analytics: Businesses can analyse customer interactions in call centers to identify trends, customer sentiments, and areas for improvement in customer service.
- Voice Biometrics: Speech recognition in artificial intelligence can be used to create voiceprints for user authentication, adding an extra layer of security to systems and services.
- Multilingual Support: Speech recognition can aid in real-time translation during global business communications, breaking down language barriers.
- Speech Analytics : Analysing recorded customer calls using AI speech recognition can help extract valuable insights about customer preferences, pain points, and market trends.
- Customer Service : Call centres utilize speech recognition AI for efficient call routing and automated assistance.
Incorporate Speech recognition in artificial intelligence with Rezo.ai

Leveraging cutting-edge AI speech recognition technology with Rezo.ai empowers businesses to optimize their customer service, drive efficiency, and ultimately craft meaningful connections that drive success. Rezo’s speech recognition in artificial intelligence not only converts spoken words into written text but also delves deeper, analyzing the nuances within the conversation. Rezo’s Engage AI processes audio data by converting speech to text in real-time, overcoming challenges like background noise, accent, inconsistent quality, and dual-channel separation with a reduced word error rate. Let’s explore how Rezo’s Engage AI is poised to reshape the business landscape:
- Sentiment Analysis: Rezo’s Engage AI captures the underlying sentiment in conversations by analysing the tone. Businesses can gauge customer satisfaction, detect potential issues, and tailor responses accordingly.
- Intelligent Routing: Through advanced algorithms, Rezo’s voice agents analyse the tone of the customer. When a customer is unsatisfied and needs further assistance, EngageAI intelligently routes calls and inquiries to the most suitable agent.
- Appropriate Responses: Powered by machine learning, the platform suggests appropriate responses based on the analysis of the conversation. This not only saves human agent workload but also ensures consistent and accurate communication with customers.
- Training Agents: Rezo’s Analyse AI isn’t just a tool; it’s a training ground for agents. By providing real-time insights into customer interactions, agents can refine their communication skills and enhance their ability to meet customer expectations effectively.
- Elevated Customer Experience: With the power of Rezo.ai, businesses can provide an elevated customer experience. From quicker problem resolution to personalized engagement, every interaction becomes an opportunity to leave a positive impact round the clock.
- Streamlined Processes: By automating the transcription process, Rezo’s Engage AI frees up valuable time for agents and reduces the chance of errors associated with manual transcription.
Speech recognition is revolutionising business in the field of artificial intelligence by enabling machines to comprehend and intelligently respond to human speech. Automatic Speech Recognition (ASR) is a technology that converts spoken language into text by utilising advanced algorithms and technologies such as machine learning and neural networks to detect speech. The applications of ASR are numerous, ranging from voice assistants to call analytics.
Rezo.ai’s Engage AI expands on this by providing sentiment analysis, intelligent routing, and better customer experiences. Request a demo to discover the full potential of Rezo.ai’s speech recognition technology for your business.
FAQs on Speech Recognition in AI
Take the leap towards innovation with rezo.ai, related posts.

A Comprehensive Guide to Data-Driven Decision-Making

What is CSAT, How to Measure and Improve It

5 Key Features of Rezo’s Conversational AI and Analytics Platform

Subscribe To Our Newsletter For Exclusive Insights
Platform stack, tech stacks, by industries.

Feel Free To Contact Us
Top 18 Speech Recognition Companies: Leading the Way in Language Technology

The speech recognition industry is a rapidly growing sector that focuses on developing technologies that can convert spoken language into written text. Within this industry, there are various companies that specialize in different aspects of speech recognition. Some companies, like Atexto and Rev, provide speech-to-text services, transcribing audio and video files into accurate text for accessibility and wider audience reach. Others, such as SoundHound and Speechmatics, offer advanced conversational intelligence and speech-to-text technology through their API, enabling developers to create engaging user experiences. Additionally, companies like Sensory, Inc. specialize in speech recognition and artificial intelligence technology, offering services in consumer electronics, wearables, banking, medical, and automotive industries. The speech recognition industry is poised for future growth as advancements in AI and machine learning continue, leading to improved accuracy and usability of speech recognition technologies.
Top 18 Speech Recognition Companies
1. atexto.
- Headquarter: San Francisco, California, Spain
- Founded: 2019
- Headcount: 10001+
- Latest funding type: Seed
Atexto.com is a language support company that offers high-quality data, delivery speed, and pricing for improving speech recognition accuracy. They provide training datasets and management tools for speech recognition engines, along with benchmark models and competitors' analysis. With a large number of contributors worldwide, they collect labeled speech data and offer customized voice data to enhance language support. Atexto.com is the go-to partner for making voice-based products smarter.
2. SoundHound
- Headquarter: Santa Clara, California, United States
- Founded: 2005
- Headcount: 201-500
SoundHound is a leading innovator of conversational intelligence, offering voice AI solutions trusted by top brands worldwide. They empower brands to have a voice and deliver real business value through their advanced conversational technologies.
3. Rev
- Headquarter: Austin, Texas, United States
- Founded: 2010
- Latest funding type: Series D
Rev is a company that provides speech-to-text services. They transcribe audio and video files into accurate text, including captions and subtitles. Their services are used by individuals and large organizations across various industries to improve accessibility, reach a wider audience, and save time.
4. Speechmatics®
- Headquarter: Cambridge, United Kingdom
- Founded: 2006
- Headcount: 51-200
- Latest funding type: Non Equity Assistance
Speechmatics is a leading provider of speech-to-text technology, offering an API that covers nearly half the world's languages with exceptional accuracy. Their comprehensive features include streaming support, speaker labels, translation, and more, enabling developers to create compelling user experiences. With their pioneering use of self-supervised learning techniques, Speechmatics delivers unrivaled accuracy regardless of accent or background noise.
5. Sensory, Inc.
- Founded: 1994
- Latest funding type: Series Unknown
Sensory is a company that specializes in speech recognition and artificial intelligence technology. They offer cloud-based voice and vision AI services, domain-specific voice assistants, and sound identification and speaker verification solutions. Their expertise lies in industries such as consumer electronics, wearables and hearables, banking and medical, and automotive.
6. Phonexia
- Headquarter: Brno, Czechia
Phonexia offers AI-powered solutions for audio analysis and investigation. Their technology includes voice biometrics, speaker identification, speech-to-text transcription, and voicebot capabilities. Phonexia helps businesses streamline operations and enhance security by providing tools for fraud detection, remote identity verification, and speech analytics. They serve a range of industries, such as call centers, banks, and government agencies. Phonexia's products are scalable, accurate, and utilize the latest advancements in artificial intelligence, acoustics, phonetics, and voice biometrics science.
7. Deepgram
- Headquarter: San Francisco, California, United States
- Founded: 2015
- Latest funding type: Series B
Deepgram.com is a leading speech-to-text AI platform that offers transcription and context services. They provide easy integration and scalability, with support for over 30 languages. Their solutions are used in contact centers, insurance fraud detection, and other industries.
8. AssemblyAI
- Founded: 2017
AssemblyAI is an AI-powered platform that provides state-of-the-art AI models to summarize speech, detect hateful content, and analyze spoken topics. With a simple API, businesses can easily embed these features into their applications.
9. Voci Technologies, a Medallia Company
- Headquarter: Pittsburgh, Pennsylvania, United States
Vocitec.com is a company that specializes in providing data-rich transcripts for 100% of calls. They offer industry-leading transcription accuracy in contact center environments and have the ability to customize language models for specific applications. With their speech technology, they aim to amplify the value of voice data, providing accurate, smart, and secure transcripts.
10. Cobalt Speech & Language
- Headquarter: Tyngsboro, Massachusetts, United States
- Founded: 2014
- Headcount: 11-50
Cobalt Speech and Language is a company that specializes in speech recognition and language technology. They offer a range of products and services including automatic speech transcription, call summarization, and voice user interfaces. They leverage the benefits of artificial intelligence and machine learning to provide state-of-the-art solutions for businesses and individuals.
11. GoVivace Inc.
- Headquarter: Mclean, Virginia, United States
- Founded: 2009
GoVivace is an AI technology company that specializes in voice-related solutions. They offer services such as Automatic Speech Recognition, Voice Biometrics (Speaker Verification), Speech to Text Software, Speaker Identification, Keyword Spotting, and Call Monitoring. Their solutions can be applied in various industries including finance, e-commerce, healthcare, and education.
12. Vivoka
- Headquarter: Metz, Grand Est, France
Vivoka.com offers a powerful all-in-one solution for creating secure embedded voice assistants. They specialize in voice AI technologies and provide software that voice-enables products and services with crystal-clear sound signal and high recognition accuracy.
13. Speechly
- Headquarter: Helsinki, Southern Finland, Finland
- Founded: 2016
Speechly is a company that offers tools and APIs for accurate real-time Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). Their technology allows for extracting information from spoken language and creating voice-enabled multimodal applications. They specialize in reducing cloud costs, enhancing privacy, and ensuring zero-latency experiences by running their services directly on end-users' devices. Their products are ideal for high-volume voice chat moderation, AI-assisted sales, logistics, e-commerce, and other input-heavy cases.
14. Voiser
- Headquarter: İstanbul, Kartal, India
- Founded: 2020
Voiser.net is a company that offers text-to-speech and speech-to-text services through their web services. They provide a variety of formats for exporting documents with optional time stamps, punctuation marks, and profanity filters. With their advanced technology, they offer accurate and realistic voice conversion in multiple languages. Customers can easily review, search, and edit their text using the online text editor. They also offer a JavaScript code that automatically converts website content into audio to enhance user experience.
15. Rev.ai
Rev AI is a company that specializes in human transcription and offers an AI-powered transcription platform for audio and video files. They provide the highest level of accuracy in their transcripts and offer services such as topic extraction, sentiment analysis, and language identification. Rev AI is known for its asynchronous streaming capabilities and has a global presence. They cater to various industries and customers, ensuring privacy and security.
16. Picovoice
- Headquarter: Vancouver, British Columbia, Canada
- Founded: 2018
- Latest funding type: Pre Seed
Picovoice is the end-to-end platform for adding voice to anything on your terms.
17. TranscribeMe
- Founded: 2011
TranscribeMe is a technology and service provider that offers transcription, translation, machine transcription, AI datasets, and data annotation solutions. Their team of experts delivers accurate and secure results with high quality and low prices.
18. Authôt
- Headquarter: Ivry Sur Seine, Iles De France, France
- Founded: 2012
Authot.com is a company that offers innovative solutions for efficient transcription of audio and video content. They provide a platform with advanced speech recognition technology and transcription services to meet the needs of various industries.
Want to find more speech recognition companies?
If you want to find more companies that provide speech-to-text services, advanced conversational intelligence, and AI technology you can doso with Inven. This list was built with Inven and there are hundreds ofcompanies like these globally.
With Inven you'll also get to know the company's:
- Ownership: Which of these are private equity backed? Which are family-owned?
- Contact data: Who are the owners and CEO's? What are their emailsand phone numbers?
- Financials: What is the financial performance of these companies?
...and a lot more!
Get started with Inven
Find companies 10x faster with Inven

Keep on reading
More articles.

How to set up and use Windows 10 Speech Recognition
Windows 10 has a hands-free using Speech Recognition feature, and in this guide, we show you how to set up the experience and perform common tasks.

On Windows 10 , Speech Recognition is an easy-to-use experience that allows you to control your computer entirely with voice commands.
Anyone can set up and use this feature to navigate, launch applications, dictate text, and perform a slew of other tasks. However, Speech Recognition was primarily designed to help people with disabilities who can't use a mouse or keyboard.
In this Windows 10 guide, we walk you through the steps to configure and start using Speech Recognition to control your computer only with voice.
How to configure Speech Recognition on Windows 10
How to train speech recognition to improve accuracy, how to change speech recognition settings, how to use speech recognition on windows 10.
To set up Speech Recognition on your device, use these steps:
- Open Control Panel .
- Click on Ease of Access .
- Click on Speech Recognition .

- Click the Start Speech Recognition link.

- In the "Set up Speech Recognition" page, click Next .
- Select the type of microphone you'll be using. Note: Desktop microphones are not ideal, and Microsoft recommends headset microphones or microphone arrays.

- Click Next .
- Click Next again.

- Read the text aloud to ensure the feature can hear you.

- Speech Recognition can access your documents and emails to improve its accuracy based on the words you use. Select the Enable document review option, or select Disable document review if you have privacy concerns.

- Use manual activation mode — Speech Recognition turns off the "Stop Listening" command. To turn it back on, you'll need to click the microphone button or use the Ctrl + Windows key shortcut.
- Use voice activation mode — Speech Recognition goes into sleep mode when not in use, and you'll need to invoke the "Start Listening" voice command to turn it back on.

- If you're not familiar with the commands, click the View Reference Sheet button to learn more about the voice commands you can use.

- Select whether you want this feature to start automatically at startup.

- Click the Start tutorial button to access the Microsoft video tutorial about this feature, or click the Skip tutorial button to complete the setup.

Once you complete these steps, you can start using the feature with voice commands, and the controls will appear at the top of the screen.
Quick Tip: You can drag and dock the Speech Recognition interface anywhere on the screen.
After the initial setup, we recommend training Speech Recognition to improve its accuracy and to prevent the "What was that?" message as much as possible.
Get the Windows Central Newsletter
All the latest news, reviews, and guides for Windows and Xbox diehards.
- Click the Train your computer to better understand you link.

- Click Next to continue with the training as directed by the application.

After completing the training, Speech Recognition should have a better understanding of your voice to provide an improved experience.
If you need to change the Speech Recognition settings, use these steps:
- Click the Advanced speech options link in the left pane.

Inside "Speech Properties," in the Speech Recognition tab, you can customize various aspects of the experience, including:
- Recognition profiles.
- User settings.
- Microphone.

In the Text to Speech tab, you can control voice settings, including:
- Voice selection.
- Voice speed.

Additionally, you can always right-click the experience interface to open a context menu to access all the different features and settings you can use with Speech Recognition.

While there is a small learning curve, Speech Recognition uses clear and easy-to-remember commands. For example, using the "Start" command opens the Start menu, while saying "Show Desktop" will minimize everything on the screen.
If Speech Recognition is having difficulties understanding your voice, you can always use the Show numbers command as everything on the screen has a number. Then say the number and speak OK to execute the command.

Here are some common tasks that will get you started with Speech Recognition:
Starting Speech Recognition
To launch the experience, just open the Start menu , search for Windows Speech Recognition , and select the top result.
Turning on and off
To start using the feature, click the microphone button or say Start listening depending on your configuration.

In the same way, you can turn it off by saying Stop listening or clicking the microphone button.
Using commands
Some of the most frequent commands you'll use include:
- Open — Launches an app when saying "Open" followed by the name of the app. For example, "Open Mail," or "Open Firefox."
- Switch to — Jumps to another running app when saying "Switch to" followed by the name of the app. For example, "Switch to Microsoft Edge."
- Control window in focus — You can use the commands "Minimize," "Maximize," and "Restore" to control an active window.
- Scroll — Allows you to scroll in a page. Simply use the command "Scroll down" or "Scroll up," "Scroll left" or "Scroll right." It's also possible to specify long scrolls. For example, you can try: "Scroll down two pages."
- Close app — Terminates an application by saying "Close" followed by the name of the running application. For example, "Close Word."
- Clicks — Inside an application, you can use the "Click" command followed by the name of the element to perform a click. For example, in Word, you can say "Click Layout," and Speech Recognition will open the Layout tab. In the same way, you can use "Double-click" or "Right-click" commands to perform those actions.
- Press — This command lets you execute shortcuts. For example, you can say "Press Windows A" to open Action Center.
Using dictation
Speech Recognition also includes the ability to convert voice into text using the dictation functionality, and it works automatically.
If you need to dictate text, open the application (making sure the feature is in listening mode) and start dictating. However, remember that you'll have to say each punctuation mark and special character.
For example, if you want to insert the "Good morning, where do you like to go today?" sentence, you'll need to speak, "Open quote good morning comma where do you like to go today question mark close quote."
In the case that you need to correct some text that wasn't recognized accurately, use the "Correct" command followed by the text you want to change. For example, if you meant to write "suite" and the feature recognized it as "suit," you can say "Correct suit," select the suggestion using the correction panel or say "Spell it" to speak the correct text, and then say "OK".

Wrapping things up
Although Speech Recognition doesn't offer a conversational experience like a personal assistant, it's still a powerful tool for anyone who needs to control their device entirely using only voice.
Cortana also provides the ability to control a device with voice, but it's limited to a specific set of input commands, and it's not possible to control everything that appears on the screen.
However, that doesn't mean that you can't get the best of both worlds. Speech Recognition runs independently of Cortana, which means that you can use the Microsoft's digital assistant for certain tasks and Speech Recognition to navigate and execute other commands.
It's worth noting that this speech recognition isn't available in every language. Supported languages include English (U.S. and UK), French, German, Japanese, Mandarin (Chinese Simplified and Chinese Traditional), and Spanish.
While this guide is focused on Windows 10, Speech Recognition has been around for a long time, so you can refer to it even if you're using Windows 8.1 or Windows 7.
More Windows 10 resources
For more helpful articles, coverage, and answers to common questions about Windows 10, visit the following resources:
- Windows 10 on Windows Central – All you need to know
- Windows 10 help, tips, and tricks
- Windows 10 forums on Windows Central
Mauro Huculak has been a Windows How-To Expert contributor for WindowsCentral.com for nearly a decade and has over 15 years of experience writing comprehensive guides. He also has an IT background and has achieved different professional certifications from Microsoft, Cisco, VMware, and CompTIA. He has been recognized as a Microsoft MVP for many years.
- 2 Microsoft 'temporarily' pumps the brakes on its intrusive Windows 11 ads after receiving constant backlash from Windows 10 users
- 3 Remember Fallout Shelter? Bethesda does, and now there's an Elder Scrolls version coming soon to a phone near you
- 4 Collecting old Xbox 360 games used to be fun, but it's quickly getting far too expensive for normal gamers to enjoy and I hate it
- 5 Dragon Age: The Veilguard's release date officially announced — here's when you can play this RPG on Xbox and PC
Bill Barrow, Associated Press Bill Barrow, Associated Press
Leave your feedback
- Copy URL https://www.pbs.org/newshour/politics/watch-live-trump-delivers-remarks-on-economic-policy-at-campaign-rally-in-asheville-nc
WATCH: Trump makes big economic promises and veers off topic during speech in Asheville, NC
ASHEVILLE, N.C. (AP) — Donald Trump made little effort to stay on message Wednesday at a rally in North Carolina that his campaign billed as a big economic address, mixing pledges to slash energy prices and “unleash economic abundance” with familiar off-script tangents on Democratic nominee Kamala Harris’ laugh, the mechanics of wind energy and President Joe Biden’s son.
Watch live in the player above.
The 75-minute speech featured a litany of broad policy ideas and even grander promises to end inflation, bolster already record-level U.S. energy production and raise Americans’ standard of living. But those pronouncements were often lost in the former president’s typically freewheeling, grievance-laden speaking style as he tries to blunt the enthusiasm of Harris’ nascent campaign.
Trump aired his frustration over the Democrats swapping the vice president in place of Biden at the top of their presidential ticket. He repeatedly denigrated San Francisco, where Harris was once the district attorney, as “unlivable” and went after his rival in deeply personal terms, questioning her intelligence, saying she has “the laugh of a crazy person” and musing that Democrats were being “politically correct” in trying to elevate the first Black woman and person of south Asian descent to serve as vice president.
“You know why she hasn’t done an interview? She’s not smart. She’s not intelligent. And we’ve gone through enough of that with this guy, crooked Joe,” Trump said, using the nickname he often uses for Biden.
WATCH: How Trump’s wish for more Federal Reserve control could impact economy if he’s reelected
When he was focusing on policy, Trump pledged to end “job-killing regulations,” roll back Biden-era restrictions on fossil fuel production and investments in green energy, instruct Cabinet members to use “every tool” to “defeat inflation” within the first year of a second term and end all taxes on Social Security benefits and income classified as tips. Specifically, he pledged to lower Americans’ energy costs by “50 to 70 percent” within 12 months, or a “maximum 18 months.”
But he immediately hedged: “If it doesn’t work out, you’ll say, oh well, I voted for him and he still got it down a lot.”
Trump spoke at Harrah’s Cherokee Center, an auditorium in downtown Asheville, with his podium flanked by more than a dozen American flags and custom backdrops that read: “No tax on Social Security” and “No tax on tips” — a scene that seemed to project the policy heft his campaign wanted Trump to convey.
Republicans had been looking for him to focus more on the economy than the scattershot arguments and attacks he has made on Harris since Democrats shifted to her as their presidential nominee. Twice in the past week, Trump has virtually bypassed such opportunities, first in an hourlong news conference at his Mar-a-Lago estate in Florida, then in a 2 1/2-hour conversation on the social media platform X with CEO Elon Musk.
WATCH: Trump holds news conference at Mar-a-Lago
When he stayed on script Wednesday, Trump contrasted the current economy with his own presidency, asking, “Is anything less expensive under Kamala Harris and Crooked Joe?”
“Kamala has declared that tackling inflation will be a ‘Day One priority’ for her,” Trump said. “But Day One for Kamala was three and a half years ago. Why hasn’t she done it?”
Yet throughout his speech, Trump ping-ponged between his prepared remarks and familiar attacks — deviating from the teleprompter in the middle of explaining a new economic promise when something triggered another thought. He ticked through prepared remarks crisply and quickly. The rest was his more wide-ranging style, punctuated with hand gestures and hyperbole.
More than once, he jumped from a policy contrast with Harris to taking another swipe at her hometown of San Francisco. He also noted several times that it was Biden, not Harris, who earned votes from Democratic primary voters. During a section of his speech on energy, he slipped in an apparent dig at Hunter Biden, the president’s son, and his “laptop from hell.”
READ MORE: Trump recounts assassination attempt and deportations with Musk during chat on X
Trump sought to connect his emphasis on the border and immigration policy to the economy. He repeated his dubious claim that the influx would strain Social Security and Medicare to the point of collapse. He bemoaned the taxpayer money being spent on housing migrants in some U.S. cities, including his native New York. But most of the time he spent on immigration was the same broadsides about immigrants and violent crime that have been a staple of Trump’s speeches since 2015.
The latest attempt to reset his campaign comes in the state that delivered Trump his closest statewide margin of victory four years ago and that is once again expected to be a battleground in 2024.
Trump aides have long thought that an inflationary economy was an albatross for Democrats this year. But the event in Asheville only amplifies questions about whether Trump can effectively make it a centerpiece of his matchup against Harris.
The speech came the same day that the Labor Department reported that year-over-year inflation reached its lowest level in more than three years in July, a potential reprieve for Harris in the face of Trump’s attacks over inflation. Harris plans to be in North Carolina on Friday to release more details of her promise to make “building up the middle class … a defining goal of my presidency.”
READ MORE: Americans view Harris as more honest and disciplined, slightly favor Trump on economy and immigration, AP-NORC poll finds
A new poll from The Associated Press-NORC Center for Public Affairs Research finds that Americans are more likely to trust Trump over Harris when it comes to handling the economy, but the difference is slight — 45 percent for Trump and 38 percent for Harris.
Some voters who came to hear Trump said they were ready to hear him talk more specifically about his plans, not because they don’t already trust him but because they want him to expand his appeal ahead of Election Day.
“He needs to tell people what he’s going to do, talk about the issues,” said Timothy Vath, a 55-year-old who drove from Greenville, South Carolina. “He did what he said he was going to do” in his initial term. “Talk about how he’d do that again.”
Mona Shope, a 60-year-old from nearby Candler, said Trump, despite his own wealth, “understands working people and wants what’s best for us.” A recent retiree from a public community college, Shope said she has a state pension but has picked up part-time work to mitigate against inflation. “It’s so I can still have vacations and spending money after paying my bills,” she said. “Sometimes it feels like there’s nothing left to save.”
READ MORE: Harris cautious on policy, aims to outmaneuver Trump and address 2020 vulnerabilities
In some of his off-script moments, Trump ventured into familiar misrepresentations of fact, including when he mocked wind energy by suggesting people would face power outages when the wind wasn’t blowing.
Trump again claimed that inflation would not have spiked had he been reelected, ignoring the global supply chain interruptions during the COVID-19 pandemic, COVID-19 spending boosts that included a massive aid package Trump signed as president, and the global energy price effects of Russia’s invasion of Ukraine.
A Harris aide said Wednesday that the vice president welcomes any comparison Trump is able to make.
“No matter what he says, one thing is certain: Trump has no plan, no vision, and no meaningful interest in helping build up the middle class,” communications director Michael Tyler wrote in a campaign memo. Tyler pointed to the economic slowdown of the pandemic and 2017 tax cuts that were tilted to corporations and wealthy individual households, and predicted Trump’s proposals on trade, taxation and reversing Biden-era policies would “send inflation skyrocketing and cost our economy millions of jobs – all to benefit the ultra-wealthy and special interests.”
Support Provided By: Learn more
Educate your inbox
Subscribe to Here’s the Deal, our politics newsletter for analysis you won’t find anywhere else.
Thank you. Please check your inbox to confirm.

- Speech and Voice Recognition Market
"Smart Strategies, Giving Speed to your Growth Trajectory"
Speech and Voice Recognition Market Size, Share & Industry Analysis, By Technology (Voice Recognition and Speech Recognition), By Deployment (Cloud and On-Premise), By End-user (Healthcare, IT and Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail & Ecommerce, Media & Entertainment, and Others), and Regional Forecast, 2024-2032
Last Updated: July 29, 2024 | Format: PDF | Report ID: FBI101382
- Segmentation
- Methodology
- Infographics
- Request Sample PDF
KEY MARKET INSIGHTS
The global speech and voice recognition market size was valued at USD 12.62 billion in 2023. The market is projected to be worth USD 15.46 billion in 2024 and reach USD 84.97 billion by 2032, exhibiting a CAGR of 23.7% during the forecast period (2024-2032). Pattern recognition is used to turn speech into a series of words in speech and voice recognition technologies. This enables users to receive prompt responses by verbally addressing the systems rather than typing or scrolling through the screen with the assistance of voice and speech software.
Moreover, ongoing advances in Natural Language Processing (NLP) , Machine Learning (ML), and Automated Speech Recognition (ASR), along with the massive amount of data and availability of AI based platforms have led to an exponential increase in the capabilities to process voice at a larger scale. For instance,
- In August 2023, Meta introduced an AI model for speech and text translation into nearly a hundred languages. By reducing delays and errors in the translation process, this new model improves efficiency and quality.
- In August 2021, LumenVox launched Automatic Speech Recognition (ASR) engine with transcription. The next-generation speech and voice recognition technology was built on deep Machine Learning (ML) and Artificial Intelligence (AI), delivering accurate speech-enabled customer experiences.
The COVID-19 pandemic augmented the development of various technologies that stimulate safety and social distancing, from telemedicine to contactless payments. Speech and voice recognition software played a vital role during the COVID-19 pandemic.
Speech and Voice Recognition Market Trends
Machine Learning and Artificial Intelligence to be the Nexus Point of Innovation and a Key Trendsetter for Speech and Voice Recognition
The evolution of artificial intelligence is creating potential opportunities for the digitalization of numerous industries. The dominance of AI-powered devices indicates that search algorithms and systems have evolved to improve machine learning and its applications in daily life. Google's RankBrain is a crucial example designed to recognize phrases and words to learn, understand, and better predict outcomes. It uses machine learning and natural language processing technologies to transcript voice searches.
Moreover, web conferencing tools have gained popularity in the industry. Speech and voice recognition technology can further improve web conferencing by providing post-call transcripts through real-time captioning from calls.
As per the Speechmatics Voice report, in 2021, web conference transcription accounts for around 44% of the voice technology market share and is one of the top applications that will have the most significant commercial impact.
Request a Free sample to learn more about this report.
Speech and Voice Recognition Market Growth Factors
Rising Use of Deep Neural Engines and Networks to Increase Speech and Voice System Demand
Superior adoption of emerging technologies, such as IoT, AI, and machine learning, fuels the speech and voice recognition market growth. Voice-based authentications in smartphone applications have increased the demand for voice and speech biometric systems. Moreover, the usage of deep learning and neural networks in applications, such as audio-visual speech recognition, isolated word recognition, speaker adaptation, and digital speaker recognition, is propelling the demand for voice technologies. Key players are focusing on such emerging technological advancements to grow their businesses in the long run. For instance,
- In April 2022, Google LLC released speech recognition technology to help boost the voice UI. Google's Speech-to-Text API utilizes a neural sequence-to-sequence model to further develop exactness in 23 dialects and 61 of the supported localities.
RESTRAINING FACTORS
Speaker Diarization & Accuracy in Multilinguistic Approach to Hinder Speech Recognition Technology Demand
As voice technology continues to excel, developers and engineers have been trying to surpass difficulties related to speech software. Factors frequently seen hindering the seamless performance of speech and voice recognition systems include fluency, punctuation, accent, technical words/jargon, background noise, and speaker identification. One of the biggest challenges in voice is the breakthrough in accuracy for languages other than American English. As per the Speechmatics Voice report, in 2021, around 30.4% and 21.2% account for concerns related to accent and dialect, respectively.
Voice-based technologies will sustain to deliver more customized experiences as they better differentiate and identify users' voices. However, the threat to voice data privacy remains, which hinders the market growth.
Speech and Voice Recognition Market Segmentation Analysis
By technology analysis.
Rising Deployment of Smart Appliances and Behavioral Shift of Consumers to Propel Speech Recognition Demand
On the basis of technology, the market is divided into speech recognition and voice recognition.
Speech recognition segment holds the largest market share and is estimated to continue its dominance over the forecast period. The continuous advancements in Artificial Intelligence (AI) and the development of smart appliances with the availability of high-speed internet connectivity have increased the growth of the market. In addition, this technology enables doctors and radiologists to keep patient records due to benefits such as shorter turnaround times for reports. The market demand is projected to increase as a result of the integration of speech recognition with Virtual Reality (VR).
Further, the voice recognition segment is anticipated to witness the highest growth rate during the projection period. This is due to increased adoption across banking and finance institutions, contact centers, and healthcare institutions to reduce fraudulent activities. AI-based speech and voice recognition software identify the speech pattern of users and speaker voice, which is expected to boost the market growth.
By Deployment Analysis
Surging Adoption of Cloud-based Solutions by Small & Medium Enterprises to Augment Segment Share
On the basis of deployment, the market is categorized into on-premise and cloud. The cloud segment is expected to rise with the highest CAGR, owing to escalating demand for cloud solutions. The increased adoption of cloud technology among organizations is expected to drive cloud deployments during the forecast period.
However, the on-premise segment is expected to show a slow demand during the projection period owing to increasing adoption of cloud-based solutions among SMEs.
By End-user Analysis
To know how our report can help streamline your business, Speak to Analyst
Increasing Product Demand in Healthcare to Impel Industry Growth
By end-user, the market is classified into healthcare, IT & telecommunications, BFSI, automotive, government & legal, education, retail & ecommerce, media & entertainment, and others.
The demand for speech and voice recognition software has increased drastically among healthcare and BFSI, owing to the COVID-19 outbreak. The process of capturing data in electronic health records systems is enhanced by speech recognition. By speaking a few words, physicians are empowered to interact with the system. The development and deployment of speech recognition in individual healthcare segments, such as radiology, pathology, emergency medicine, and others, is still ongoing.
- In September 2021, clinical voice solutions provider Scribetech introduced Augnito, a cloud-based, AI-powered, secure, and portable speech recognition platform. The solution offered an efficient and fast way to collect live clinical data on any device, including smartphone, Windows, or Mac, with higher accuracy. It was also equipped to automatically transcribe referrals, medical records, and patient letters into clinical documentation at the point of dictation.
REGIONAL INSIGHTS
The global market scope is classified across five regions, North America, South America, Europe, the Middle East & Africa, and Asia Pacific.
North America Speech and Voice Recognition Market Size, 2023 (USD Billion)
To get more information on the regional analysis of this market, Request a Free sample
In 2023, North America held the highest market share. The presence of prominent market players such as Amazon Web Services, Inc., IBM, Google LLC, and Microsoft Corporation, among others contributes to market growth. The growing adoption of smart home appliances with voice assistants is expected to spur market expansion. For instance, as per the Voicebot.AI 2021 report, 45.2 million U.S. adults leveraged voice search for shopping a product at least once.
Asia Pacific is projected to expand at the highest rate during the analysis period. The surge in adoption of AI technology across BFSI, healthcare, automotive, and government is anticipated to boost the implementation of voice technology across the region.
Similarly, Europe is expected to showcase remarkable growth in the coming years owing to increased innovations and advancements in voice assistants to support French, Spanish, Russian, and other European languages.
Further, recent developments in Latin American countries will foster the market growth in this region. For instance,
- In June 2022, Minds Digital, Brazil-based voice biometrics developer, raised USD 305,000 in seed funding round.
- In April 2022, AWS added Alexa voice services in Chile, Argentina, Costa Rica, and Peru.
List of Key Companies in Speech and Voice Recognition Market
Strategic Collaborations and Partnerships to Expand Product Reach of Key Players
Major global corporations are forming alliances and partnerships with other players to streamline and grow their business operations. The key players adopt this strategy to support their product portfolio and expand the scale of their operations. For instance,
- January 2024: RAZ Mobility integrated speech recognition technology into its Memory cell phone to enable it to recognize nonstandard spoken language. The integration of this technology into the RAZ Memory cell phone enables people with speech impairment to use telecommunications in a completely new way.
- November 2023: Assembly Software, a reseller of Nuance Communications, launched its Neos case management platform with the cloud-based Nuance Dragon Legal Anywhere speech recognition solution for legal experts. With the addition of Dragon Legal Anywhere to the Neos platform, legal practitioners can streamline their processes and easily dictate directly to the platform.
List of Key Companies Profiled:
- Alphabet Inc. (U.S.)
- Amazon Web Services, Inc. (U.S.)
- Microsoft Corporation (U.S.)
- IBM Corporation (U.S.)
- Apple Inc. (U.S.)
- Baidu, Inc. (China)
- iFLYTEK Co., Ltd. (China)
- SESTEK (Turkey)
- LumenVox (U.S.)
- Sensory Inc. (U.S.)
KEY INDUSTRY DEVELOPMENTS
- May 2023 – Webex by Cisco, a video conferencing platform, and the speech recognition technology company, Voiceitt, announced a partnership aiming to make virtual meetings more accessible to people with speech impairments. Transcription for people with speech impairments and real-time AI-enabled captioning, will be made possible as a result of the partnership so that users can understand during Webex virtual meetings.
- January 2023 – iFLYTEK launched its pre-trained industrial AI models at the iFLYTEK Global 1024 Developers’ Day, 2022. The pre-trained AI model can be deployed for a range of services such as emotion recognition, speech recognition, and others. The pre-trained AI-based speech recognition model is intended to give complete speech recognition services.
- August 2022 – iFLYTEK launched multilingual AI subtitling solutions in addition to translation and transcription services for live and video streams. The solution enabled machine translation between Chinese and 168 languages and speech and voice recognition for 70 languages.
- June 2022 – STMicroelectronics, a worldwide semiconductor organization serving clients across the range of electronics applications, and Tangible Inc., a company providing embedded speech recognition technology and a ST Approved partner, announced a partnership that empowers the STM32 microcontroller (MCU) user community to create and model intuitive voice-based UIs for a large variety of smart embedded products.
- September 2021 – IBM Corporation launched additional automation and AI capabilities in IBM Watson Assistant to make it easy for firms to create great customer experiences. This launch includes a new partnership with IntelePeer to test a voice agent. IntelePeer is a Communications Platform-as-a-Service provider.
- August 2021 – Amazon Transcribe supports group transcription in six new dialects - Danish, Afrikaans, Mandarin Chinese (Taiwan), New Zealand English, Thai, and South African English. These dialects are accessible in all open AWS regions where Amazon Transcribe is accessible.
REPORT COVERAGE
An Infographic Representation of Speech and Voice Recognition Market

To get information on various segments, share your queries with us
The research report highlights leading regions across the world to offer a better understanding to the user. Furthermore, the report provides insights into the latest industry and market trends and analyzes technologies deployed at a rapid pace at the global level. It further highlights some growth-stimulating factors and restraints, helping the reader gain an in-depth knowledge about the market.
REPORT SCOPE & SEGMENTATION
|
|
| 2019–2032 |
| 2023 |
| 2024 |
| 2024–2032 |
| 2019–2022 |
| CAGR of 23.7% from 2024 to 2032 |
| Value (USD Billion) |
|
|
Frequently Asked Questions
Fortune Business Insights says that the market was valued at USD 12.62 billion in 2023.
Fortune Business Insights says that the market is expected to reach USD 84.97 billion in 2032.
The market is anticipated to grow at a CAGR of 23.7% during the forecast period (2024-2032).
The IT and telecommunications segment is expected to hold the highest revenue share in 2022.
The rising popularity of speech recognition technology among voice-based IVRs for better customer experience is the key factor driving the market growth.
Alphabet Inc., Amazon Web Services (AWS) Inc., Microsoft Corporation, IBM Corporation, Apple Inc., Baidu, Inc., iFLYTEK Co., Ltd., SESTEK, LumenVox, and Sensory Inc. are the top players in the market.
The Asia Pacific market is expected to grow with a remarkable CAGR over the estimated period.
In 2023, North America held the highest market share.
Seeking Comprehensive Intelligence on Different Markets? Get in Touch with Our Experts
- STUDY PERIOD: 2019-2032
- BASE YEAR: 2023
- HISTORICAL DATA: 2019-2022
- NO OF PAGES: 150
Personalize this Research
- Granular Research on Specified Regions or Segments
- Companies Profiled based on User Requirement
- Broader Insights Pertaining to a Specific Segment or Region
- Breaking Down Competitive Landscape as per Your Requirement
- Other Specific Requirement on Customization

Information & Technology Clients

Related Reports
- Speech-to-Text API Market
- Voice Biometric Solutions Market
- Intelligent Virtual Assistant Market
Client Testimonials
“We are quite happy with the methodology you outlined. We really appreciate the time your team has spent on this project, and the efforts of your team to answer our questions.”
“Thanks a million. The report looks great!”
“Thanks for the excellent report and the insights regarding the lactose market.”
“I liked the report; would it be possible to send me the PPT version as I want to use a few slides in an internal presentation that I am preparing.”
“This report is really well done and we really appreciate it! Again, I may have questions as we dig in deeper. Thanks again for some really good work.”
“Kudos to your team. Thank you very much for your support and agility to answer our questions.”
“We appreciate you and your team taking out time to share the report and data file with us, and we are grateful for the flexibility provided to modify the document as per request. This does help us in our business decision making. We would be pleased to work with you again, and hope to continue our business relationship long into the future.”
“I want to first congratulate you on the great work done on the Medical Platforms project. Thank you so much for all your efforts.”
“Thank you very much. I really appreciate the work your team has done. I feel very comfortable recommending your services to some of the other startups that I’m working with, and will likely establish a good long partnership with you.”
“We received the below report on the U.S. market from you. We were very satisfied with the report.”
“I just finished my first pass-through of the report. Great work! Thank you!”
“Thanks again for the great work on our last partnership. We are ramping up a new project to understand the imaging and imaging service and distribution market in the U.S.”
“We feel positive about the results. Based on the presented results, we will do strategic review of this new information and might commission a detailed study on some of the modules included in the report after end of the year. Overall we are very satisfied and please pass on the praise to the team. Thank you for the co-operation!”
“Thank you very much for the very good report. I have another requirement on cutting tools, paper crafts and decorative items.”
“We are happy with the professionalism of your in-house research team as well as the quality of your research reports. Looking forward to work together on similar projects”
“We appreciate the teamwork and efficiency for such an exhaustive and comprehensive report. The data offered to us was exactly what we were looking for. Thank you!”
“I recommend Fortune Business Insights for their honesty and flexibility. Not only that they were very responsive and dealt with all my questions very quickly but they also responded honestly and flexibly to the detailed requests from us in preparing the research report. We value them as a research company worthy of building long-term relationships.”
“Well done Fortune Business Insights! The report covered all the points and was very detailed. Looking forward to work together in the future”
“It has been a delightful experience working with you guys. Thank you Fortune Business Insights for your efforts and prompt response”
“I had a great experience working with Fortune Business Insights. The report was very accurate and as per my requirements. Very satisfied with the overall report as it has helped me to build strategies for my business”
“This is regarding the recent report I bought from Fortune Business insights. Remarkable job and great efforts by your research team. I would also like to thank the back end team for offering a continuous support and stitching together a report that is so comprehensive and exhaustive”
“Please pass on our sincere thanks to the whole team at Fortune Business Insights. This is a very good piece of work and will be very helpful to us going forward. We know where we will be getting business intelligence from in the future.”
“Thank you for sending the market report and data. It looks quite comprehensive and the data is exactly what I was looking for. I appreciate the timeliness and responsiveness of you and your team.”
Get in Touch with Us
+1 424 253 0390 (US)
+44 2071 939123 (UK)
+91 744 740 1245 (APAC)
[email protected]
- Request Sample
Sharing this report over the email

The global speech and voice recognition market size is projected to be worth $15.46 billion in 2024 and reach $84.97 billion by 2032, at a CAGR of 23.7%
Read More at:-
- SI SWIMSUIT
- SI SPORTSBOOK
- Buckeyes In the NFL
Ohio State Buckeyes' Star Playmaker Earns Major Recognition For 2024
Matthew schmidt | aug 14, 2024.
 runs during football practice at the Woody Hayes Athletic Complex.")
- Ohio State Buckeyes
There is a ton of hype surrounding Ohio State Buckeyes wide receiver Jeremiah Smith heading into his freshman season, and for good reason.
Smith is expected to make an impact right off the bat in Columbus, which is why CBS Sports has named him Freshman of the Year heading into the 2024 campaign.
Just as soon as one freakish receiver in Marvin Harrison Jr. departed Ohio State, another has arrived.
During his senior year at Chaminade-Madonna Prep in Miami, Fl., Smith hauled in 88 receptions for 1,376 yards and 19 touchdowns.
The 6-foot-3, 215-pound pass-catcher certainly has the profile of an elite receiver, and he appears to have the tools and abilities to become one, as well.
The question is, just how effective will Smith be right off the bat?
It's always tough for college players to play a significant role in their debut campaigns. Even Harrison didn't do all that much in his first season with the Buckeyes, logging 11 catches for 139 yards and three scores in 2021.
However, things could very well be different for Smith, who is expected by many to be a key cog in Ohio State's offense from Day 1.
Smith joins a loaded Buckeyes receiving corps that features junior Emeka Egbuka, sophomores Carnell Tate and Brandon Inniss as well as fellow incoming freshman Mylan Graham (who has apparently been looking pretty impressive in his own right).
We'll get to see Smith on the field (hopefully) when Ohio State hosts Akron in the season opener on Aug. 31.
MATTHEW SCHMIDT
IMAGES
COMMENTS
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format. While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal ...
Speech recognition, also known as automatic speech recognition (ASR), enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications, including customer service, healthcare, finance and sales.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition ( ASR ), computer speech recognition or speech-to-text ( STT ).
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing, audio inputs, machine learning, and voice recognition. Speech recognition systems analyze speech patterns to identify phonemes, the basic units of sound in a language.
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It's also known as automatic speech recognition (ASR), speech-to-text, or computer speech recognition. Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger ...
Discover what automatic speech recognition (ASR) means for practitioners. Learn about ARS advancements, challenges, industry impact, and more.
Photo: Using a headset microphone like this makes a huge difference to the accuracy of speech recognition: it reduces background sound, making it much easier for the computer to separate the signal (the all-important words you're speaking) from the noise (everything else).
Speech recognition converts human speech into text, simplifying the way we operate devices. Learn how speech recognition works, how it has evolved, and more.
Speech recognition works by using artificial intelligence to recognize the words or language that a person speaks and then translate that content into text. It's important to note that this technology is still in its infancy but is improving its accuracy rapidly.
Learn about speech recognition technology—how speech to text software works, benefits, limitations, transcriptions, and other real world applications. Whether you're a professional in need of more efficient transcription solutions or simply want your voice-enabled device to work smarter for you, this guide to speech recognition technology is here with all the answers.
Voice recognition is a set of algorithms that the assistants use to convert your speech into a digital signal and ascertain what you're saying. Programs like Microsoft Word use voice recognition to help type down words.
You can define speech recognition as a technology (or a set of technologies) that accept human voice as input, process this raw audio into structured text, and generate some kind of output which could be either a transcription of the text, and analysis, or an automated action). Unlike voice recognition that seeks to match a series of uttered ...
Learn how voice recognition works, and the challenges it faces, in this explainer video from iluli by Mike Lamb - explaining the ideas and innovations changing our lives.
Speech recognition or speech-to-text recognition, is the capacity of a machine or program to recognize spoken words and transform them into text. Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. In this article, we are going to discuss every point about speech recognition.
Speech recognition is a proven technology. Indeed, voice interfaces and voice assistants are now more powerful than ever and are developing in many fields. This exponential and continuous growth is leading to a diversification of speech recognition applications and related technologies.
The history of voice recognition technology pre-dates the entrance of Google, Amazon, and Apple. Here, we look at the past, present, and future of this technology.
Speech recognition technology allows computers to take spoken audio, interpret it and generate text from it. But how do computers understand human speech? The short answer is…the wonder of signal processing.
Voice recognition technology can interpret speech and identify a single speaker. Like fingerprints, individual's have unique markers in their voices that technology can use to identify them. Many companies are already using this tool to authenticate that a person is indeed the individual they claim to be when speaking.
The Future of Speech Recognition: Where Will We Be in 2030? 20.Aug.2022 . 11 min read. The last two years have been some of the most exciting and highly anticipated in Automatic Speech Recognition's (ASR's) long and rich history, as we saw multiple enterprise-level fully neural network-based ASR models go to market (e.g. Alexa, Rev ...
Speech recognition in artificial intelligence is a game-changing development for businesses. Speech recognition enables machines and computers to understand human voice or speech data and respond intelligently. This incredible capability has transformed the way we interact with technology, making tasks more convenient and accessible than ever ...
Explore the leading speech recognition software on the market to find the best one for your business. Learn more about features, pricing, and more.
Discover the top 18 speech recognition companies revolutionizing the industry. Explore the advanced technologies of Atexto and SoundHound for enhanced language support.
Windows 10 has a hands-free using Speech Recognition feature, and in this guide, we show you how to set up the experience and perform common tasks.
Donald Trump made little effort to stay on message Wednesday at a rally in North Carolina that his campaign billed as a big economic address, mixing pledges to slash energy prices and "unleash ...
The global speech and voice recognition market size is projected to be worth $15.46 billion in 2024 and reach $84.97 billion by 2032, at a CAGR of 23.7%
Ohio State Buckeyes' Star Playmaker Earns Major Recognition For 2024 ... Ohio State Buckeyes WR Jeremiah Smith Opens Up About His Main Focus ... No one should expect to make money from the picks ...
Former President Donald Trump held a news conference on Thursday in which he continued to be highly dishonest - again making more than 20 false claims, as he also did in his Monday conversation ...
Mr. Trump's remarks on the economy and his insults aimed at Ms. Harris suggested the Trump campaign continues to suffer growing pains as it adjusts to a new opponent.
Joe Biden offered a glowing endorsement of Kamala Harris, and Donald Trump spoke in New Jersey.
Elon Musk, the owner of the X platform, was a sympathetic interviewer, and the former president rattled off familiar lines from his stump speech.