- About AssemblyAI

The top free Speech-to-Text APIs, AI Models, and Open Source Engines
This post compares the best free Speech-to-Text APIs and AI models on the market today, including APIs that have a free tier. We’ll also look at several free open-source Speech-to-Text engines and explore why you might choose an API vs. an open-source library, or vice versa.

Choosing the best Speech-to-Text API , AI model, or open-source engine to build with can be challenging. You need to compare accuracy, model design, features, support options, documentation, security, and more.
This post examines the best free Speech-to-Text APIs and AI models on the market today, including ones that have a free tier, to help you make an informed decision. We’ll also look at several free open-source Speech-to-Text engines and explore why you might choose an API or AI model vs. an open-source library, or vice versa.
Looking for a powerful speech-to-text API or AI model?
Learn why AssemblyAI is the leading Speech AI partner.
Free Speech-to-Text APIs and AI Models
APIs and AI models are more accurate, easier to integrate, and come with more out-of-the-box features than open-source options. However, large-scale use of APIs and AI models can come with a higher cost than open-source options.
If you’re looking to use an API or AI model for a small project or a trial run, many of today’s Speech-to-Text APIs and AI models have a free tier. This means that the API or model is free for anyone to use up to a certain volume per day, per month, or per year.
Let’s compare three of the most popular Speech-to-Text APIs and AI models with a free tier: AssemblyAI, Google, and AWS Transcribe.
AssemblyAI offers speech AI models via an API that product teams and developers can use to build powerful AI solutions based on voice data for their users.
AssemblyAI offers cutting-edge AI models such as Speaker Diarization , Topic Detection, Entity Detection , Automated Punctuation and Casing , Content Moderation , Sentiment Analysis , Text Summarization , and more. These AI models help users get more out of voice data, with continuous improvements being made to accuracy .
The company offers a $50 credit to get users started with speech-to-text.
AssemblyAI also offers Speech Understanding models, including Audio Intelligence models and LeMUR. LeMUR enables users to leverage Large Language Models (LLMs) to pull valuable information from their voice data—including answering questions, generating summaries and action items, and more.
Its high accuracy and diverse collection of AI models built by AI experts make AssemblyAI a sound option for developers looking for a free Speech-to-Text API. The API also supports virtually every audio and video file format out-of-the-box for easier transcription.
AssemblyAI offers two options for Speech-to-Text: "Best" and "Nano. " Best is the default model, which gives users access to the company's most accurate and advanced Speech-to-Text offering to help users capture the nuances of voice data. The company's Nano tier offers high-quality Speech-to-Text at an accessible price point for users that require cost efficiency.
AssemblyAI has expanded the languages it supports to include 17 different languages for its Best offering and 102 languages for its Nano offering, with additional languages released monthly. See the full list here .
AssemblyAI’s easy-to-use models also allow for quick set-up and transcription in any programming language. You can copy/paste code examples in your preferred language directly from the AssemblyAI Docs or use the AssemblyAI Python SDK or another one of its ready-to-use integrations .
- Free to test in the AI playground , plus $50 credits with an API sign-up
- Speech-to-Text Best – $0.37 per hour
- Speech-to-Text Nano – $0.12 per hour
- Streaming Speech-to-Text – $0.47 per hour
- Speech Understanding – varies
- Volume pricing is also available
See the full pricing list here .
- High accuracy
- Breadth of AI models available, built by AI experts
- Continuous model iteration and improvement
- Developer-friendly documentation and SDKs
- Pay as you go and custom plans
- White glove support
- Strict security and privacy practices
- Models are not open-source
Google Speech-to-Text is a well-known speech transcription API. Google gives users 60 minutes of free transcription, with $300 in free credits for Google Cloud hosting.
Google only supports transcribing files already in a Google Cloud Bucket, so the free credits won’t get you very far. Google also requires you to sign up for a GCP account and project — whether you're using the free tier or paid.
With good accuracy and 125+ languages supported, Google is a decent choice if you’re willing to put in some initial work.
- 60 minutes of free transcription
- $300 in free credits for Google Cloud hosting
- Decent accuracy
- Multi-language support
- Only supports transcription of files in a Google Cloud Bucket
- Difficult to get started
- Lower accuracy than other similarly-priced APIs
- AWS Transcribe
AWS Transcribe offers one hour free per month for the first 12 months of use.
Like Google, you must create an AWS account first if you don’t already have one. AWS also has lower accuracy compared to alternative APIs and only supports transcribing files already in an Amazon S3 bucket.
However, if you’re looking for a specific feature, like medical transcription, AWS has some options. Its Transcribe Medical API is a medical-focused ASR option that is available today.
- One hour free per month for the first 12 months of use
- Tiered pricing , based on usage, ranges from $0.02400 to $0.00780
- Integrates into existing AWS ecosystem
- Medical language transcription
- Difficult to get started from scratch
- Only supports transcribing files already in an Amazon S3 bucket
Open-Source Speech Transcription engines
An alternative to APIs and AI models, open-source Speech-to-Text libraries are completely free--with no limits on use. Some developers also see data security as a plus, since your data doesn’t have to be sent to a third party or the cloud.
There is work involved with open-source engines, so you must be comfortable putting in a lot of time and effort to get the results you want, especially if you are trying to use these libraries at scale. Open-source Speech-to-Text engines are typically less accurate than the APIs discussed above.
If you want to go the open-source route, here are some options worth exploring:
DeepSpeech is an open-source embedded Speech-to-Text engine designed to run in real-time on a range of devices, from high-powered GPUs to a Raspberry Pi 4. The DeepSpeech library uses end-to-end model architecture pioneered by Baidu.
DeepSpeech also has decent out-of-the-box accuracy for an open-source option and is easy to fine-tune and train on your own data.
- Easy to customize
- Can use it to train your own model
- Can be used on a wide range of devices
- Lack of support
- No model improvement outside of individual custom training
- Heavy lift to integrate into production-ready applications
Kaldi is a speech recognition toolkit that has been widely popular in the research community for many years.
Like DeepSpeech, Kaldi has good out-of-the-box accuracy and supports the ability to train your own models. It’s also been thoroughly tested—a lot of companies currently use Kaldi in production and have used it for a while—making more developers confident in its application.
- Can use it to train your own models
- Active user base
- Can be complex and expensive to use
- Uses a command-line interface
Flashlight ASR (formerly Wav2Letter)
Flashlight ASR, formerly Wav2Letter, is Facebook AI Research’s Automatic Speech Recognition (ASR) Toolkit. It is also written in C++ and usesthe ArrayFire tensor library.
Like DeepSpeech, Flashlight ASR is decently accurate for an open-source library and is easy to work with on a small project.
- Customizable
- Easier to modify than other open-source options
- Processing speed
- Very complex to use
- No pre-trained libraries available
- Need to continuously source datasets for training and model updates, which can be difficult and costly
- SpeechBrain
SpeechBrain is a PyTorch-based transcription toolkit. The platform releases open implementations of popular research works and offers a tight integration with Hugging Face for easy access.
Overall, the platform is well-defined and constantly updated, making it a straightforward tool for training and finetuning.
- Integration with Pytorch and Hugging Face
- Pre-trained models are available
- Supports a variety of tasks
- Even its pre-trained models take a lot of customization to make them usable
- Lack of extensive docs makes it not as user-friendly, except for those with extensive experience
Coqui is another deep learning toolkit for Speech-to-Text transcription. Coqui is used in over twenty languages for projects and also offers a variety of essential inference and productionization features.
The platform also releases custom-trained models and has bindings for various programming languages for easier deployment.
- Generates confidence scores for transcripts
- Large support comunity
- No longer updated and maintained by Coqui
Whisper by OpenAI, released in September 2022, is comparable to other current state-of-the-art open-source options.
Whisper can be used either in Python or from the command line and can also be used for multilingual translation.
Whisper has five different models of varying sizes and capabilities, depending on the use case, including v3 released in November 2023 .
However, you’ll need a fairly large computing power and access to an in-house team to maintain, scale, update, and monitor the model to run Whisper at a large scale, making the total cost of ownership higher compared to other options.
As of March 2023, Whisper is also now available via API . On-demand pricing starts at $0.006/minute.
- Multilingual transcription
- Can be used in Python
- Five models are available, each with different sizes and capabilities
- Need an in-house research team to maintain and update
- Costly to run
Which free Speech-to-Text API, AI model, or Open Source engine is right for your project?
The best free Speech-to-Text API, AI model, or open-source engine will depend on our project. Do you want something that is easy-to-use, has high accuracy, and has additional out-of-the-box features? If so, one of these APIs might be right for you:
Alternatively, you might want a completely free option with no data limits—if you don’t mind the extra work it will take to tailor a toolkit to your needs. If so, you might choose one of these open-source libraries:
Whichever you choose, make sure you find a product that can continually meet the needs of your project now and what your project may develop into in the future.
Want to get started with an API?
Get a free API key for AssemblyAI.
Popular posts

AssemblyAI's C# .NET SDK + Latest Tutorials

Developer Educator

Build a Discord Voice Bot to Add ChatGPT to Your Voice Channel

Featured writer

What is speech recognition? A comprehensive guide

Announcement
Introducing the AssemblyAI C# .NET SDK

Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
Cross-platform, real-time, offline speech recognition plugin for Unreal Engine. Based on Whisper OpenAI technology, whisper.cpp.
gtreshchev/RuntimeSpeechRecognizer
Folders and files.
| Name | Name | |||
|---|---|---|---|---|
| 117 Commits | ||||
Repository files navigation
Runtime Speech Recognizer
High-performance OpenAI's Whisper speech recognition Explore the docs » Marketplace . Releases Discord support chat
Key features
- Fast recognition speed
- English-only and multilingual models available, with multilingual supporting 100 languages
- Different model sizes available (from 75 Mb to 2.9 Gb)
- Automatic download of language models in the Editor
- Optional translation of recognized speech to English
- Customizable properties
- Easy selection of model size and language in settings
- No static libraries or external dependencies
- Cross-platform compatibility (Windows, Mac, Linux, Android, iOS, etc)
Additional information
The implementation is based on whisper.cpp .
Unreal® is a trademark or registered trademark of Epic Games, Inc. in the United States of America and elsewhere.
Unreal® Engine, Copyright 1998 – 2024, Epic Games, Inc. All rights reserved.
Contributors 2
Speech to Text - Voice Typing & Transcription
Take notes with your voice for free, or automatically transcribe audio & video recordings. amazingly accurate, secure & blazing fast..
~ Proudly serving millions of users since 2015 ~
I need to >
Dictate Notes
Start taking notes, on our online voice-enabled notepad right away, for free. Learn more.
Transcribe Recordings
Automatically transcribe (& optionally translate) recordings, audio and video files, YouTubes and more, in no time. Learn more.
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe & translate your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export options, Speechnotes provides an efficient and user-friendly dictation and transcription experience. Proudly serving millions of users since 2015, Speechnotes is the go-to tool for anyone who needs fast, accurate & private transcription. Our Portfolio of Complementary Speech-To-Text Tools Includes:
Voice typing - Chrome extension
Dictate instead of typing on any form & text-box across the web. Including on Gmail, and more.
Transcription API & webhooks
Speechnotes' API enables you to send us files via standard POST requests, and get the transcription results sent directly to your server.
Zapier integration
Combine the power of automatic transcriptions with Zapier's automatic processes. Serverless & codeless automation! Connect with your CRM, phone calls, Docs, email & more.
Android Speechnotes app
Speechnotes' notepad for Android, for notes taking on your mobile, battle tested with more than 5Million downloads. Rated 4.3+ ⭐
iOS TextHear app
TextHear for iOS, works great on iPhones, iPads & Macs. Designed specifically to help people with hearing impairment participate in conversations. Please note, this is a sister app - so it has its own pricing plan.
Audio & video converting tools
Tools developed for fast - batch conversions of audio files from one type to another and extracting audio only from videos for minimizing uploads.
Our Sister Apps for Text-To-Speech & Live Captioning
Complementary to Speechnotes
Reads out loud texts, files & web pages
Listen on the go to any written content, from custom texts to websites & e-books, for free.
Speechlogger
Live Captioning & Translation
Live captions & simultaneous translation for conferences, online meetings, webinars & more.
Need Human Transcription? We Can Offer a 10% Discount Coupon
We do not provide human transcription services ourselves, but, we partnered with a UK company that does. Learn more on human transcription and the 10% discount .
Dictation Notepad
Start taking notes with your voice for free
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing.
Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts. We strive to provide the best online dictation tool by engaging cutting-edge speech-recognition technology for the most accurate results technology can achieve today, together with incorporating built-in tools (automatic or manual) to increase users' efficiency, productivity and comfort. Works entirely online in your Chrome browser. No download, no install and even no registration needed, so you can start working right away.
Speechnotes is especially designed to provide you a distraction-free environment. Every note, starts with a new clear white paper, so to stimulate your mind with a clean fresh start. All other elements but the text itself are out of sight by fading out, so you can concentrate on the most important part - your own creativity. In addition to that, speaking instead of typing, enables you to think and speak it out fluently, uninterrupted, which again encourages creative, clear thinking. Fonts and colors all over the app were designed to be sharp and have excellent legibility characteristics.
Example use cases
- Voice typing
- Writing notes, thoughts
- Medical forms - dictate
- Transcribers (listen and dictate)
Transcription Service
Start transcribing
Fast turnaround - results within minutes. Includes timestamps, auto punctuation and subtitles at unbeatable price. Protects your privacy: no human in the loop, and (unlike many other vendors) we do NOT keep your audio. Pay per use, no recurring payments. Upload your files or transcribe directly from Google Drive, YouTube or any other online source. Simple. No download or install. Just send us the file and get the results in minutes.
- Transcribe interviews
- Captions for Youtubes & movies
- Auto-transcribe phone calls or voice messages
- Students - transcribe lectures
- Podcasters - enlarge your audience by turning your podcasts into textual content
- Text-index entire audio archives
Key Advantages
Speechnotes is powered by the leading most accurate speech recognition AI engines by Google & Microsoft. We always check - and make sure we still use the best. Accuracy in English is very good and can easily reach 95% accuracy for good quality dictation or recording.
Lightweight & fast
Both Speechnotes dictation & transcription are lightweight-online no install, work out of the box anywhere you are. Dictation works in real time. Transcription will get you results in a matter of minutes.
Super Private & Secure!
Super private - no human handles, sees or listens to your recordings! In addition, we take great measures to protect your privacy. For example, for transcribing your recordings - we pay Google's speech to text engines extra - just so they do not keep your audio for their own research purposes.
Health advantages
Typing may result in different types of Computer Related Repetitive Strain Injuries (RSI). Voice typing is one of the main recommended ways to minimize these risks, as it enables you to sit back comfortably, freeing your arms, hands, shoulders and back altogether.
Saves you time
Need to transcribe a recording? If it's an hour long, transcribing it yourself will take you about 6! hours of work. If you send it to a transcriber - you will get it back in days! Upload it to Speechnotes - it will take you less than a minute, and you will get the results in about 20 minutes to your email.
Saves you money
Speechnotes dictation notepad is completely free - with ads - or a small fee to get it ad-free. Speechnotes transcription is only $0.1/minute, which is X10 times cheaper than a human transcriber! We offer the best deal on the market - whether it's the free dictation notepad ot the pay-as-you-go transcription service.
Dictation - Free
- Online dictation notepad
- Voice typing Chrome extension
Dictation - Premium
- Premium online dictation notepad
- Premium voice typing Chrome extension
- Support from the development team
Transcription
$0.1 /minute.
- Pay as you go - no subscription
- Audio & video recordings
- Speaker diarization in English
- Generate captions .srt files
- REST API, webhooks & Zapier integration
Compare plans
| Dictation Free | Dictation Premium | Transcription | |
|---|---|---|---|
| Unlimited dictation | ✅ | ✅ | |
| Online notepad | ✅ | ✅ | |
| Voice typing extension | ✅ | ✅ | |
| Editing | ✅ | ✅ | ✅ |
| Ads free | ✅ | ✅ | |
| Transcribe recordings | ✅ | ||
| Transcribe Youtubes | ✅ | ||
| API & webhooks | ✅ | ||
| Zapier | ✅ | ||
| Export to captions | ✅ | ||
| Extra security | ✅ | ✅ | |
| Support from the development team | ✅ | ✅ |
Privacy Policy
We at Speechnotes, Speechlogger, TextHear, Speechkeys value your privacy, and that's why we do not store anything you say or type or in fact any other data about you - unless it is solely needed for the purpose of your operation. We don't share it with 3rd parties, other than Google / Microsoft for the speech-to-text engine.
Privacy - how are the recordings and results handled?
- transcription service.
Our transcription service is probably the most private and secure transcription service available.
- HIPAA compliant.
- No human in the loop. No passing your recording between PCs, emails, employees, etc.
- Secure encrypted communications (https) with and between our servers.
- Recordings are automatically deleted from our servers as soon as the transcription is done.
- Our contract with Google / Microsoft (our speech engines providers) prohibits them from keeping any audio or results.
- Transcription results are securely kept on our secure database. Only you have access to them - only if you sign in (or provide your secret credentials through the API)
- You may choose to delete the transcription results - once you do - no copy remains on our servers.
- Dictation notepad & extension
For dictation, the recording & recognition - is delegated to and done by the browser (Chrome / Edge) or operating system (Android). So, we never even have access to the recorded audio, and Edge's / Chrome's / Android's (depending the one you use) privacy policy apply here.
The results of the dictation are saved locally on your machine - via the browser's / app's local storage. It never gets to our servers. So, as long as your device is private - your notes are private.
Payments method privacy
The whole payments process is delegated to PayPal / Stripe / Google Pay / Play Store / App Store and secured by these providers. We never receive any of your credit card information.
More generic notes regarding our site, cookies, analytics, ads, etc.
- We may use Google Analytics on our site - which is a generic tool to track usage statistics.
- We use cookies - which means we save data on your browser to send to our servers when needed. This is used for instance to sign you in, and then keep you signed in.
- For the dictation tool - we use your browser's local storage to store your notes, so you can access them later.
- Non premium dictation tool serves ads by Google. Users may opt out of personalized advertising by visiting Ads Settings . Alternatively, users can opt out of a third-party vendor's use of cookies for personalized advertising by visiting https://youradchoices.com/
- In case you would like to upload files to Google Drive directly from Speechnotes - we'll ask for your permission to do so. We will use that permission for that purpose only - syncing your speech-notes to your Google Drive, per your request.
SpeechTexter is a free multilingual speech-to-text application aimed at assisting you with transcription of notes, documents, books, reports or blog posts by using your voice. This app also features a customizable voice commands list, allowing users to add punctuation marks, frequently used phrases, and some app actions (undo, redo, make a new paragraph).
SpeechTexter is used daily by students, teachers, writers, bloggers around the world.
It will assist you in minimizing your writing efforts significantly.
Voice-to-text software is exceptionally valuable for people who have difficulty using their hands due to trauma, people with dyslexia or disabilities that limit the use of conventional input devices. Speech to text technology can also be used to improve accessibility for those with hearing impairments, as it can convert speech into text.
It can also be used as a tool for learning a proper pronunciation of words in the foreign language, in addition to helping a person develop fluency with their speaking skills.

Accuracy levels higher than 90% should be expected. It varies depending on the language and the speaker.
No download, installation or registration is required. Just click the microphone button and start dictating.
Speech to text technology is quickly becoming an essential tool for those looking to save time and increase their productivity.
Powerful real-time continuous speech recognition
Creation of text notes, emails, blog posts, reports and more.
Custom voice commands
More than 70 languages supported
SpeechTexter is using Google Speech recognition to convert the speech into text in real-time. This technology is supported by Chrome browser (for desktop) and some browsers on Android OS. Other browsers have not implemented speech recognition yet.
Note: iPhones and iPads are not supported
List of supported languages:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Azerbaijani, Basque, Bengali, Bosnian, Bulgarian, Burmese, Catalan, Chinese (Mandarin, Cantonese), Croatian, Czech, Danish, Dutch, English, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Kinyarwanda, Korean, Lao, Latvian, Lithuanian, Macedonian, Malay, Malayalam, Marathi, Mongolian, Nepali, Norwegian Bokmål, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Serbian, Sinhala, Slovak, Slovenian, Southern Sotho, Spanish, Sundanese, Swahili, Swati, Swedish, Tamil, Telugu, Thai, Tsonga, Tswana, Turkish, Ukrainian, Urdu, Uzbek, Venda, Vietnamese, Xhosa, Zulu.
Instructions for web app on desktop (Windows, Mac, Linux OS)
Requirements: the latest version of the Google Chrome [↗] browser (other browsers are not supported).
1. Connect a high-quality microphone to your computer.
2. Make sure your microphone is set as the default recording device on your browser.
To go directly to microphone's settings paste the line below into Chrome's URL bar.
chrome://settings/content/microphone

To capture speech from video/audio content on the web or from a file stored on your device, select 'Stereo Mix' as the default audio input.
3. Select the language you would like to speak (Click the button on the top right corner).
4. Click the "microphone" button. Chrome browser will request your permission to access your microphone. Choose "allow".

5. You can start dictating!
Instructions for the web app on a mobile and for the android app
Requirements: - Google app [↗] installed on your Android device. - Any of the supported browsers if you choose to use the web app.
Supported android browsers (not a full list): Chrome browser (recommended), Edge, Opera, Brave, Vivaldi.
1. Tap the button with the language name (on a web app) or language code (on android app) on the top right corner to select your language.
2. Tap the microphone button. The SpeechTexter app will ask for permission to record audio. Choose 'allow' to enable microphone access.

3. You can start dictating!
Common problems on a desktop (Windows, Mac, Linux OS)
Error: 'speechtexter cannot access your microphone'..
Please give permission to access your microphone.
Click on the "padlock" icon next to the URL bar, find the "microphone" option, and choose "allow".

Error: 'No speech was detected. Please try again'.
If you get this error while you are speaking, make sure your microphone is set as the default recording device on your browser [see step 2].
If you're using a headset, make sure the mute switch on the cord is off.
Error: 'Network error'
The internet connection is poor. Please try again later.
The result won't transfer to the "editor".
The result confidence is not high enough or there is a background noise. An accumulation of long text in the buffer can also make the engine stop responding, please make some pauses in the speech.
The results are wrong.
Please speak loudly and clearly. Speaking clearly and consistently will help the software accurately recognize your words.
Reduce background noise. Background noise from fans, air conditioners, refrigerators, etc. can drop the accuracy significantly. Try to reduce background noise as much as possible.
Speak directly into the microphone. Speaking directly into the microphone enhances the accuracy of the software. Avoid speaking too far away from the microphone.
Speak in complete sentences. Speaking in complete sentences will help the software better recognize the context of your words.
Can I upload an audio file and get the transcription?
No, this feature is not available.
How do I transcribe an audio (video) file on my PC or from the web?
Playback your file in any player and hit the 'mic' button on the SpeechTexter website to start capturing the speech. For better results select "Stereo Mix" as the default recording device on your browser, if you are accessing SpeechTexter and the file from the same device.
I don't see the "Stereo mix" option (Windows OS)
"Stereo Mix" might be hidden or it's not supported by your system. If you are a Windows user go to 'Control panel' → Hardware and Sound → Sound → 'Recording' tab. Right-click on a blank area in the pane and make sure both "View Disabled Devices" and "View Disconnected Devices" options are checked. If "Stereo Mix" appears, you can enable it by right clicking on it and choosing 'enable'. If "Stereo Mix" hasn't appeared, it means it's not supported by your system. You can try using a third-party program such as "Virtual Audio Cable" or "VB-Audio Virtual Cable" to create a virtual audio device that includes "Stereo Mix" functionality.

How to use the voice commands list?

The voice commands list allows you to insert the punctuation, some text, or run some preset functions using only your voice. On the first column you enter your voice command. On the second column you enter a punctuation mark or a function. Voice commands are case-sensitive. Available functions: #newparagraph (add a new paragraph), #undo (undo the last change), #redo (redo the last change)
To use the function above make a pause in your speech until all previous dictated speech appears in your note, then say "insert a new paragraph" and wait for the command execution.
Found a mistake in the voice commands list or want to suggest an update? Follow the steps below:
- Navigate to the voice commands list [↑] on this website.
- Click on the edit button to update or add new punctuation marks you think other users might find useful in your language.
- Click on the "Export" button located above the voice commands list to save your list in JSON format to your device.
Next, send us your file as an attachment via email. You can find the email address at the bottom of the page. Feel free to include a brief description of the mistake or the updates you're suggesting in the email body.
Your contribution to the improvement of the services is appreciated.
Can I prevent my custom voice commands from disappearing after closing the browser?
SpeechTexter by default saves your data inside your browser's cache. If your browsers clears the cache your data will be deleted. However, you can export your custom voice commands to your device and import them when you need them by clicking the corresponding buttons above the list. SpeechTexter is using JSON format to store your voice commands. You can create a .txt file in this format on your device and then import it into SpeechTexter. An example of JSON format is shown below:
{ "period": ".", "full stop": ".", "question mark": "?", "new paragraph": "#newparagraph" }
I lost my dictated work after closing the browser.
SpeechTexter doesn't store any text that you dictate. Please use the "autosave" option or click the "download" button (recommended). The "autosave" option will try to store your work inside your browser's cache, where it will remain until you switch the "text autosave" option off, clear the cache manually, or if your browser clears the cache on exit.
Common problems on the Android app
I get the message: 'speech recognition is not available'..
'Google app' from Play store is required for SpeechTexter to work. download [↗]
Where does SpeechTexter store the saved files?
Version 1.5 and above stores the files in the internal memory.
Version 1.4.9 and below stores the files inside the "SpeechTexter" folder at the root directory of your device.
After updating the app from version 1.x.x to version 2.x.x my files have disappeared
As a result of recent updates, the Android operating system has implemented restrictions that prevent users from accessing folders within the Android root directory, including SpeechTexter's folder. However, your old files can still be imported manually by selecting the "import" button within the Speechtexter application.

Common problems on the mobile web app
Tap on the "padlock" icon next to the URL bar, find the "microphone" option and choose "allow".

- TERMS OF USE
- PRIVACY POLICY
- Play Store [↗]
copyright © 2014 - 2024 www.speechtexter.com . All Rights Reserved.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Quickstart: Recognize and convert speech to text
- 3 contributors
Some of the features described in this article might only be available in preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews .
In this quickstart, you try real-time speech to text in Azure AI Studio .
Prerequisites
- Azure subscription - Create one for free .
- Some AI services features are free to try in AI Studio. For access to all capabilities described in this article, you need to connect AI services to your hub in AI Studio .
Try real-time speech to text
Go to the Home page in AI Studio and then select AI Services from the left pane.

Select Speech from the list of AI services.
Select Real-time speech to text .

In the Try it out section, select your hub's AI services connection. For more information about AI services connections, see connect AI services to your hub in AI Studio .

Select Show advanced options to configure speech to text options such as:
- Language identification : Used to identify languages spoken in audio when compared against a list of supported languages. For more information about language identification options such as at-start and continuous recognition, see Language identification .
- Speaker diarization : Used to identify and separate speakers in audio. Diarization distinguishes between the different speakers who participate in the conversation. The Speech service provides information about which speaker was speaking a particular part of transcribed speech. For more information about speaker diarization, see the real-time speech to text with speaker diarization quickstart.
- Custom endpoint : Use a deployed model from custom speech to improve recognition accuracy. To use Microsoft's baseline model, leave this set to None. For more information about custom speech, see Custom Speech .
- Output format : Choose between simple and detailed output formats. Simple output includes display format and timestamps. Detailed output includes more formats (such as display, lexical, ITN, and masked ITN), timestamps, and N-best lists.
- Phrase list : Improve transcription accuracy by providing a list of known phrases, such as names of people or specific locations. Use commas or semicolons to separate each value in the phrase list. For more information about phrase lists, see Phrase lists .
Select an audio file to upload, or record audio in real-time. In this example, we use the Call1_separated_16k_health_insurance.wav file that's available in the Speech SDK repository on GitHub . You can download the file or use your own audio file.

You can view the real-time speech to text results in the Results section.

Reference documentation | Package (NuGet) | Additional samples on GitHub
In this quickstart, you create and run an application to recognize and transcribe speech to text in real-time.
To instead transcribe audio files asynchronously, see What is batch transcription . If you're not sure which speech to text solution is right for you, see What is speech to text?
- An Azure subscription. You can create one for free .
- Create a Speech resource in the Azure portal.
- Get the Speech resource key and region. After your Speech resource is deployed, select Go to resource to view and manage keys.
Set up the environment
The Speech SDK is available as a NuGet package and implements .NET Standard 2.0. You install the Speech SDK later in this guide. For any other requirements, see Install the Speech SDK .
Set environment variables
You need to authenticate your application to access Azure AI services. This article shows you how to use environment variables to store your credentials. You can then access the environment variables from your code to authenticate your application. For production, use a more secure way to store and access your credentials.
We recommend Microsoft Entra ID authentication with managed identities for Azure resources to avoid storing credentials with your applications that run in the cloud.
If you use an API key, store it securely somewhere else, such as in Azure Key Vault . Don't include the API key directly in your code, and never post it publicly.
For more information about AI services security, see Authenticate requests to Azure AI services .
To set the environment variables for your Speech resource key and region, open a console window, and follow the instructions for your operating system and development environment.
- To set the SPEECH_KEY environment variable, replace your-key with one of the keys for your resource.
- To set the SPEECH_REGION environment variable, replace your-region with one of the regions for your resource.
If you only need to access the environment variables in the current console, you can set the environment variable with set instead of setx .
After you add the environment variables, you might need to restart any programs that need to read the environment variables, including the console window. For example, if you're using Visual Studio as your editor, restart Visual Studio before you run the example.
Edit your .bashrc file, and add the environment variables:
After you add the environment variables, run source ~/.bashrc from your console window to make the changes effective.
Edit your .bash_profile file, and add the environment variables:
After you add the environment variables, run source ~/.bash_profile from your console window to make the changes effective.
For iOS and macOS development, you set the environment variables in Xcode. For example, follow these steps to set the environment variable in Xcode 13.4.1.
- Select Product > Scheme > Edit scheme .
- Select Arguments on the Run (Debug Run) page.
- Under Environment Variables select the plus (+) sign to add a new environment variable.
- Enter SPEECH_KEY for the Name and enter your Speech resource key for the Value .
To set the environment variable for your Speech resource region, follow the same steps. Set SPEECH_REGION to the region of your resource. For example, westus .
For more configuration options, see the Xcode documentation .
Recognize speech from a microphone
Follow these steps to create a console application and install the Speech SDK.
Open a command prompt window in the folder where you want the new project. Run this command to create a console application with the .NET CLI.
This command creates the Program.cs file in your project directory.
Install the Speech SDK in your new project with the .NET CLI.
Replace the contents of Program.cs with the following code:
To change the speech recognition language, replace en-US with another supported language . For example, use es-ES for Spanish (Spain). If you don't specify a language, the default is en-US . For details about how to identify one of multiple languages that might be spoken, see Language identification .
Run your new console application to start speech recognition from a microphone:
Make sure that you set the SPEECH_KEY and SPEECH_REGION environment variables . If you don't set these variables, the sample fails with an error message.
Speak into your microphone when prompted. What you speak should appear as text:
Here are some other considerations:
This example uses the RecognizeOnceAsync operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech .
To recognize speech from an audio file, use FromWavFileInput instead of FromDefaultMicrophoneInput :
For compressed audio files such as MP4, install GStreamer and use PullAudioInputStream or PushAudioInputStream . For more information, see How to use compressed input audio .
Clean up resources
You can use the Azure portal or Azure Command Line Interface (CLI) to remove the Speech resource you created.
The Speech SDK is available as a NuGet package and implements .NET Standard 2.0. You install the Speech SDK later in this guide. For other requirements, see Install the Speech SDK .
Create a new C++ console project in Visual Studio Community named SpeechRecognition .
Select Tools > Nuget Package Manager > Package Manager Console . In the Package Manager Console , run this command:
Replace the contents of SpeechRecognition.cpp with the following code:
Build and run your new console application to start speech recognition from a microphone.
Reference documentation | Package (Go) | Additional samples on GitHub
Install the Speech SDK for Go. For requirements and instructions, see Install the Speech SDK .
Follow these steps to create a GO module.
Open a command prompt window in the folder where you want the new project. Create a new file named speech-recognition.go .
Copy the following code into speech-recognition.go :
Run the following commands to create a go.mod file that links to components hosted on GitHub:
Build and run the code:
Reference documentation | Additional samples on GitHub
To set up your environment, install the Speech SDK . The sample in this quickstart works with the Java Runtime .
Install Apache Maven . Then run mvn -v to confirm successful installation.
Create a new pom.xml file in the root of your project, and copy the following code into it:
Install the Speech SDK and dependencies.
Follow these steps to create a console application for speech recognition.
Create a new file named SpeechRecognition.java in the same project root directory.
Copy the following code into SpeechRecognition.java :
To recognize speech from an audio file, use fromWavFileInput instead of fromDefaultMicrophoneInput :
Reference documentation | Package (npm) | Additional samples on GitHub | Library source code
You also need a .wav audio file on your local machine. You can use your own .wav file (up to 30 seconds) or download the https://crbn.us/whatstheweatherlike.wav sample file.
To set up your environment, install the Speech SDK for JavaScript. Run this command: npm install microsoft-cognitiveservices-speech-sdk . For guided installation instructions, see Install the Speech SDK .
Recognize speech from a file
Follow these steps to create a Node.js console application for speech recognition.
Open a command prompt window where you want the new project, and create a new file named SpeechRecognition.js .
Install the Speech SDK for JavaScript:
Copy the following code into SpeechRecognition.js :
In SpeechRecognition.js , replace YourAudioFile.wav with your own .wav file. This example only recognizes speech from a .wav file. For information about other audio formats, see How to use compressed input audio . This example supports up to 30 seconds of audio.
Run your new console application to start speech recognition from a file:
The speech from the audio file should be output as text:
This example uses the recognizeOnceAsync operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech .
Recognizing speech from a microphone is not supported in Node.js. It's supported only in a browser-based JavaScript environment. For more information, see the React sample and the implementation of speech to text from a microphone on GitHub.
The React sample shows design patterns for the exchange and management of authentication tokens. It also shows the capture of audio from a microphone or file for speech to text conversions.
Reference documentation | Package (PyPi) | Additional samples on GitHub
The Speech SDK for Python is available as a Python Package Index (PyPI) module . The Speech SDK for Python is compatible with Windows, Linux, and macOS.
- For Windows, install the Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017, 2019, and 2022 for your platform. Installing this package for the first time might require a restart.
- On Linux, you must use the x64 target architecture.
Install a version of Python from 3.7 or later . For other requirements, see Install the Speech SDK .
Follow these steps to create a console application.
Open a command prompt window in the folder where you want the new project. Create a new file named speech_recognition.py .
Run this command to install the Speech SDK:
Copy the following code into speech_recognition.py :
To change the speech recognition language, replace en-US with another supported language . For example, use es-ES for Spanish (Spain). If you don't specify a language, the default is en-US . For details about how to identify one of multiple languages that might be spoken, see language identification .
This example uses the recognize_once_async operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech .
To recognize speech from an audio file, use filename instead of use_default_microphone :
Reference documentation | Package (download) | Additional samples on GitHub
The Speech SDK for Swift is distributed as a framework bundle. The framework supports both Objective-C and Swift on both iOS and macOS.
The Speech SDK can be used in Xcode projects as a CocoaPod , or downloaded directly and linked manually. This guide uses a CocoaPod. Install the CocoaPod dependency manager as described in its installation instructions .
Follow these steps to recognize speech in a macOS application.
Clone the Azure-Samples/cognitive-services-speech-sdk repository to get the Recognize speech from a microphone in Swift on macOS sample project. The repository also has iOS samples.
Navigate to the directory of the downloaded sample app ( helloworld ) in a terminal.
Run the command pod install . This command generates a helloworld.xcworkspace Xcode workspace containing both the sample app and the Speech SDK as a dependency.
Open the helloworld.xcworkspace workspace in Xcode.
Open the file named AppDelegate.swift and locate the applicationDidFinishLaunching and recognizeFromMic methods as shown here.
In AppDelegate.m , use the environment variables that you previously set for your Speech resource key and region.
To make the debug output visible, select View > Debug Area > Activate Console .
Build and run the example code by selecting Product > Run from the menu or selecting the Play button.
After you select the button in the app and say a few words, you should see the text that you spoke on the lower part of the screen. When you run the app for the first time, it prompts you to give the app access to your computer's microphone.
This example uses the recognizeOnce operation to transcribe utterances of up to 30 seconds, or until silence is detected. For information about continuous recognition for longer audio, including multi-lingual conversations, see How to recognize speech .
Objective-C
The Speech SDK for Objective-C shares client libraries and reference documentation with the Speech SDK for Swift. For Objective-C code examples, see the recognize speech from a microphone in Objective-C on macOS sample project in GitHub.
Speech to text REST API reference | Speech to text REST API for short audio reference | Additional samples on GitHub
You also need a .wav audio file on your local machine. You can use your own .wav file up to 60 seconds or download the https://crbn.us/whatstheweatherlike.wav sample file.
Open a console window and run the following cURL command. Replace YourAudioFile.wav with the path and name of your audio file.
You should receive a response similar to what is shown here. The DisplayText should be the text that was recognized from your audio file. The command recognizes up to 60 seconds of audio and converts it to text.
For more information, see Speech to text REST API for short audio .
Follow these steps and see the Speech CLI quickstart for other requirements for your platform.
Run the following .NET CLI command to install the Speech CLI:
Run the following commands to configure your Speech resource key and region. Replace SUBSCRIPTION-KEY with your Speech resource key and replace REGION with your Speech resource region.
Run the following command to start speech recognition from a microphone:
Speak into the microphone, and you see transcription of your words into text in real-time. The Speech CLI stops after a period of silence, 30 seconds, or when you select Ctrl + C .
To recognize speech from an audio file, use --file instead of --microphone . For compressed audio files such as MP4, install GStreamer and use --format . For more information, see How to use compressed input audio .
To improve recognition accuracy of specific words or utterances, use a phrase list . You include a phrase list in-line or with a text file along with the recognize command:
To change the speech recognition language, replace en-US with another supported language . For example, use es-ES for Spanish (Spain). If you don't specify a language, the default is en-US .
For continuous recognition of audio longer than 30 seconds, append --continuous :
Run this command for information about more speech recognition options such as file input and output:
Learn more about speech recognition
Was this page helpful?
Additional resources
Speech to Text Converter
Descript instantly turns speech into text in real time. Just start recording and watch our AI speech recognition transcribe your voice—with 95% accuracy—into text that’s ready to edit or export.

How to automatically convert speech to text with Descript
Create a project in Descript, select record, and choose your microphone input to start a recording session. Or upload a voice file to convert the audio to text.
As you speak into your mic, Descript’s speech-to-text software turns what you say into text in real time. Don’t worry about filler words or mistakes; Descript makes it easy to find and remove those from both the generated text and recorded audio.
Enter Correct mode (press the C key) to edit, apply formatting, highlight sections, and leave comments on your speech-to-text transcript. Filler words will be highlighted, which you can remove by right clicking to remove some or all instances. When ready, export your text as HTML, Markdown, Plain text, Word file, or Rich Text format.
Download the app for free
More articles and resources.

How to write a transcript: 9 tips for beginners

What is a video crossfade effect?

New one-click integrations with Riverside, SquadCast, Restream, Captivate
Other tools from descript, voice cloning, video collage maker, advertising video maker, facebook video maker, youtube video summarizer, rotate video, marketing video maker.
Speech to Text
- 3 Create a new project Drag your file into the box above, or click Select file and import it from your computer or wherever it lives.
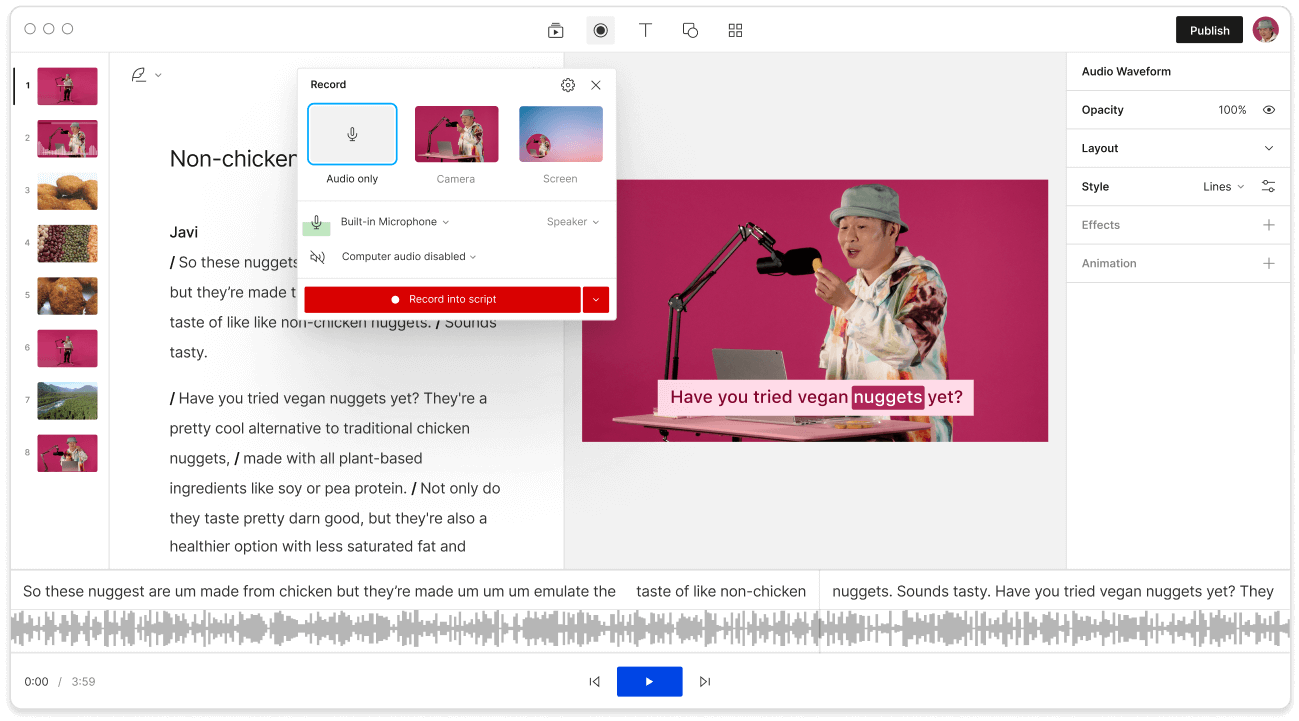
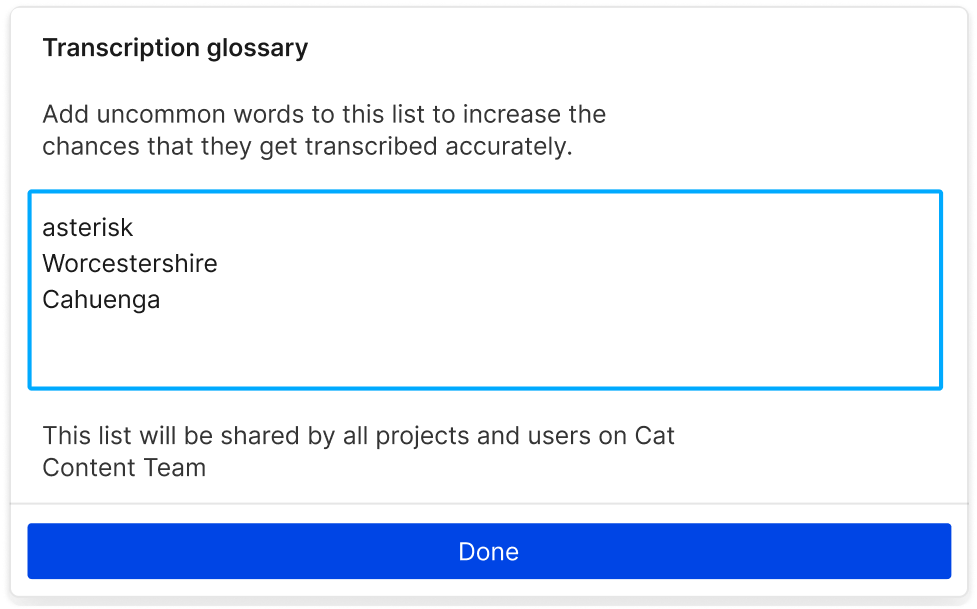
Expand Descript’s online voice recognition powers with an expandable transcription glossary to recognize hard-to-translate words like names and jargon.
Record yourself talking and turn it into text, audio, and video that’s ready to edit in Descript’s timeline. You can format, search, highlight, and other actions you’d perform in a Google Doc, while taking advantage of features like text-to-speec h, captions, and more.

Go from speech to text in over 22 different languages, plus English. Transcribe audio in French , Spanish , Italian, German and other languages from around the world. Finnish? Oh we’re just getting started.

Yes, basic real-time speech to text conversion is included for free with most modern devices (Android, Mac, etc.) Descript also offers a 95% accurate text-to-speech converter for up to 1 hour per month for free.
Speech-to-text conversion works by using AI and large quantities of diverse training data to recognize the acoustic qualities of specific words, despite the different speech patterns and accents people have, to generate it as text.
Yes! Descript‘s AI-powered Overdub feature lets you not only turn speech to text but also generate human-sounding speech from a script in your choice of AI stock voices.
Descript supports speech-to-text conversion in Catalan, Finnish, Lithuanian, Slovak, Croatian, French (FR), Malay, Slovenian, Czech, German, Norwegian, Spanish (US), Danish, Hungarian, Polish, Swedish, Dutch, Italian, Portuguese (BR), Turkish.
Descript’s included AI transcription offers up to 95% accurate speech to text generation. We also offer a white glove pay-per-word transcription service and 99% accuracy. Expanding your transcription glossary makes the automatic transcription more accurate over time.
- Español – América Latina
- Português – Brasil
- Cloud Speech-to-Text
- Documentation
Speech-to-Text supported languages
This page lists all languages supported by Cloud Speech-to-Text. Language is specified within a recognition request's languageCode parameter. For more information about sending a recognition request and specifying the language of the transcription, see the how-to guides about performing speech recognition. For more information about the class tokens available for each language, see the class tokens page .
Try it for yourself
If you're new to Google Cloud, create an account to evaluate how Speech-to-Text performs in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
The table below lists the models available for each language. Cloud Speech-to-Text offers multiple recognition models , each tuned to different audio types. The default and command_and_search recognition models support all available languages. The command_and_search model is optimized for short audio clips, such as voice commands or voice searches. The default model can be used to transcribe any audio type.
Some languages are supported by additional models, optimized for additional audio types: enhanced phone_call , and enhanced video . These models can recognize speech captured from these audio sources more accurately than the default model. See the enhanced models page for more information. If any of these additional models are available for your language, they will be listed with the default and command_and_search models for your language. If only the default and command_and_search models are listed with your language, no additional models are currently available.
Use only the language codes shown in the following table. The following language codes are officially maintained and monitored externally by Google. Using other language codes can result in breaking changes.
| ( ) ( ) | ( ) ( ) ( ) ( ) |
| Name | BCP-47 | Model | Automatic punctuation | Diarization | Model adaptation | Word-level confidence | Profanity filter | Spoken punctuation | Spoken emojis | |
|---|---|---|---|---|---|---|---|---|---|---|
| Afrikaans (South Africa) | af-ZA | False | ||||||||
| Afrikaans (South Africa) | af-ZA | True | ||||||||
| Afrikaans (South Africa) | af-ZA | False | ||||||||
| Albanian (Albania) | sq-AL | False | ||||||||
| Albanian (Albania) | sq-AL | True | ||||||||
| Albanian (Albania) | sq-AL | False | ||||||||
| Amharic (Ethiopia) | am-ET | False | ||||||||
| Amharic (Ethiopia) | am-ET | True | ||||||||
| Amharic (Ethiopia) | am-ET | False | ||||||||
| Arabic (Algeria) | ar-DZ | False | ||||||||
| Arabic (Algeria) | ar-DZ | True | ||||||||
| Arabic (Algeria) | ar-DZ | False | ||||||||
| Arabic (Algeria) | ar-DZ | False | ✔ | |||||||
| Arabic (Algeria) | ar-DZ | True | ✔ | |||||||
| Arabic (Algeria) | ar-DZ | False | ✔ | |||||||
| Arabic (Algeria) | ar-DZ | True | ✔ | |||||||
| Arabic (Bahrain) | ar-BH | False | ||||||||
| Arabic (Bahrain) | ar-BH | True | ||||||||
| Arabic (Bahrain) | ar-BH | False | ||||||||
| Arabic (Bahrain) | ar-BH | False | ✔ | |||||||
| Arabic (Bahrain) | ar-BH | True | ✔ | |||||||
| Arabic (Bahrain) | ar-BH | False | ✔ | |||||||
| Arabic (Bahrain) | ar-BH | True | ✔ | |||||||
| Arabic (Egypt) | ar-EG | False | ||||||||
| Arabic (Egypt) | ar-EG | True | ||||||||
| Arabic (Egypt) | ar-EG | False | ||||||||
| Arabic (Egypt) | ar-EG | False | ✔ | |||||||
| Arabic (Egypt) | ar-EG | True | ✔ | |||||||
| Arabic (Egypt) | ar-EG | False | ✔ | |||||||
| Arabic (Egypt) | ar-EG | True | ✔ | |||||||
| Arabic (Iraq) | ar-IQ | False | ||||||||
| Arabic (Iraq) | ar-IQ | True | ||||||||
| Arabic (Iraq) | ar-IQ | False | ||||||||
| Arabic (Iraq) | ar-IQ | False | ✔ | |||||||
| Arabic (Iraq) | ar-IQ | True | ✔ | |||||||
| Arabic (Iraq) | ar-IQ | False | ✔ | |||||||
| Arabic (Iraq) | ar-IQ | True | ✔ | |||||||
| Arabic (Israel) | ar-IL | False | ||||||||
| Arabic (Israel) | ar-IL | True | ||||||||
| Arabic (Israel) | ar-IL | False | ||||||||
| Arabic (Israel) | ar-IL | False | ✔ | |||||||
| Arabic (Israel) | ar-IL | True | ✔ | |||||||
| Arabic (Israel) | ar-IL | False | ✔ | |||||||
| Arabic (Israel) | ar-IL | True | ✔ | |||||||
| Arabic (Jordan) | ar-JO | False | ||||||||
| Arabic (Jordan) | ar-JO | True | ||||||||
| Arabic (Jordan) | ar-JO | False | ||||||||
| Arabic (Jordan) | ar-JO | False | ✔ | |||||||
| Arabic (Jordan) | ar-JO | True | ✔ | |||||||
| Arabic (Jordan) | ar-JO | False | ✔ | |||||||
| Arabic (Jordan) | ar-JO | True | ✔ | |||||||
| Arabic (Kuwait) | ar-KW | False | ||||||||
| Arabic (Kuwait) | ar-KW | True | ||||||||
| Arabic (Kuwait) | ar-KW | False | ||||||||
| Arabic (Kuwait) | ar-KW | False | ✔ | |||||||
| Arabic (Kuwait) | ar-KW | True | ✔ | |||||||
| Arabic (Kuwait) | ar-KW | False | ✔ | |||||||
| Arabic (Kuwait) | ar-KW | True | ✔ | |||||||
| Arabic (Lebanon) | ar-LB | False | ||||||||
| Arabic (Lebanon) | ar-LB | True | ||||||||
| Arabic (Lebanon) | ar-LB | False | ||||||||
| Arabic (Lebanon) | ar-LB | False | ✔ | |||||||
| Arabic (Lebanon) | ar-LB | True | ✔ | |||||||
| Arabic (Lebanon) | ar-LB | False | ✔ | |||||||
| Arabic (Lebanon) | ar-LB | True | ✔ | |||||||
| Arabic (Mauritania) | ar-MR | False | ||||||||
| Arabic (Mauritania) | ar-MR | True | ||||||||
| Arabic (Mauritania) | ar-MR | False | ||||||||
| Arabic (Mauritania) | ar-MR | False | ✔ | |||||||
| Arabic (Mauritania) | ar-MR | True | ✔ | |||||||
| Arabic (Mauritania) | ar-MR | False | ✔ | |||||||
| Arabic (Mauritania) | ar-MR | True | ✔ | |||||||
| Arabic (Morocco) | ar-MA | False | ||||||||
| Arabic (Morocco) | ar-MA | True | ||||||||
| Arabic (Morocco) | ar-MA | False | ||||||||
| Arabic (Morocco) | ar-MA | False | ✔ | |||||||
| Arabic (Morocco) | ar-MA | True | ✔ | |||||||
| Arabic (Morocco) | ar-MA | False | ✔ | |||||||
| Arabic (Morocco) | ar-MA | True | ✔ | |||||||
| Arabic (Oman) | ar-OM | False | ||||||||
| Arabic (Oman) | ar-OM | True | ||||||||
| Arabic (Oman) | ar-OM | False | ||||||||
| Arabic (Oman) | ar-OM | False | ✔ | |||||||
| Arabic (Oman) | ar-OM | True | ✔ | |||||||
| Arabic (Oman) | ar-OM | False | ✔ | |||||||
| Arabic (Oman) | ar-OM | True | ✔ | |||||||
| Arabic (Qatar) | ar-QA | False | ||||||||
| Arabic (Qatar) | ar-QA | True | ||||||||
| Arabic (Qatar) | ar-QA | False | ||||||||
| Arabic (Qatar) | ar-QA | False | ✔ | |||||||
| Arabic (Qatar) | ar-QA | True | ✔ | |||||||
| Arabic (Qatar) | ar-QA | False | ✔ | |||||||
| Arabic (Qatar) | ar-QA | True | ✔ | |||||||
| Arabic (Saudi Arabia) | ar-SA | False | ||||||||
| Arabic (Saudi Arabia) | ar-SA | True | ||||||||
| Arabic (Saudi Arabia) | ar-SA | False | ||||||||
| Arabic (Saudi Arabia) | ar-SA | False | ✔ | |||||||
| Arabic (Saudi Arabia) | ar-SA | True | ✔ | |||||||
| Arabic (Saudi Arabia) | ar-SA | False | ✔ | |||||||
| Arabic (Saudi Arabia) | ar-SA | True | ✔ | |||||||
| Arabic (State of Palestine) | ar-PS | False | ||||||||
| Arabic (State of Palestine) | ar-PS | True | ||||||||
| Arabic (State of Palestine) | ar-PS | False | ||||||||
| Arabic (State of Palestine) | ar-PS | False | ✔ | |||||||
| Arabic (State of Palestine) | ar-PS | True | ✔ | |||||||
| Arabic (State of Palestine) | ar-PS | False | ✔ | |||||||
| Arabic (State of Palestine) | ar-PS | True | ✔ | |||||||
| Arabic (Syria) | ar-SY | False | ||||||||
| Arabic (Syria) | ar-SY | True | ||||||||
| Arabic (Syria) | ar-SY | False | ||||||||
| Arabic (Tunisia) | ar-TN | False | ||||||||
| Arabic (Tunisia) | ar-TN | True | ||||||||
| Arabic (Tunisia) | ar-TN | False | ||||||||
| Arabic (Tunisia) | ar-TN | False | ✔ | |||||||
| Arabic (Tunisia) | ar-TN | True | ✔ | |||||||
| Arabic (Tunisia) | ar-TN | False | ✔ | |||||||
| Arabic (Tunisia) | ar-TN | True | ✔ | |||||||
| Arabic (United Arab Emirates) | ar-AE | False | ||||||||
| Arabic (United Arab Emirates) | ar-AE | True | ||||||||
| Arabic (United Arab Emirates) | ar-AE | False | ||||||||
| Arabic (United Arab Emirates) | ar-AE | False | ✔ | |||||||
| Arabic (United Arab Emirates) | ar-AE | True | ✔ | |||||||
| Arabic (United Arab Emirates) | ar-AE | False | ✔ | |||||||
| Arabic (United Arab Emirates) | ar-AE | True | ✔ | |||||||
| Arabic (Yemen) | ar-YE | False | ||||||||
| Arabic (Yemen) | ar-YE | True | ||||||||
| Arabic (Yemen) | ar-YE | False | ||||||||
| Arabic (Yemen) | ar-YE | False | ✔ | |||||||
| Arabic (Yemen) | ar-YE | True | ✔ | |||||||
| Arabic (Yemen) | ar-YE | False | ✔ | |||||||
| Arabic (Yemen) | ar-YE | True | ✔ | |||||||
| Armenian (Armenia) | hy-AM | False | ||||||||
| Armenian (Armenia) | hy-AM | True | ||||||||
| Armenian (Armenia) | hy-AM | False | ||||||||
| Azerbaijani (Azerbaijan) | az-AZ | False | ||||||||
| Azerbaijani (Azerbaijan) | az-AZ | True | ||||||||
| Azerbaijani (Azerbaijan) | az-AZ | False | ||||||||
| Basque (Spain) | eu-ES | False | ||||||||
| Basque (Spain) | eu-ES | True | ||||||||
| Basque (Spain) | eu-ES | False | ||||||||
| Bengali (Bangladesh) | bn-BD | False | ||||||||
| Bengali (Bangladesh) | bn-BD | True | ||||||||
| Bengali (Bangladesh) | bn-BD | False | ||||||||
| Bengali (Bangladesh) | bn-BD | False | ||||||||
| Bengali (Bangladesh) | bn-BD | True | ||||||||
| Bengali (Bangladesh) | bn-BD | False | ||||||||
| Bengali (Bangladesh) | bn-BD | True | ||||||||
| Bengali (India) | bn-IN | False | ||||||||
| Bengali (India) | bn-IN | True | ||||||||
| Bengali (India) | bn-IN | False | ||||||||
| Bosnian (Bosnia and Herzegovina) | bs-BA | False | ||||||||
| Bosnian (Bosnia and Herzegovina) | bs-BA | True | ||||||||
| Bosnian (Bosnia and Herzegovina) | bs-BA | False | ||||||||
| Bulgarian (Bulgaria) | bg-BG | False | ||||||||
| Bulgarian (Bulgaria) | bg-BG | True | ||||||||
| Bulgarian (Bulgaria) | bg-BG | False | ||||||||
| Bulgarian (Bulgaria) | bg-BG | False | ||||||||
| Bulgarian (Bulgaria) | bg-BG | True | ||||||||
| Bulgarian (Bulgaria) | bg-BG | False | ||||||||
| Bulgarian (Bulgaria) | bg-BG | True | ||||||||
| Burmese (Myanmar) | my-MM | False | ||||||||
| Burmese (Myanmar) | my-MM | True | ||||||||
| Burmese (Myanmar) | my-MM | False | ||||||||
| Catalan (Spain) | ca-ES | False | ||||||||
| Catalan (Spain) | ca-ES | True | ||||||||
| Catalan (Spain) | ca-ES | False | ||||||||
| Chinese (Simplified, China) | cmn-Hans-CN | False | ✔ | |||||||
| Chinese (Simplified, China) | cmn-Hans-CN | True | ✔ | |||||||
| Chinese (Simplified, China) | cmn-Hans-CN | False | ✔ | |||||||
| Chinese (Simplified, Hong Kong) | cmn-Hans-HK | False | ✔ | |||||||
| Chinese (Simplified, Hong Kong) | cmn-Hans-HK | True | ✔ | |||||||
| Chinese (Simplified, Hong Kong) | cmn-Hans-HK | False | ✔ | |||||||
| Chinese (Traditional, Taiwan) | cmn-Hant-TW | False | ✔ | |||||||
| Chinese (Traditional, Taiwan) | cmn-Hant-TW | True | ✔ | |||||||
| Chinese (Traditional, Taiwan) | cmn-Hant-TW | False | ✔ | |||||||
| Chinese, Cantonese (Traditional Hong Kong) | yue-Hant-HK | False | ||||||||
| Chinese, Cantonese (Traditional Hong Kong) | yue-Hant-HK | True | ||||||||
| Chinese, Cantonese (Traditional Hong Kong) | yue-Hant-HK | False | ||||||||
| Croatian (Croatia) | hr-HR | False | ||||||||
| Croatian (Croatia) | hr-HR | True | ||||||||
| Croatian (Croatia) | hr-HR | False | ||||||||
| Czech (Czech Republic) | cs-CZ | False | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | True | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | False | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | False | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | True | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | False | ✔ | |||||||
| Czech (Czech Republic) | cs-CZ | True | ✔ | |||||||
| Danish (Denmark) | da-DK | False | ✔ | |||||||
| Danish (Denmark) | da-DK | True | ✔ | |||||||
| Danish (Denmark) | da-DK | False | ✔ | |||||||
| Danish (Denmark) | da-DK | False | ✔ | |||||||
| Danish (Denmark) | da-DK | True | ✔ | |||||||
| Danish (Denmark) | da-DK | False | ✔ | |||||||
| Danish (Denmark) | da-DK | True | ✔ | |||||||
| Dutch (Belgium) | nl-BE | False | ||||||||
| Dutch (Belgium) | nl-BE | True | ||||||||
| Dutch (Belgium) | nl-BE | False | ||||||||
| Dutch (Belgium) | nl-BE | False | ✔ | |||||||
| Dutch (Belgium) | nl-BE | False | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | False | ||||||||
| Dutch (Netherlands) | nl-NL | True | ||||||||
| Dutch (Netherlands) | nl-NL | False | ||||||||
| Dutch (Netherlands) | nl-NL | False | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | True | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | False | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | True | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | False | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | True | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | False | ✔ | |||||||
| Dutch (Netherlands) | nl-NL | True | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | True | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | True | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | True | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | True | ✔ | |||||||
| English (Australia) | en-AU | False | ✔ | |||||||
| English (Australia) | en-AU | True | ✔ | |||||||
| English (Canada) | en-CA | False | ||||||||
| English (Canada) | en-CA | True | ||||||||
| English (Canada) | en-CA | False | ||||||||
| English (Canada) | en-CA | False | ✔ | |||||||
| English (Canada) | en-CA | True | ✔ | |||||||
| English (Canada) | en-CA | False | ✔ | |||||||
| English (Canada) | en-CA | True | ✔ | |||||||
| English (Ghana) | en-GH | False | ||||||||
| English (Ghana) | en-GH | True | ||||||||
| English (Ghana) | en-GH | False | ||||||||
| English (Hong Kong) | en-HK | False | ||||||||
| English (Hong Kong) | en-HK | True | ||||||||
| English (Hong Kong) | en-HK | False | ||||||||
| English (Hong Kong) | en-HK | False | ✔ | |||||||
| English (Hong Kong) | en-HK | False | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | True | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | True | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | True | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | True | ✔ | |||||||
| English (India) | en-IN | False | ✔ | |||||||
| English (India) | en-IN | True | ✔ | |||||||
| English (Ireland) | en-IE | False | ||||||||
| English (Ireland) | en-IE | True | ||||||||
| English (Ireland) | en-IE | False | ||||||||
| English (Ireland) | en-IE | False | ✔ | |||||||
| English (Ireland) | en-IE | False | ✔ | |||||||
| English (Kenya) | en-KE | False | ||||||||
| English (Kenya) | en-KE | True | ||||||||
| English (Kenya) | en-KE | False | ||||||||
| English (New Zealand) | en-NZ | False | ||||||||
| English (New Zealand) | en-NZ | True | ||||||||
| English (New Zealand) | en-NZ | False | ||||||||
| English (New Zealand) | en-NZ | False | ✔ | |||||||
| English (New Zealand) | en-NZ | False | ✔ | |||||||
| English (Nigeria) | en-NG | False | ||||||||
| English (Nigeria) | en-NG | True | ||||||||
| English (Nigeria) | en-NG | False | ||||||||
| English (Pakistan) | en-PK | False | ||||||||
| English (Pakistan) | en-PK | True | ||||||||
| English (Pakistan) | en-PK | False | ||||||||
| English (Pakistan) | en-PK | False | ✔ | |||||||
| English (Pakistan) | en-PK | False | ✔ | |||||||
| English (Philippines) | en-PH | False | ||||||||
| English (Philippines) | en-PH | True | ||||||||
| English (Philippines) | en-PH | False | ||||||||
| English (Singapore) | en-SG | False | ✔ | |||||||
| English (Singapore) | en-SG | True | ✔ | |||||||
| English (Singapore) | en-SG | False | ✔ | |||||||
| English (Singapore) | en-SG | False | ✔ | |||||||
| English (Singapore) | en-SG | False | ✔ | |||||||
| English (South Africa) | en-ZA | False | ||||||||
| English (South Africa) | en-ZA | True | ||||||||
| English (South Africa) | en-ZA | False | ||||||||
| English (Tanzania) | en-TZ | False | ||||||||
| English (Tanzania) | en-TZ | True | ||||||||
| English (Tanzania) | en-TZ | False | ||||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | True | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | True | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | True | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | True | ✔ | |||||||
| English (United Kingdom) | en-GB | False | ✔ | |||||||
| English (United Kingdom) | en-GB | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| English (United States) | en-US | True | ✔ | |||||||
| English (United States) | en-US | False | ✔ | |||||||
| Estonian (Estonia) | et-EE | False | ||||||||
| Estonian (Estonia) | et-EE | True | ||||||||
| Estonian (Estonia) | et-EE | False | ||||||||
| Filipino (Philippines) | fil-PH | False | ||||||||
| Filipino (Philippines) | fil-PH | True | ||||||||
| Filipino (Philippines) | fil-PH | False | ||||||||
| Finnish (Finland) | fi-FI | False | ✔ | |||||||
| Finnish (Finland) | fi-FI | True | ✔ | |||||||
| Finnish (Finland) | fi-FI | False | ✔ | |||||||
| Finnish (Finland) | fi-FI | False | ✔ | |||||||
| Finnish (Finland) | fi-FI | True | ✔ | |||||||
| Finnish (Finland) | fi-FI | False | ✔ | |||||||
| Finnish (Finland) | fi-FI | True | ✔ | |||||||
| French (Belgium) | fr-BE | False | ||||||||
| French (Belgium) | fr-BE | True | ||||||||
| French (Belgium) | fr-BE | False | ||||||||
| French (Belgium) | fr-BE | False | ✔ | |||||||
| French (Belgium) | fr-BE | False | ✔ | |||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | True | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | True | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | True | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | True | ||||||||
| French (Canada) | fr-CA | False | ||||||||
| French (Canada) | fr-CA | True | ||||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | True | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | True | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | True | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | True | ✔ | |||||||
| French (France) | fr-FR | False | ✔ | |||||||
| French (France) | fr-FR | True | ✔ | |||||||
| French (Switzerland) | fr-CH | False | ||||||||
| French (Switzerland) | fr-CH | True | ||||||||
| French (Switzerland) | fr-CH | False | ||||||||
| French (Switzerland) | fr-CH | False | ✔ | |||||||
| French (Switzerland) | fr-CH | False | ✔ | |||||||
| Galician (Spain) | gl-ES | False | ||||||||
| Galician (Spain) | gl-ES | True | ||||||||
| Galician (Spain) | gl-ES | False | ||||||||
| Georgian (Georgia) | ka-GE | False | ||||||||
| Georgian (Georgia) | ka-GE | True | ||||||||
| Georgian (Georgia) | ka-GE | False | ||||||||
| German (Austria) | de-AT | False | ||||||||
| German (Austria) | de-AT | True | ||||||||
| German (Austria) | de-AT | False | ||||||||
| German (Austria) | de-AT | False | ✔ | |||||||
| German (Austria) | de-AT | False | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | True | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | True | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | True | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | True | ✔ | |||||||
| German (Germany) | de-DE | False | ✔ | |||||||
| German (Germany) | de-DE | True | ✔ | |||||||
| German (Switzerland) | de-CH | False | ||||||||
| German (Switzerland) | de-CH | True | ||||||||
| German (Switzerland) | de-CH | False | ||||||||
| German (Switzerland) | de-CH | False | ✔ | |||||||
| German (Switzerland) | de-CH | False | ✔ | |||||||
| Greek (Greece) | el-GR | False | ||||||||
| Greek (Greece) | el-GR | True | ||||||||
| Greek (Greece) | el-GR | False | ||||||||
| Gujarati (India) | gu-IN | False | ||||||||
| Gujarati (India) | gu-IN | True | ||||||||
| Gujarati (India) | gu-IN | False | ||||||||
| Hebrew (Israel) | iw-IL | False | ||||||||
| Hebrew (Israel) | iw-IL | True | ||||||||
| Hebrew (Israel) | iw-IL | False | ||||||||
| Hindi (India) | hi-IN | False | ||||||||
| Hindi (India) | hi-IN | True | ||||||||
| Hindi (India) | hi-IN | False | ||||||||
| Hindi (India) | hi-IN | False | ✔ | |||||||
| Hindi (India) | hi-IN | True | ✔ | |||||||
| Hindi (India) | hi-IN | False | ✔ | |||||||
| Hindi (India) | hi-IN | True | ✔ | |||||||
| Hindi (India) | hi-IN | False | ✔ | |||||||
| Hindi (India) | hi-IN | True | ✔ | |||||||
| Hindi (India) | hi-IN | False | ✔ | |||||||
| Hindi (India) | hi-IN | True | ✔ | |||||||
| Hungarian (Hungary) | hu-HU | False | ||||||||
| Hungarian (Hungary) | hu-HU | True | ||||||||
| Hungarian (Hungary) | hu-HU | False | ||||||||
| Hungarian (Hungary) | hu-HU | False | ||||||||
| Hungarian (Hungary) | hu-HU | True | ||||||||
| Hungarian (Hungary) | hu-HU | False | ||||||||
| Hungarian (Hungary) | hu-HU | True | ||||||||
| Icelandic (Iceland) | is-IS | False | ||||||||
| Icelandic (Iceland) | is-IS | True | ||||||||
| Icelandic (Iceland) | is-IS | False | ||||||||
| Indonesian (Indonesia) | id-ID | False | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | True | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | False | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | False | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | True | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | False | ✔ | |||||||
| Indonesian (Indonesia) | id-ID | True | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | True | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | True | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | True | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | True | ✔ | |||||||
| Italian (Italy) | it-IT | False | ✔ | |||||||
| Italian (Italy) | it-IT | True | ✔ | |||||||
| Italian (Switzerland) | it-CH | False | ||||||||
| Italian (Switzerland) | it-CH | True | ||||||||
| Italian (Switzerland) | it-CH | False | ||||||||
| Italian (Switzerland) | it-CH | False | ✔ | |||||||
| Italian (Switzerland) | it-CH | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | True | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | True | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | True | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | True | ✔ | |||||||
| Japanese (Japan) | ja-JP | False | ✔ | |||||||
| Japanese (Japan) | ja-JP | True | ✔ | |||||||
| Javanese (Indonesia) | jv-ID | False | ||||||||
| Javanese (Indonesia) | jv-ID | True | ||||||||
| Javanese (Indonesia) | jv-ID | False | ||||||||
| Kannada (India) | kn-IN | False | ||||||||
| Kannada (India) | kn-IN | True | ||||||||
| Kannada (India) | kn-IN | False | ||||||||
| Kannada (India) | kn-IN | False | ||||||||
| Kannada (India) | kn-IN | True | ||||||||
| Kannada (India) | kn-IN | False | ||||||||
| Kannada (India) | kn-IN | True | ||||||||
| Kazakh (Kazakhstan) | kk-KZ | False | ||||||||
| Kazakh (Kazakhstan) | kk-KZ | True | ||||||||
| Kazakh (Kazakhstan) | kk-KZ | False | ||||||||
| Khmer (Cambodia) | km-KH | False | ||||||||
| Khmer (Cambodia) | km-KH | True | ||||||||
| Khmer (Cambodia) | km-KH | False | ||||||||
| Khmer (Cambodia) | km-KH | False | ||||||||
| Khmer (Cambodia) | km-KH | True | ||||||||
| Khmer (Cambodia) | km-KH | False | ||||||||
| Khmer (Cambodia) | km-KH | True | ||||||||
| Kinyarwanda (Rwanda) | rw-RW | False | ||||||||
| Kinyarwanda (Rwanda) | rw-RW | True | ||||||||
| Kinyarwanda (Rwanda) | rw-RW | False | ||||||||
| Kinyarwanda (Rwanda) | rw-RW | True | ||||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | True | ✔ | |||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | True | ✔ | |||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | True | ✔ | |||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | True | ✔ | |||||||
| Korean (South Korea) | ko-KR | False | ✔ | |||||||
| Korean (South Korea) | ko-KR | True | ✔ | |||||||
| Lao (Laos) | lo-LA | False | ||||||||
| Lao (Laos) | lo-LA | True | ||||||||
| Lao (Laos) | lo-LA | False | ||||||||
| Latvian (Latvia) | lv-LV | False | ||||||||
| Latvian (Latvia) | lv-LV | True | ||||||||
| Latvian (Latvia) | lv-LV | False | ||||||||
| Lithuanian (Lithuania) | lt-LT | False | ||||||||
| Lithuanian (Lithuania) | lt-LT | True | ||||||||
| Lithuanian (Lithuania) | lt-LT | False | ||||||||
| Macedonian (North Macedonia) | mk-MK | False | ||||||||
| Macedonian (North Macedonia) | mk-MK | True | ||||||||
| Macedonian (North Macedonia) | mk-MK | False | ||||||||
| Macedonian (North Macedonia) | mk-MK | False | ||||||||
| Macedonian (North Macedonia) | mk-MK | True | ||||||||
| Macedonian (North Macedonia) | mk-MK | False | ||||||||
| Macedonian (North Macedonia) | mk-MK | True | ||||||||
| Malay (Malaysia) | ms-MY | False | ||||||||
| Malay (Malaysia) | ms-MY | True | ||||||||
| Malay (Malaysia) | ms-MY | False | ||||||||
| Malayalam (India) | ml-IN | False | ||||||||
| Malayalam (India) | ml-IN | True | ||||||||
| Malayalam (India) | ml-IN | False | ||||||||
| Malayalam (India) | ml-IN | False | ||||||||
| Malayalam (India) | ml-IN | True | ||||||||
| Malayalam (India) | ml-IN | False | ||||||||
| Malayalam (India) | ml-IN | True | ||||||||
| Marathi (India) | mr-IN | False | ||||||||
| Marathi (India) | mr-IN | True | ||||||||
| Marathi (India) | mr-IN | False | ||||||||
| Marathi (India) | mr-IN | False | ||||||||
| Marathi (India) | mr-IN | True | ||||||||
| Marathi (India) | mr-IN | False | ||||||||
| Marathi (India) | mr-IN | True | ||||||||
| Mongolian (Mongolia) | mn-MN | False | ||||||||
| Mongolian (Mongolia) | mn-MN | True | ||||||||
| Mongolian (Mongolia) | mn-MN | False | ||||||||
| Nepali (Nepal) | ne-NP | False | ||||||||
| Nepali (Nepal) | ne-NP | True | ||||||||
| Nepali (Nepal) | ne-NP | False | ||||||||
| Norwegian Bokmål (Norway) | no-NO | False | ||||||||
| Norwegian Bokmål (Norway) | no-NO | True | ||||||||
| Norwegian Bokmål (Norway) | no-NO | False | ||||||||
| Norwegian Bokmål (Norway) | no-NO | False | ||||||||
| Norwegian Bokmål (Norway) | no-NO | True | ||||||||
| Norwegian Bokmål (Norway) | no-NO | False | ||||||||
| Norwegian Bokmål (Norway) | no-NO | True | ||||||||
| Persian (Iran) | fa-IR | False | ||||||||
| Persian (Iran) | fa-IR | True | ||||||||
| Persian (Iran) | fa-IR | False | ||||||||
| Polish (Poland) | pl-PL | False | ||||||||
| Polish (Poland) | pl-PL | True | ||||||||
| Polish (Poland) | pl-PL | False | ||||||||
| Polish (Poland) | pl-PL | False | ||||||||
| Polish (Poland) | pl-PL | True | ||||||||
| Polish (Poland) | pl-PL | False | ||||||||
| Polish (Poland) | pl-PL | True | ||||||||
| Portuguese (Brazil) | pt-BR | False | ||||||||
| Portuguese (Brazil) | pt-BR | True | ||||||||
| Portuguese (Brazil) | pt-BR | False | ||||||||
| Portuguese (Brazil) | pt-BR | False | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | True | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | False | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | True | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | False | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | False | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | True | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | False | ✔ | |||||||
| Portuguese (Brazil) | pt-BR | True | ✔ | |||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | True | ||||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | True | ||||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | True | ||||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | True | ||||||||
| Portuguese (Portugal) | pt-PT | False | ||||||||
| Portuguese (Portugal) | pt-PT | True | ||||||||
| Punjabi (Gurmukhi India) | pa-Guru-IN | False | ||||||||
| Punjabi (Gurmukhi India) | pa-Guru-IN | True | ||||||||
| Punjabi (Gurmukhi India) | pa-Guru-IN | False | ||||||||
| Romanian (Romania) | ro-RO | False | ||||||||
| Romanian (Romania) | ro-RO | True | ||||||||
| Romanian (Romania) | ro-RO | False | ||||||||
| Romanian (Romania) | ro-RO | False | ||||||||
| Romanian (Romania) | ro-RO | True | ||||||||
| Romanian (Romania) | ro-RO | False | ||||||||
| Romanian (Romania) | ro-RO | True | ||||||||
| Russian (Russia) | ru-RU | False | ||||||||
| Russian (Russia) | ru-RU | True | ||||||||
| Russian (Russia) | ru-RU | False | ||||||||
| Russian (Russia) | ru-RU | False | ✔ | |||||||
| Russian (Russia) | ru-RU | True | ✔ | |||||||
| Russian (Russia) | ru-RU | False | ✔ | |||||||
| Russian (Russia) | ru-RU | True | ✔ | |||||||
| Russian (Russia) | ru-RU | False | ✔ | |||||||
| Serbian (Serbia) | sr-RS | False | ||||||||
| Serbian (Serbia) | sr-RS | True | ||||||||
| Serbian (Serbia) | sr-RS | False | ||||||||
| Sinhala (Sri Lanka) | si-LK | False | ||||||||
| Sinhala (Sri Lanka) | si-LK | True | ||||||||
| Sinhala (Sri Lanka) | si-LK | False | ||||||||
| Slovak (Slovakia) | sk-SK | False | ||||||||
| Slovak (Slovakia) | sk-SK | True | ||||||||
| Slovak (Slovakia) | sk-SK | False | ||||||||
| Slovenian (Slovenia) | sl-SI | False | ||||||||
| Slovenian (Slovenia) | sl-SI | True | ||||||||
| Slovenian (Slovenia) | sl-SI | False | ||||||||
| Southern Sotho (South Africa) | st-ZA | False | ||||||||
| Southern Sotho (South Africa) | st-ZA | True | ||||||||
| Southern Sotho (South Africa) | st-ZA | False | ||||||||
| Southern Sotho (South Africa) | st-ZA | True | ||||||||
| Spanish (Argentina) | es-AR | False | ||||||||
| Spanish (Argentina) | es-AR | True | ||||||||
| Spanish (Argentina) | es-AR | False | ||||||||
| Spanish (Argentina) | es-AR | False | ✔ | |||||||
| Spanish (Bolivia) | es-BO | False | ||||||||
| Spanish (Bolivia) | es-BO | True | ||||||||
| Spanish (Bolivia) | es-BO | False | ||||||||
| Spanish (Bolivia) | es-BO | False | ✔ | |||||||
| Spanish (Chile) | es-CL | False | ||||||||
| Spanish (Chile) | es-CL | True | ||||||||
| Spanish (Chile) | es-CL | False | ||||||||
| Spanish (Chile) | es-CL | False | ✔ | |||||||
| Spanish (Colombia) | es-CO | False | ||||||||
| Spanish (Colombia) | es-CO | True | ||||||||
| Spanish (Colombia) | es-CO | False | ||||||||
| Spanish (Colombia) | es-CO | False | ✔ | |||||||
| Spanish (Costa Rica) | es-CR | False | ||||||||
| Spanish (Costa Rica) | es-CR | True | ||||||||
| Spanish (Costa Rica) | es-CR | False | ||||||||
| Spanish (Costa Rica) | es-CR | False | ✔ | |||||||
| Spanish (Dominican Republic) | es-DO | False | ||||||||
| Spanish (Dominican Republic) | es-DO | True | ||||||||
| Spanish (Dominican Republic) | es-DO | False | ||||||||
| Spanish (Dominican Republic) | es-DO | False | ✔ | |||||||
| Spanish (Ecuador) | es-EC | False | ||||||||
| Spanish (Ecuador) | es-EC | True | ||||||||
| Spanish (Ecuador) | es-EC | False | ||||||||
| Spanish (Ecuador) | es-EC | False | ✔ | |||||||
| Spanish (El Salvador) | es-SV | False | ||||||||
| Spanish (El Salvador) | es-SV | True | ||||||||
| Spanish (El Salvador) | es-SV | False | ||||||||
| Spanish (El Salvador) | es-SV | False | ✔ | |||||||
| Spanish (Guatemala) | es-GT | False | ||||||||
| Spanish (Guatemala) | es-GT | True | ||||||||
| Spanish (Guatemala) | es-GT | False | ||||||||
| Spanish (Guatemala) | es-GT | False | ✔ | |||||||
| Spanish (Honduras) | es-HN | False | ||||||||
| Spanish (Honduras) | es-HN | True | ||||||||
| Spanish (Honduras) | es-HN | False | ||||||||
| Spanish (Honduras) | es-HN | False | ✔ | |||||||
| Spanish (Mexico) | es-MX | False | ||||||||
| Spanish (Mexico) | es-MX | True | ||||||||
| Spanish (Mexico) | es-MX | False | ||||||||
| Spanish (Mexico) | es-MX | False | ✔ | |||||||
| Spanish (Nicaragua) | es-NI | False | ||||||||
| Spanish (Nicaragua) | es-NI | True | ||||||||
| Spanish (Nicaragua) | es-NI | False | ||||||||
| Spanish (Nicaragua) | es-NI | False | ✔ | |||||||
| Spanish (Panama) | es-PA | False | ||||||||
| Spanish (Panama) | es-PA | True | ||||||||
| Spanish (Panama) | es-PA | False | ||||||||
| Spanish (Panama) | es-PA | False | ✔ | |||||||
| Spanish (Paraguay) | es-PY | False | ||||||||
| Spanish (Paraguay) | es-PY | True | ||||||||
| Spanish (Paraguay) | es-PY | False | ||||||||
| Spanish (Peru) | es-PE | False | ||||||||
| Spanish (Peru) | es-PE | True | ||||||||
| Spanish (Peru) | es-PE | False | ||||||||
| Spanish (Peru) | es-PE | False | ✔ | |||||||
| Spanish (Puerto Rico) | es-PR | False | ||||||||
| Spanish (Puerto Rico) | es-PR | True | ||||||||
| Spanish (Puerto Rico) | es-PR | False | ||||||||
| Spanish (Puerto Rico) | es-PR | False | ✔ | |||||||
| Spanish (Spain) | es-ES | False | ||||||||
| Spanish (Spain) | es-ES | True | ||||||||
| Spanish (Spain) | es-ES | False | ||||||||
| Spanish (Spain) | es-ES | False | ✔ | |||||||
| Spanish (Spain) | es-ES | True | ✔ | |||||||
| Spanish (Spain) | es-ES | False | ✔ | |||||||
| Spanish (Spain) | es-ES | True | ✔ | |||||||
| Spanish (Spain) | es-ES | False | ||||||||
| Spanish (Spain) | es-ES | False | ✔ | |||||||
| Spanish (Spain) | es-ES | True | ✔ | |||||||
| Spanish (Spain) | es-ES | False | ✔ | |||||||
| Spanish (Spain) | es-ES | True | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | True | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | True | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | True | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | True | ✔ | |||||||
| Spanish (United States) | es-US | False | ✔ | |||||||
| Spanish (United States) | es-US | True | ✔ | |||||||
| Spanish (Uruguay) | es-UY | False | ||||||||
| Spanish (Uruguay) | es-UY | True | ||||||||
| Spanish (Uruguay) | es-UY | False | ||||||||
| Spanish (Uruguay) | es-UY | False | ✔ | |||||||
| Spanish (Venezuela) | es-VE | False | ||||||||
| Spanish (Venezuela) | es-VE | True | ||||||||
| Spanish (Venezuela) | es-VE | False | ||||||||
| Spanish (Venezuela) | es-VE | False | ✔ | |||||||
| Sundanese (Indonesia) | su-ID | False | ||||||||
| Sundanese (Indonesia) | su-ID | True | ||||||||
| Sundanese (Indonesia) | su-ID | False | ||||||||
| Swahili (Kenya) | sw-KE | False | ||||||||
| Swahili (Kenya) | sw-KE | True | ||||||||
| Swahili (Kenya) | sw-KE | False | ||||||||
| Swahili (Tanzania) | sw-TZ | False | ||||||||
| Swahili (Tanzania) | sw-TZ | True | ||||||||
| Swahili (Tanzania) | sw-TZ | False | ||||||||
| Swati (Latin, South Africa) | ss-Latn-ZA | False | ||||||||
| Swati (Latin, South Africa) | ss-Latn-ZA | True | ||||||||
| Swati (Latin, South Africa) | ss-Latn-ZA | False | ||||||||
| Swati (Latin, South Africa) | ss-Latn-ZA | True | ||||||||
| Swedish (Sweden) | sv-SE | False | ✔ | |||||||
| Swedish (Sweden) | sv-SE | True | ✔ | |||||||
| Swedish (Sweden) | sv-SE | False | ✔ | |||||||
| Swedish (Sweden) | sv-SE | False | ✔ | |||||||
| Swedish (Sweden) | sv-SE | True | ✔ | |||||||
| Swedish (Sweden) | sv-SE | False | ✔ | |||||||
| Swedish (Sweden) | sv-SE | True | ✔ | |||||||
| Tamil (India) | ta-IN | False | ||||||||
| Tamil (India) | ta-IN | True | ||||||||
| Tamil (India) | ta-IN | False | ||||||||
| Tamil (India) | ta-IN | False | ||||||||
| Tamil (India) | ta-IN | True | ||||||||
| Tamil (India) | ta-IN | False | ||||||||
| Tamil (India) | ta-IN | True | ||||||||
| Tamil (Malaysia) | ta-MY | False | ||||||||
| Tamil (Malaysia) | ta-MY | True | ||||||||
| Tamil (Malaysia) | ta-MY | False | ||||||||
| Tamil (Singapore) | ta-SG | False | ||||||||
| Tamil (Singapore) | ta-SG | True | ||||||||
| Tamil (Singapore) | ta-SG | False | ||||||||
| Tamil (Sri Lanka) | ta-LK | False | ||||||||
| Tamil (Sri Lanka) | ta-LK | True | ||||||||
| Tamil (Sri Lanka) | ta-LK | False | ||||||||
| Telugu (India) | te-IN | False | ||||||||
| Telugu (India) | te-IN | True | ||||||||
| Telugu (India) | te-IN | False | ||||||||
| Telugu (India) | te-IN | False | ||||||||
| Telugu (India) | te-IN | True | ||||||||
| Telugu (India) | te-IN | False | ||||||||
| Telugu (India) | te-IN | True | ||||||||
| Thai (Thailand) | th-TH | False | ||||||||
| Thai (Thailand) | th-TH | True | ||||||||
| Thai (Thailand) | th-TH | False | ||||||||
| Thai (Thailand) | th-TH | False | ||||||||
| Thai (Thailand) | th-TH | True | ||||||||
| Thai (Thailand) | th-TH | False | ||||||||
| Thai (Thailand) | th-TH | True | ||||||||
| Tsonga (South Africa) | ts-ZA | False | ||||||||
| Tsonga (South Africa) | ts-ZA | True | ||||||||
| Tsonga (South Africa) | ts-ZA | False | ||||||||
| Tsonga (South Africa) | ts-ZA | True | ||||||||
| Tswana (Latin, South Africa) | tn-Latn-ZA | False | ||||||||
| Tswana (Latin, South Africa) | tn-Latn-ZA | True | ||||||||
| Tswana (Latin, South Africa) | tn-Latn-ZA | False | ||||||||
| Tswana (Latin, South Africa) | tn-Latn-ZA | True | ||||||||
| Turkish (Turkey) | tr-TR | False | ✔ | |||||||
| Turkish (Turkey) | tr-TR | True | ✔ | |||||||
| Turkish (Turkey) | tr-TR | False | ✔ | |||||||
| Turkish (Turkey) | tr-TR | False | ✔ | |||||||
| Turkish (Turkey) | tr-TR | True | ✔ | |||||||
| Turkish (Turkey) | tr-TR | False | ✔ | |||||||
| Turkish (Turkey) | tr-TR | True | ✔ | |||||||
| Ukrainian (Ukraine) | uk-UA | False | ||||||||
| Ukrainian (Ukraine) | uk-UA | True | ||||||||
| Ukrainian (Ukraine) | uk-UA | False | ||||||||
| Ukrainian (Ukraine) | uk-UA | False | ||||||||
| Ukrainian (Ukraine) | uk-UA | True | ||||||||
| Ukrainian (Ukraine) | uk-UA | False | ||||||||
| Ukrainian (Ukraine) | uk-UA | True | ||||||||
| Urdu (India) | ur-IN | False | ||||||||
| Urdu (India) | ur-IN | True | ||||||||
| Urdu (India) | ur-IN | False | ||||||||
| Urdu (Pakistan) | ur-PK | False | ||||||||
| Urdu (Pakistan) | ur-PK | True | ||||||||
| Urdu (Pakistan) | ur-PK | False | ||||||||
| Uzbek (Uzbekistan) | uz-UZ | False | ||||||||
| Uzbek (Uzbekistan) | uz-UZ | True | ||||||||
| Uzbek (Uzbekistan) | uz-UZ | False | ||||||||
| Venda (South Africa) | ve-ZA | False | ||||||||
| Venda (South Africa) | ve-ZA | True | ||||||||
| Venda (South Africa) | ve-ZA | False | ||||||||
| Venda (South Africa) | ve-ZA | True | ||||||||
| Vietnamese (Vietnam) | vi-VN | False | ||||||||
| Vietnamese (Vietnam) | vi-VN | True | ||||||||
| Vietnamese (Vietnam) | vi-VN | False | ||||||||
| Vietnamese (Vietnam) | vi-VN | False | ✔ | |||||||
| Vietnamese (Vietnam) | vi-VN | True | ✔ | |||||||
| Vietnamese (Vietnam) | vi-VN | False | ✔ | |||||||
| Vietnamese (Vietnam) | vi-VN | True | ✔ | |||||||
| Xhosa (South Africa) | xh-ZA | False | ||||||||
| Xhosa (South Africa) | xh-ZA | True | ||||||||
| Xhosa (South Africa) | xh-ZA | False | ||||||||
| Xhosa (South Africa) | xh-ZA | True | ||||||||
| Zulu (South Africa) | zu-ZA | False | ||||||||
| Zulu (South Africa) | zu-ZA | True | ||||||||
| Zulu (South Africa) | zu-ZA | False |
| * | Language tags follow the . |
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2024-09-05 UTC.
speech_to_text 7.0.0 speech_to_text: ^7.0.0 copied to clipboard
A Flutter plugin that exposes device specific speech to text recognition capability.
speech_to_text #
A library that exposes device specific speech recognition capability.
This plugin contains a set of classes that make it easy to use the speech recognition capabilities of the underlying platform in Flutter. It supports Android, iOS, MacOS and web. The target use cases for this library are commands and short phrases, not continuous spoken conversion or always on listening.
Platform Support #
| Support | Android | iOS | MacOS | Web* | Linux | Windows |
|---|---|---|---|---|---|---|
| build | ✅ | ✅ | ✅ | ✅ | ✘ | ✘ |
| speech | ✅ | ✅ | ✅ | ✅ | ✘ | ✘ |
build: means you can build and run with the plugin on that platform
speech: means most speech recognition features work. Platforms with build but not speech report false for initialize
* Only some browsers are supported, see here
Recent Updates #
- Now supports speech recognition on MacOS with many thanks to @alexrabin-sentracam for the PR!
- Now supports WASM compliation for web with many thanks to yeikel16 for the PR!
6.6.0 listen now uses 'SpeechListenOptions' to specify the options for the current listen session, including new options for controlling haptics and punctuation during recognition on iOS.
Note : Feedback from any test devices is welcome.
To recognize text from the microphone import the package and call the plugin, like so:
Complete Flutter example #
Example apps #.
In the example directory you'll find a few different example apps that demonstrate how to use the plugin.
Basic example ( example/lib/main.dart )
This shows how to initialize and use the plugin and allows many of the options to be set through a simple UI. This is probably the first example to look at to understand how to use the plugin.
Provide example ( example/lib/provider_example.dart )
If you are using the (Provider)[https://pub.dev/packages/provider] package in Flutter then this example shows how to use the plugin as a provider throught the SpeechToTextProvider class.
Plugin stress test ( example/lib/stress.dart )
The plugin opens and closes several platform resources as it is used. To help ensure that the plugin does not leak resources this stress test loops through various operations to make it easier to track resource usage. This is mostly an internal development tool so not as useful for reference purposes.
Audio player interaction ( examples/audio_player_interaction/lib/main.dart )
A common use case is to have this plugin and an audio playback plugin working together. This example shows one way to make them work well together. You can find this in
Initialize once #
The initialize method only needs to be called once per application session. After that listen , start , stop , and cancel can be used to interact with the plugin. Subsequent calls to initialize are ignored which is safe but does mean that the onStatus and onError callbacks cannot be reset after the first call to initialize . For that reason there should be only one instance of the plugin per application. The SpeechToTextProvider is one way to create a single instance and easily reuse it in multiple widgets.
Permissions #
Applications using this plugin require user permissions.
iOS & macOS #
Add the following keys to your Info.plist file, located in <project root>/ios/Runner/Info.plist :
- NSSpeechRecognitionUsageDescription - describe why your app uses speech recognition. This is called Privacy - Speech Recognition Usage Description in the visual editor.
- NSMicrophoneUsageDescription - describe why your app needs access to the microphone. This is called Privacy - Microphone Usage Description in the visual editor.
Additional Warning for macOS #
When running the macOS app through VSCode, the app will crash when requesting permissions. This is a known issue with Flutter https://github.com/flutter/flutter/issues/70374 .
You can only request permissions if you run the app directly from Xcode.
If you are upgrading an existing MacOS app to use the new plugin don't forget to update your dependencies and the pods by opening the project directory in your terminal and:
Add the record audio permission to your AndroidManifest.xml file, located in <project root>/android/app/src/main/AndroidManifest.xml .
- android.permission.RECORD_AUDIO - this permission is required for microphone access.
- android.permission.INTERNET - this permission is required because speech recognition may use remote services.
- android.permission.BLUETOOTH - this permission is required because speech recognition can use bluetooth headsets when connected.
- android.permission.BLUETOOTH_ADMIN - this permission is required because speech recognition can use bluetooth headsets when connected.
- android.permission.BLUETOOTH_CONNECT - this permission is required because speech recognition can use bluetooth headsets when connected.
Android SDK 30 or later
If you are targeting Android SDK, i.e. you set your targetSDKVersion to 30 or later, then you will need to add the following to your AndroidManifest.xml right after the permissions section. See the example app for the complete usage.
Adding Sounds for iOS (optional) #
Android automatically plays system sounds when speech listening starts or stops but iOS does not. This plugin supports playing sounds to indicate listening status on iOS if sound files are available as assets in the application. To enable sounds in an application using this plugin add the sound files to the project and reference them in the assets section of the application pubspec.yaml . The location and filenames of the sound files must exactly match what is shown below or they will not be found. The example application for the plugin shows the usage. Note These files should be very short as they delay the start / end of the speech recognizer until the sound playback is complete.
- speech_to_text_listening.m4r - played when the listen method is called.
- speech_to_text_cancel.m4r - played when the cancel method is called.
- speech_to_text_stop.m4r - played when the stop method is called.
Switching Recognition Language #
The speech_to_text plugin uses the default locale for the device for speech recognition by default. However it also supports using any language installed on the device. To find the available languages and select a particular language use these properties.
There's a locales property on the SpeechToText instance that provides the list of locales installed on the device as LocaleName instances. Then the listen method takes an optional localeId named param which would be the localeId property of any of the values returned in locales . A call looks like this:
Troubleshooting #
Speech recognition not working on ios simulator #.
If speech recognition is not working on your simulator try going to the Settings app in the simulator: Accessibility -> Spoken content -> Voices
From there select any language and any speaker and it should download to the device. After that speech recognition should work on the simulator.
Using a Bluetooth headset with your Mac may cause an issue with the simulator speech recognition, see: https://github.com/csdcorp/speech_to_text/issues/539 for details.
Speech recognition stops after a brief pause on Android #
Android speech recognition has a very short timeout when the speaker pauses. The duration seems to vary by device and version of the Android OS. In the devices I've used none have had a pause longer than 5 seconds. Unfortunately there appears to be no way to change that behaviour.
Android beeps on start/stop of speech recognition #
This is a feature of the Android OS and there is no supported way to disable it.
Duplicate results in browser recogntion #
On Android in Chrome and possibly other browsers, the speech API has been implemented differently. The plugin supports a fix for it but it requires a flag to be set on initialization. You can see the details in this issue
Android build #
Version 5.2.0 of the plugin and later require at least compileSdkVersion 31 for the Android build. This property can be set in the build.gradle file.
Continuous speech recognition #
There have been a number of questions about how to achieve continuous speech recognition using this plugin. Currently the plugin is designed for short intermittent use, like when expecting a response to a question, or issuing a single voice command. Issue #63 is the current home for that discussion. There is not yet a way to achieve this goal using the Android or iOS speech recognition capabilities.
There are at least two separate use cases for continuous speech recognition:
- voice assistant style, where recognition of a particular phrase triggers an interaction;
- dictation of text for input.
Voice assistant style interaction is possibly better handled by integrating with the existing assistant capability on the device rather than building out a separate capability. Text dictation is available through the keyboard for standard text input controls though there are other uses of dictation that are not currently well supported.
Browser support for speech recognition #
Web browsers vary in their level of support for speech recognition. This issue has some details. The best lists I've seen are https://caniuse.com/speech-recognition and https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition . In particular in issue #239 it was reported that Brave Browser and Firefox for Linux do not support speech recognition.
Speech recognition from recorded audio #
There have been a number of questions about whether speech can be recognized from recorded audio. The short answer is that this may be possible on iOS but doesn't appear to be on Android. There is an open issue on this here #205.
iOS interactions with other sound plugins, crash when listening or initializing, pauses #
On iOS the speech recognition plugin can interact with other sound plugins, things like WebRTC, or sound playback or recording plugins. While this plugin tries hard to be a good citizen and properly share the various iOS sound resources there is always room for interactions. One thing that might help is to add a brief delay between the end of another sound plugin and starting to listen using SpeechToText. See this issue for example.
SDK version error trying to compile for Android #
The speech_to_text plugin requires at least Android SDK 21 because some of the speech functions in Android were only introduced in that version. To fix this error you need to change the build.gradle entry to reflect this version. Here's what the relevant part of that file looked like as of this writing:
Recording audio on Android #
It is not currently possible to record audio on Android while doing speech recognition. The only solution right now is to stop recording while the speech recognizer is active and then start again after.
Incorrect Swift version trying to compile for iOS #
This happens when the Swift language version is not set correctly. See this thread for help https://github.com/csdcorp/speech_to_text/issues/45 .
Swift not supported trying to compile for iOS #
This usually happens for older projects that only support Objective-C. See this thread for help https://github.com/csdcorp/speech_to_text/issues/88 .
Last word lost on Android #
There's a discussion here https://github.com/csdcorp/speech_to_text/issues/434 about this known issue with some Android speech recognition. This issue is up to Google and other Android implementers to address, the plugin can't improve on their recognition quality.
Not working on a particular Android device #
The symptom for this issue is that the initialize method will always fail. If you turn on debug logging using the debugLogging: true flag on the initialize method you'll see 'Speech recognition unavailable' in the Android log. There's a lengthy issue discussion here https://github.com/csdcorp/speech_to_text/issues/36 about this. The issue seems to be that the recognizer is not always automatically enabled on the device. Two key things helped resolve the issue in this case at least.
Not working on an Android emulator #
The above tip about getting it working on an Android device is also useful for emulators. Some users have reported seeing another error on Android simulators - sdk gphone x86 (Pixel 3a API 30). AUDIO_RECORD perms were in Manifest, also manually set Mic perms in Android Settings. When running sample app, Initialize works, but Start failed the log looks as follows.
Resolved by
Resolved it by Opening Google, clicking Mic icon and granting it perms, then everything on the App works...
- Go to Google Play
- Search for 'Google'
- You should find this app: https://play.google.com/store/apps/details?id=com.google.android.googlequicksearchbox If 'Disabled' enable it
This is the SO post that helped: https://stackoverflow.com/questions/28769320/how-to-check-wether-speech-recognition-is-available-or-not
Ensure the app has the required permissions. The symptom for this that you get a permanent error notification 'error_audio_error` when starting a listen session. Here's a Stack Overflow post that addresses that https://stackoverflow.com/questions/46376193/android-speechrecognizer-audio-recording-error Here's the important excerpt:
You should go to system setting, Apps, Google app, then enable its permission of microphone.
User reported steps
From issue #298 this is the detailed set of steps that resolved their issue:
- install google app
- Settings > Voice > Languages - select the language
- Settings > Voice > Languages > Offline speech recognition - install language
- Settings > Language and region - select the Search language and Search region
- Delete the build folder from the root path of the project and run again
iOS recognition guidelines #
Apple has quite a good guide on the user experience for using speech, the original is here https://developer.apple.com/documentation/speech/sfspeechrecognizer This is the section that I think is particularly relevant:
Create a Great User Experience for Speech Recognition Here are some tips to consider when adding speech recognition support to your app.
Be prepared to handle failures caused by speech recognition limits. Because speech recognition is a network-based service, limits are enforced so that the service can remain freely available to all apps. Individual devices may be limited in the number of recognitions that can be performed per day, and each app may be throttled globally based on the number of requests it makes per day. If a recognition request fails quickly (within a second or two of starting), check to see if the recognition service became unavailable. If it is, you may want to ask users to try again later.
Plan for a one-minute limit on audio duration. Speech recognition places a relatively high burden on battery life and network usage. To minimize this burden, the framework stops speech recognition tasks that last longer than one minute. This limit is similar to the one for keyboard-related dictation. Remind the user when your app is recording. For example, display a visual indicator and play sounds at the beginning and end of speech recognition to help users understand that they're being actively recorded. You can also display speech as it is being recognized so that users understand what your app is doing and see any mistakes made during the recognition process.
Do not perform speech recognition on private or sensitive information. Some speech is not appropriate for recognition. Don't send passwords, health or financial data, and other sensitive speech for recognition.
Repository (GitHub) View/report issues
Documentation
API reference
Dependencies
clock , flutter , flutter_web_plugins , json_annotation , meta , pedantic , speech_to_text_platform_interface , web
Packages that depend on speech_to_text
We Trust in Human Precision
20,000+ Professional Language Experts Ready to Help. Expertise in a variety of Niches.
API Solutions
- API Pricing
- Cost estimate
- Customer loyalty program
- Educational Discount
- Non-Profit Discount
- Green Initiative Discount1
Value-Driven Pricing
Unmatched expertise at affordable rates tailored for your needs. Our services empower you to boost your productivity.
- Special Discounts
- Enterprise transcription solutions
- Enterprise translation solutions
- Transcription/Caption API
- AI Transcription Proofreading API
Trusted by Global Leaders
GoTranscript is the chosen service for top media organizations, universities, and Fortune 50 companies.
GoTranscript
One of the Largest Online Transcription and Translation Agencies in the World. Founded in 2005.
Speaker 1: Hi. In this video, we are going to see how we can perform a streaming transcription on speech-to-text. Now, what is streaming transcription? In my last video, I discussed on batch transcription. So, you take an audio file, you feed an audio file to a speech-to-text model, it transcribes the entire audio at one shot and gives you the output. If you have not seen the video, you can click the link on the top and watch it, or the link is also in the video description below. When we talk about streaming transcription, these are basically typically used for your real-time transcription. Say you want to upload an audio and kind of convert it into text, but the audio is around one hour of play or 20 minutes or 30 minutes. Typically, the speech-to-text process will take around 20 minutes or 30 minutes to do it, and you don't want to wait that long. So, that's where streaming transcription comes into play. What you can do is you can upload the audio, you can buffer the audio in chunks, and then feed the chunk into your speech-to-text transcription and only transcribe a part of it. So, as the audio is kind of getting converted, you can see the output in real-time. Streaming transcription is also applicable when you're talking on a microphone and you want to immediately convert the speech-to-text output. So, typically, in a conversational AI system, when you're talking like, okay, Google, put me the maps. So, as you're talking, if you want to understand, if you see like, okay, Google will start typing it. So, you want to do the transcription real-time, and there also the streaming transcription comes into play. So, let's get started with the video. I would recommend you watch the batch transcription video, which I mentioned earlier. It's there in the YouTube description, but if not as well, it's fine. Some of the concepts, I will cover it and show the difference where the streaming transcription and the batch transcription differs. So, for this video, what I'm doing is, I'm installing some of Unix-specific libraries, LibaSound, PortAudio, which are like prerequisite for your DeepSpeech. And then I am installing DeepSpeech, which is the speech-to-text package we are going to use. I have covered DeepSpeech as well in a separate video. But to give a quick gist, DeepSpeech is basically an Baidu open-sourced package. They use an end-to-end deep learning model to train an acoustic model. And apart from acoustic model, there is a language model as well to improve the accuracy of the output. So, that's what I'm going to do. I have already installed DeepSpeech. And if you see over here, I am downloading two different files from DeepSpeech website. One is the PBMM file, which is nothing but the acoustic model. And this is the end-to-end deep learning library I was talking about. And you have a scorer model, which is nothing but your language model. The language model works on top of the acoustic model output to increase the accuracy of the transcription. So, these are the two files. I have already downloaded it. Now, I am importing a DeepSpeech library. I am importing the model function from that. I am importing NumPy, OS, Wave, and JSON. I am importing, but I am not going to use this in this particular video. And then I am having iPython display audio to play the audio. So, let me run this. Then I am assigning multiple paths. I am assigning the model file path and the language file path. Now, this is the files I downloaded on the top. So, I am telling this is my model file. This is my language model. And then I have multiple parameters that are set. The LM alpha and LM beta are for the language model. And this is taken from the DeepSpeech GitHub repo. This is the best parameter they have published over there based on the hyperparameter search. Hyperparameter search when the model was trained. But you can tune this model to see how you are... Tune these parameters to see how your transcription performs as well. The beamwidth is another parameter. Now, beamwidth basically tells you how many different word sequences will be evaluated by the model. So, if you have a beamwidth of 500, maybe 500 word sequences will be evaluated to find the best probability out of it. If I give 100, it's going to evaluate 100 different word sequences. Now, the more you give, the better transcription you may get. But it also increases the processing time of your end transcription. So, these are the parameters. And then I am calling the model object which I imported on the top and sending the model file path. And once I have the model object, what I am doing is I am enabling an external scoring component for the language model and giving the language model file path. So, I have run this. Now, next what I am going to do is I am going to also set the parameters that I have, lm alpha and lm beta for the scoring model, that is a language model, and beamwidth for your entire hackaustic model. So, let me run this. Now, this is where... This is different from the batch model. So, in the batch model, what we do is we read an audio, we took the entire audio into buffer and sent it for transcription. Here, what we are going to do is we are going to create a stream so that as the audio is read, we are going to take chunk of the audio and then send it for transcription. That's why I am creating a stream object here. So, I am doing a model.createStream and it will give me a stream object. And after that, I am creating two functions. The first function is to read the audio file that I am sending. So, I am sending the audio file. I am getting the frame rate. What is the frame rate of the audio file? What is the number of frames in the audio file? I want to know how many frames are there so that I can kind of iterate and buffer the audio for that particular final frames. And then I am getting a buffer where I am basically taking the frames and then reading the frames and keeping it in a buffer and returning buffer and rate. This is one function. This is nothing but just reads an audio file and sends a byte array of the audio file and also what rate it is. The next thing I am going to do is I am creating one more function called transcribe. In this case, transcribe streaming because transcribe as it is getting streamed I am passing the audio. I am calling the top function read wave file. I am passing the audio file and it returns me buffer and rate and I am setting some of the parameters. In this, what I am doing is I am basically checking my offset. So, I am starting from offset zero. I am checking less than length of buffer. So, my buffer is nothing but the audio byte array. I am checking the length of the audio byte array. If it is less than audio byte array, I am iterating a loop. And in this loop, what I am telling take a batch size of 8196. So, I am taking batch size of 8 KB of the audio every time and transcribing it. That's what this batch size is. So, if you see over here, what I am doing is I am taking the offset plus batch size that is the first 8 KB, read it and then I am taking the buffer object which has the audio and I am passing the starting offset that is zero in this case and then the end offset that is the 8 KB for me. So, I have to read 8 KB chunk. Once I have this chunk size, I am passing it to the numpy array from buffer. So, if I am doing a batch audio, what I am going to do is I am going to pass the buffer directly into this from buffer object. But in this case, I am taking only a portion of an audio to transcribe every time. So, that's why I am sending it to numpy.fromBuffer and then what I am doing is I am telling like stream.feedAudioContent basically, whatever data I got, I am passing it to it and then I am telling like stream.intermediateDecode which will decode at the step. In this case, a set of stream object of 8 KB buffer. It will decode it and give the text. I am printing the text. Now, this is something I have commented out. If in case, what will happen like it will keep printing one after the other and you can see a lot of duplicate data. If you want, you can just clear the console out and watch it. But I want to show you how it looks like and once the first 8 KB is read, I am sending my end offset to offset. So, my top again will come 8 KB plus again 8 KB that is the 8 KB to 8 KB. It will buffer the next 8 KB, next 8 KB till the end of the audio. So, that's what I am doing and it's returning true. Once I have done with the transcription. So, this is run. I am going to download a wave file from the DeepSpeech repo which is nothing but a man1.wp I will show you what it contains and I am downloading it as speech.wav file and let me run this and if you see the, if I list the directory, you can see basically, I have the speech.wav I also have the pbmm score I downloaded. Now, let me take and play this audio file. So, that's why I am calling this audio object which is IPython library that I am using. So, let's listen to the audio. So, this is a very short audio that I have. This is a very short audio that I have. Now, what I am going to do is I am going to take this audio file and call the transcribe streaming function and pass this audio file. That's what I am going to do. So, now once I run it, you can see rather than waiting for the entire file to get completed, it will do it. Just a minute. I think I did not run one more function on the top. Let me go and run the read wave file. Yeah. And then, now let me call this transcribe function. And now you can see rather than as the audio is getting spoken, basically, it's trying to run it and it's printing the output. So, if you see over here, in the course of December, because it has only taken part of the audio, it is trying to guess the word. It's guessing it as dice, not this. Because what will happen, the acoustic model will correct it and also the language model will correct it to see what is the probability of the right word over there. But as I'm getting more buffer, it is trying to interpret the words properly. And finally, you can see in the last one, it is scripting the entire word that we saw in the audio. So, basically, the streaming transcription is pretty much applicable in cases where you want to record from a microphone or you have a very large audio file. You don't want to wait. You want to see the output as soon as the transcription is happening. You can use the streaming transcription function. Thank you very much.

trending now in US News

Accused Georgia school shooter sent haunting apology text to mom...

Biden's astonishing vacation total revealed — prez took 48...

Mom of accused Georgia school shooter speaks out for the first...

Unauthorized satellite dish on warship lands Navy chief in hot...

Ex-Mafia hitman learns his fate for killing notorious Boston...

Gunman on the loose near Ky. highway after 'numerous persons'...

Mom of alleged Georgia school shooter once threatened to kill...

16-year-old accused of fatally shooting classmate, 15, in...
Exclusive photos, trump vows to bring back free speech, calls ‘fake news’ a ‘threat to this country’.
Former President Donald Trump vowed Saturday to bring back free speech in America “because it’s being taken away,” after wowing 15,000 supporters by arriving to a Wisconsin rally in his private jet.
“They’ve taken away your free speech, and the fake news threat is a threat to this country,” said the Republican presidential nominee while speaking at the Central Wisconsin Airport in Mosinee, Wis.
Although Trump didn’t mention any journalists or media outlets by name, his remarks came two days after New York Times publisher A.G. Sulzberger had a scathing op-ed run in the Washington Post, warning “Trump stands out for his aggressive and sustained efforts to undermine the free press.”

Sulzberger also insisted Americans should be ready for Trump’s anti-media “play book” if he wins in November.
“When you’re a politician…, and you happen to be a Republican or somewhat conservative, they write just the opposite of what the facts are, and if you are driving a cab, if you’re an accountant, if you are a lawyer, if you are something other than that, you don’t know the details,” said Trump, who arrived at the airport in his Boeing 757 nicknamed “Trump Force One.”
“When we know the facts, and the story gets written the exact opposite of what it is, you start to lose faith in the press.”
Trump promised, if re-elected, to sign an executive order “banning any federal employee from colluding to limit speech” and to “fire any federal bureaucrat who engaged in domestic censorship under the Harris regime.”
Trump’s appearance was his fourth to Wisconsin during the campaign, but marked his first trip to the deep red, largely rural part of the key battleground state.

He also ripped Harris – who he’ll face Tuesday’s high-stakes presidential debate — for loose border policies that created a national migrant crisis, which has led to spiking crime rates and drained taxpayers’ pockets nationwide.
Like Trump, Harris has been a frequent visitor to Wisconsin this year, a state where four of the past six presidential elections have been decided by less than a percentage point.
Polls of Wisconsin voters conducted since Biden withdrew his re-election bid in July show Harris and Trump in a stalemate.
Democrats consider Wisconsin a must-win “blue wall” state.
Biden, who was in Wisconsin Thursday, won the state in 2020 by just under 21,000 votes, while Trump carried it by nearly 23,000 votes in 2016.
Greek PM to unveil plan to boost pensions, spending power in major speech
- Medium Text

- Greek PM Mitsotakis to unveil economic plan for next year
- He is expected to announce 3 bln extra spending for 2025
- Aim is to lift pensions, cut social security contributions
Sign up here.
Reporting by Lefteris Papadimas and Renee Maltezou; Editing by Edward McAllister and Philippa Fletcher
Our Standards: The Thomson Reuters Trust Principles. , opens new tab

Active shooter at Kentucky highway, 'numerous persons' shot in traffic
How many were shot and the nature of the injuries was not immediately clear.

Go to list of users who liked
More than 3 years have passed since last update.
Flutterで行うSTT(Speech To Text)
- SpeechToText
Flutterの記事を整理し本にしました
- 本稿の記事を含む様々な記事を体系的に整理し本にまとめました
- 今後はこちらを最新化するため、 最新情報はこちらをご確認ください
- 20万文字を超える超大作になっています!!
- Flutter系の記事のまとめ
スマートフォンの機能を使って、人間が喋った音声データをテキストに変換することができます。
パッケージインストール
マイクと録音に関する権限を要求します。
SpeechToTextを使って、喋った内容を文字にします。
await speech.initialize で初期化を行い、 speech.listen でSTTを開始します。 resultListener に変換された文字が順次やってくるため、変数にいれて、格納しています。
再生ボタンで識別開始、停止ボタンで終了します。
Androidの場合は、一定期間音声がないと自動で終了します。
Go to list of comments
Register as a new user and use Qiita more conveniently
- You get articles that match your needs
- You can efficiently read back useful information
- You can use dark theme
‘Stand up and fight': Read Tim Walz's full speech to the Democratic National Convention
Walz highlighted his small-town values and decades-long service in the national guard in a speech to the dnc in chicago, published august 21, 2024 • updated on august 21, 2024 at 11:53 pm.
Editor's note: The text of the speech below is as prepared. His actual delivery may have varied.
Free 24/7 Connecticut news stream: Watch NBC CT wherever you are
Thank you, Vice President Kamala Harris, for putting your trust in me and for inviting me to be part of this incredible campaign. Thank you to President Joe Biden for four years of strong, historic leadership. And it is the honor of my life to accept your nomination for vice president of the United States.
We’re all here tonight for one beautiful, simple reason—we love this country! So thanks to all of you here in Chicago and watching at home tonight—for your passion, for your determination, for the joy that you’re bringing to this fight.
Get top local stories in Connecticut delivered to you every morning. Sign up for NBC Connecticut's News Headlines newsletter.
I grew up in the small town of Butte, Nebraska, population 400. I had 24 kids in my high school class and none of ’em went to Yale. Growing up in a small town like that, you learn to take care of each other. The family down the road—they may not think like you do, they may not pray like you do, they may not love like you do, but they’re your neighbors. And you look out for them, just like they do for you.
Everybody belongs, and everybody has a responsibility to contribute. For me, it was serving in the Army National Guard. I joined up two days after my 17th birthday and I proudly wore our country’s uniform for 24 years. My dad, a Korean War-era veteran, died of lung cancer a couple years later and left behind a mountain of medical debt. Thank God for Social Security survivor benefits. And thank God for the GI Bill that allowed both my dad and me to go to college—just like it has for millions of Americans.
Eventually, I fell in love with teaching, just like the rest of my family. Heck, three out of four of us even married teachers. I wound up teaching social studies and coaching football at Mankato West High School. Go Scarlets! We ran a 4-4 defense, played through the whistle every single down, and even won a state championship. Never close that yearbook, people.
U.S. & World

Multiple people shot along I-75 in southeastern Kentucky, authorities say

Former top US nuclear weapons official dead after car crash in New Mexico
It was my students who first inspired me to run for Congress. They saw in me what I hoped to instill in them—a commitment to the common good. An understanding that we’re all in this together. And a true belief that one person can make a real difference for their neighbors.
So there I was, a 40-something high school teacher with young kids, zero political experience, no money, and running in a deep-red district. But you know what? Never underestimate a public school teacher.
I represented my neighbors in Congress for 12 years and I learned an awful lot. I learned how to work across the aisle on issues like growing rural economies and taking care of our veterans. And I learned how to compromise without compromising my values.
Then I came back home to serve as governor and we got right to work making a difference in our neighbors’ lives. We cut taxes for middle-class families. We passed paid family and medical leave. We invested in fighting crime and affordable housing. We cut the cost of prescription drugs and helped people escape the kind of medical debt that nearly sank my family. And we made sure that every kid in our state got breakfast and lunch at school. So while other states were banning books from their schools, we were banishing hunger from ours.
We also protected reproductive freedom because, in Minnesota, we respect our neighbors and the personal choices they make. And even if we wouldn’t make the same choices for ourselves, we’ve got a Golden Rule—mind your own damn business.
That includes IVF and fertility treatments. This is personal for Gwen and me. Let me just say this—even if you’ve never experienced the hell of infertility, I guarantee you know somebody who has. I remember praying each night for a call with good news, the pit in my stomach when the phone would ring, and the agony when we heard the treatments hadn’t worked. It took me and Gwen years. But we had access to fertility treatments and when our daughter was finally born, we named her Hope. Hope, Gus, Gwen—you are my whole world. I love you all so much.
I’m letting you in on how we started our family because that’s a big part of what this election is about—freedom. When Republicans use that word, they mean that the government should be free to invade your doctor’s office. Corporations free to pollute the air and water. Banks free to take advantage of customers. But when we Democrats talk about freedom, we mean your freedom to make a better life for yourself and the people you love. The freedom to make your own health care decisions. And, yeah, your kids’ freedom to go to school without worrying they’ll be shot dead in the halls.
Look, I know guns. I’m a veteran. I’m a hunter. I was a better shot than most Republicans in Congress and I have the trophies to prove it. But I’m also a dad. I believe in the Second Amendment. But I also believe that our first responsibility is to keep our kids safe. That’s what this is all about. The responsibility we have to our kids, to each other, and to the future we’re building together—a future in which everyone is free to build the kind of life they want.
But not everyone feels the same sense of responsibility. Some folks just don’t understand what it means to be a good neighbor. Take Donald Trump and JD Vance—their Project 2025 will make things much, much harder for people who are just trying to live their lives. They’ve spent a lot of time pretending they know nothing about it. But look, I coached high school football long enough, I promise you this—when somebody takes the time to draw up a playbook, they plan on using it.
We know what they’ll do if they get back in the White House. They’ll jack up costs on middle-class families. They’ll repeal the Affordable Care Act. They’ll gut Social Security and Medicare. They’ll ban abortion across America, with or without Congress.
It’s an agenda that nobody asked for. It’s an agenda that serves nobody but the richest people and the most extreme voices in our country. An agenda that does nothing for our neighbors in need. Is it weird? Absolutely. But it’s also wrong. And it’s dangerous. It’s not just me saying so. It’s Trump’s own people. They were with him for four years. And they’re warning us that the next four years would be much, much worse.
When I was teaching, we would always elect a student body president. And you know what? Those teenagers could teach Donald Trump a lesson about what it means to be a leader. Leaders don’t spend all day insulting people and blaming people. Leaders do the work. I don’t know about you all, but I’m ready to turn the page on these guys. So say it with me: “We’re not going back.”
We’ve got something better to offer the American people. It starts with our candidate, Kamala Harris. From her first day as a prosecutor, as a district attorney, as an attorney general, as a U.S. senator, and then, as our vice president, she’s fought on the side of the American people. She’s taken on predators and fraudsters. She’s taken down transnational gangs. She’s stood up to powerful corporate interests. She’s never hesitated to reach across the aisle if it meant improving lives. And she’s always done it with energy, passion, and joy.
Folks, we have a chance to make Kamala Harris the next president of the United States. But I think we owe it to the American people to tell them exactly what she’d do as president before we ask for their votes. So here’s the part you clip and save and send to that undecided relative.
If you’re a middle-class family or a family trying to get into the middle class, Kamala Harris is gonna cut your taxes. If you’re getting squeezed by the price of your prescription drugs, Kamala Harris is gonna take on Big Pharma. If you’re hoping to buy a home, Kamala Harris is gonna help make it more affordable. And no matter who you are, Kamala Harris is gonna stand up and fight for your freedom to live the life you want to lead. Because that’s what we want for ourselves. And that’s what we want for our neighbors.
You know, I haven’t given a lot of big speeches like this one in my life. But I’ve given a lot of pep talks. So let me finish with this, team. It’s the fourth quarter. We’re down a field goal. But we’re on offense. We’re driving down the field. And, boy, do we have the right team to win this. Kamala Harris is tough. She’s experienced. And she’s ready. Our job is to get in the trenches and do the blocking and tackling. One inch at a time, one yard at a time, one phone call at a time, one door knock at a time, one $5 donation at a time. We’ve only got 76 days to go. That’s nothing. We’ll sleep when we’re dead. And we’re gonna leave it all on the field.
That’s how we’ll keep moving forward. That’s how we’ll turn the page on Donald Trump. That’s how we’ll build a country where workers come first, health care and housing are human rights, and the government stays the hell out of our bedrooms. That’s how we make America a place where no child is left hungry. Where no community is left behind. Where nobody gets told they don’t belong.
That’s how we’re gonna fight. And as the next president of the United States says, “When we fight, we win!” When we fight, we win! When we fight, we win! Thank you, and God bless America!
This article tagged under:
IMAGES
VIDEO
COMMENTS
speech.RecognitionConfig () RecognitionConfig でエンコーディングの設定を行います。. エンコードの種類は こちら から確認できます。. Speech-to-Text 用に音声ファイルを最適化する が役に立ちそうでした。. エンコードの知識がないというのもありますが、この設定方法 ...
Careers. Qiita Blog. はじめにこんにちは。. 現在 株式会社Nexceed にてインターンを行っている学生です。. 今回は議事録を自動生成したいということで音声認識のAPIの使い方を調べてみました。. 以下に簡単な使い方の例….
音声検出のみWeb Speech APIを使い、文字起こし自体はGoogle Speech to Text APIを使うことで、ブラウザ文字起こしにおいてリアルタイム感と精度の高さを両立する; 発端. 現在開発中のプロダクトの中で、Speech to Textの仕組みを導入するために様々な方法を調べてい ...
DeepSpeech is an open source embedded (offline, on-device) speech-to-text engine which can run in real time on devices ranging from a Raspberry Pi 4 to high power GPU servers. machine-learning embedded deep-learning offline tensorflow speech-recognition neural-networks speech-to-text deepspeech on-device.
The Top Free Speech-to-Text APIs, AI Models, and Open ...
Best 13 speech-to-text open-source engine · 1 Whisper · 2 Project DeepSpeech · 3 Kaldi · 4 SpeechBrain · 5 Coqui · 6 Julius · 7 Flashlight ASR (Formerly Wav2Letter++) · 8 PaddleSpeech (Formerly DeepSpeech2) · 9 OpenSeq2Seq · 10 Vosk · 11 Athena · 12 ESPnet · 13 Tensorflow ASR.
Cross-platform, real-time, offline speech recognition plugin for Unreal Engine. Based on Whisper OpenAI technology, whisper.cpp. - gtreshchev/RuntimeSpeechRecognizer
Support your global user base with Speech-to-Text service's extensive language support in over 125 languages and variants. Have full control over your infrastructure and protected speech data while leveraging Google's speech recognition technology on-premises, right in your own private data centers. Take the next step.
Speech-to-Text documentation. View all product documentation. Speech-to-Text enables easy integration of Google speech recognition technologies into developer applications. Send audio and receive a text transcription from the Speech-to-Text API service. Learn more.
Free Speech to Text Online, Voice Typing & Transcription
Speech-to-Text APIの使い方. 今回はSpeech-to-Text APIをコマンドラインから使用する方法をお伝えします。. * コマンドプロンプトを管理者として開く. * 以下のコマンドを実行し、先程ダウンロードした鍵のパスを環境変数に設定する. set GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH".
The Best Speech-to-Text Apps and Tools for Every Type of ...
In this video, I will explain you how to convert speech to text using Python and Google API. Basically, we will be writing a code for implementing a very popular technology known as speech recognition. But before starting, make sure that you have following Python libraries installed in your system. These libraries are Speech Recognition, PY ...
SpeechTexter is a free multilingual speech-to-text application aimed at assisting you with transcription of notes, documents, books, reports or blog posts by using your voice. This app also features a customizable voice commands list, allowing users to add punctuation marks, frequently used phrases, and some app actions (undo, redo, make a new ...
Azure AI text to speech avatar feature capabilities include: Converts text into a digital video of a photorealistic human speaking with natural-sounding voices powered by Azure AI text to speech. Provides a collection of prebuilt avatars. The voice of the avatar is generated by Azure AI text to speech. For more information, see Avatar voice and ...
Go to the Home page in AI Studio and then select AI Services from the left pane. Select Speech from the list of AI services. Select Real-time speech to text. In the Try it out section, select your hub's AI services connection. For more information about AI services connections, see connect AI services to your hub in AI Studio.
Free Speech to Text Converter | Instant Voice Transcription
Idiomas compatibles con Speech-to-Text
自分が何かできるかを考え挙句、Speech-to-textを使って、面接の振り返りできるサービスを作ってみになりません。 設計. 面接官と応募者のオンライン面接の会話をテキストへ変化、記録、分析、面接官へフィットバックします。 Speech-to-text と ASR
speech_to_text | Flutter package
Typically, the speech-to-text process will take around 20 minutes or 30 minutes to do it, and you don't want to wait that long. So, that's where streaming transcription comes into play. What you can do is you can upload the audio, you can buffer the audio in chunks, and then feed the chunk into your speech-to-text transcription and only ...
Former President Donald Trump vowed Saturday to bring back free speech in America "because it's being taken away," after wowing 15,000 supporters by arriving to a Wisconsin rally in his ...
Youtubeは字幕が表示できない動画もあるのです。そんな折、Google Cloud Speech-to-Textを使えば簡単に作成できそうというのがわかりましたので、Googleのドキュメントにあるサンプルプログラムを少し変更して試しに作ってみました。 Google Cloud Speech-to-Textとは
Greek Prime Minister Kyriakos Mitsotakis is expected to unveil plans on Saturday to increase pensions, reduce social security contributions and improve public services in an effort to win back ...
await speech.initializeで初期化を行い、speech.listenでSTTを開始します。 resultListenerに変換された文字が順次やってくるため、変数にいれて、格納しています。. 動作確認. 再生ボタンで識別開始、停止ボタンで終了します。 Androidの場合は、一定期間音声がないと自動で終了します。
'Stand up and fight': Read Tim Walz's full speech to the Democratic National Convention Walz highlighted his small-town values and decades-long service in the National Guard in a speech to the ...