Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Guide to Experimental Design | Overview, Steps, & Examples

Guide to Experimental Design | Overview, 5 steps & Examples
Published on December 3, 2019 by Rebecca Bevans . Revised on June 21, 2023.
Experiments are used to study causal relationships . You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design create a set of procedures to systematically test a hypothesis . A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead. This minimizes several types of research bias, particularly sampling bias , survivorship bias , and attrition bias as time passes.
Table of contents
Step 1: define your variables, step 2: write your hypothesis, step 3: design your experimental treatments, step 4: assign your subjects to treatment groups, step 5: measure your dependent variable, other interesting articles, frequently asked questions about experiments.
You should begin with a specific research question . We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables .
| Research question | Independent variable | Dependent variable |
|---|---|---|
| Phone use and sleep | Minutes of phone use before sleep | Hours of sleep per night |
| Temperature and soil respiration | Air temperature just above the soil surface | CO2 respired from soil |
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
| Extraneous variable | How to control | |
|---|---|---|
| Phone use and sleep | in sleep patterns among individuals. | measure the average difference between sleep with phone use and sleep without phone use rather than the average amount of sleep per treatment group. |
| Temperature and soil respiration | also affects respiration, and moisture can decrease with increasing temperature. | monitor soil moisture and add water to make sure that soil moisture is consistent across all treatment plots. |
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.

Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
| Null hypothesis (H ) | Alternate hypothesis (H ) | |
|---|---|---|
| Phone use and sleep | Phone use before sleep does not correlate with the amount of sleep a person gets. | Increasing phone use before sleep leads to a decrease in sleep. |
| Temperature and soil respiration | Air temperature does not correlate with soil respiration. | Increased air temperature leads to increased soil respiration. |
The next steps will describe how to design a controlled experiment . In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalized and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable : either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size : how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power , which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups . Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group , which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomized design vs a randomized block design .
- A between-subjects design vs a within-subjects design .
Randomization
An experiment can be completely randomized or randomized within blocks (aka strata):
- In a completely randomized design , every subject is assigned to a treatment group at random.
- In a randomized block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
| Completely randomized design | Randomized block design | |
|---|---|---|
| Phone use and sleep | Subjects are all randomly assigned a level of phone use using a random number generator. | Subjects are first grouped by age, and then phone use treatments are randomly assigned within these groups. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random by using a number generator to generate map coordinates within the study area. | Soils are first grouped by average rainfall, and then treatment plots are randomly assigned within these groups. |
Sometimes randomization isn’t practical or ethical , so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design .
Between-subjects vs. within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomizing or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
| Between-subjects (independent measures) design | Within-subjects (repeated measures) design | |
|---|---|---|
| Phone use and sleep | Subjects are randomly assigned a level of phone use (none, low, or high) and follow that level of phone use throughout the experiment. | Subjects are assigned consecutively to zero, low, and high levels of phone use throughout the experiment, and the order in which they follow these treatments is randomized. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random and the soils are kept at this temperature throughout the experiment. | Every plot receives each warming treatment (1, 3, 5, 8, and 10C above ambient temperatures) consecutively over the course of the experiment, and the order in which they receive these treatments is randomized. |
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimize research bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalized to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Likert scale
Research bias
- Implicit bias
- Framing effect
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 21). Guide to Experimental Design | Overview, 5 steps & Examples. Scribbr. Retrieved August 26, 2024, from https://www.scribbr.com/methodology/experimental-design/
Is this article helpful?

Rebecca Bevans
Other students also liked, random assignment in experiments | introduction & examples, quasi-experimental design | definition, types & examples, how to write a lab report, get unlimited documents corrected.
✔ Free APA citation check included ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
Three Principles of Experimental Designs
by Kim Love 1 Comment

Yes, absolutely! Understanding experimental design can help you recognize the questions you can and can’t answer with the data. It will also help you identify possible sources of bias that can lead to undesirable results. Finally, it will help you provide recommendations to make future studies more efficient.
The Three Rs of Experimental Design
An experiment involves one or more treatments, each with two or more conditions. The defining characteristic of an experiment is that the researcher is able to assign subjects to treatment groups.
There are three principles that underlie any experiment. These are often called the three Rs of experimental design , and they are:
Randomization
Replication.
- Reduction of variance
Let’s look at each principle in the context of a specific experiment.
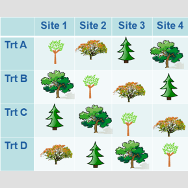
Randomization is the assignment of the subjects in the study to treatment groups in a random way. This is one of the most important aspects of an experiment.
It ensures that the only systematic difference in groups is the treatment condition. In the training experiment, this would mean that any difference in the outcomes between the two groups is due to the training. In other words, random assignment allows you to demonstrate causation.
Suppose the researcher did not randomize, and assigned men to one group and women to the other group. It should be clear that we won’t know if differences between the treatment groups come from gender or training.
Although in this example our confounding variable , gender, is obvious, that’s not always true. Randomization is the only sure way to avoid accidental confounding and its resulting bias.
Replication refers to having multiple subjects in each group. The more subjects in each group, the easier to determine whether any differences between the groups are due to the treatment and not the characteristics of individuals in the groups.
Suppose the training study had limited resources. Would it be enough to recruit only two people, and compare their times after training? Again, it’s probably obvious you can’t do this. The difference in outcomes would depend as much on those two people as it would on the training method.
There are many considerations that go into determining sample size . Generally, though, more subjects per group means more statistical confidence in the outcomes. Too few subjects in a group makes it very hard to find differences in the outcomes between treatment groups.
Reduction of Variance
Reduction of variance refers to removing or accounting for systematic difference among subjects. This allows you to measure the differences due to the treatment more precisely. There are multiple ways to approach this.
One way is to limit the population of the study so the subjects are more similar. Another way is to incorporate covariates into the analysis. These are variables outside of the experimental design that you can measure.
A third way is blocking. This refers to identifying related subjects and randomly assigning them to different treatments.
In the training experiment, not accounting for gender could make it more difficult to estimate the effects of training. There are at least three ways to account for it in the design and data collection.
- Only include one gender in the study, and limit the results of the study to that one gender.
- Measure the participants’ gender and include it in the study as a covariate.
- Include gender in the experimental design as a block. Randomly assign men and women in equal number to the two groups, and include gender in the analysis.
Application to Analysis
Although there are many types of experimental designs, the three Rs are at the heart of each of them. Advanced experimental designs simply achieve these under complicated circumstances. Understanding these principles, even without advanced knowledge, will make you a better analyst.
Always answer the following questions any time you are analyzing experimental data:
1. How was randomization applied in the experiment? This will help you understand whether you can draw causal conclusions. It will also help you recognize if the general conclusions of the study could be biased.
2. How much replication was there in the experiment? If the number of subjects was small (overall or in certain groups), this could result in a lack of findings.
3. Was variability outside of the scope of the experiment appropriately reduced? If the researcher can account for outside factors in the future, this will make the experiment more efficient.

Reader Interactions

July 19, 2022 at 3:02 am
Hi Kim, Thanks for this nice article,
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Privacy Overview
Experimental Design: Types, Examples & Methods
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs.
Probably the most common way to design an experiment in psychology is to divide the participants into two groups, the experimental group and the control group, and then introduce a change to the experimental group, not the control group.
The researcher must decide how he/she will allocate their sample to the different experimental groups. For example, if there are 10 participants, will all 10 participants participate in both groups (e.g., repeated measures), or will the participants be split in half and take part in only one group each?
Three types of experimental designs are commonly used:
1. Independent Measures
Independent measures design, also known as between-groups , is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group.
Independent measures involve using two separate groups of participants, one in each condition. For example:

- Con : More people are needed than with the repeated measures design (i.e., more time-consuming).
- Pro : Avoids order effects (such as practice or fatigue) as people participate in one condition only. If a person is involved in several conditions, they may become bored, tired, and fed up by the time they come to the second condition or become wise to the requirements of the experiment!
- Con : Differences between participants in the groups may affect results, for example, variations in age, gender, or social background. These differences are known as participant variables (i.e., a type of extraneous variable ).
- Control : After the participants have been recruited, they should be randomly assigned to their groups. This should ensure the groups are similar, on average (reducing participant variables).
2. Repeated Measures Design
Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants.
Repeated Measures design is also known as within-groups or within-subjects design .
- Pro : As the same participants are used in each condition, participant variables (i.e., individual differences) are reduced.
- Con : There may be order effects. Order effects refer to the order of the conditions affecting the participants’ behavior. Performance in the second condition may be better because the participants know what to do (i.e., practice effect). Or their performance might be worse in the second condition because they are tired (i.e., fatigue effect). This limitation can be controlled using counterbalancing.
- Pro : Fewer people are needed as they participate in all conditions (i.e., saves time).
- Control : To combat order effects, the researcher counter-balances the order of the conditions for the participants. Alternating the order in which participants perform in different conditions of an experiment.
Counterbalancing
Suppose we used a repeated measures design in which all of the participants first learned words in “loud noise” and then learned them in “no noise.”
We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
The sample would be split into two groups: experimental (A) and control (B). For example, group 1 does ‘A’ then ‘B,’ and group 2 does ‘B’ then ‘A.’ This is to eliminate order effects.
Although order effects occur for each participant, they balance each other out in the results because they occur equally in both groups.

3. Matched Pairs Design
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group .
One member of each matched pair must be randomly assigned to the experimental group and the other to the control group.

- Con : If one participant drops out, you lose 2 PPs’ data.
- Pro : Reduces participant variables because the researcher has tried to pair up the participants so that each condition has people with similar abilities and characteristics.
- Con : Very time-consuming trying to find closely matched pairs.
- Pro : It avoids order effects, so counterbalancing is not necessary.
- Con : Impossible to match people exactly unless they are identical twins!
- Control : Members of each pair should be randomly assigned to conditions. However, this does not solve all these problems.
Experimental design refers to how participants are allocated to an experiment’s different conditions (or IV levels). There are three types:
1. Independent measures / between-groups : Different participants are used in each condition of the independent variable.
2. Repeated measures /within groups : The same participants take part in each condition of the independent variable.
3. Matched pairs : Each condition uses different participants, but they are matched in terms of important characteristics, e.g., gender, age, intelligence, etc.
Learning Check
Read about each of the experiments below. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design.
1 . To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period.
The researchers attempted to ensure that the patients in the two groups had similar severity of depressed symptoms by administering a standardized test of depression to each participant, then pairing them according to the severity of their symptoms.
2 . To assess the difference in reading comprehension between 7 and 9-year-olds, a researcher recruited each group from a local primary school. They were given the same passage of text to read and then asked a series of questions to assess their understanding.
3 . To assess the effectiveness of two different ways of teaching reading, a group of 5-year-olds was recruited from a primary school. Their level of reading ability was assessed, and then they were taught using scheme one for 20 weeks.
At the end of this period, their reading was reassessed, and a reading improvement score was calculated. They were then taught using scheme two for a further 20 weeks, and another reading improvement score for this period was calculated. The reading improvement scores for each child were then compared.
4 . To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page.
Experiment Terminology
Ecological validity.
The degree to which an investigation represents real-life experiences.
Experimenter effects
These are the ways that the experimenter can accidentally influence the participant through their appearance or behavior.
Demand characteristics
The clues in an experiment lead the participants to think they know what the researcher is looking for (e.g., the experimenter’s body language).
Independent variable (IV)
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable.
Dependent variable (DV)
Variable the experimenter measures. This is the outcome (i.e., the result) of a study.
Extraneous variables (EV)
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible.
Confounding variables
Variable(s) that have affected the results (DV), apart from the IV. A confounding variable could be an extraneous variable that has not been controlled.
Random Allocation
Randomly allocating participants to independent variable conditions means that all participants should have an equal chance of taking part in each condition.
The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effects
Changes in participants’ performance due to their repeating the same or similar test more than once. Examples of order effects include:
(i) practice effect: an improvement in performance on a task due to repetition, for example, because of familiarity with the task;
(ii) fatigue effect: a decrease in performance of a task due to repetition, for example, because of boredom or tiredness.
Design of Experiments
Chapter 1 principles of experimental design.
Although it is obviously true that statistical tests are not the only method for arriving at the ‘truth’, it is equally true that formal experiments generally provide the most scientifically valid research result. (Bailar III 1981 )
1.1 Introduction
The validity of conclusions drawn from a statistical analysis crucially hinges on the manner in which the data are acquired, and even the most sophisticated analysis will not rescue a flawed experiment. Planning an experiment and thinking about the details of data acquisition is so important for a successful analysis that R. A. Fisher—who single-handedly invented many of the experimental design techniques we are about to discuss—famously wrote
To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of. (Fisher 1938 )
(Statistical) design of experiments provides the principles and methods for planning experiments and tailoring the data acquisition to an intended analysis. Design and analysis of an experiment are best considered as two aspects of the same enterprise: the goals of the analysis strongly inform an appropriate design, and the implemented design determines the possible analyses.
The primary aim of designing experiments is to ensure that valid statistical and scientific conclusions can be drawn that withstand the scrutiny of a determined skeptic. Good experimental design also considers that resources are used efficiently, and that estimates are sufficiently precise and hypothesis tests adequately powered. It protects our conclusions by excluding alternative interpretations or rendering them implausible. Three main pillars of experimental design are randomization , replication , and blocking , and we will invest substantial effort into fleshing out their effects on the subsequent analysis as well as their implementation in an experimental design.
An experimental design is always tailored towards predefined (primary) analyses and an efficient analysis and unambiguous interpretation of the experimental data is often straightforward from a good design. This does not prevent us from doing additional analyses of interesting observations after the data are acquired, but these analyses can be subjected to more severe criticisms and conclusions are more tentative.
In this chapter, we provide the wider context for using experiments in a larger research enterprise and informally introduce the main statistical ideas of experimental design. We use a comparison of two samples as our main example to study how design choices affect their comparison, but postpone a formal quantitative analysis to the next chapters.
1.2 A cautionary tale
| A | 8.96 | 8.95 | 11.37 | 12.63 | 11.38 | 8.36 | 6.87 | 12.35 | 10.32 | 11.99 |
| B | 12.68 | 11.37 | 12.00 | 9.81 | 10.35 | 11.76 | 9.01 | 10.83 | 8.76 | 9.99 |
For illustrating some of the issues arising in the interplay of experimental design and analysis, we consider a simple example. We are interested in comparing the enzyme levels measured in processed blood samples from laboratory mice, when the preparation is done either with a kit from a vendor A, or a kit from a competitor B. The data in Table 1.1 show measured enzyme levels of 20 mice, with samples of 10 mice prepared with kit A and the remaining 10 samples with kit B.
One option for comparing the two kits is by looking at the difference in average enzyme levels, and we find an average level of 10.32 for vendor A and 10.66 for vendor B. We would like to interpret their difference -0.34 as the difference due to the two preparation kits and conclude whether the two kits give equal results, or if measurements base done one kit are systematically different from those based on the other kit.
Such interpretation, however, is only valid if the two groups of mice and their measurements are identical in all aspects except the sample preparation kit. If we use one strain of mice for kit A and another strain for kit B, any difference might also be attributed to inherent differences between the strains. Similarly, if the measurements using kit B were conducted much later than those using kit A, any observed difference might be attributed to changes in, e.g., mice selected, batches of chemicals used, device calibration or any number of other influences. None of these competing explanation for an observed difference can be excluded from the given data alone, but good experimental design allows us to render them (almost) arbitrarily implausible.
A second aspect for our analysis is the inherent uncertainty in our calculated difference: if we repeat the experiment, the observed difference will change each time, and this will be more pronounced for smaller number of mice, among others. If we do not use a sufficient number of mice in our experiment, the uncertainty associated with the observed difference might be too large, such that random fluctuations become a plausible explanation for the observed difference. Systematic differences between the two kits, of practically relevant magnitude in either direction, might then be compatible with the data, and we can not draw any reliable conclusions from our experiment.
In each case, the statistical analysis—no matter how clever—was doomed before the experiment was even started, while simple ideas from statistical design of experiments would have prevented failure and provided correct and robust results with interpretable conclusions.
1.3 The language of experimental design
By an experiment , we understand an investigation where the researcher has full control over selecting and altering the experimental conditions of interest, and we only consider investigations of this type. The selected experimental conditions are called treatments . An experiment is comparative if the responses to several treatments are to be compared or contrasted. The experimental units are the smallest subdivision of the experimental material to which a treatment can be assigned. All experimental units given the same treatment constitute a treatment group . Especially in biology, we often contrast responses to a control group to which some standard experimental conditions are applied; a typical example is using a placebo for the control group, and different drugs in the other treatment groups.
Multiple experimental units are sometimes combined into groupings or blocks , for example mice are naturally grouped by litter, and samples by batches of chemicals used for their preparation. The values observed are called responses and are measured on the response units ; these are often identical to the experimental units but need not be. More generally, we call any grouping of the experimental material a unit .
In our example, we selected the mice, used a single sample per mouse, deliberately chose the two specific vendors, and had full control over assigning a kit to a mouse. Here, the mice are the experimental units, the samples the response units, the two kits are the treatments, and the responses are the measured enzyme levels. Since we compare the average enzyme levels between treatments and choose which kit to assign to which sample, this is a comparative experiment.
In this example, we can identify experimental and response units, because we have a single response per mouse and cannot distinguish a sample from a mouse in the analysis. By contrast, if we take two samples per mouse and use the same kit for both samples, then the mice are still the experimental units, but each mouse now has two response units associated with it. If we take two samples per mouse, but apply each kit to one of the two samples, then the samples are both the experimental and response units, while the mice are blocks that group the samples. If we only use one kit and determine the average enzyme level, then this investigation is still an experiment, but is not comparative.
Finally, the design of an experiment determines the logical structure of the experiment ; it consists of (i) a set of treatments; (ii) a specification of the experimental units (animals, cell lines, samples); (iii) a procedure for assigning treatments to units; and (iv) a specification of the response units and the quantity to be measured as a response.
1.4 Experiment validity
Before we embark on the more technical aspects of experimental design, we discuss three components for evaluating an experiment’s validity: construct validity , internal validity , and external validity . These criteria are well-established in, e.g., educational and psychological research, but have more recently been proposed for animal research (Würbel 2017 ) where experiments are increasingly scutinized for their scientific rationale and their design and intended analyses.
1.4.1 Construct validity
Construct validity concerns the choice of the experimental system for answering our research question. Is the system even capable of providing a relevant answer to the question?
Studying the mechanisms of a particular disease, for example, might require careful choice of an appropriate animal model that shows a disease phenotype and is amenable to experimental interventions. If the animal model is a proxy for drug development for humans, biological mechanisms must be sufficiently similar between animal and human physiologies.
Another important aspect of the construct is the quantity that we intend to measure (the measurand ), and its relation to the quantity or property we are interested in. For example, we might measure the concentration of the same chemical compound once in a blood sample and once in a highly purified sample, and these constitute two different measurands, whose values might not be comparable. Often, the quantity of interest (e.g., liver function) is not directly measurable (or even quantifiable) and we measure a biomarker instead. For example, pre-clinical and clinical investigations may use concentrations of proteins or counts of specific cell types from blood samples, such as the CD4+ cell count used as a biomarker for immune system function. The problem of measurements and measurands is further discussed for statistics in (Hand 1996 ) and specifcially for biological experiments in (Coxon, Longstaff, and Burns 2019 ) .
1.4.2 Internal validity
The internal validity of an experiment concerns the soundness of the scientific rationale, statistical properties such as precision of estimates, and the measures taken against risk of bias. It refers to the validity of claims within the context of the experiment. Statistical design of experiments plays a prominent role in ensuring internal validity, and we briefly discuss the main ideas here before providing the technical details and an application to our example in the subsequent sections.
Scientific rationale and research question
The scientific rationale of a study is (usually) not immediately a statistical question. Translating a scientific question into a quantitative comparison amenable to statistical analysis is no small task and often requires substantial thought. It is a substantial, if non-statistical, benefit of using experimental design that we are forced to formulate a precise-enough research question and decide on the main analyses required for answering it before we conduct the experiment. For example, the question: is there a difference between placebo and drug? is insufficiently precise for planning a statistical analysis and determine an adequate experimental design. What exactly is the drug treatment? What concentration and how is it administered? How do we make sure that the placebo group is comparable to the drug group in all other aspects? What do we measure and what do we mean by “difference”? A shift in average response, a fold-change, change in response before and after treatment?
There are almost never enough resources to answer all conceivable scientific questions in a statistical analysis. We therefore select a few primary outcome variables whose analysis answers the most important questions and design the experiment to ensure these variables can be estimated and tested appropriately. Other, secondary outcome variables , can still be measured and analyzed, but we are not willing to increase the experiment to ensure that reliable conclusions can be drawn from these variables.
The scientific rationale also enters the choice of a potential control group to which we compare responses. The quote
The deep, fundamental question in statistical analysis is ‘Compared to what?’ (Tufte 1997 )
from Edward Tufte highlights the importance of this choice also for the statistical analyses of an experiment’s results.
Risk of bias
Experimental bias is a systematic difference in response between experimental units in addition to the difference caused by the treatments. The experimental units in the different groups are then not equal in all aspects except the treatment applied to them, and we saw several examples in Section 1.2 .
Minimizing the risk of bias is crucial for internal validity. Experimental design offers several methods for this, such as randomization , the random assignment of treatments to units to randomly distribute other differences between the treatment groups; blinding , the hiding of treatment assignments from the researcher and potential experiment subject to prevent conscious or unconscious biased assignments (e.g., by treating more agile mice with our favourite drug and more docile ones with the competitor’s); sampling , the random selection of units for inclusion in the experiment; and predefining the analysis plan detailing the intended analyses, including how to deal with missing data to counteract criticisms of performing many comparisons and only reporting those with the desired outcome, for example.
Precision and effect size
Another aspect of internal validity is the precision of estimates and the expected effect sizes. Is the experimental setup, in principle, able to detect a difference of relevant magnitude? Experimental design offers several methods for answering this question based on the expected heterogeneity of samples, the measurement error, and other sources of variation: power analysis is a technique for determining the number of samples required to reliably detect a relevant effect size and provide estimates of sufficient precision. More samples yield more precision and more power, but we have to be careful that replication is done at the right level: simply measuring a biological sample multiple times yields more measured values, but is pseudo-replication for analyses. Replication should also ensure that the statistical uncertainties of estimates can be gauged from the data of the experiment itself, and does not require additional untestable assumptions. Finally, the technique of blocking can remove a substantial proportion of the variation and thereby increase power and precision if we find a way to apply it.
1.4.3 External validity
The external validity of an experiment concerns its replicability and the generalizability of inferences. An experiment is replicable if its results can be confirmed by an independent new experiment, preferably by a different lab and researcher. Experimental conditions in the replicate experiment usually differ from the original experiment, which provides evidence that the observed effects are robust to such changes. A much weaker condition on an experiment is reproducibility , the property that an independent researcher draws equivalent conclusions based on the data from this particular experiment, using the same analyses techniques. Reproducibility requires publishing the raw data, details on the experimental protocol, and a detailed description of the statistical analyses, preferably with accompagnying source code.
Reporting the results of an experiment so that others can preproduce and replicate them is no simple task, and requires sufficient information about the experiment and its analysis. Many scientific journals subscribe to reporting guidelines that are also helpful for planning an experiment. Two such guidelines are the the ARRIVE guidelines for animal research (Kilkenny et al. 2010 ) and the CONSORT guidelines for clinical trials (Moher et al. 2010 ) . Guidelines describing the minimal information required for reproducing experimental results have been developed for many types of experimental techniques, including microarrays (MIAME), RNA sequencing (MINSEQE), metabolomics (MSI) and proteomics (MIAPE) experiments, and the FAIRSHARE initiative provides a more comprehensive collection (Sansone et al. 2019 ) .
A main threat to replicability and generalizability are too tightly controlled experimental conditions, when inferences only hold for a specific lab under the very specific conditions of the original experiment. Introducing systematic heterogeneity and using multi-center studies effectively broadens the experimental conditions and therefore the inferences for which internal validity is available.
For systematic heterogeneity , experimental conditions other than treatments are systematically altered and treatment differences estimated for each condition. For example, we might split the experimental material into several batches and use a different day of analysis, sample preparation, batch of buffer, measurement device, and lab technician for each the batches. A more general inference is then possible if the effect size, effect direction, and precision are comparable between the batches, indicating that the treatment differences are stable over the different conditions.
In multi-center experiments , the same experiment is conducted in several different labs and the results compared and merged. Already using a second laboratory increases replicability of animal studies substantially (Karp 2018 ) and differences between labs can be used for standardizing the treatment effects (Kafkafi et al. 2017 ) . Multi-center approaches are very common in clinical trials and often necessary to reach the required number of patient enrollments.
Generalizability of randomized controlled trials in medicine and animal studies often suffers from overly restrictive eligibility criteria. In clinical trials, patients are often included or excluded based on co-medications and co-morbidities, and the resulting sample of eligible patients might no longer be representative of the patient population. For example, (Travers et al. 2007 ) used the eligibility criteria of 17 random controlled trials of asthma treatments and found that out of 749 patients, only a median of 6% (45 patients) would be eligible for an asthma-related randomized controlled trial. This puts a question mark on the relevance of the trials’ findings for asthma patients in general.
1.5 Reducing the risk of bias
1.5.1 randomization of treatment allocation.
If systematic differences other than the treatment exist between our treatment groups, then the effect of the treatment is confounded with these other differences and our estimates of treatment effects might be biased.
We remove such unwanted sysstematic differences from our treatment comparisons by randomizing the allocation of treatments to experimental units. In a completely randomized design , each experimental unit has the same chance of being subjected to any of the treatments, and any differences between the experimental units other than the treatments are distributed over the treatment groups. Importantly, randomization is the only method that also protects our experiment against unknown sources of bias: we do not need to know all or even any of the potential differences and yet their impact is eliminated from the treatment comparisons by random treatment allocation.
Randomization has two effects: (i) differences unrelated to treatment become part of the residual variance rendering the treatment groups more similar; and (ii) the systematic differences are thereby eliminated as sources of bias from the treatment comparison. In short,
Randomization transforms systematic variation into random variation.
In our example, a proper randomization would select 10 out of our 20 mice fully at random, such that the probability of any mice being picked is 1/20. These ten mice are then assigned to kit A, and the remaining mice to kit B. This allocation is entirely independent of the treatments and of any properties of the mice.
To ensure completely random treatment allocation, some kind of random process needs to be employed. This can be as simple as shuffling a pack of 10 red and 10 black cards or we might use a software-based random number generator. Randomization is slightly more difficult if the number of experimental units is not known at the start of the experiment, such as when patients are recruited for an ongoing clinical trial (sometimes called rolling recruitment ), and we want to have reasonable balance between the treatment groups at each stage of the trial.
Seemingly random assignments “by hand” are usually no less complicated than fully random assignments, but are always inferior. If surprising results ensue from the experiment, such assignments are subject to unanswerable criticism and suspicion of unwanted bias. Even worse are systematic allocations; they can only remove bias from known causes, and immediately raise red flags under the slightest scrutiny.
The problem of undesired assignments
Even with a fully random treatment allocation procedure, we might end up with an undesirable allocation. For our example, the treatment group of kit A might—just by chance—contain mice that are bigger or more active than those in the other treatment group. Statistical orthodoxy and some authors recommend using the design nevertheless, because only full randomization guarantees valid estimates of residual variance and unbiased estimates of effects. This argument, however, concerns the long-run properties of the procedure and seems of little help in this specific situation. Why should we care if the randomization yields correct estimates under replication of the experiment, if the particular experiment is jeopardized?
Another solution is to create a list of all possible allocations that we would accept and randomly choose one of these allocations for our experiment. The analysis should then reflect this restriction in the possible randomizations, which often renders this approach difficult to implement.
The most pragmatic method is to reject undesirable designs and compute a new randomization (Cox 1958 ) . Undesirable allocations are unlikely to arise for large sample sizes, and we might accept a small bias in estimation for small sample sizes, when uncertainty in the estimated treatment effect is already high. In this approach, whenever we reject a particular outcome, we must also be willing to reject the outcome if we permute the treatment level labels. If we reject eight big and two small mice for kit A, then we must also reject a two big and eight small mice. We must also be transparent and report a rejected allocation, so that a critic may weigh the risk in bias due to rejection against the risk of bias due to the rejected allocation.
1.5.2 Blinding
Bias in treatment comparisons is also introduced if treatment allocation is random, but responses cannot be measured entirely objective, or if knowledge of the assigned treatment might affect the response. In clinical trials, for example, patients might (objectively) react differently when they know to be on a placebo treatment, an effect known as cognitive bias . In animal experiments, caretakers might report more abnormal behavior for animals on a more severe treatment. Cognitive bias can be eliminated by concealing the treatment allocation from participants of a clinical trial or technicians, a technique called single-blinding .
If response measures are partially based on professional judgement (e.g., a pain score), patient or physician might unconsciously report lower scores for a placebo treatment, a phenomenon known as observer bias . Its removal requires double blinding , where treatment allocations are additionally concealed from the experimentalist.
Blinding requires randomized treatment allocation to begin with and substantial effort might be needed to implement it. Drug companies, for example, have to go to great lengths to ensure that a placebo looks, tastes, and feels similar enough to the actual drug so that patients cannot unblind their treatment. Additionally, blinding is often done by coding the treatment conditions and samples, and statements about effect sizes and statistical significance are made before the code is revealed.
In clinical trials, double-blinding creates a conflict of interest. The attending doctors do not know which patient received which treatment, and thus accumulation of side-effects cannot be linked to any treatment. For this reason, clinical trials always have a data monitoring committee, constituted of doctors, pharmacologists, and statisticians. At predefined intervals, the data from the trials is used for an intermediate analysis of efficacy and safety by members of the committee. If severe problems are detected, the committee might recommend altering or aborting the trial. The same might happen if one treatment already shows overwhelming evidence of superiority, such that it becomes unethical to withhold better treatment from the other treatment groups.
1.5.3 Analysis plan, and registration
An often overlooked but nevertheless severe source of bias is what has been termed ‘researcher degrees of freedom’ or ‘a garden of forking paths’ in the data analysis. For any set of data, there are many different options for its analysis: some results might be considered outliers and discarded, assumptions are made on error distributions and appropriate test statistics, different covariates might be included into a regression model. Often, multiple hypotheses are investigated and tested, and analyses are done separately on various (overlapping) subgroups. Hypotheses formed after looking at the data require additional care in their interpretation; almost never will \(p\) -values for these ad hoc or post hoc hypotheses be statistically justifiable. Only reporting those sub-analyses that gave ‘interesting’ findings invariably leads to biased conclusions and is called cherry-picking or \(p\) -hacking (or much less flattering names). Many different measured response variables invite fishing expeditions , where patterns in the data are sought without an underlying hypothesis.
The interpretation of a statistical analysis is always part of a larger scientific argument and we should consider the necessary computations in relation to building our scientific argument about the interpretation of the data. In addition to the statistical calculations, this interpretation requires substantial subject-matter knowledge and includes (many) non-statistical arguments. Two quotes highlight highlight that experiment and analysis are a means to an end and not the end in itself.
There is a boundary in data interpretation beyond which formulas and quantitative decision procedures do not go, where judgment and style enter. (Abelson 1995 )
Often, perfectly reasonable people come to perfectly reasonable decisions or conclusions based on nonstatistical evidence. Statistical analysis is a tool with which we support reasoning. It is not a goal in itself. (Bailar III 1981 )
The deliberate use of statistical analyses and their interpretation for supporting a larger argument was called statistics as principled argument (Abelson 1995 ) . Employing useless statistical analysis without reference to the actual scientific question is surrogate science (Gigerenzer and Marewski 2014 ) and adaptive thinking is integral to meaningful statistical analysis (Gigerenzer 2002 ) .
There is often a grey area between exploiting researcher degrees of freedom to arrive at a desired conclusion, and creative yet informed analyses of data. One way to navigate this area is to distinguish between exploratory studies and confirmatory studies . The former have no clear stated scientific question, but are used to generate interesting hypotheses by identifying potential associations or effects that are then further investigated. Conclusions from these studies are very tentative and must be reported honestly. In contrast, standards are much higher for conformatory studies, which investigate a clearly defined scientific question. Here, analysis plans and pre-registration of an experiment are now the accepted means for demonstrating lack of bias due to researcher degrees of freedom.
Analysis plans
The analysis plan is written before conducting the experiment and details the measurands and estimands, the hypotheses to be tested together with a power and sample size calculation, a discussion of relevant effect sizes, detection and handling of outliers and missing data, as well as steps for data normalization such as transformations and baseline corrections. If a regression model is required, its factors and covariates are outlined. Particularly in biology, measurements below the limit of quantification require special attention in the analysis plan.
In the context of clinical trials, the problem of estimands has become a recent focus of attention. The estimand is the target of a statistical estimation procedure, for example the true average difference in enzyme levels between the two preparation kits. A main problem in many studies are post-randomization events that can change the estimand, even if the estimation procedure remains the same. For example, if kit B fails to produce usable samples for measurement in five out of ten cases because the enzyme level was too low, while kit A could handle these enzyme levels perfectly fine, then this might severely exaggerate the observed difference between the two kits. Similar problems arise in drug trials, when some patients stop taking one of the drugs due to side-effects or other complications, and data is then available for only those patients without side-effects.
Pre-registration
Pre-registration of experiments is an even more severe measure used in conjunction with an analysis plan and is becoming standard in clinical trials. Here, information about the trial, including the analysis plan, procedure to recruit patients, and stopping criteria, are registered at a dedicated website, such as ClinicalTrials.gov or AllTrials.net , and stored in a database. Publications based on the trial then refer to this registration, such that reviewers and readers can compare what the researchers intended to do and what they actually did. A similar portal for pre-clinical and translational research is PreClinicalTrials.eu .
Abelson, R P. 1995. Statistics as principled argument . Lawrence Erlbaum Associates Inc.
Bailar III, J. C. 1981. “Bailar’s laws of data analysis.” Clinical Pharmacology & Therapeutics 20 (1): 113–19.
Cox, D R. 1958. Planning of Experiments . Wiley-Blackwell.
Coxon, Carmen H., Colin Longstaff, and Chris Burns. 2019. “Applying the science of measurement to biology: Why bother?” PLOS Biology 17 (6): e3000338. https://doi.org/10.1371/journal.pbio.3000338 .
Fisher, R. 1938. “Presidential Address to the First Indian Statistical Congress.” Sankhya: The Indian Journal of Statistics 4: 14–17.
Gigerenzer, G. 2002. Adaptive Thinking: Rationality in the Real World . Oxford Univ Press. https://doi.org/10.1093/acprof:oso/9780195153729.003.0013 .
Gigerenzer, G, and J N Marewski. 2014. “Surrogate Science: The Idol of a Universal Method for Scientific Inference.” Journal of Management 41 (2). {SAGE} Publications: 421–40. https://doi.org/10.1177/0149206314547522 .
Hand, D J. 1996. “Statistics and the theory of measurement.” Journal of the Royal Statistical Society A 159 (3): 445–92. http://www.jstor.org/stable/2983326 .
Kafkafi, Neri, Ilan Golani, Iman Jaljuli, Hugh Morgan, Tal Sarig, Hanno Würbel, Shay Yaacoby, and Yoav Benjamini. 2017. “Addressing reproducibility in single-laboratory phenotyping experiments.” Nature Methods 14 (5): 462–64. https://doi.org/10.1038/nmeth.4259 .
Karp, Natasha A. 2018. “Reproducible preclinical research—Is embracing variability the answer?” PLOS Biology 16 (3): e2005413. https://doi.org/10.1371/journal.pbio.2005413 .
Kilkenny, Carol, William J Browne, Innes C Cuthill, Michael Emerson, and Douglas G Altman. 2010. “Improving Bioscience Research Reporting: The ARRIVE Guidelines for Reporting Animal Research.” PLoS Biology 8 (6): e1000412. https://doi.org/10.1371/journal.pbio.1000412 .
Moher, David, Sally Hopewell, Kenneth F Schulz, Victor Montori, Peter C Gøtzsche, P J Devereaux, Diana Elbourne, Matthias Egger, and Douglas G Altman. 2010. “CONSORT 2010 Explanation and Elaboration: updated guidelines for reporting parallel group randomised trials.” BMJ 340. BMJ Publishing Group Ltd. https://doi.org/10.1136/bmj.c869 .
Sansone, Susanna-Assunta, Peter McQuilton, Philippe Rocca-Serra, Alejandra Gonzalez-Beltran, Massimiliano Izzo, Allyson L. Lister, and Milo Thurston. 2019. “FAIRsharing as a community approach to standards, repositories and policies.” Nature Biotechnology 37 (4): 358–67. https://doi.org/10.1038/s41587-019-0080-8 .
Travers, Justin, Suzanne Marsh, Mathew Williams, Mark Weatherall, Brent Caldwell, Philippa Shirtcliffe, Sarah Aldington, and Richard Beasley. 2007. “External validity of randomised controlled trials in asthma: To whom do the results of the trials apply?” Thorax 62 (3): 219–33. https://doi.org/10.1136/thx.2006.066837 .
Tufte, E. 1997. Visual Explanations: Images and Quantities, Evidence and Narrative . 1st ed. Graphics Press.
Würbel, Hanno. 2017. “More than 3Rs: The importance of scientific validity for harm-benefit analysis of animal research.” Lab Animal 46 (4). Nature Publishing Group: 164–66. https://doi.org/10.1038/laban.1220 .
1.4 Experimental Design and Ethics
Does aspirin reduce the risk of heart attacks? Is one brand of fertilizer more effective at growing roses than another? Is fatigue as dangerous to a driver as speeding? Questions like these are answered using randomized experiments. In this module, you will learn important aspects of experimental design. Proper study design ensures the production of reliable, accurate data.
The purpose of an experiment is to investigate the relationship between two variables. In an experiment, there is the explanatory variable which affects the response variable . In a randomized experiment, the researcher manipulates the explanatory variable and then observes the response variable. Each value of the explanatory variable used in an experiment is called a treatment .
You want to investigate the effectiveness of vitamin E in preventing disease. You recruit a group of subjects and ask them if they regularly take vitamin E. You notice that the subjects who take vitamin E exhibit better health on average than those who do not. Does this prove that vitamin E is effective in disease prevention? It does not. There are many differences between the two groups compared in addition to vitamin E consumption. People who take vitamin E regularly often take other steps to improve their health: exercise, diet, other vitamin supplements. Any one of these factors could be influencing health. As described, this study does not prove that vitamin E is the key to disease prevention.
Additional variables that can cloud a study are called lurking variables . In order to prove that the explanatory variable is causing a change in the response variable, it is necessary to isolate the explanatory variable. The researcher must design her experiment in such a way that there is only one difference between groups being compared: the planned treatments. This is accomplished by the random assignment of experimental units to treatment groups. When subjects are assigned treatments randomly, all of the potential lurking variables are spread equally among the groups. At this point the only difference between groups is the one imposed by the researcher. Different outcomes measured in the response variable, therefore, must be a direct result of the different treatments. In this way, an experiment can prove a cause-and-effect connection between the explanatory and response variables.
Confounding occurs when the effects of multiple factors on a response cannot be separated, for instance, if a student guesses on the even-numbered questions on an exam and sits in a favorite spot on exam day. Why does the student get a high test scores on the exam? It could be the increased study time or sitting in the favorite spot or both. Confounding makes it difficult to draw valid conclusions about the effect of each factor on the outcome. The way around this is to test several outcomes with one method (treatment). This way, we know which treatment really works.
The power of suggestion can have an important influence on the outcome of an experiment. Studies have shown that the expectation of the study participant can be as important as the actual medication. In one study of performance-enhancing substances, researchers noted the following:
Results showed that believing one had taken the substance resulted in [ performance ] times almost as fast as those associated with consuming the substance itself. In contrast, taking the substance without knowledge yielded no significant performance increment. 1
When participation in a study prompts a physical response from a participant, it is difficult to isolate the effects of the explanatory variable. To counter the power of suggestion, researchers set aside one treatment group as a control group . This group is given a placebo treatment, a treatment that cannot influence the response variable. The control group helps researchers balance the effects of being in an experiment with the effects of the active treatments. Of course, if you are participating in a study and you know that you are receiving a pill that contains no actual medication, then the power of suggestion is no longer a factor. Blinding in a randomized experiment designed to reduce bias by hiding information. When a person involved in a research study is blinded, he does not know who is receiving the active treatment(s) and who is receiving the placebo treatment. A double-blind experiment is one in which both the subjects and the researchers involved with the subjects are blinded.
Sometimes, it is neither possible nor ethical for researchers to conduct experimental studies. For example, if you want to investigate whether malnutrition affects elementary school performance in children, it would not be appropriate to assign an experimental group to be malnourished. In these cases, observational studies or surveys may be used. In an observational study, the researcher does not directly manipulate the independent variable. Instead, he or she takes recordings and measurements of naturally occurring phenomena. By sorting these data into control and experimental conditions, the relationship between the dependent and independent variables can be drawn. In a survey, a researcher’s measurements consist of questionnaires that are answered by the research participants.
Example 1.20
Researchers want to investigate whether taking aspirin regularly reduces the risk of a heart attack. 400 men between the ages of 50 and 84 are recruited as participants. The men are divided randomly into two groups: one group will take aspirin, and the other group will take a placebo. Each man takes one pill each day for three years, but he does not know whether he is taking aspirin or the placebo. At the end of the study, researchers count the number of men in each group who have had heart attacks.
Identify the following values for this study: population, sample, experimental units, explanatory variable, response variable, treatments.
The population is men aged 50 to 84. The sample is the 400 men who participated. The experimental units are the individual men in the study. The explanatory variable is oral medication. The treatments are aspirin and a placebo. The response variable is whether a subject had a heart attack.
Example 1.21
The Smell & Taste Treatment and Research Foundation conducted a study to investigate whether smell can affect learning. Subjects completed mazes multiple times while wearing masks. They completed the pencil and paper mazes three times wearing floral-scented masks, and three times with unscented masks. Participants were assigned at random to wear the floral mask during the first three trials or during the last three trials. For each trial, researchers recorded the time it took to complete the maze and the subject’s impression of the mask’s scent: positive, negative, or neutral.
- Describe the explanatory and response variables in this study.
- What are the treatments?
- Identify any lurking variables that could interfere with this study.
- Is it possible to use blinding in this study?
- The explanatory variable is scent, and the response variable is the time it takes to complete the maze.
- There are two treatments: a floral-scented mask and an unscented mask.
- All subjects experienced both treatments. The order of treatments was randomly assigned so there were no differences between the treatment groups. Random assignment eliminates the problem of lurking variables.
- Subjects will clearly know whether they can smell flowers or not, so subjects cannot be blinded in this study. Researchers timing the mazes can be blinded, though. The researcher who is observing a subject will not know which mask is being worn.
Example 1.22
A researcher wants to study the effects of birth order on personality. Explain why this study could not be conducted as a randomized experiment. What is the main problem in a study that cannot be designed as a randomized experiment?
The explanatory variable is birth order. You cannot randomly assign a person’s birth order. Random assignment eliminates the impact of lurking variables. When you cannot assign subjects to treatment groups at random, there will be differences between the groups other than the explanatory variable.
Try It 1.22
You are concerned about the effects of texting on driving performance. Design a study to test the response time of drivers while texting and while driving only. How many seconds does it take for a driver to respond when a leading car hits the brakes?
- Describe the explanatory and response variables in the study.
- What should you consider when selecting participants?
- Your research partner wants to divide participants randomly into two groups: one to drive without distraction and one to text and drive simultaneously. Is this a good idea? Why or why not?
- How can blinding be used in this study?
The widespread misuse and misrepresentation of statistical information often gives the field a bad name. Some say that “numbers don’t lie,” but the people who use numbers to support their claims often do.
A recent investigation of famous social psychologist, Diederik Stapel, has led to the retraction of his articles from some of the world’s top journals including, Journal of Experimental Social Psychology, Social Psychology, Basic and Applied Social Psychology, British Journal of Social Psychology, and the magazine Science . Diederik Stapel is a former professor at Tilburg University in the Netherlands. Over the past two years, an extensive investigation involving three universities where Stapel has worked concluded that the psychologist is guilty of fraud on a colossal scale. Falsified data taints over 55 papers he authored and 10 Ph.D. dissertations that he supervised.
Stapel did not deny that his deceit was driven by ambition. But it was more complicated than that, he told me. He insisted that he loved social psychology but had been frustrated by the messiness of experimental data, which rarely led to clear conclusions. His lifelong obsession with elegance and order, he said, led him to concoct results that journals found attractive. “It was a quest for aesthetics, for beauty—instead of the truth,” he said. He described his behavior as an addiction that drove him to carry out acts of increasingly daring fraud . 2
The committee investigating Stapel concluded that he is guilty of several practices including
- creating datasets, which largely confirmed the prior expectations,
- altering data in existing datasets,
- changing measuring instruments without reporting the change, and
- misrepresenting the number of experimental subjects.
Clearly, it is never acceptable to falsify data the way this researcher did. Sometimes, however, violations of ethics are not as easy to spot.
Researchers have a responsibility to verify that proper methods are being followed. The report describing the investigation of Stapel’s fraud states that, “statistical flaws frequently revealed a lack of familiarity with elementary statistics.” 3 Many of Stapel’s co-authors should have spotted irregularities in his data. Unfortunately, they did not know very much about statistical analysis, and they simply trusted that he was collecting and reporting data properly.
Many types of statistical fraud are difficult to spot. Some researchers simply stop collecting data once they have just enough to prove what they had hoped to prove. They don’t want to take the chance that a more extensive study would complicate their lives by producing data contradicting their hypothesis.
Professional organizations, like the American Statistical Association, clearly define expectations for researchers. There are even laws in the federal code about the use of research data.
When a statistical study uses human participants, as in medical studies, both ethics and the law dictate that researchers should be mindful of the safety of their research subjects. The U.S. Department of Health and Human Services oversees federal regulations of research studies with the aim of protecting participants. When a university or other research institution engages in research, it must ensure the safety of all human subjects. For this reason, research institutions establish oversight committees known as Institutional Review Boards (IRB) . All planned studies must be approved in advance by the IRB. Key protections that are mandated by law include the following:
- Risks to participants must be minimized and reasonable with respect to projected benefits.
- Participants must give informed consent . This means that the risks of participation must be clearly explained to the subjects of the study. Subjects must consent in writing, and researchers are required to keep documentation of their consent.
- Data collected from individuals must be guarded carefully to protect their privacy.
These ideas may seem fundamental, but they can be very difficult to verify in practice. Is removing a participant’s name from the data record sufficient to protect privacy? Perhaps the person’s identity could be discovered from the data that remains. What happens if the study does not proceed as planned and risks arise that were not anticipated? When is informed consent really necessary? Suppose your doctor wants a blood sample to check your cholesterol level. Once the sample has been tested, you expect the lab to dispose of the remaining blood. At that point the blood becomes biological waste. Does a researcher have the right to take it for use in a study?
It is important that students of statistics take time to consider the ethical questions that arise in statistical studies. How prevalent is fraud in statistical studies? You might be surprised—and disappointed. There is a website dedicated to cataloging retractions of study articles that have been proven fraudulent. A quick glance will show that the misuse of statistics is a bigger problem than most people realize.
Vigilance against fraud requires knowledge. Learning the basic theory of statistics will empower you to analyze statistical studies critically.
Example 1.23
Describe the unethical behavior in each example and describe how it could impact the reliability of the resulting data. Explain how the problem should be corrected.
A researcher is collecting data in a community.
- She selects a block where she is comfortable walking because she knows many of the people living on the street.
- No one seems to be home at four houses on her route. She does not record the addresses and does not return at a later time to try to find residents at home.
- She skips four houses on her route because she is running late for an appointment. When she gets home, she fills in the forms by selecting random answers from other residents in the neighborhood.
- By selecting a convenient sample, the researcher is intentionally selecting a sample that could be biased. Claiming that this sample represents the community is misleading. The researcher needs to select areas in the community at random.
- Intentionally omitting relevant data will create bias in the sample. Suppose the researcher is gathering information about jobs and child care. By ignoring people who are not home, she may be missing data from working families that are relevant to her study. She needs to make every effort to interview all members of the target sample.
- It is never acceptable to fake data. Even though the responses she uses are real responses provided by other participants, the duplication is fraudulent and can create bias in the data. She needs to work diligently to interview everyone on her route.
Try It 1.23
Describe the unethical behavior, if any, in each example and describe how it could impact the reliability of the resulting data. Explain how the problem should be corrected.
A study is commissioned to determine the favorite brand of fruit juice among teens in California.
- The survey is commissioned by the seller of a popular brand of apple juice.
- There are only two types of juice included in the study: apple juice and cranberry juice.
- Researchers allow participants to see the brand of juice as samples are poured for a taste test.
- Twenty-five percent of participants prefer Brand X, 33 percent prefer Brand Y and 42 percent have no preference between the two brands. Brand X references the study in a commercial saying “Most teens like Brand X as much as or more than Brand Y.”
- 1 McClung, M. and Collins, D. (2007 June). "Because I know it will!" Placebo effects of an ergogenic aid on athletic performance. Journal of Sport & Exercise Psychology, 29(3), 382-94 .
- 2 Bhattacharjee, Y. (2013, April 26). The mind of a con man. The New York Times . Retrieved from http://www.nytimes.com/2013/04/28/magazine/diederik-stapels-audacious-academic-fraud.html?_r=3&src=dayp&.
- 3 Tillburg University. (2012, Nov. 28). Flawed science: the fraudulent research practices of social psychologist Diederik Stapel. Retrieved from https://www.tilburguniversity.edu/upload/3ff904d7-547b-40ae-85fe-bea38e05a34a_Final%20report%20Flawed%20Science.pdf.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute Texas Education Agency (TEA). The original material is available at: https://www.texasgateway.org/book/tea-statistics . Changes were made to the original material, including updates to art, structure, and other content updates.
Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Authors: Barbara Illowsky, Susan Dean
- Publisher/website: OpenStax
- Book title: Statistics
- Publication date: Mar 27, 2020
- Location: Houston, Texas
- Book URL: https://openstax.org/books/statistics/pages/1-introduction
- Section URL: https://openstax.org/books/statistics/pages/1-4-experimental-design-and-ethics
© Apr 16, 2024 Texas Education Agency (TEA). The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
1.1.5 - principles of experimental design.
The following principles of experimental design have to be followed to enable a researcher to conclude that differences in the results of an experiment, not reasonably attributable to chance, are likely caused by the treatments.
The benefits to randomization are:
- If a random assignment of treatment is done then significant results can be concluded as causal or cause and effect conclusions. That is, that the treatment caused the result. This treatment can be referred to as the explanatory variable and the result as the response variable.
- If random selection is done where the subjects are randomly selected from some population, then the results can be extended to that population. The random assignment is required for an experiment. When both random assignment and selection are part of the study then we have a completely randomized experiment. Without random assignment (i.e.an observational study) then the treatment can only be referred to as being related to the outcome.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 6: Experimental Research
Experimental Design
Learning Objectives
- Explain the difference between between-subjects and within-subjects experiments, list some of the pros and cons of each approach, and decide which approach to use to answer a particular research question.
- Define random assignment, distinguish it from random sampling, explain its purpose in experimental research, and use some simple strategies to implement it.
- Define what a control condition is, explain its purpose in research on treatment effectiveness, and describe some alternative types of control conditions.
- Define several types of carryover effect, give examples of each, and explain how counterbalancing helps to deal with them.
In this section, we look at some different ways to design an experiment. The primary distinction we will make is between approaches in which each participant experiences one level of the independent variable and approaches in which each participant experiences all levels of the independent variable. The former are called between-subjects experiments and the latter are called within-subjects experiments.
Between-Subjects Experiments
In a between-subjects experiment , each participant is tested in only one condition. For example, a researcher with a sample of 100 university students might assign half of them to write about a traumatic event and the other half write about a neutral event. Or a researcher with a sample of 60 people with severe agoraphobia (fear of open spaces) might assign 20 of them to receive each of three different treatments for that disorder. It is essential in a between-subjects experiment that the researcher assign participants to conditions so that the different groups are, on average, highly similar to each other. Those in a trauma condition and a neutral condition, for example, should include a similar proportion of men and women, and they should have similar average intelligence quotients (IQs), similar average levels of motivation, similar average numbers of health problems, and so on. This matching is a matter of controlling these extraneous participant variables across conditions so that they do not become confounding variables.
Random Assignment
The primary way that researchers accomplish this kind of control of extraneous variables across conditions is called random assignment , which means using a random process to decide which participants are tested in which conditions. Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and it is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too.
In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition (e.g., a 50% chance of being assigned to each of two conditions). The second is that each participant is assigned to a condition independently of other participants. Thus one way to assign participants to two conditions would be to flip a coin for each one. If the coin lands heads, the participant is assigned to Condition A, and if it lands tails, the participant is assigned to Condition B. For three conditions, one could use a computer to generate a random integer from 1 to 3 for each participant. If the integer is 1, the participant is assigned to Condition A; if it is 2, the participant is assigned to Condition B; and if it is 3, the participant is assigned to Condition C. In practice, a full sequence of conditions—one for each participant expected to be in the experiment—is usually created ahead of time, and each new participant is assigned to the next condition in the sequence as he or she is tested. When the procedure is computerized, the computer program often handles the random assignment.
One problem with coin flipping and other strict procedures for random assignment is that they are likely to result in unequal sample sizes in the different conditions. Unequal sample sizes are generally not a serious problem, and you should never throw away data you have already collected to achieve equal sample sizes. However, for a fixed number of participants, it is statistically most efficient to divide them into equal-sized groups. It is standard practice, therefore, to use a kind of modified random assignment that keeps the number of participants in each group as similar as possible. One approach is block randomization . In block randomization, all the conditions occur once in the sequence before any of them is repeated. Then they all occur again before any of them is repeated again. Within each of these “blocks,” the conditions occur in a random order. Again, the sequence of conditions is usually generated before any participants are tested, and each new participant is assigned to the next condition in the sequence. Table 6.2 shows such a sequence for assigning nine participants to three conditions. The Research Randomizer website will generate block randomization sequences for any number of participants and conditions. Again, when the procedure is computerized, the computer program often handles the block randomization.
| Participant | Condition |
|---|---|
| 1 | A |
| 2 | C |
| 3 | B |
| 4 | B |
| 5 | C |
| 6 | A |
| 7 | C |
| 8 | B |
| 9 | A |
Random assignment is not guaranteed to control all extraneous variables across conditions. It is always possible that just by chance, the participants in one condition might turn out to be substantially older, less tired, more motivated, or less depressed on average than the participants in another condition. However, there are some reasons that this possibility is not a major concern. One is that random assignment works better than one might expect, especially for large samples. Another is that the inferential statistics that researchers use to decide whether a difference between groups reflects a difference in the population takes the “fallibility” of random assignment into account. Yet another reason is that even if random assignment does result in a confounding variable and therefore produces misleading results, this confound is likely to be detected when the experiment is replicated. The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design.
Treatment and Control Conditions
Between-subjects experiments are often used to determine whether a treatment works. In psychological research, a treatment is any intervention meant to change people’s behaviour for the better. This intervention includes psychotherapies and medical treatments for psychological disorders but also interventions designed to improve learning, promote conservation, reduce prejudice, and so on. To determine whether a treatment works, participants are randomly assigned to either a treatment condition , in which they receive the treatment, or a control condition , in which they do not receive the treatment. If participants in the treatment condition end up better off than participants in the control condition—for example, they are less depressed, learn faster, conserve more, express less prejudice—then the researcher can conclude that the treatment works. In research on the effectiveness of psychotherapies and medical treatments, this type of experiment is often called a randomized clinical trial .
There are different types of control conditions. In a no-treatment control condition , participants receive no treatment whatsoever. One problem with this approach, however, is the existence of placebo effects. A placebo is a simulated treatment that lacks any active ingredient or element that should make it effective, and a placebo effect is a positive effect of such a treatment. Many folk remedies that seem to work—such as eating chicken soup for a cold or placing soap under the bedsheets to stop nighttime leg cramps—are probably nothing more than placebos. Although placebo effects are not well understood, they are probably driven primarily by people’s expectations that they will improve. Having the expectation to improve can result in reduced stress, anxiety, and depression, which can alter perceptions and even improve immune system functioning (Price, Finniss, & Benedetti, 2008) [1] .
Placebo effects are interesting in their own right (see Note “The Powerful Placebo” ), but they also pose a serious problem for researchers who want to determine whether a treatment works. Figure 6.2 shows some hypothetical results in which participants in a treatment condition improved more on average than participants in a no-treatment control condition. If these conditions (the two leftmost bars in Figure 6.2 ) were the only conditions in this experiment, however, one could not conclude that the treatment worked. It could be instead that participants in the treatment group improved more because they expected to improve, while those in the no-treatment control condition did not.

Fortunately, there are several solutions to this problem. One is to include a placebo control condition , in which participants receive a placebo that looks much like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness. When participants in a treatment condition take a pill, for example, then those in a placebo control condition would take an identical-looking pill that lacks the active ingredient in the treatment (a “sugar pill”). In research on psychotherapy effectiveness, the placebo might involve going to a psychotherapist and talking in an unstructured way about one’s problems. The idea is that if participants in both the treatment and the placebo control groups expect to improve, then any improvement in the treatment group over and above that in the placebo control group must have been caused by the treatment and not by participants’ expectations. This difference is what is shown by a comparison of the two outer bars in Figure 6.2 .
Of course, the principle of informed consent requires that participants be told that they will be assigned to either a treatment or a placebo control condition—even though they cannot be told which until the experiment ends. In many cases the participants who had been in the control condition are then offered an opportunity to have the real treatment. An alternative approach is to use a waitlist control condition , in which participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it. This disclosure allows researchers to compare participants who have received the treatment with participants who are not currently receiving it but who still expect to improve (eventually). A final solution to the problem of placebo effects is to leave out the control condition completely and compare any new treatment with the best available alternative treatment. For example, a new treatment for simple phobia could be compared with standard exposure therapy. Because participants in both conditions receive a treatment, their expectations about improvement should be similar. This approach also makes sense because once there is an effective treatment, the interesting question about a new treatment is not simply “Does it work?” but “Does it work better than what is already available?
The Powerful Placebo
Many people are not surprised that placebos can have a positive effect on disorders that seem fundamentally psychological, including depression, anxiety, and insomnia. However, placebos can also have a positive effect on disorders that most people think of as fundamentally physiological. These include asthma, ulcers, and warts (Shapiro & Shapiro, 1999) [2] . There is even evidence that placebo surgery—also called “sham surgery”—can be as effective as actual surgery.
Medical researcher J. Bruce Moseley and his colleagues conducted a study on the effectiveness of two arthroscopic surgery procedures for osteoarthritis of the knee (Moseley et al., 2002) [3] . The control participants in this study were prepped for surgery, received a tranquilizer, and even received three small incisions in their knees. But they did not receive the actual arthroscopic surgical procedure. The surprising result was that all participants improved in terms of both knee pain and function, and the sham surgery group improved just as much as the treatment groups. According to the researchers, “This study provides strong evidence that arthroscopic lavage with or without débridement [the surgical procedures used] is not better than and appears to be equivalent to a placebo procedure in improving knee pain and self-reported function” (p. 85).
Within-Subjects Experiments
In a within-subjects experiment , each participant is tested under all conditions. Consider an experiment on the effect of a defendant’s physical attractiveness on judgments of his guilt. Again, in a between-subjects experiment, one group of participants would be shown an attractive defendant and asked to judge his guilt, and another group of participants would be shown an unattractive defendant and asked to judge his guilt. In a within-subjects experiment, however, the same group of participants would judge the guilt of both an attractive and an unattractive defendant.
The primary advantage of this approach is that it provides maximum control of extraneous participant variables. Participants in all conditions have the same mean IQ, same socioeconomic status, same number of siblings, and so on—because they are the very same people. Within-subjects experiments also make it possible to use statistical procedures that remove the effect of these extraneous participant variables on the dependent variable and therefore make the data less “noisy” and the effect of the independent variable easier to detect. We will look more closely at this idea later in the book. However, not all experiments can use a within-subjects design nor would it be desirable to.
Carryover Effects and Counterbalancing
The primary disad vantage of within-subjects designs is that they can result in carryover effects. A carryover effect is an effect of being tested in one condition on participants’ behaviour in later conditions. One type of carryover effect is a practice effect , where participants perform a task better in later conditions because they have had a chance to practice it. Another type is a fatigue effect , where participants perform a task worse in later conditions because they become tired or bored. Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions. This type of effect is called a context effect . For example, an average-looking defendant might be judged more harshly when participants have just judged an attractive defendant than when they have just judged an unattractive defendant. Within-subjects experiments also make it easier for participants to guess the hypothesis. For example, a participant who is asked to judge the guilt of an attractive defendant and then is asked to judge the guilt of an unattractive defendant is likely to guess that the hypothesis is that defendant attractiveness affects judgments of guilt. This knowledge could lead the participant to judge the unattractive defendant more harshly because he thinks this is what he is expected to do. Or it could make participants judge the two defendants similarly in an effort to be “fair.”
Carryover effects can be interesting in their own right. (Does the attractiveness of one person depend on the attractiveness of other people that we have seen recently?) But when they are not the focus of the research, carryover effects can be problematic. Imagine, for example, that participants judge the guilt of an attractive defendant and then judge the guilt of an unattractive defendant. If they judge the unattractive defendant more harshly, this might be because of his unattractiveness. But it could be instead that they judge him more harshly because they are becoming bored or tired. In other words, the order of the conditions is a confounding variable. The attractive condition is always the first condition and the unattractive condition the second. Thus any difference between the conditions in terms of the dependent variable could be caused by the order of the conditions and not the independent variable itself.
There is a solution to the problem of order effects, however, that can be used in many situations. It is counterbalancing , which means testing different participants in different orders. For example, some participants would be tested in the attractive defendant condition followed by the unattractive defendant condition, and others would be tested in the unattractive condition followed by the attractive condition. With three conditions, there would be six different orders (ABC, ACB, BAC, BCA, CAB, and CBA), so some participants would be tested in each of the six orders. With counterbalancing, participants are assigned to orders randomly, using the techniques we have already discussed. Thus random assignment plays an important role in within-subjects designs just as in between-subjects designs. Here, instead of randomly assigning to conditions, they are randomly assigned to different orders of conditions. In fact, it can safely be said that if a study does not involve random assignment in one form or another, it is not an experiment.
An efficient way of counterbalancing is through a Latin square design which randomizes through having equal rows and columns. For example, if you have four treatments, you must have four versions. Like a Sudoku puzzle, no treatment can repeat in a row or column. For four versions of four treatments, the Latin square design would look like:
| A | B | C | D |
| B | C | D | A |
| C | D | A | B |
| D | A | B | C |
There are two ways to think about what counterbalancing accomplishes. One is that it controls the order of conditions so that it is no longer a confounding variable. Instead of the attractive condition always being first and the unattractive condition always being second, the attractive condition comes first for some participants and second for others. Likewise, the unattractive condition comes first for some participants and second for others. Thus any overall difference in the dependent variable between the two conditions cannot have been caused by the order of conditions. A second way to think about what counterbalancing accomplishes is that if there are carryover effects, it makes it possible to detect them. One can analyze the data separately for each order to see whether it had an effect.
When 9 is “larger” than 221
Researcher Michael Birnbaum has argued that the lack of context provided by between-subjects designs is often a bigger problem than the context effects created by within-subjects designs. To demonstrate this problem, he asked participants to rate two numbers on how large they were on a scale of 1-to-10 where 1 was “very very small” and 10 was “very very large”. One group of participants were asked to rate the number 9 and another group was asked to rate the number 221 (Birnbaum, 1999) [4] . Participants in this between-subjects design gave the number 9 a mean rating of 5.13 and the number 221 a mean rating of 3.10. In other words, they rated 9 as larger than 221! According to Birnbaum, this difference is because participants spontaneously compared 9 with other one-digit numbers (in which case it is relatively large) and compared 221 with other three-digit numbers (in which case it is relatively small) .
Simultaneous Within-Subjects Designs
So far, we have discussed an approach to within-subjects designs in which participants are tested in one condition at a time. There is another approach, however, that is often used when participants make multiple responses in each condition. Imagine, for example, that participants judge the guilt of 10 attractive defendants and 10 unattractive defendants. Instead of having people make judgments about all 10 defendants of one type followed by all 10 defendants of the other type, the researcher could present all 20 defendants in a sequence that mixed the two types. The researcher could then compute each participant’s mean rating for each type of defendant. Or imagine an experiment designed to see whether people with social anxiety disorder remember negative adjectives (e.g., “stupid,” “incompetent”) better than positive ones (e.g., “happy,” “productive”). The researcher could have participants study a single list that includes both kinds of words and then have them try to recall as many words as possible. The researcher could then count the number of each type of word that was recalled. There are many ways to determine the order in which the stimuli are presented, but one common way is to generate a different random order for each participant.
Between-Subjects or Within-Subjects?
Almost every experiment can be conducted using either a between-subjects design or a within-subjects design. This possibility means that researchers must choose between the two approaches based on their relative merits for the particular situation.
Between-subjects experiments have the advantage of being conceptually simpler and requiring less testing time per participant. They also avoid carryover effects without the need for counterbalancing. Within-subjects experiments have the advantage of controlling extraneous participant variables, which generally reduces noise in the data and makes it easier to detect a relationship between the independent and dependent variables.
A good rule of thumb, then, is that if it is possible to conduct a within-subjects experiment (with proper counterbalancing) in the time that is available per participant—and you have no serious concerns about carryover effects—this design is probably the best option. If a within-subjects design would be difficult or impossible to carry out, then you should consider a between-subjects design instead. For example, if you were testing participants in a doctor’s waiting room or shoppers in line at a grocery store, you might not have enough time to test each participant in all conditions and therefore would opt for a between-subjects design. Or imagine you were trying to reduce people’s level of prejudice by having them interact with someone of another race. A within-subjects design with counterbalancing would require testing some participants in the treatment condition first and then in a control condition. But if the treatment works and reduces people’s level of prejudice, then they would no longer be suitable for testing in the control condition. This difficulty is true for many designs that involve a treatment meant to produce long-term change in participants’ behaviour (e.g., studies testing the effectiveness of psychotherapy). Clearly, a between-subjects design would be necessary here.
Remember also that using one type of design does not preclude using the other type in a different study. There is no reason that a researcher could not use both a between-subjects design and a within-subjects design to answer the same research question. In fact, professional researchers often take exactly this type of mixed methods approach.
Key Takeaways
- Experiments can be conducted using either between-subjects or within-subjects designs. Deciding which to use in a particular situation requires careful consideration of the pros and cons of each approach.
- Random assignment to conditions in between-subjects experiments or to orders of conditions in within-subjects experiments is a fundamental element of experimental research. Its purpose is to control extraneous variables so that they do not become confounding variables.
- Experimental research on the effectiveness of a treatment requires both a treatment condition and a control condition, which can be a no-treatment control condition, a placebo control condition, or a waitlist control condition. Experimental treatments can also be compared with the best available alternative.
- You want to test the relative effectiveness of two training programs for running a marathon.
- Using photographs of people as stimuli, you want to see if smiling people are perceived as more intelligent than people who are not smiling.
- In a field experiment, you want to see if the way a panhandler is dressed (neatly vs. sloppily) affects whether or not passersby give him any money.
- You want to see if concrete nouns (e.g., dog ) are recalled better than abstract nouns (e.g., truth ).
- Discussion: Imagine that an experiment shows that participants who receive psychodynamic therapy for a dog phobia improve more than participants in a no-treatment control group. Explain a fundamental problem with this research design and at least two ways that it might be corrected.
- Price, D. D., Finniss, D. G., & Benedetti, F. (2008). A comprehensive review of the placebo effect: Recent advances and current thought. Annual Review of Psychology, 59 , 565–590. ↵
- Shapiro, A. K., & Shapiro, E. (1999). The powerful placebo: From ancient priest to modern physician . Baltimore, MD: Johns Hopkins University Press. ↵
- Moseley, J. B., O’Malley, K., Petersen, N. J., Menke, T. J., Brody, B. A., Kuykendall, D. H., … Wray, N. P. (2002). A controlled trial of arthroscopic surgery for osteoarthritis of the knee. The New England Journal of Medicine, 347 , 81–88. ↵
- Birnbaum, M.H. (1999). How to show that 9>221: Collect judgments in a between-subjects design. Psychological Methods, 4(3), 243-249. ↵
An experiment in which each participant is only tested in one condition.
A method of controlling extraneous variables across conditions by using a random process to decide which participants will be tested in the different conditions.
All the conditions of an experiment occur once in the sequence before any of them is repeated.
Any intervention meant to change people’s behaviour for the better.
A condition in a study where participants receive treatment.
A condition in a study that the other condition is compared to. This group does not receive the treatment or intervention that the other conditions do.
A type of experiment to research the effectiveness of psychotherapies and medical treatments.
A type of control condition in which participants receive no treatment.
A simulated treatment that lacks any active ingredient or element that should make it effective.
A positive effect of a treatment that lacks any active ingredient or element to make it effective.
Participants receive a placebo that looks like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness.
Participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it.
Each participant is tested under all conditions.
An effect of being tested in one condition on participants’ behaviour in later conditions.
Participants perform a task better in later conditions because they have had a chance to practice it.
Participants perform a task worse in later conditions because they become tired or bored.
Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions.
Testing different participants in different orders.
Research Methods in Psychology - 2nd Canadian Edition Copyright © 2015 by Paul C. Price, Rajiv Jhangiani, & I-Chant A. Chiang is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

Module 2: Research Design - Section 2

- Section 1 Discussion
- Section 2 Discussion
Section 2: Experimental Studies
Unlike a descriptive study, an experiment is a study in which a treatment, procedure, or program is intentionally introduced and a result or outcome is observed. The American Heritage Dictionary of the English Language defines an experiment as "A test under controlled conditions that is made to demonstrate a known truth, to examine the validity of a hypothesis, or to determine the efficacy of something previously untried."

This means that no matter who the participant is, he/she has an equal chance of getting into all of the groups or treatments in an experiment. This process helps to ensure that the groups or treatments are similar at the beginning of the study so that there is more confidence that the manipulation (group or treatment) "caused" the outcome. More information about random assignment may be found in section Random assignment.
Definition : An experiment is a study in which a treatment, procedure, or program is intentionally introduced and a result or outcome is observed.
Case Example for Experimental Study
Experimental studies — example 1.

Experimental Studies — Example 2
A fitness instructor wants to test the effectiveness of a performance-enhancing herbal supplement on students in her exercise class. To create experimental groups that are similar at the beginning of the study, the students are assigned into two groups at random (they can not choose which group they are in). Students in both groups are given a pill to take every day, but they do not know whether the pill is a placebo (sugar pill) or the herbal supplement. The instructor gives Group A the herbal supplement and Group B receives the placebo (sugar pill). The students' fitness level is compared before and after six weeks of consuming the supplement or the sugar pill. No differences in performance ability were found between the two groups suggesting that the herbal supplement was not effective.
Email Updates
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
12.1 Experimental design: What is it and when should it be used?
Learning objectives.
- Define experiment
- Identify the core features of true experimental designs
- Describe the difference between an experimental group and a control group
- Identify and describe the various types of true experimental designs
Experiments are an excellent data collection strategy for social workers wishing to observe the effects of a clinical intervention or social welfare program. Understanding what experiments are and how they are conducted is useful for all social scientists, whether they actually plan to use this methodology or simply aim to understand findings from experimental studies. An experiment is a method of data collection designed to test hypotheses under controlled conditions. Students in my research methods classes often use the term experiment to describe all kinds of research projects, but in social scientific research, the term has a unique meaning and should not be used to describe all research methodologies.

Experiments have a long and important history in social science. Behaviorists such as John Watson, B. F. Skinner, Ivan Pavlov, and Albert Bandura used experimental design to demonstrate the various types of conditioning. Using strictly controlled environments, behaviorists were able to isolate a single stimulus as the cause of measurable differences in behavior or physiological responses. The foundations of social learning theory and behavior modification are found in experimental research projects. Moreover, behaviorist experiments brought psychology and social science away from the abstract world of Freudian analysis and towards empirical inquiry, grounded in real-world observations and objectively-defined variables. Experiments are used at all levels of social work inquiry, including agency-based experiments that test therapeutic interventions and policy experiments that test new programs.
Several kinds of experimental designs exist. In general, designs considered to be true experiments contain three key features: independent and dependent variables, pretesting and posttesting, and experimental and control groups. In a true experiment, the effect of an intervention is tested by comparing two groups: one that is exposed to the intervention (the experimental group , also known as the treatment group) and another that does not receive the intervention (the control group ).
In some cases, it may be immoral to withhold treatment from a control group within an experiment. If you recruited two groups of people with severe addiction and only provided treatment to one group, the other group would likely suffer. For these cases, researchers use a comparison group that receives “treatment as usual.” Experimenters must clearly define what treatment as usual means. For example, a standard treatment in substance abuse recovery is attending Alcoholics Anonymous or Narcotics Anonymous meetings. A substance abuse researcher conducting an experiment may use twelve-step programs in their comparison group and use their experimental intervention in the experimental group. The results would show whether the experimental intervention worked better than normal treatment, which is useful information. However, using a comparison group is a deviation from true experimental design and is more associated with quasi-experimental designs.
Importantly, participants in a true experiment need to be randomly assigned to either the control or experimental groups. Random assignment uses a random number generator or some other random process to assign people into experimental and control groups. Random assignment is important in experimental research because it helps to ensure that the experimental group and control group are comparable and that any differences between the experimental and control groups are due to random chance. We will address more of the logic behind random assignment in the next section.
In an experiment, the independent variable is the intervention being tested—for example, a therapeutic technique, prevention program, or access to some service or support. It is less common in of social work research, but social science research may also have a stimulus, rather than an intervention as the independent variable. For example, an electric shock or a reading about death might be used as a stimulus to provoke a response.
The dependent variable is usually the intended effect the researcher wants the intervention to have. If the researcher is testing a new therapy for individuals with binge eating disorder, their dependent variable may be the number of binge eating episodes a participant reports. The researcher likely expects her intervention to decrease the number of binge eating episodes reported by participants. Thus, she must measure the number of episodes that existed prior to the intervention, which is the pretest , and after the intervention, which is the posttest .
Let’s put these concepts in chronological order so we can better understand how an experiment runs from start to finish. Once you’ve collected your sample, you’ll need to randomly assign your participants to the experimental group and control group. You will then give both groups your pretest, which measures your dependent variable, to see what your participants are like before you start your intervention. Next, you will provide your intervention, or independent variable, to your experimental group. Many interventions last a few weeks or months to complete, particularly therapeutic treatments. Finally, you will administer your posttest to both groups to observer any changes in your dependent variable. Together, this is known as the classic experimental design and is the simplest type of true experimental design. All of the designs we review in this section are variations on this approach. Figure 12.1 visually represents these steps.

An interesting example of experimental research can be found in Shannon K. McCoy and Brenda Major’s (2003) [1] study of peoples’ perceptions of prejudice. In one portion of this multifaceted study, all participants were given a pretest to assess their levels of depression. No significant differences in depression were found between the experimental and control groups during the pretest. Participants in the experimental group were then asked to read an article suggesting that prejudice against their own racial group is severe and pervasive, while participants in the control group were asked to read an article suggesting that prejudice against a racial group other than their own is severe and pervasive. Clearly, these were not meant to be interventions or treatments to help depression, but were stimuli designed to elicit changes in people’s depression levels. Upon measuring depression scores during the posttest period, the researchers discovered that those who had received the experimental stimulus (the article citing prejudice against their same racial group) reported greater depression than those in the control group. This is just one of many examples of social scientific experimental research.
In addition to classic experimental design, there are two other ways of designing experiments that are considered to fall within the purview of “true” experiments (Babbie, 2010; Campbell & Stanley, 1963). [2] The posttest-only control group design is almost the same as classic experimental design, except it does not use a pretest. Researchers who use posttest-only designs want to eliminate testing effects , in which a participant’s scores on a measure change because they have already been exposed to it. If you took multiple SAT or ACT practice exams before you took the real one you sent to colleges, you’ve taken advantage of testing effects to get a better score. Considering the previous example on racism and depression, participants who are given a pretest about depression before being exposed to the stimulus would likely assume that the intervention is designed to address depression. That knowledge can cause them to answer differently on the posttest than they otherwise would. Participants are not stupid. They are actively trying to figure out what your study is about.
In theory, as long as the control and experimental groups have been determined randomly and are therefore comparable, no pretest is needed. However, most researchers prefer to use pretests so they may assess change over time within both the experimental and control groups. Researchers wishing to account for testing effects but also gather pretest data can use a Solomon four-group design. In the Solomon four-group design , the researcher uses four groups. Two groups are treated as they would be in a classic experiment—pretest, experimental group intervention, and posttest. The other two groups do not receive the pretest, though one receives the intervention. All groups are given the posttest. Table 12.1 illustrates the features of each of the four groups in the Solomon four-group design. By having one set of experimental and control groups that complete the pretest (Groups 1 and 2) and another set that does not complete the pretest (Groups 3 and 4), researchers using the Solomon four-group design can account for testing effects in their analysis.
| Group 1 | X | X | X |
| Group 2 | X | X | |
| Group 3 | X | X | |
| Group 4 | X |
Solomon four-group designs are challenging to implement in the real world because they are time- and resource-intensive. Researchers must recruit enough participants to create four groups and implement interventions in two of them. Overall, true experimental designs are sometimes difficult to implement in a real-world practice environment. It may be impossible to withhold treatment from a control group or randomly assign participants in a study. In these cases, pre-experimental and quasi-experimental designs can be used. However, the differences in rigor from true experimental designs leave their conclusions more open to critique.
Key Takeaways
- True experimental designs require random assignment.
- Control groups do not receive an intervention, and experimental groups receive an intervention.
- The basic components of a true experiment include a pretest, posttest, control group, and experimental group.
- Testing effects may cause researchers to use variations on the classic experimental design.
- Classic experimental design- uses random assignment, an experimental and control group, as well as pre- and posttesting
- Comparison group- a group in quasi-experimental designs that receives “treatment as usual” instead of no treatment
- Control group- the group in an experiment that does not receive the intervention
- Experiment- a method of data collection designed to test hypotheses under controlled conditions
- Experimental group- the group in an experiment that receives the intervention
- Posttest- a measurement taken after the intervention
- Posttest-only control group design- a type of experimental design that uses random assignment, and an experimental and control group, but does not use a pretest
- Pretest- a measurement taken prior to the intervention
- Random assignment-using a random process to assign people into experimental and control groups
- Solomon four-group design- uses random assignment, two experimental and two control groups, pretests for half of the groups, and posttests for all
- Testing effects- when a participant’s scores on a measure change because they have already been exposed to it
- True experiments- a group of experimental designs that contain independent and dependent variables, pretesting and post testing, and experimental and control groups
Image attributions
exam scientific experiment by mohamed_hassan CC-0
- McCoy, S. K., & Major, B. (2003). Group identification moderates emotional response to perceived prejudice. Personality and Social Psychology Bulletin , 29, 1005–1017. ↵
- Babbie, E. (2010). The practice of social research (12th ed.). Belmont, CA: Wadsworth; Campbell, D., & Stanley, J. (1963). Experimental and quasi-experimental designs for research . Chicago, IL: Rand McNally. ↵
Scientific Inquiry in Social Work Copyright © 2018 by Matthew DeCarlo is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Experimental Design
- Reference work entry
- First Online: 01 January 2024
- pp 2311–2313
- Cite this reference work entry

- Kim Koh 2
Experiments ; Randomized clinical trial ; Randomized trial
In quality-of-life and well-being research specifically, and in medical, nursing, social, educational, and psychological research more generally, experimental design can be used to test cause-and-effect relationships between the independent and dependent variables.
Description
Experimental design was pioneered by R. A. Fisher in the fields of agriculture and education (Fisher 1935 ). In studies that use experimental design, the independent variables are manipulated or controlled by researchers, which enables the testing of the cause-and-effect relationship between the independent and dependent variables. An experimental design can control many threats to internal validity by using random assignment of participants to different treatment/intervention and control/comparison groups. Therefore, it is considered one of the most statistically robust designs in quality-of-life and well-being research, as well as in...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Campbell, D. T., & Stanley, J. C. (1963). Experimental and quasi-experimental designs for research . Chicago: Rand MçNally & Company.
Google Scholar
Fisher, R. A. (1935). The design of experiments . Edinburgh: Oliver and Boyd.
Kerlinger, F. N., & Lee, H. B. (2000). Foundations of behavioral research (4th ed.). Belmont: Cengage Learning.
Schneider, B., Carnoy, M., Kilpatrick, J., Schmidt, W. H., & Shavelson, R. J. (2007). Estimating causal effects: Using experimental designs and observational design . Washington, DC: American Educational Research Association.
Download references
Author information
Authors and affiliations.
Werklund School of Education, University of Calgary, Calgary, AB, Canada
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Kim Koh .
Editor information
Editors and affiliations.
Dipartimento di Scienze Statistiche, Sapienza Università di Roma, Roma, Roma, Italy
Filomena Maggino
Section Editor information
Department of ECPS & Intitute of Applied Mathematics, University of British Columbia, Vancouver, BC, Canada
Bruno Zumbo
Rights and permissions
Reprints and permissions
Copyright information
© 2023 Springer Nature Switzerland AG
About this entry
Cite this entry.
Koh, K. (2023). Experimental Design. In: Maggino, F. (eds) Encyclopedia of Quality of Life and Well-Being Research. Springer, Cham. https://doi.org/10.1007/978-3-031-17299-1_967
Download citation
DOI : https://doi.org/10.1007/978-3-031-17299-1_967
Published : 11 February 2024
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-17298-4
Online ISBN : 978-3-031-17299-1
eBook Packages : Social Sciences Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
Share this entry
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
IMAGES
COMMENTS
Study with Quizlet and memorize flashcards containing terms like A pharmaceutical company wants to test whether its medication reduces cholesterol levels. They assign the numbers 00-99 to each of the 100 participants, and use a table of random digits to select 50 subjects to take the medication. The remaining 50 subjects are given a placebo., Refer to this design web of a car manufacturer's ...
single blind. double blind (correct) placebo effect. controlled experiment. Study with Quizlet and memorize flashcards containing terms like A biology student wanted to determine if using fertilizer would promote plant growth. One hundred plants were randomly assigned to one of two groups as shown in the design web.
Additional Principles of Experimental Design. A new cream was developed to reduce the irritation caused by poison ivy. To test the effectiveness, researchers placed an ad online asking for volunteers to participate in the study. One hundred subjects replied, and they were informed that one group would receive the new cream and the other group ...
Table of contents. Step 1: Define your variables. Step 2: Write your hypothesis. Step 3: Design your experimental treatments. Step 4: Assign your subjects to treatment groups. Step 5: Measure your dependent variable. Other interesting articles. Frequently asked questions about experiments.
In an experiment, random assignment means that experimental units are assigned to treatments using a _____ process. replication In an experiment, _____ means giving each treatment enough experimental units so that a difference in the effects of the treatment can be distinguished from chance variation due to the random assignment.
1.3 The Language of Experimental Design. By an experiment we understand an investigation where the researcher has full control over selecting and altering the experimental conditions of interest, and we only consider investigations of this type. The selected experimental conditions are called treatments.An experiment is comparative if the responses to several treatments are to be compared or ...
There are three principles that underlie any experiment. These are often called the three Rs of experimental design, and they are: Randomization. Replication. Reduction of variance. Let's look at each principle in the context of a specific experiment. In this experiment, a researcher assigned each subject to one of two different exercise ...
Three types of experimental designs are commonly used: 1. Independent Measures. Independent measures design, also known as between-groups, is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
Chapter 1 Principles of experimental design. Chapter 1. Principles of experimental design. Although it is obviously true that statistical tests are not the only method for arriving at the 'truth', it is equally true that formal experiments generally provide the most scientifically valid research result. (Bailar III 1981)
The researcher must design her experiment in such a way that there is only one difference between groups being compared: the planned treatments. This is accomplished by the random assignment of experimental units to treatment groups. When subjects are assigned treatments randomly, all of the potential lurking variables are spread equally among ...
Study with Quizlet and memorize flashcards containing terms like A company that manufactures golf balls produces a new type of ball that is supposed to travel significantly farther than the company's previous golf ball. To determine this, 40 new-style golf balls and 40 original-style golf balls are randomly selected from the company's production line on a specific day. The balls are then ...
1. 4. Experimental design 1. 4. 1. The role of experimental design Experimental design concerns the validity and efficiency of the experiment. The experimental design in the following diagram (Box et al., 1978), is represented by a movable window through which certain aspects of the true state of nature, more or less distorted by noise, may be ...
1.1.5 - Principles of Experimental Design. The following principles of experimental design have to be followed to enable a researcher to conclude that differences in the results of an experiment, not reasonably attributable to chance, are likely caused by the treatments. Need to control for effects due to factors other than the ones of primary ...
Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition ...
True experiments have four elements: manipulation, control , random assignment, and random selection. The most important of these elements are manipulation and control. Manipulation means that something is purposefully changed by the researcher in the environment. Control is used to prevent outside factors from influencing the study outcome.
Two groups are treated as they would be in a classic experiment—pretest, experimental group intervention, and posttest. The other two groups do not receive the pretest, though one receives the intervention. All groups are given the posttest. Table 12.1 illustrates the features of each of the four groups in the Solomon four-group design.
Terms in this set (9) Explain the difference between repetition and replication. Repetition refers to performing multiple trials throughout an experiment. Repetition reduces mistakes and increases one's confidence in the results. Replication refers to the ability of a process to be repeated by another individual.
Chapter 11 - Experiments and Observational Studies. In Chapter 10 and 11 we talk about different methods used to collect data. In the last chapter we learned about Sample Surveys. In this chapter we will talk about Observational Studies and Experiments. They all collect data in different ways and lead to different conclusions.
Benefits of Designed Experiments over Observational Studies. Well designed can yield evidence for cause-effect relationships. Allows for the study of combined effects of several factors simultaneously, and of interactions among the factors. Placebo Effect: Many patients respond favorably to any treatment - even a placebo.
Quizlet has study tools to help you learn anything. Improve your grades and reach your goals with flashcards, practice tests and expert-written solutions today. ... Additional Principles of Experimental Design Assignment. Log in. Sign up. Get a hint. A pharmaceutical company wants to test whether its medication reduces cholesterol levels. They ...
The (statistical) design of experiments provides the principles and methods for planning experiments and tailoring the data acquisition to an intended analysis.The design and analysis of an experiment are best considered as two aspects of the same enterprise: the goals of the analysis strongly inform an appropriate design, and the implemented design determines the possible analyses.
Quizlet has study tools to help you learn anything. Improve your grades and reach your goals with flashcards, practice tests and expert-written solutions today.
An experimental design can control many threats to internal validity by using random assignment of participants to different treatment/intervention and control/comparison groups. Therefore, it is considered one of the most statistically robust designs in quality-of-life and well-being research, as well as in medical, nursing, social ...