- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Text Analytics
- Try Thematic
Welcome to the community


Coding Qualitative Data: How To Guide
How many hours have you spent sitting in front of Excel spreadsheets trying to find new insights from customer feedback?
You know that asking open-ended survey questions gives you more actionable insights than asking your customers for just a numerical Net Promoter Score (NPS) . But when you ask open-ended, free-text questions, you end up with hundreds (or even thousands) of free-text responses.
How can you turn all of that text into quantifiable, applicable information about your customers’ needs and expectations? By coding qualitative data.
In this article, we will cover different coding methods for qualitative data, including both manual and automated approaches, to provide a comprehensive understanding of the techniques used in the first-round pass at coding.
Keep reading to learn:
- What coding qualitative data means (and why it’s important)
- Different methods of coding qualitative data
- How to manually code qualitative data to find significant themes in your data
What is coding in qualitative research?
Conducting qualitative research, particularly through coding, is a crucial step in ensuring the validity and reliability of the findings. Coding is the process of labeling and organizing your qualitative data to identify different themes and the relationships between them.
When coding customer feedback , you assign labels to words or phrases that represent important (and recurring) themes in each response. These labels can be words, phrases, or numbers; we recommend using words or short phrases, since they’re easier to remember, skim, and organize.
Coding qualitative research to find common themes and concepts is part of thematic analysis . Thematic analysis extracts themes from text by analyzing the word and sentence structure.
Within the context of customer feedback, it’s important to understand the many different types of qualitative feedback a business can collect, such as open-ended surveys, social media comments, reviews & more.
What is qualitative data analysis?
Qualitative data analysis , including coding and analyzing qualitative data, is essential for understanding the depth and complexity of qualitative data. It is the process of examining and interpreting qualitative data to understand what it represents.
Qualitative analysis is crucial as it involves various methods such as thematic analysis, emotion coding, inductive and deductive thematic analysis, and content analysis. These methods help in coding the data, which is vital for the validity of the analysis.
Qualitative data is defined as any non-numerical and unstructured data; when looking at customer feedback, qualitative data usually refers to any verbatim or text-based feedback such as reviews, open-ended responses in surveys , complaints, chat messages, customer interviews, case notes or social media posts.
For example, NPS metric can be strictly quantitative, but when you ask customers why they gave you a rating a score, you will need qualitative data analysis methods in place to understand the comments that customers leave alongside numerical responses.
Methods of qualitative data analysis
Thematic analysis.
This refers to the uncovering of themes, by analyzing the patterns and relationships in a set of qualitative data. A theme emerges or is built when related findings appear to be meaningful and there are multiple occurrences. Thematic analysis can be used by anyone to transform and organize open-ended responses, analyze online reviews , and other qualitative data into significant themes. Thematic analysis coding is a method that aids in categorizing data extracts and deriving themes and patterns for qualitative analysis, facilitating the identification of themes revolving around a particular concept or phenomenon in the social sciences.
Content analysis:
This refers to the categorization, tagging and thematic analysis of qualitative data. Essentially content analysis is a quantification of themes, by counting the occurrence of concepts, topics or themes. Content analysis can involve combining the categories in qualitative data with quantitative data, such as behavioral data or demographic data, for deeper insights.
Narrative analysis:
Some qualitative data, such as interviews or field notes may contain a story on how someone experienced something. For example, the process of choosing a product, using it, evaluating its quality and decision to buy or not buy this product next time. The goal of narrative analysis is to turn the individual narratives into data that can be coded. This is then analyzed to understand how events or experiences had an impact on the people involved. Process coding is particularly useful in narrative analysis for identifying specific phases, sequences, and movements within the stories, capturing actions within qualitative data by using codes that typically represent gerunds ending in 'ing', providing a dynamic account of events within the data.
Discourse analysis:
This refers to analysis of what people say in social and cultural context. The goal of discourse analysis is to understand user or customer behavior by uncovering their beliefs, interests and agendas. These are reflected in the way they express their opinions, preferences and experiences. Structural coding is a method that can be applied here, organizing data based on predetermined structures, such as the structure of discourse elements, to enhance the analysis of discourse. It’s particularly useful when your focus is on building or strengthening a brand , by examining how they use metaphors and rhetorical devices.
Framework analysis:
When performing qualitative data analysis, it is useful to have a framework to organize the buckets of meaning. A taxonomy or code frame (a hierarchical set of themes used in coding qualitative data) is an example of the result. Don't fall into the trap of starting with a framework to make it faster to organize your data. You should look at how themes relate to each other by analyzing the data and consistently check that you can validate that themes are related to each other .
Grounded theory:
This method of analysis starts by formulating a theory around a single data case. Therefore the theory is “grounded' in actual data. Then additional cases can be examined to see if they are relevant and can add to the original theory.
Why is it important to code qualitative data?
Coding qualitative data makes it easier to interpret customer feedback. Assigning codes to words and phrases in each response helps capture what the response is about which, in turn, helps you better analyze and summarize the results of the entire survey.
Researchers use coding and other qualitative data analysis processes to help them make data-driven decisions based on customer feedback. When you use coding to analyze your customer feedback, you can quantify the common themes in customer language. This makes it easier to accurately interpret and analyze customer satisfaction.
What is thematic coding?
Thematic coding, also called thematic analysis, is a type of qualitative data analysis that finds themes in text by analyzing the meaning of words and sentence structure.
When you use thematic coding to analyze customer feedback for example, you can learn which themes are most frequent in feedback. This helps you understand what drives customer satisfaction in an accurate, actionable way.
To learn more about how Thematic analysis software helps you automate the data coding process, check out this article .
Automated vs. Manual coding of qualitative data
Methods of coding qualitative data fall into three categories: automated coding and manual coding, and a blend of the two.
You can automate the coding of your qualitative data with thematic analysis software . Thematic analysis and qualitative data analysis software use machine learning, artificial intelligence (AI) natural language processing (NLP) to code your qualitative data and break text up into themes.
Thematic analysis software is autonomous , which means…
- You don't need to set up themes or categories in advance.
- You don't need to train the algorithm — it learns on its own.
- You can easily capture the “unknown unknowns” to identify themes you may not have spotted on your own.
…all of which will save you time (and lots of unnecessary headaches) when analyzing your customer feedback.
Businesses are also seeing the benefit of using thematic analysis software. The capacity to aggregate data sources into a single source of analysis helps to break down data silos, unifying the analysis and insights across departments . This is now being referred to as Omni channel analysis or Unified Data Analytics .
Use Thematic Analysis Software
Try Thematic today to discover why leading companies rely on the platform to automate the coding of qualitative customer feedback at scale. Whether you have tons of customer reviews, support chat, customer service conversationals ( conversational analytics ) or open-ended survey responses, Thematic brings every valuable insight to the surface, while saving you thousands of hours.
Advances in natural language processing & machine learning have made it possible to automate the analysis of qualitative data, in particular content and framework analysis. The most commonly used software for automated coding of qualitative data is text analytics software such as Thematic .
While manual human analysis is still popular due to its perceived high accuracy, automating most of the analysis is quickly becoming the preferred choice. Unlike manual analysis, which is prone to bias and doesn't scale to the amount of qualitative data that is generated today, automating analysis is not only more consistent and therefore can be more accurate, but can also save a ton of time, and therefore money.
Our Theme Editor tool ensures you take a reflexive approach, an important step in thematic analysis. The drag-and-drop tool makes it easy to refine, validate, and rename themes as you get more data. By guiding the AI, you can ensure your results are always precise, easy to understand and perfectly aligned with your objectives.
Thematic is the best software to automate code qualitative feedback at scale.
Don't just take it from us. Here's what some of our customers have to say:
I'm a fan of Thematic's ability to save time and create heroes. It does an excellent job using a single view to break down the verbatims into themes displayed by volume, sentiment and impact on our beacon metric, often but not exclusively NPS.
It does a superlative job using GenAI in summarizing a theme or sub-theme down to a single paragraph making it clear what folks are trying to say. Peter K, Snr Research Manager.
Thematic is a very intuitive tool to use. It boasts a robust level of granularity, allowing the user to see the general breadth of verbatim themes, dig into the sub-themes, and further into the sentiment of the open text itself. Artem C, Sr Manager of Research. LinkedIn.
AI-powered software to transform qualitative data at scale through a thematic and content analysis.
How to manually code qualitative data
For the rest of this post, we'll focus on manual coding. Different researchers have different processes, but manual coding usually looks something like this:
- Choose whether you'll use deductive or inductive coding.
- Read through your data to get a sense of what it looks like. Assign your first set of codes.
- Go through your data line-by-line to code as much as possible. Your codes should become more detailed at this step.
- Categorize your codes and figure out how they fit into your coding frame.
- Identify which themes come up the most — and act on them.
Let's break it down a little further…
Deductive coding vs. inductive coding
Before you start qualitative data coding, you need to decide which codes you'll use.
What is Deductive Coding?
Deductive coding means you start with a predefined set of codes, then assign those codes to the new qualitative data. These codes might come from previous research, or you might already know what themes you're interested in analyzing. Deductive coding is also called concept-driven coding.
For example, let's say you're conducting a survey on customer experience . You want to understand the problems that arise from long call wait times, so you choose to make “wait time” one of your codes before you start looking at the data.
The deductive approach can save time and help guarantee that your areas of interest are coded. But you also need to be careful of bias; when you start with predefined codes, you have a bias as to what the answers will be. Make sure you don't miss other important themes by focusing too hard on proving your own hypothesis.
What is Inductive Coding?
Inductive coding , also called open coding, starts from scratch and creates codes based on the qualitative data itself. You don't have a set codebook; all codes arise directly from the survey responses.
Here's how inductive coding works:
- Break your qualitative dataset into smaller samples.
- Read a sample of the data.
- Create codes that will cover the sample.
- Reread the sample and apply the codes.
- Read a new sample of data, applying the codes you created for the first sample.
- Note where codes don't match or where you need additional codes.
- Create new codes based on the second sample.
- Go back and recode all responses again.
- Repeat from step 5 until you've coded all of your data.
If you add a new code, split an existing code into two, or change the description of a code, make sure to review how this change will affect the coding of all responses. Otherwise, the same responses at different points in the survey could end up with different codes.
Sounds like a lot of work, right? Inductive coding is an iterative process, which means it takes longer and is more thorough than deductive coding. A major advantage is that it gives you a more complete, unbiased look at the themes throughout your data.
Combining inductive and deductive coding
In practice, most researchers use a blend of inductive and deductive approaches to coding.
For example, with Thematic, the AI inductively comes up with themes , while also framing the analysis so that it reflects how business decisions are made . At the end of the analysis, researchers use the Theme Editor to iterate or refine themes. Then, in the next wave of analysis, as new data comes in, the AI starts deductively with the theme taxonomy.
Categorize your codes with coding frames
Once you create your codes, you need to put them into a coding frame. A coding frame represents the organizational structure of the themes in your research. There are two types of coding frames: flat and hierarchical.
Flat Coding Frame
A flat coding frame assigns the same level of specificity and importance to each code. While this might feel like an easier and faster method for manual coding, it can be difficult to organize and navigate the themes and concepts as you create more and more codes. It also makes it hard to figure out which themes are most important, which can slow down decision making.
Hierarchical Coding Frame
Hierarchical frames help you organize codes based on how they relate to one another. For example, you can organize the codes based on your customers' feelings on a certain topic:

Hierarchical Coding Frame example
In this example:
- The top-level code describes the topic (customer service)
- The mid-level code specifies whether the sentiment is positive or negative
- The third level details the attribute or specific theme associated with the topic
Hierarchical framing supports a larger code frame and lets you organize codes based on organizational structure. It also allows for different levels of granularity in your coding.
Whether your code frames are hierarchical or flat, your code frames should be flexible. Manually analyzing survey data takes a lot of time and effort; make sure you can use your results in different contexts.
For example, if your survey asks customers about customer service, you might only use codes that capture answers about customer service. Then you realize that the same survey responses have a lot of comments about your company's products. To learn more about what people say about your products, you may have to code all of the responses from scratch! A flexible coding frame covers different topics and insights, which lets you reuse the results later on.
Tips for manually coding qualitative data
Now that you know the basics of coding your qualitative data, here are some tips on making the most of your qualitative research.
Use a codebook to keep track of your codes
As you code more and more data, it can be hard to remember all of your codes off the top of your head. Tracking your codes in a codebook helps keep you organized throughout the data analysis process. Your codebook can be as simple as an Excel spreadsheet or word processor document. As you code new data, add new codes to your codebook and reorganize categories and themes as needed.
Make sure to track:
- The label used for each code
- A description of the concept or theme the code refers to
- Who originally coded it
- The date that it was originally coded or updated
- Any notes on how the code relates to other codes in your analysis
How to create high-quality codes - 4 tips
1. cover as many survey responses as possible..
The code should be generic enough to apply to multiple comments, but specific enough to be useful in your analysis. For example, “Product” is a broad code that will cover a variety of responses — but it's also pretty vague. What about the product? On the other hand, “Product stops working after using it for 3 hours” is very specific and probably won't apply to many responses. “Poor product quality” or “short product lifespan” might be a happy medium.
2. Avoid commonalities.
Having similar codes is okay as long as they serve different purposes. “Customer service” and “Product” are different enough from one another, while “Customer service” and “Customer support” may have subtle differences but should likely be combined into one code.
3. Capture the positive and the negative.
Try to create codes that contrast with each other to track both the positive and negative elements of a topic separately. For example, “Useful product features” and “Unnecessary product features” would be two different codes to capture two different themes.
4. Reduce data — to a point.
Let's look at the two extremes: There are as many codes as there are responses, or each code applies to every single response. In both cases, the coding exercise is pointless; you don't learn anything new about your data or your customers. To make your analysis as useful as possible, try to find a balance between having too many and too few codes.
Group responses based on themes, not words
Make sure to group responses with the same themes under the same code, even if they don't use the same exact wording. For example, a code such as “cleanliness” could cover responses including words and phrases like:
- Looked like a dump
- Could eat off the floor
Having only a few codes and hierarchical framing makes it easier to group different words and phrases under one code. If you have too many codes, especially in a flat frame, your results can become ambiguous and themes can overlap. Manual coding also requires the coder to remember or be able to find all of the relevant codes; the more codes you have, the harder it is to find the ones you need, no matter how organized your codebook is.
Make accuracy a priority
Manually coding qualitative data means that the coder's cognitive biases can influence the coding process. For each study, make sure you have coding guidelines and training in place to keep coding reliable, consistent, and accurate .
One thing to watch out for is definitional drift, which occurs when the data at the beginning of the data set is coded differently than the material coded later. Check for definitional drift across the entire dataset and keep notes with descriptions of how the codes vary across the results.
If you have multiple coders working on one team, have them check one another's coding to help eliminate cognitive biases.
Conclusion: 6 main takeaways for coding qualitative data
Here are 6 final takeaways for manually coding your qualitative data:
- Coding is the process of labeling and organizing your qualitative data to identify themes. After you code your qualitative data, you can analyze it just like numerical data.
- Inductive coding (without a predefined code frame) is more difficult, but less prone to bias, than deductive coding.
- Code frames can be flat (easier and faster to use) or hierarchical (more powerful and organized).
- Your code frames need to be flexible enough that you can make the most of your results and use them in different contexts.
- When creating codes, make sure they cover several responses, contrast one another, and strike a balance between too much and too little information.
- Consistent coding = accuracy. Establish coding procedures and guidelines and keep an eye out for definitional drift in your qualitative data analysis.
Some more detail in our downloadable guide
If you've made it this far, you'll likely be interested in our free guide: Best practices for analyzing open-ended questions.
The guide includes some of the topics covered in this article, and goes into some more niche details.
If your company is looking to automate your qualitative coding process, try Thematic !
If you're looking to trial multiple solutions, check out our free buyer's guide . It covers what to look for when trialing different feedback analytics solutions to ensure you get the depth of insights you need.
Happy coding!
Authored by Alyona Medelyan, PhD – Natural Language Processing & Machine Learning

CEO and Co-Founder
Alyona has a PhD in NLP and Machine Learning. Her peer-reviewed articles have been cited by over 2600 academics. Her love of writing comes from years of PhD research.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Discover the power of thematic analysis to unlock insights from qualitative data. Learn about manual vs. AI-powered approaches, best practices, and how Thematic software can revolutionize your analysis workflow.
When two major storms wreaked havoc on Auckland and Watercare’s infrastructurem the utility went through a CX crisis. With a massive influx of calls to their support center, Thematic helped them get inisghts from this data to forge a new approach to restore services and satisfaction levels.
University Library
Qualitative Data Analysis: Coding
- Atlas.ti web
- R for text analysis
- Microsoft Excel & spreadsheets
- Other options
- Planning Qual Data Analysis
- Free Tools for QDA
- QDA with NVivo
- QDA with Atlas.ti
- QDA with MAXQDA
- PKM for QDA
- QDA with Quirkos
- Working Collaboratively
- Qualitative Methods Texts
- Transcription
- Data organization
- Example Publications
Coding Qualitative Data
Planning your coding strategy.
Coding is a qualitative data analysis strategy in which some aspect of the data is assigned a descriptive label that allows the researcher to identify related content across the data. How you decide to code - or whether to code- your data should be driven by your methodology. But there are rarely step-by-step descriptions, and you'll have to make many decisions about how to code for your own project.
Some questions to consider as you decide how to code your data:
What will you code?
What aspects of your data will you code? If you are not coding all of your available data, how will you decide which elements need to be coded? If you have recordings interviews or focus groups, or other types of multimedia data, will you create transcripts to analyze and code? Or will you code the media itself (see Farley, Duppong & Aitken, 2020 on direct coding of audio recordings rather than transcripts).
Where will your codes come from?
Depending on your methodology, your coding scheme may come from previous research and be applied to your data (deductive). Or you my try to develop codes entirely from the data, ignoring as much as possible, previous knowledge of the topic under study, to develop a scheme grounded in your data (inductive). In practice, however, many practices will fall between these two approaches.
How will you apply your codes to your data?
You may decide to use software to code your qualitative data, to re-purpose other software tools (e.g. Word or spreadsheet software) or work primarily with physical versions of your data. Qualitative software is not strictly necessary, though it does offer some advantages, like:
- Codes can be easily re-labeled, merged, or split. You can also choose to apply multiple coding schemes to the same data, which means you can explore multiple ways of understanding the same data. Your analysis, then, is not limited by how often you are able to work with physical data, such as paper transcripts.
- Most software programs for QDA include the ability to export and import coding schemes. This means you can create a re-use a coding scheme from a previous study, or that was developed in outside of the software, without having to manually create each code.
- Some software for QDA includes the ability to directly code image, video, and audio files. This may mean saving time over creating transcripts. Or, your coding may be enhanced by access to the richness of mediated content, compared to transcripts.
- Using QDA software may also allow you the ability to use auto-coding functions. You may be able to automatically code all of the statements by speaker in a focus group transcript, for example, or identify and code all of the paragraphs that include a specific phrase.
What will be coded?
Will you deploy a line-by-line coding approach, with smaller codes eventually condensed into larger categories or concepts? Or will you start with codes applied to larger segments of the text, perhaps later reviewing the examples to explore and re-code for differences between the segments?
How will you explain the coding process?
- Regardless of how you approach coding, the process should be clearly communicated when you report your research, though this is not always the case (Deterding & Waters, 2021).
- Carefully consider the use of phrases like "themes emerged." This phrasing implies that the themes lay passively in the data, waiting for the researcher to pluck them out. This description leaves little room for describing how the researcher "saw" the themes and decided which were relevant to the study. Ryan and Bernard (2003) offer a terrific guide to ways that you might identify themes in the data, using both your own observations as well as manipulations of the data.
How will you report the results of your coding process?
How you report your coding process should align with the methodology you've chosen. Your methodology may call for careful and consistent application of a coding scheme, with reports of inter-rater reliability and counts of how often a code appears within the data. Or you may use the codes to help develop a rich description of an experience, without needing to indicate precisely how often the code was applied.
How will you code collaboratively?
If you are working with another researcher or a team, your coding process requires careful planning and implementation. You will likely need to have regular conversations about your process, particularly if your goal is to develop and consistently apply a coding scheme across your data.
Coding Features in QDA Software Programs
- Atlas.ti (Mac)
- Atlas.ti (Windows)
- NVivo (Windows)
- NVivo (Mac)
- Coding data See how to create and manage codes and apply codes to segments of the data (known as quotations in Atlas.ti).
- Search and Code Using the search and code feature lets you locate and automatically code data through text search, regular expressions, Named Entity Recognition, and Sentiment Analysis.
- Focus Group Coding Properly prepared focus group documents can be automatically coded by speaker.
- Inter-Coder Agreement Coded text, audio, and video documents can be tested for inter-coder agreement. ICA is not available for images or PDF documents.
- Quotation Reader Once you've coded data, you can view just the data that has been assigned that code.
- Find Redundant Codings (Mac) This tool identifies "overlapping or embedded" quotations that have the same code, that are the result of manual coding or errors when merging project files.
- Coding Data in Atlas.ti (Windows) Demonstrates how to create new codes, manage codes and applying codes to segments of the data (known as quotations in Atlas.ti)
- Search and Code in Atlas.ti (Windows) You can use a text search, regular expressions, Named Entity Recognition, and Sentiment Analysis to identify and automatically code data in Atlas.ti.
- Focus Group Coding in Atlas.ti (Windows) Properly prepared focus group transcripts can be automatically coded by speaker.
- Inter-coder Agreement in Atlas.ti (Windows) Coded text, audio, and video documents can be tested for inter-coder agreement. ICA is not available for images or PDF documents.
- Quotation Reader in Atlas.ti (Windows) Once you've coded data, you can view and export the quotations that have been assigned that code.
- Find Redundant Codings in Atlas.ti (Windows) This tool identifies "overlapping or embedded" quotations that have the same code, that are the result of manual coding or errors when merging project files.
- Coding in NVivo (Windows) This page includes an overview of the coding features in NVivo.
- Automatic Coding in Documents in NVivo (Windows) You can use paragraph formatting styles or speaker names to automatically format documents.
- Coding Comparison Query in NVivo (Windows) You can use the coding comparison feature to compare how different users have coded data in NVivo.
- Review the References in a Node in NVivo (Windows) References are the term that NVivo uses for coded segments of the data. This shows you how to view references related to a code (or any node)
- Text Search Queries in NVivo (Windows) Text queries let you search for specific text in your data. The results of your query can be saved as a node (a form of auto coding).
- Coding Query in NVivo (Windows) Use a coding query to display references from your data for a single code or multiples of codes.
- Code Files and Manage Codes in NVivo (Mac) This page offers an overview of coding features in NVivo. Note that NVivo uses the concept of a node to refer to any structure around which you organize your data. Codes are a type of node, but you may see these terms used interchangeably.
- Automatic Coding in Datasets in NVivo (Mac) A dataset in NVivo is data that is in rows and columns, as in a spreadsheet. If a column is set to be codable, you can also automatically code the data. This approach could be used for coding open-ended survey data.
- Text Search Query in NVivo (Mac) Use the text search query to identify relevant text in your data and automatically code references by saving as a node.
- Review the References in a Node in NVivo (Mac) NVivo uses the term references to refer to data that has been assigned to a code or any node. You can use the reference view to see the data linked to a specific node or combination of nodes.
- Coding Comparison Query in NVivo (Mac) Use the coding comparison query to calculate a measure of inter-rater reliability when you've worked with multiple coders.
The MAXQDA interface is the same across Mac and Windows devices.
- The "Code System" in MAXQDA This section of the manual shows how to create and manage codes in MAXQDA's code system.
- How to Code with MAXQDA
- Display Coded Segments in the Document Browser Once you've coded a document within MAXQDA, you can choose which of those codings will appear on the document, as well as choose whether or not the text is highlighted in the color linked to the code.
- Creative Coding in MAXQDA Use the creative coding feature to explore the relationships between codes in your system. If you develop a new structure to you codes that you like, you can apply the changes to your overall code scheme.
- Text Search in MAXQDA Use a Text Search to identify data that matches your search terms and automatically code the results. You can choose whether to code only the matching results, the sentence the results are in, or the paragraph the results appear in.
- Segment Retrieval in MAXQDA Data that has been coded is considered a segment. Segment retrieval is how you display the segments that match a code or combination of codes. You can use the activation feature to show only the segments from a document group, or that match a document variable.
- Intercorder Agreement in MAXQDA MAXQDA includes the ability to compare coding between two coders on a single project.
- Create Tags in Taguette Taguette uses the term tag to refer to codes. You can create single tags as well as a tag hierarchy using punctuation marks.
- Highlighting in Taguette Select text with a document (a highlight) and apply tags to code data in Taguette.
Useful Resources on Coding

Deterding, N. M., & Waters, M. C. (2021). Flexible coding of in-depth interviews: A twenty-first-century approach. Sociological Methods & Research , 50 (2), 708–739. https://doi.org/10.1177/0049124118799377
Farley, J., Duppong Hurley, K., & Aitken, A. A. (2020). Monitoring implementation in program evaluation with direct audio coding. Evaluation and Program Planning , 83 , 101854. https://doi.org/10.1016/j.evalprogplan.2020.101854
Ryan, G. W., & Bernard, H. R. (2003). Techniques to identify themes. Field Methods , 15 (1), 85–109. https://doi.org/10.1177/1525822X02239569.
- << Previous: Data organization
- Next: Citations >>
- Last Updated: Sep 4, 2024 10:13 AM
- URL: https://guides.library.illinois.edu/qualitative
A guide to coding qualitative research data
Last updated
12 February 2023
Reviewed by
Short on time? Get an AI generated summary of this article instead
Each time you ask open-ended and free-text questions, you'll end up with numerous free-text responses. When your qualitative data piles up, how do you sift through it to determine what customers value? And how do you turn all the gathered texts into quantifiable and actionable information related to your user's expectations and needs?
Qualitative data can offer significant insights into respondents’ attitudes and behavior. But to distill large volumes of text / conversational data into clear and insightful results can be daunting. One way to resolve this is through qualitative research coding.
Streamline data coding
Use global data tagging systems in Dovetail so everyone analyzing research is speaking the same language
- What is coding in qualitative research?
This is the system of classifying and arranging qualitative data . Coding in qualitative research involves separating a phrase or word and tagging it with a code. The code describes a data group and separates the information into defined categories or themes. Using this system, researchers can find and sort related content.
They can also combine categorized data with other coded data sets for analysis, or analyze it separately. The primary goal of coding qualitative data is to change data into a consistent format in support of research and reporting.
A code can be a phrase or a word that depicts an idea or recurring theme in the data. The code’s label must be intuitive and encapsulate the essence of the researcher's observations or participants' responses. You can generate these codes using two approaches to coding qualitative data: manual coding and automated coding.
- Why is it important to code qualitative data?
By coding qualitative data, it's easier to identify consistency and scale within a set of individual responses. Assigning codes to phrases and words within feedback helps capture what the feedback entails. That way, you can better analyze and understand the outcome of the entire survey.
Researchers use coding and other qualitative data analysis procedures to make data-driven decisions according to customer responses. Coding in customer feedback will help you assess natural themes in the customers’ language. With this, it's easy to interpret and analyze customer satisfaction .
- How do inductive and deductive approaches to qualitative coding work?
Before you start qualitative research coding, you must decide whether you're starting with some predefined code frames, within which the data will be sorted (deductive approach). Or, you may plan to develop and evolve the codes while reviewing the qualitative data generated by the research (inductive approach). A combination of both approaches is also possible.
In most instances, a combined approach will be best. For example, researchers will have some predefined codes/themes they expect to find in the data, but will allow for a degree of discovery in the data where new themes and codes come to light.
Inductive coding
This is an exploratory method in which new data codes and themes are generated by the review of qualitative data. It initiates and generates code according to the source of the data itself. It's ideal for investigative research, in which you devise a new idea, theory, or concept.
Inductive coding is otherwise called open coding. There's no predefined code-frame within inductive coding, as all codes are generated by reviewing the raw qualitative data.
If you're adding a new code, changing a code descriptor, or dividing an existing code in half, ensure you review the wider code frame to determine whether this alteration will impact other feedback codes. Failure to do this may lead to similar responses at various points in the qualitative data, generating different codes while containing similar themes or insights.
Inductive coding is more thorough and takes longer than deductive coding, but offers a more unbiased and comprehensive overview of the themes within your data.
Deductive coding
This is a hierarchical approach to coding. In this method, you develop a codebook using your initial code frames. These frames may depend on an ongoing research theory or questions. Go over the data once again and filter data to different codes.
After generating your qualitative data, your codes must be a match for the code frame you began with. Program evaluation research could use this coding approach.
Inductive and deductive approaches
Research studies usually blend both inductive and deductive coding approaches. For instance, you may use a deductive approach for your initial set of code sets, and later use an inductive approach to generate fresh codes and recalibrate them while you review and analyze your data.
- What are the practical steps for coding qualitative data?
You can code qualitative data in the following ways:
1. Conduct your first-round pass at coding qualitative data
You need to review your data and assign codes to different pieces in this step. You don't have to generate the right codes since you will iterate and evolve them ahead of the second-round coding review.
Let's look at examples of the coding methods you may use in this step.
Open coding : This involves the distilling down of qualitative data into separate, distinct coded elements.
Descriptive coding : In this method, you create a description that encapsulates the data section’s content. Your code name must be a noun or a term that describes what the qualitative data relates to.
Values coding : This technique categorizes qualitative data that relates to the participant's attitudes, beliefs, and values.
Simultaneous coding : You can apply several codes to a single piece of qualitative data using this approach.
Structural coding : In this method, you can classify different parts of your qualitative data based on a predetermined design to perform additional analysis within the design.
In Vivo coding : Use this as the initial code to represent specific phrases or single words generated via a qualitative interview (i.e., specifically what the respondent said).
Process coding : A process of coding which captures action within data. Usually, this will be in the form of gerunds ending in “ing” (e.g., running, searching, reviewing).
2. Arrange your qualitative codes into groups and subcodes
You can start organizing codes into groups once you've completed your initial round of qualitative data coding. There are several ways to arrange these groups.
You can put together codes related to one another or address the same subjects or broad concepts, under each category. Continue working with these groups and rearranging the codes until you develop a framework that aligns with your analysis.
3. Conduct more rounds of qualitative coding
Conduct more iterations of qualitative data coding to review the codes and groups you've already established. You can change the names and codes, combine codes, and re-group the work you've already done during this phase.
In contrast, the initial attempt at data coding may have been hasty and haphazard. But these coding rounds focus on re-analyzing, identifying patterns, and drawing closer to creating concepts and ideas.
Below are a few techniques for qualitative data coding that are often applied in second-round coding.
Pattern coding : To describe a pattern, you join snippets of data, similarly classified under a single umbrella code.
Thematic analysis coding : When examining qualitative data, this method helps to identify patterns or themes.
Selective coding/focused coding : You can generate finished code sets and groups using your first pass of coding.
Theoretical coding : By classifying and arranging codes, theoretical coding allows you to create a theoretical framework's hypothesis. You develop a theory using the codes and groups that have been generated from the qualitative data.
Content analysis coding : This starts with an existing theory or framework and uses qualitative data to either support or expand upon it.
Axial coding : Axial coding allows you to link different codes or groups together. You're looking for connections and linkages between the information you discovered in earlier coding iterations.
Longitudinal coding : In this method, by organizing and systematizing your existing qualitative codes and categories, it is possible to monitor and measure them over time.
Elaborative coding : This involves applying a hypothesis from past research and examining how your present codes and groups relate to it.
4. Integrate codes and groups into your concluding narrative
When you finish going through several rounds of qualitative data coding and applying different forms of coding, use the generated codes and groups to build your final conclusions. The final result of your study could be a collection of findings, theory, or a description, depending on the goal of your study.
Start outlining your hypothesis , observations , and story while citing the codes and groups that served as its foundation. Create your final study results by structuring this data.
- What are the two methods of coding qualitative data?
You can carry out data coding in two ways: automatic and manual. Manual coding involves reading over each comment and manually assigning labels. You'll need to decide if you're using inductive or deductive coding.
Automatic qualitative data analysis uses a branch of computer science known as Natural Language Processing to transform text-based data into a format that computers can comprehend and assess. It's a cutting-edge area of artificial intelligence and machine learning that has the potential to alter how research and insight is designed and delivered.
Although automatic coding is faster than human coding, manual coding still has an edge due to human oversight and limitations in terms of computer power and analysis.
- What are the advantages of qualitative research coding?
Here are the benefits of qualitative research coding:
Boosts validity : gives your data structure and organization to be more certain the conclusions you are drawing from it are valid
Reduces bias : minimizes interpretation biases by forcing the researcher to undertake a systematic review and analysis of the data
Represents participants well : ensures your analysis reflects the views and beliefs of your participant pool and prevents you from overrepresenting the views of any individual or group
Fosters transparency : allows for a logical and systematic assessment of your study by other academics
- What are the challenges of qualitative research coding?
It would be best to consider theoretical and practical limitations while analyzing and interpreting data. Here are the challenges of qualitative research coding:
Labor-intensive: While you can use software for large-scale text management and recording, data analysis is often verified or completed manually.
Lack of reliability: Qualitative research is often criticized due to a lack of transparency and standardization in the coding and analysis process, being subject to a collection of researcher bias.
Limited generalizability : Detailed information on specific contexts is often gathered using small samples. Drawing generalizable findings is challenging even with well-constructed analysis processes as data may need to be more widely gathered to be genuinely representative of attitudes and beliefs within larger populations.
Subjectivity : It is challenging to reproduce qualitative research due to researcher bias in data analysis and interpretation. When analyzing data, the researchers make personal value judgments about what is relevant and what is not. Thus, different people may interpret the same data differently.
- What are the tips for coding qualitative data?
Here are some suggestions for optimizing the value of your qualitative research now that you are familiar with the fundamentals of coding qualitative data.
Keep track of your codes using a codebook or code frame
It can be challenging to recall all your codes offhand as you code more and more data. Keeping track of your codes in a codebook or code frame will keep you organized as you analyze the data. An Excel spreadsheet or word processing document might be your codebook's basic format.
Ensure you track:
The label applied to each code and the time it was first coded or modified
An explanation of the idea or subject matter that the code relates to
Who the original coder is
Any notes on the relationship between the code and other codes in your analysis
Add new codes to your codebook as you code new data, and rearrange categories and themes as necessary.
- How do you create high-quality codes?
Here are four useful tips to help you create high-quality codes.
1. Cover as many survey responses as possible
The code should be generic enough to aid your analysis while remaining general enough to apply to various comments. For instance, "product" is a general code that can apply to many replies but is also ambiguous.
Also, the specific statement, "product stops working after using it for 3 hours" is unlikely to apply to many answers. A good compromise might be "poor product quality" or "short product lifespan."
2. Avoid similarities
Having similar codes is acceptable only if they serve different objectives. While "product" and "customer service" differ from each other, "customer support" and "customer service" can be unified into a single code.
3. Take note of the positive and the negative
Establish contrasting codes to track an issue's negative and positive aspects separately. For instance, two codes to identify distinct themes would be "excellent customer service" and "poor customer service."
4. Minimize data—to a point
Try to balance having too many and too few codes in your analysis to make it as useful as possible.
What is the best way to code qualitative data?
Depending on the goal of your research, the procedure of coding qualitative data can vary. But generally, it entails:
Reading through your data
Assigning codes to selected passages
Carrying out several rounds of coding
Grouping codes into themes
Developing interpretations that result in your final research conclusions
You can begin by first coding snippets of text or data to summarize or characterize them and then add your interpretative perspective in the second round of coding.
A few techniques are more or less acceptable depending on your study’s goal; there is no right or incorrect way to code a data set.
What is an example of a code in qualitative research?
A code is, at its most basic level, a label specifying how you should read a text. The phrase, "Pigeons assaulted me and took my meal," is an illustration. You can use pigeons as a code word.
Is there coding in qualitative research?
An essential component of qualitative data analysis is coding. Coding aims to give structure to free-form data so one can systematically study it.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 18 April 2023
Last updated: 27 February 2023
Last updated: 22 August 2024
Last updated: 5 February 2023
Last updated: 16 August 2024
Last updated: 9 March 2023
Last updated: 30 April 2024
Last updated: 12 December 2023
Last updated: 11 March 2024
Last updated: 4 July 2024
Last updated: 6 March 2024
Last updated: 5 March 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next, log in or sign up.
Get started for free

The Ultimate Guide to Qualitative Research - Part 2: Handling Qualitative Data

- Handling qualitative data
- Transcripts
- Field notes
- Survey data and responses
- Visual and audio data
- Data organization
- Introduction
Qualitative data
Coding qualitative data, coding methods, using atlas.ti for qualitative data coding, automated coding tools in atlas.ti.
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative data analysis software
Coding qualitative data for valuable insights
Qualitative researchers, at one point or another, will inevitably find themselves involved in coding their data. The coding process can be arduous and time-consuming, so it's essential to understand how coding contributes to the understanding of knowledge in qualitative research .

Qualitative research tends to work with unstructured data that requires some systematic organization to facilitate insights relevant to your research inquiry. Suppose you need to determine the most critical aspects for deciding what hotel to stay in when you go on vacation. The decision process that goes into choosing the "best" hotel can be located in various and separate places (e.g., travel websites, blogs, personal conversations) and scattered among pieces of information that may not be relevant to you. In qualitative research, one of the goals prior to data analysis is to identify what information is important, find that information, and sort that information in a way that makes it easy for you to come to a decision.

Qualitative coding is almost always a necessary part of the qualitative data analysis process . Coding provides a way to make the meaning of the data clear to you and to your research audience.
What is a code?
A code in the context of qualitative data analysis is a summary of a larger segment of text. Imagine applying a couple of sticky notes to a collection of recipes, marking each section with short labels like "ingredients," "directions," and "advice." Afterward, someone can page through those recipes and easily locate the section they are looking for, thanks to those sticky notes.
Now, suppose you have different colors of sticky notes, where each color denotes a particular cuisine (e.g., Italian, Chinese, vegetarian). Now, with two ways to organize the data in front of you, you can look at all of the ingredient sections of all the recipes belonging to a cuisine to get a sense of the items that are commonly used for such recipes.
As illustrated in this example, one reason someone might apply sticky notes to a recipe is to help the reader save time in getting the desired information from that text, which is essentially the goal of qualitative coding. Coding allows a reader to get the information they are looking for to facilitate the analysis process. Moreover, this process of categorizing the different pieces of data helps researchers see what is going on in their data and identify emerging dimensions and patterns.
The use of codes also has a purpose beyond simply establishing a convenient means to draw meaning from the data . When presenting qualitative research to an audience, researchers could rely on a narrative summary of the data, but such narratives might be too lengthy to grasp or difficult to convey to others.
As a result, researchers in all fields tend to rely on data visualizations to illustrate their data analysis . Naturally, suppose such visualizations rely on tables and figures like bar charts and diagrams to convey meaning. In that case, researchers need to find ways to "count" the data along established data points, which is a role that coding can fulfill. While a strictly numerical understanding of qualitative research may overlook the finer aspects of social phenomena, researchers ultimately benefit from an analysis of the frequency of codes, combinations of codes, and patterns of codes that can contribute to theory generation. In addition, codes can be visualized in numerous ways to present qualitative insights. From flow charts to semantic networks, codes provide researchers with almost limitless possibilities in choosing how to present their rich qualitative data to different audiences.
Applying codes
To engage in coding, a researcher looks at the data line-by-line and develops a codebook by identifying data segments that can be represented by words or short phrases.

In the example above, a set of three paragraphs is represented by one code displayed in green in the right margin. Without codes, the researcher might have to re-read all of the text to remind themselves what the data is about. Indeed, any researcher who examines the codebook of a project can glean a sense of the data and analysis.
Analyzing codes
Think of a simple example to illustrate the importance of analyzing codes. Suppose you are analyzing survey responses for people's preferences for shopping in brick-and-mortar stores and shopping online. In that case, you might think about marking each survey response as either "prefers shopping in-person" or "prefers shopping online." Once you have applied the relevant codes to each survey response, you can compare the frequencies of both codes to determine where the population as a whole stands on the subject.
Among other things, codes can be analyzed by their frequency or their connection to other codes (or co-occurrence with other codes). In the example above, you may also decide to code the data for the reasons that inform people's shopping habits, applying labels such as "convenience," "value," and "service." Then, the analysis process is simply a matter of determining how often each reason co-occurs with preferences for in-person shopping and online shopping by analyzing the codes applied to the data.
As a result, qualitative coding transforms raw data into a form that facilitates the generation of deeper insights through empirical analysis.
That said, coding is a time-consuming, albeit necessary, task in qualitative research and one that researchers have developed into an array of established methods that are worth briefly looking at.
Years of development of qualitative research methods have yielded multiple methods for assigning codes to data. While all qualitative coding approaches essentially seek to summarize large amounts of information succinctly, there are various approaches you can apply to your coding process.
Inductive coding
Probably the most basic form of coding is to look at the data and reduce it to its salient points of information through coding. Any inductive approach to research involves generating knowledge from the ground up. Inductive coding, as a result, looks to generate insights from the qualitative data itself.
Inductive coding benefits researchers who need to look at the data primarily for its inherent meaning rather than for how external frameworks of knowledge might look at it. Inductive coding can also provide a new perspective that established theory has yet to consider, which would make a theory-driven approach inappropriate.
Deductive coding
A deductive approach to coding is also useful in qualitative research . In contrast with inductive coding, a deductive coding approach applies an existing research framework or previous research study to new data. This means that the researcher applies a set of predefined codes based on established research to the new data.
Researchers can benefit from using both approaches in tandem if their research questions call for a synthesized analysis . Returning to the example of a cookbook, a person may mark the different sections of each recipe because they have prior knowledge about what a typical recipe might look like. On the other hand, if they come across a non-typical recipe (e.g., a recipe that may not have an ingredients section), they might need to create new codes to identify parts of the recipe that seem unusual or novel.
Employing both inductive coding and deductive coding , as a result, can help you achieve a more holistic analysis of your data by building on existing knowledge of a phenomenon while generating new knowledge about the less familiar aspects.
Thematic analysis coding
Whether you decide to apply an inductive coding or deductive coding approach to qualitative data, the coding should also be relevant to your research inquiry in order to be useful and avoid a cumbersome amount of coding that might defeat the purpose of summarizing your data. Let's look at a series of more specific approaches to qualitative coding to get a wider sense of how coding has been applied to qualitative research.
The goal of a thematic analysis arising from coding , as the name suggests, is to identify themes revolving around a particular concept or phenomenon. While concepts in the natural sciences, such as temperature and atomic weight, can be measured with numerical data, concepts in the social sciences often escape easy numerical analysis. Rather than reduce the beauty of a work of art or proficiency in a foreign language down to a number, thematic analysis coding looks to describe these phenomena by various aspects that can be grouped together within common themes.
Looking at the recipe again, we can describe a typical recipe by the sections that appear the most often. The same is true for describing a sport (e.g., rules, strategies, equipment) or a car (e.g., type, price, fuel efficiency, safety rating). While later analysis might be able to numerically measure these themes if they are particular enough, the role of coding along the lines of themes provides a good starting point for recognizing and analyzing relevant concepts.
Process coding
Processes are phenomena that are characterized by action. Think about the act of driving a car rather than describing the car itself. In this case, process coding can be thought of as an extension of thematic coding, except that the major aspects of a process can also be identified by sequences and patterns, on the assumption that some actions may follow other actions. After all, drivers typically turn the key in the ignition before releasing the parking brake or shifting to drive. Capturing the specific phases and sequences is a key objective in process coding.
Structural coding
The "structure" of a recipe in a cookbook is different from that of an essay or a newspaper article. Also, think about how an interview for research might be structured differently from an interview for a TV news program. Researchers can employ structural coding to organize the data according to its distinct structural elements, such as specific elements, the ordering of information, or the purpose behind different structures. This kind of analysis could help, for instance, to achieve a greater understanding of how cultures shape a particular piece of writing or social practice.
Longitudinal coding
Studies that observe people or practices over time do so to capture and understand changes in dynamic environments. The role of longitudinal coding is to also code for relevant contextual or temporal aspects. These can then be analyzed together with other codes to assess how frequencies and patterns change from one observation or interview to the next. This will help researchers empirically illustrate differences or changes over time.

Whatever your approach, code your data with ATLAS.ti
Powerful tools for manual coding and automated coding. Check them out with a free trial.
Qualitative data analysis software should effectively facilitate qualitative coding. Researchers can choose between manual coding and automated coding , where tools can be employed to suggest and apply codes to save time. ATLAS.ti is ideal for both approaches to suit researchers of all needs and backgrounds.
Manual coding
At the core of any qualitative data analysis software is the interface that allows researchers the freedom of assigning codes to qualitative data . ATLAS.ti's interface for viewing data makes it easy to highlight data segments and apply new codes or existing codes quickly and efficiently.

In vivo coding
Interpreting qualitative data to create codes is often a part of the coding process. This can mean that the names of codes may differ from the actual text of the data itself.
However, the best names for codes sometimes come from the textual data itself, as opposed to some interpretation of the text. As a result, there may be a particular word or short phrase that stands out to you in your data set, compelling you to incorporate that word or phrase into your qualitative codes. Think about how social media has slang or acronyms like "YOLO" or "YMMV" which condense a lot of meaning or convey something of importance in the context of the research. Rather than obscuring participants’ meanings or experiences within another layer of interpretation, researchers can build meaningful and rich insights by using participants’ own words to create in vivo codes .

In vivo coding is a handy feature in ATLAS.ti for when you come across a key term or phrase that you want to create a code out of. Simply highlight the desired text and click on "Code in Vivo" to create a new code instantly.
Code Manager
One of the biggest challenges of coding qualitative data is keeping track of dozens or even hundreds of codes, because a lack of organization may hinder researchers in the main objective of succinctly summarizing qualitative data.

Once you have developed and applied a set of codes to your project data, you can open the Code Manager to gain a bird's eye view of all of your codes so you can develop and reorganize them, into hierarchies, groups, or however you prefer. Your list of codes can also be exported to share with others or use in other qualitative or quantitative analysis software .
Use ATLAS.ti for efficient and insightful coding
Intuitive tools to help you code and analyze your data, available starting with a free trial.
Traditionally, qualitative researchers would perform this coding on their data manually by hand, which involves carefully reading each piece of data and attaching codes. For qualitative researchers using pen and paper, they can use highlighters or bookmark flags to mark the key points in their data for later reference. Qualitative researchers also have powerful qualitative data analysis software they can rely on to facilitate all aspects of the coding process.

Although researchers can use qualitative data analysis software to engage in manual coding, there is also now a range of software tools that can even automate the coding process . A number of automated coding tools in ATLAS.ti such as AI Coding, Sentiment Analysis, and Opinion Mining use machine learning and natural language processing to apply useful codes for later analysis. Moreover, other tools in ATLAS.ti rely on pattern recognition to facilitate the creation of descriptive codes throughout your project.
One of the most exciting implications of recent advances in artificial intelligence is its potential for facilitating the research process, especially in qualitative research. The use of machine learning to understand the salient points in data can be especially useful to researchers in all fields.

AI Coding , available in both the Desktop platforms and Web version of ATLAS.ti, performs comprehensive descriptive coding on your qualitative data . It processes data through OpenAI's language models to suggest and apply codes to your project in a fraction of the time that it would take to do manually.
Sentiment Analysis
Participants may often express sentiments that are positive or negative in nature. If you are interested in analyzing the feelings expressed in your data, you can analyze these sentiments . To conduct automated coding for these sentiments, ATLAS.ti employs machine learning to process your data quickly and suggest codes to be applied to relevant data segments.

Opinion Mining
If you want to understand both what participants talked about and how they felt about it, you can conduct Opinion Mining. This tool synthesizes key phrases in your textual data according to whether they are being talked about in a positive or negative manner. The codes generated from Opinion Mining can provide a useful illustration of how language in interviews, focus groups, and surveys is used when discussing certain topics or phenomena.

Code qualitative data with ATLAS.ti
Download a free trial of ATLAS.ti and code your data with ease.
Coding Qualitative Data
- First Online: 02 January 2023
Cite this chapter

- Marla Rogers 4
Part of the book series: Springer Texts in Education ((SPTE))
6055 Accesses
1 Citations
With the advent and proliferation of analysis software (e.g., Nvivo, Atlas.ti), coding data has become much easier in terms of application. Where autocoding algorithms do much to assist and enlighten a researcher in analysis, coding qualitative data remains an act that must largely be undertaken by a human in order to fully address the research question(s) (Kaufmann, A. A., Barcomb, A., & Riehle, D. (2020). Supporting interview analysis with autocoding. HICSS. https://www.semanticscholar.org/paper/Supporting-Interview-Analysis-with-Autocoding-Kaufmann-Barcomb/b6e045859b5ce94e1eb144a9545b26c5e9fa6f32 ). Even seasoned qualitative researchers can find the process of coding their datum corpus to be arduous at times. For novice researchers, the task can quickly become baffling and overwhelming.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Analyzing Qualitative Data Using NVivo

Creating Inheritable Digital Codebooks for Qualitative Research Data Analysis

How We Code
Anonymous Author. (2019, July 2). Resolve: Finding a resolution for infertility: Infertility support group and discussion community [online discussion post]. https://www.inspire.com/
Basit, T. N. (2003). Manual or electronic? The role of coding in qualitative data analysis. Educational Research, 45 (2), 143–154.
Article Google Scholar
Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3 (2), 77–101.
Caulfield, J. (2019, September 6). How to do thematic analysis . www.scribbr.com/methodology/thematicanalysis
Creswell, J. (2015). 30 Essential skills for the qualitative researcher . SAGE.
Google Scholar
Elliot, V. (2018). Thinking about the coding process in qualitative data analysis. The Qualitative Report, 23 (11), 2850–2861. https://nsuworks.nova.edu/tqr/vol23/iss11/14
Kaufmann, A. A., Barcomb, A., & Riehle, D. (2020). Supporting interview analysis with autocoding. HICSS. https://www.semanticscholar.org/paper/Supporting-Interview-Analysis-with-Autocoding-Kaufmann-Barcomb/b6e045859b5ce94e1eb144a9545b26c5e9fa6f32
Saldana, J. (2009). The coding manual for qualitative researchers. SAGE.
Further Readings
Analyzing Qualitative Data: Nvivo 12 Pro for Windows (2 hours). https://www.youtube.com/watch?v=CKPS4LF9G8A
How to Analyze Interview Transcripts. (2 minutes). https://www.rev.com/blog/analyze-interview-transcripts-in-qualitative-research
How to Know You Are Coding Correctly (4 minutes). https://www.youtube.com/watch?v=iL7Ww5kpnIM
Download references
Author information
Authors and affiliations.
University of Saskatchewan, Saskatoon, Canada
Marla Rogers
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Marla Rogers .
Editor information
Editors and affiliations.
Department of Educational Administration, College of Education, University of Saskatchewan, Saskatoon, SK, Canada
Janet Mola Okoko
Scott Tunison
Department of Educational Administration, University of Saskatchewan, Saskatoon, SK, Canada
Keith D. Walker
Rights and permissions
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Rogers, M. (2023). Coding Qualitative Data. In: Okoko, J.M., Tunison, S., Walker, K.D. (eds) Varieties of Qualitative Research Methods. Springer Texts in Education. Springer, Cham. https://doi.org/10.1007/978-3-031-04394-9_12
Download citation
DOI : https://doi.org/10.1007/978-3-031-04394-9_12
Published : 02 January 2023
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-04396-3
Online ISBN : 978-3-031-04394-9
eBook Packages : Education Education (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research

Guide to Qualitative Data Coding: Best Analysis Methods
Qualitative data is where data becomes insights, and insights drive meaningful action. It's what enables qualitative data to shine, bringing context to life from customers eager to share their honest thoughts about your brand.
But without a plan to make sense of qualitative insights, they're at risk of collecting digital dust. That's where qualitative coding comes in.
In this guide, we're going to walk through how to do qualitative data analysis, so you can turn your qualitative data into the goldmine that it is – and then some.
Below, we'll explore:
Various qualitative data analysis methods
Types of qualitative data sources, and effective strategies for data collection
A walkthrough of the best qualitative coding methods by research goal
Let's dive in!
What is qualitative data coding?
Qualitative data coding is the process of analyzing and categorizing qualitative (non-numerical) data, such as interview transcripts, open-ended survey responses, or observational notes to arrive at patterns and themes.
Coding involves assigning descriptive labels or "codes" to segments of the qualitative data, to summarize and condense the information. Coding can be done inductively, where the codes emerge from the data itself, or deductively, where the researcher starts with a pre-determined set of codes based on existing theories or frameworks.
What's the benefit of qualitative data analysis?
Qualitative data dives into the intricacies of human experiences that quantitative data often overlooks. Qualitative research typically provides a deeper, more nuanced understanding of human behaviour, experiences, perceptions, and motivations. It can reveal the "why" and "how" behind the "what" that quantitative data shows.
Qualitative research is generally more flexible, and can be adapted to explore new or unexpected insights that emerge during the research process. It's a great tool that complements, and enhances quantitative research.

Types of qualitative data
Qualitative data comes in various forms. Each offers unique insights into different aspects of the human experience. Understanding the different types of qualitative data is the key to designing effective research methodologies, and strategies for your team to code qualitative data effectively.
Let’s explore some common types of qualitative data:
1. Textual Data
What it is: Written or verbal data in the form of transcripts, interviews, focus group discussions, open-ended survey responses, social media comments, emails, or customer reviews.
Advantages: Provides rich contextual information, sentiments, opinions, and narratives from direct interactions with customers or stakeholders.
2. Visual Data
What it is: Images, videos, diagrams, infographics, or any visual representation that captures non-verbal cues, gestures, emotions, or environmental contexts.
Advantages: Complements textual data by adding visual context and expressions that enhance the depth of qualitative insights.
3. Audio Data
What it is: Recordings of interviews, phone calls, focus group sessions, or any audio-based interactions.
Advantages: Captures tonal variations, emotions, and nuances in verbal communications, providing additional layers of understanding.
4. Observational Data
What it is: Direct observations of behaviours, interactions, or events in real-time settings such as ethnographic studies, field observations, or usability testing.
Advantages: Offers firsthand insights into natural behaviours, decision-making processes, and contextual factors influencing experiences.
5. Contextual Data
What it is: Information about the context, environment, culture, demographics, or situational factors influencing behaviours or perceptions.
Usage: Helps in interpreting qualitative findings within relevant contexts, identifying cultural nuances, and understanding environmental influences.
6. Metadata
Description: Additional data accompanying qualitative sources, such as timestamps, location information, participant demographics, or categorizations.
Advantages: Provides context, aids in organizing and filtering data, and supports comparative analysis across different segments or timeframes.
7. Historical Data
Description: Past records, archival materials, historical documents, or retrospective accounts relevant to the research topic.
Advantages: Offers historical perspectives, longitudinal insights, and continuity in understanding changes, trends, or patterns over time.
8. Digital Data
Description: Data generated from digital interactions, online platforms, websites, social media, digital surveys, or user-generated content.
Advantages: Reflects digital behaviours, user experiences, online sentiments, and interactions in virtual environments.
9. Multi-modal Data
Description: Integration of multiple data types such as textual, visual, audio, and contextual data sources for comprehensive analysis.
Advantages: Enables triangulation of findings, validation of insights across different modalities, and holistic understanding of complex phenomena.
10. Secondary Data
Description: Existing data sources, literature reviews, case studies, or research studies conducted by other researchers or organizations.
Advantages: Supplements primary qualitative data, provides comparative insights, validates findings, or offers historical context to research outcomes.
Understanding when, and how, to use each data type will elevate your overall research efforts. Thanks to the diversity of the data, you can lean on a handful of different forms to arrive at meaningful insights. This flexibility enables you to design robust data strategies that are closely aligned with research objectives.
But it also means, that you'll need a qualitative coding system to analyze the data consistently, to get the most out of your diverse findings.

How to collect qualitative data
Coding qualitative data effectively starts with having the right data to begin with. Here are a few common sources you can turn to to gather qualitative data for your research project:
Interviews: Conducting structured, semi-structured, or unstructured interviews with individuals or groups is a great way to start. With these you can gather in-depth insights about experiences, opinions, and perspectives. Interviews can be face-to-face, over the phone, or done with video calls.
Focus Groups: This involves bringing together a small group of participants to engage in discussions facilitated by a moderator. Focus groups allow researchers to explore group dynamics, shared experiences, and diverse viewpoints.
Surveys: Design open-ended survey questions to capture qualitative responses from respondents. Surveys can be distributed through email, online platforms, or in-person interviews to gather large volumes of qualitative data.
Observations: Arranging sessions to systematically observe and record behaviours in a particular setting is a great qualitative data source. Observations can be participant-based (the researcher actively participates) or non-participant (the researcher observes without interference).
Document Analysis: You can review existing documents, texts, artifacts, or media sources to extract qualitative insights from them. Documents could be written reports, social media posts, customer reviews, historical records, among other things.
Diaries or Journals: Ask participants to maintain personal diaries or journals to record their thoughts, experiences, and reflections over a specific period. Diaries provide rich, real-time qualitative data about daily life and emotions.
Ethnography: Immersing yourself in participants' natural environments or cultural contexts to observe social behaviours or norms. Ethnographic studies aim to gain deep cultural insights from a particular group.
Each insight collection method offers unique advantages and challenges when it comes to your research objectives.
The key in picking your method, is to align data types and collection with your research goals as much as possible to ensure the data is rich, and will remain relevant to your research questions.
What are the different types of coding?
Before we dive into the specifics around different methods to code qualitative data, let's start with the most basic understanding of research approaches. In general, there are two: inductive and deductive coding.
Inductive coding is ideal for exploratory research, when the goal is to develop new theories, ideas or concepts. It allows the data to speak for itself.
Deductive coding, on the other hand, is better suited when the researcher has a pre-determined structure or framework they need to fit the data into, such as in program evaluation or content analysis studies.
The key difference between these two approaches is that with deductive coding, you start with a framework of pre-established codes, which you use to label all the data that comes through your research project.

Deductive coding example
Say a researcher wanted to determine the answer to the research question –– what are the main factors that influence customer satisfaction with an e-commerce website?
Using deductive coding, you would develop a set of pre-determined codes based on existing theories and research on customer satisfaction with e-commerce websites. They might include, "website usability," "pricing," "product selection," or "customer service."
The researcher then collects the qualitative data, like customer interviews or open-ended survey responses about their experiences using the e-commerce website. The pre-defined codes provide a guide with which you would systematically categorize the data according to the most relevant category.
Once all the data is coded, you can analyze the frequency and relationships between the different codes to identify the key factors influencing customer satisfaction. You may find, for example, that website usability and shipping/delivery are the most prominent factors driving satisfaction.
This deductive approach helps in testing existing theories and frameworks around e-commerce customer satisfaction. It provides a structured way to analyze the data, and answer the research question.

Inductive coding example
Inductive coding operates with a different mindset when it comes to qualitative data analysis. Instead of starting with a pre-defined set of codes, the researcher reads through interview transcripts and begins to identify emerging themes and patterns in the data. This is distinct from the 'bottom-up' deductive approach.
Let's say your research question is –– what are the key factors that influence job satisfaction among software engineers?
With this approach, you could collect your qualitative data through interviews with software engineers to hear about their experiences and perceptions about job satisfaction. As you analyze your qualitative data, you start to identify pattern and themes from the data itself, capturing them into codes. These might be "work-life balance," "career development," or "team culture".
With inductive coding, the codes you use are grounded in the actual language and perspectives of the participants. The advantage here is that the data guides the analysis, rather than trying to fit the data into pre-existing assumptions or frameworks. This typically leads to better research outcomes, as real-world experiences and perspectives of the participants ground the insights.

Qualitative coding methods
Now that we know the main ways of assigning codes, let's dive a bit deeper to understand more granular methods.
When it comes to choosing a method to structure and analyze your data, your first criteria should be to align the method with your research goals. It's also worth noting that using multiple complementary methods (triangulation) can provide more robust analysis.
In this section, let's explore a range of qualitative coding methods. Each offers unique perspectives to help you unlock the most meaning from your qualitative data.
Thematic Analysis Coding
Thematic analysis coding is your go-to method when you want to uncover recurring patterns and themes across your qualitative data.
Imagine you're knee-deep in interview transcripts from customer feedback sessions. You start noticing phrases like "user-friendly interface" or "quick issue resolution" popping up frequently. These phrases are your themes. By coding them under relevant categories like "Ease of Use" or "Efficient Support," you're essentially organizing your data in a way that makes sense. This method works wonders when you have a large volume of qualitative data and need to distill it into manageable themes for deeper analysis.
Pattern Coding
Pattern coding is all about spotting and grouping similarly coded excerpts under one overarching code to describe a pattern.
Let's say you're analyzing customer reviews of a new mobile app. You notice phrases like "love the design but slow loading times" or "great features, needs smoother navigation." These phrases share a common thread—the balance between design and functionality. By creating a pattern code like "Design-Functionality Balance," you capture the essence of these comments without losing their individual insights. This method helps you identify trends or issues that might go unnoticed otherwise.
Focused/Selective Coding
Focused or selective coding comes into play when you've completed an initial round of "open coding" and need to refine your codes further.
Picture yourself swimming in a sea of codes derived from open-ended survey responses. You've identified several themes but want to narrow them down to the most relevant ones. Focused coding helps you create a finalized set of codes and categories based on your research objectives. This method is like streamlining your focus, ensuring that every code you use aligns directly with your study's purpose.
Axial Coding
Axial coding is your tool for connecting the dots between codes or categories, unveiling relationships and links within your data.
Imagine you've coded various customer sentiments about a product launch. Some codes relate to pricing satisfaction, while others focus on feature preferences. Axial coding helps you see how these codes intersect—are customers who like certain features more forgiving about pricing, or vice versa? This method dives deep into understanding the interconnectedness of different aspects of your qualitative data.
Theoretical Coding
Theoretical coding lets you build a conceptual framework by structuring codes and categories around emerging theories or concepts.
Imagine you're studying employee satisfaction in a company undergoing digital transformation. Your codes reveal sentiments about adapting to new tools, workload changes, and management support. Theoretical coding helps you map these codes to existing theories like Herzberg's Two-Factor Theory or Maslow's Hierarchy of Needs, adding layers of theoretical understanding to your qualitative analysis.
Elaborative Coding
Elaborative coding is about applying previous research theories or frameworks to your current data and observing how they align or differ.
Let's say your study on customer loyalty echoes findings from established loyalty models like the Loyalty Pyramid. Elaborative coding helps you validate these connections or identify nuances that existing models might overlook. It's like having a conversation between your data and established theories, enriching your analysis with broader industry perspectives.
Longitudinal Coding
Longitudinal coding is crucial when you're tracking changes or developments in qualitative data over time.
Imagine you're studying consumer perceptions of a brand across multiple years. Longitudinal coding allows you to compare sentiments, identify shifts in customer preferences, and track the impact of marketing campaigns or product changes. This method provides a dynamic view of your data's evolution, helping you stay current and adaptive in your research insights.

In Vivo Coding
In vivo coding involves summarizing passages into single words or phrases directly extracted from the data itself.
Say you're analyzing focus group transcripts about online shopping experiences. Participants mention phrases like "cart abandonment blues" or "scroll fatigue." In vivo coding captures the essence of these experiences using participants' own language. It's about letting your data speak for itself, preserving the authenticity and nuances of participants' voices.
Process Coding
Process coding uses gerund codes to describe actions or processes within your qualitative data.
For example, let's say you're studying customer support interactions. Your codes highlight actions like "resolving complaints," "escalating issues," or "navigating knowledge bases." Process coding helps you dissect complex interactions into actionable steps , making it easier to analyze workflows, identify bottlenecks, or pinpoint areas for improvement.
Open Coding
Open coding kicks off your qualitative analysis journey by allowing loose and tentative coding to identify emerging concepts or themes.
Imagine you're starting interviews for a market research project. Open qualitative coding lets you tag responses with codes like "price concerns," "product satisfaction," or "brand loyalty." It's like casting a wide net to capture diverse customer insights , setting the stage for more focused coding and deeper analysis down the road.

Qualitative data software tools
When it comes to qualitative research and doing qualitative data analysis , having the right tools can make all the difference.
There are a plethora of qualitative data analysis software available to help make interpretation a lot easier –– using both deductive and inductive coding techniques. The choice of your tools depends on the specific needs of your research project, your familiarity to navigate it, and the level of complexity required. Keep in mind that many researchers find it beneficial to use a combination of tools at different stages of the research process.
Below are some factors to consider when deciding on a tool:
Ability to code and categorize data (both inductively and deductively)
Tools for identifying themes, patterns, and relationships in the data
Visualization capabilities to help explore and present findings
Support for diverse data types (text, audio, video, images)
Collaboration and reporting capabilities
Ease of use and intuitive interface
Qualitative data coding is not just about assigning labels, it's about uncovering stories, emotions, and valuable insights hidden within your qualitative research data. By using a blend of the coding methods such as thematic analysis, pattern coding, and in vivo coding, your can get to the heart of your customers' narrative, and unearth ways to serve them better.
Ready to unlock the full potential of your qualitative research journey? Get the tools, techniques, and strategies you need with Kapiche –– eliminate costly manual coding, and achieve meaningful, inductive insights fast. Check out a demo of Kapiche today to explore how it can help.
You might also like

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 10: Qualitative Data Collection & Analysis Methods
10.6 Qualitative Coding, Analysis, and Write-up: The How to Guide
This section provides an abbreviated set of steps and directions for coding, analyzing, and writing up qualitative data, taking an inductive approach. The following material is adapted from Research Rundowns, retrieved from https://researchrundowns.com/qual/qualitative-coding-analysis/ .
Step 1: Open Coding
At this first level of coding, the researcher is looking for distinct concepts and categories in the data, which will form the basic units of the analysis. In other words, the researcher is breaking down the data into first level concepts, or master headings, and second-level categories, or subheadings.
Researchers often use highlighters to distinguish concepts and categories. For example, if interviewees consistently talk about teaching methods, each time an interviewee mentions teaching methods, or something related to a teaching method, the researcher uses the same colour highlight. Teaching methods would become a concept, and other things related (types, etc.) would become categories – all highlighted in the same colour. It is valuable to use different coloured highlights to distinguish each broad concept and category. At the end of this stage, the transcripts contain many different colours of highlighted text. The next step is to transfer these into a brief outline, with main headings for concepts and subheadings for categories.
Step 2: Axial (Focused) Coding
In open coding, the researcher is focused primarily on the text from the interviews to define concepts and categories. In axial coding, the researcher is using the concepts and categories developed in the open coding process, while re-reading the text from the interviews. This step is undertaken to confirm that the concepts and categories accurately represent interview responses.
In axial coding, the researcher explores how the concepts and categories are related. To examine the latter, you might ask: What conditions caused or influenced concepts and categories? What is/was the social/political context? What are the associated effects or consequences? For example, let us suppose that one of the concepts is Adaptive Teaching , and two of the categories are tutoring and group projects . The researcher would then ask: What conditions caused or influenced tutoring and group projects to occur? From the interview transcripts, it is apparent that participants linked this condition (being able to offer tutoring and group projects) with being enabled by a supportive principle. Consequently, an axial code might be a phrase like our principal encourages different teaching methods . This discusses the context of the concept and/or categories and suggests that the researcher may need a new category labeled “supportive environment.” Axial coding is merely a more directed approach to looking at the data, to help make sure that the researcher has identified all important aspects.
Step 3: Build a Data Table
Table 10.4 illustrates how to transfer the final concepts and categories into a data table. This is a very effective way to organize results and/or discussion in a research paper. While this appears to be a quick process, it requires a lot of time to do it well.
Table 10.4 Major categories and associated concept
| Open Coding | ||
| Axial Coding Themes | ||
| New Category | ||
Step 4: Analysis & Write-Up
Not only is Table 10.4 an effective way to organize the analysis, it is also a good approach for assisting with the data analysis write-up. The first step in the analysis process is to discuss the various categories and describe the associated concepts. As part of this process, the researcher will describe the themes created in the axial coding process (the second step).
There are a variety of ways to present the data in the write-up, including: 1) telling a story; 2) using a metaphor; 3) comparing and contrasting; 4) examining relations among concepts/variables; and 5) counting. Please note that counting should not be a stand-alone qualitative data analysis process to use when writing up the results, because it cannot convey the richness of the data that has been collected. One can certainly use counting for stating the number of participants, or how many participants spoke about a specific theme or category; however, the researcher must present a much deeper level of analysis by drawing out the words of the participants, including the use of direct quotes from the participants´ interviews to demonstrate the validity of the various themes.
Here are some resources for demonstrations on other methods for coding qualitative data:
- Qualitative Data Analysis [PDF]
When writing up the analysis, it is best to “identify” participants through a number, alphabetical letter, or pseudonym in the write-up (e.g. Participant #3 stated …). This demonstrates that you drawing data from all of the participants. Think of it this way, if you were doing quantitative analysis on data from 400 participants, you would present the data for all 400 participants, assuming they all answered a specific question. You will often see in a table of quantitative results (n=400), indicating that 400 people answered the question. This is the researcher’s way of confirming, to the reader, how many participants answered a particular research question. Assigning participant numbers, letters, or pseudonyms serves the same purpose in qualitative analysis.
Research Methods for the Social Sciences: An Introduction Copyright © 2020 by Valerie Sheppard is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Chapter 18. Data Analysis and Coding
Introduction.
Piled before you lie hundreds of pages of fieldnotes you have taken, observations you’ve made while volunteering at city hall. You also have transcripts of interviews you have conducted with the mayor and city council members. What do you do with all this data? How can you use it to answer your original research question (e.g., “How do political polarization and party membership affect local politics?”)? Before you can make sense of your data, you will have to organize and simplify it in a way that allows you to access it more deeply and thoroughly. We call this process coding . [1] Coding is the iterative process of assigning meaning to the data you have collected in order to both simplify and identify patterns. This chapter introduces you to the process of qualitative data analysis and the basic concept of coding, while the following chapter (chapter 19) will take you further into the various kinds of codes and how to use them effectively.
To those who have not yet conducted a qualitative study, the sheer amount of collected data will be a surprise. Qualitative data can be absolutely overwhelming—it may mean hundreds if not thousands of pages of interview transcripts, or fieldnotes, or retrieved documents. How do you make sense of it? Students often want very clear guidelines here, and although I try to accommodate them as much as possible, in the end, analyzing qualitative data is a bit more of an art than a science: “The process of bringing order, structure, and interpretation to a mass of collected data is messy, ambiguous, time-consuming, creative, and fascinating. It does not proceed in a linear fashion: it is not neat. At times, the researcher may feel like an eccentric and tormented artist; not to worry, this is normal” ( Marshall and Rossman 2016:214 ).
To complicate matters further, each approach (e.g., Grounded Theory, deep ethnography, phenomenology) has its own language and bag of tricks (techniques) when it comes to analysis. Grounded Theory, for example, uses in vivo coding to generate new theoretical insights that emerge from a rigorous but open approach to data analysis. Ethnographers, in contrast, are more focused on creating a rich description of the practices, behaviors, and beliefs that operate in a particular field. They are less interested in generating theory and more interested in getting the picture right, valuing verisimilitude in the presentation. And then there are some researchers who seek to account for the qualitative data using almost quantitative methods of analysis, perhaps counting and comparing the uses of certain narrative frames in media accounts of a phenomenon. Qualitative content analysis (QCA) often includes elements of counting (see chapter 17). For these researchers, having very clear hypotheses and clearly defined “variables” before beginning analysis is standard practice, whereas the same would be expressly forbidden by those researchers, like grounded theorists, taking a more emergent approach.
All that said, there are some helpful techniques to get you started, and these will be presented in this and the following chapter. As you become more of an expert yourself, you may want to read more deeply about the tradition that speaks to your research. But know that there are many excellent qualitative researchers that use what works for any given study, who take what they can from each tradition. Most of us find this permissible (but watch out for the methodological purists that exist among us).

Qualitative Data Analysis as a Long Process!
Although most of this and the following chapter will focus on coding, it is important to understand that coding is just one (very important) aspect of the long data-analysis process. We can consider seven phases of data analysis, each of which is important for moving your voluminous data into “findings” that can be reported to others. The first phase involves data organization. This might mean creating a special password-protected Dropbox folder for storing your digital files. It might mean acquiring computer-assisted qualitative data-analysis software ( CAQDAS ) and uploading all transcripts, fieldnotes, and digital files to its storage repository for eventual coding and analysis. Finding a helpful way to store your material can take a lot of time, and you need to be smart about this from the very beginning. Losing data because of poor filing systems or mislabeling is something you want to avoid. You will also want to ensure that you have procedures in place to protect the confidentiality of your interviewees and informants. Filing signed consent forms (with names) separately from transcripts and linking them through an ID number or other code that only you have access to (and store safely) are important.
Once you have all of your material safely and conveniently stored, you will need to immerse yourself in the data. The second phase consists of reading and rereading or viewing and reviewing all of your data. As you do this, you can begin to identify themes or patterns in the data, perhaps writing short memos to yourself about what you are seeing. You are not committing to anything in this third phase but rather keeping your eyes and mind open to what you see. In an actual study, you may very well still be “in the field” or collecting interviews as you do this, and what you see might push you toward either concluding your data collection or expanding so that you can follow a particular group or factor that is emerging as important. For example, you may have interviewed twelve international college students about how they are adjusting to life in the US but realized as you read your transcripts that important gender differences may exist and you have only interviewed two women (and ten men). So you go back out and make sure you have enough female respondents to check your impression that gender matters here. The seven phases do not proceed entirely linearly! It is best to think of them as recursive; conceptually, there is a path to follow, but it meanders and flows.
Coding is the activity of the fourth phase . The second part of this chapter and all of chapter 19 will focus on coding in greater detail. For now, know that coding is the primary tool for analyzing qualitative data and that its purpose is to both simplify and highlight the important elements buried in mounds of data. Coding is a rigorous and systematic process of identifying meaning, patterns, and relationships. It is a more formal extension of what you, as a conscious human being, are trained to do every day when confronting new material and experiences. The “trick” or skill is to learn how to take what you do naturally and semiconsciously in your mind and put it down on paper so it can be documented and verified and tested and refined.
At the conclusion of the coding phase, your material will be searchable, intelligible, and ready for deeper analysis. You can begin to offer interpretations based on all the work you have done so far. This fifth phase might require you to write analytic memos, beginning with short (perhaps a paragraph or two) interpretations of various aspects of the data. You might then attempt stitching together both reflective and analytical memos into longer (up to five pages) general interpretations or theories about the relationships, activities, patterns you have noted as salient.
As you do this, you may be rereading the data, or parts of the data, and reviewing your codes. It’s possible you get to this phase and decide you need to go back to the beginning. Maybe your entire research question or focus has shifted based on what you are now thinking is important. Again, the process is recursive , not linear. The sixth phase requires you to check the interpretations you have generated. Are you really seeing this relationship, or are you ignoring something important you forgot to code? As we don’t have statistical tests to check the validity of our findings as quantitative researchers do, we need to incorporate self-checks on our interpretations. Ask yourself what evidence would exist to counter your interpretation and then actively look for that evidence. Later on, if someone asks you how you know you are correct in believing your interpretation, you will be able to explain what you did to verify this. Guard yourself against accusations of “ cherry-picking ,” selecting only the data that supports your preexisting notion or expectation about what you will find. [2]
The seventh and final phase involves writing up the results of the study. Qualitative results can be written in a variety of ways for various audiences (see chapter 20). Due to the particularities of qualitative research, findings do not exist independently of their being written down. This is different for quantitative research or experimental research, where completed analyses can somewhat speak for themselves. A box of collected qualitative data remains a box of collected qualitative data without its written interpretation. Qualitative research is often evaluated on the strength of its presentation. Some traditions of qualitative inquiry, such as deep ethnography, depend on written thick descriptions, without which the research is wholly incomplete, even nonexistent. All of that practice journaling and writing memos (reflective and analytical) help develop writing skills integral to the presentation of the findings.
Remember that these are seven conceptual phases that operate in roughly this order but with a lot of meandering and recursivity throughout the process. This is very different from quantitative data analysis, which is conducted fairly linearly and processually (first you state a falsifiable research question with hypotheses, then you collect your data or acquire your data set, then you analyze the data, etc.). Things are a bit messier when conducting qualitative research. Embrace the chaos and confusion, and sort your way through the maze. Budget a lot of time for this process. Your research question might change in the middle of data collection. Don’t worry about that. The key to being nimble and flexible in qualitative research is to start thinking and continue thinking about your data, even as it is being collected. All seven phases can be started before all the data has been gathered. Data collection does not always precede data analysis. In some ways, “qualitative data collection is qualitative data analysis.… By integrating data collection and data analysis, instead of breaking them up into two distinct steps, we both enrich our insights and stave off anxiety. We all know the anxiety that builds when we put something off—the longer we put it off, the more anxious we get. If we treat data collection as this mass of work we must do before we can get started on the even bigger mass of work that is analysis, we set ourselves up for massive anxiety” ( Rubin 2021:182–183 ; emphasis added).
The Coding Stage
A code is “a word or short phrase that symbolically assigns a summative, salient, essence-capturing, and/or evocative attribute for a portion of language-based or visual data” ( Saldaña 2014:5 ). Codes can be applied to particular sections of or entire transcripts, documents, or even videos. For example, one might code a video taken of a preschooler trying to solve a puzzle as “puzzle,” or one could take the transcript of that video and highlight particular sections or portions as “arranging puzzle pieces” (a descriptive code) or “frustration” (a summative emotion-based code). If the preschooler happily shouts out, “I see it!” you can denote the code “I see it!” (this is an example of an in vivo, participant-created code). As one can see from even this short example, there are many different kinds of codes and many different strategies and techniques for coding, more of which will be discussed in detail in chapter 19. The point to remember is that coding is a rigorous systematic process—to some extent, you are always coding whenever you look at a person or try to make sense of a situation or event, but you rarely do this consciously. Coding is the process of naming what you are seeing and how you are simplifying the data so that you can make sense of it in a way that is consistent with your study and in a way that others can understand and follow and replicate. Another way of saying this is that a code is “a researcher-generated interpretation that symbolizes or translates data” ( Vogt et al. 2014:13 ).
As with qualitative data analysis generally, coding is often done recursively, meaning that you do not merely take one pass through the data to create your codes. Saldaña ( 2014 ) differentiates first-cycle coding from second-cycle coding. The goal of first-cycle coding is to “tag” or identify what emerges as important codes. Note that I said emerges—you don’t always know from the beginning what will be an important aspect of the study or not, so the coding process is really the place for you to begin making the kinds of notes necessary for future analyses. In second-cycle coding, you will want to be much more focused—no longer gathering wholly new codes but synthesizing what you have into metacodes.
You might also conceive of the coding process in four parts (figure 18.1). First, identify a representative or diverse sample set of interview transcripts (or fieldnotes or other documents). This is the group you are going to use to get a sense of what might be emerging. In my own study of career obstacles to success among first-generation and working-class persons in sociology, I might select one interview from each career stage: a graduate student, a junior faculty member, a senior faculty member.
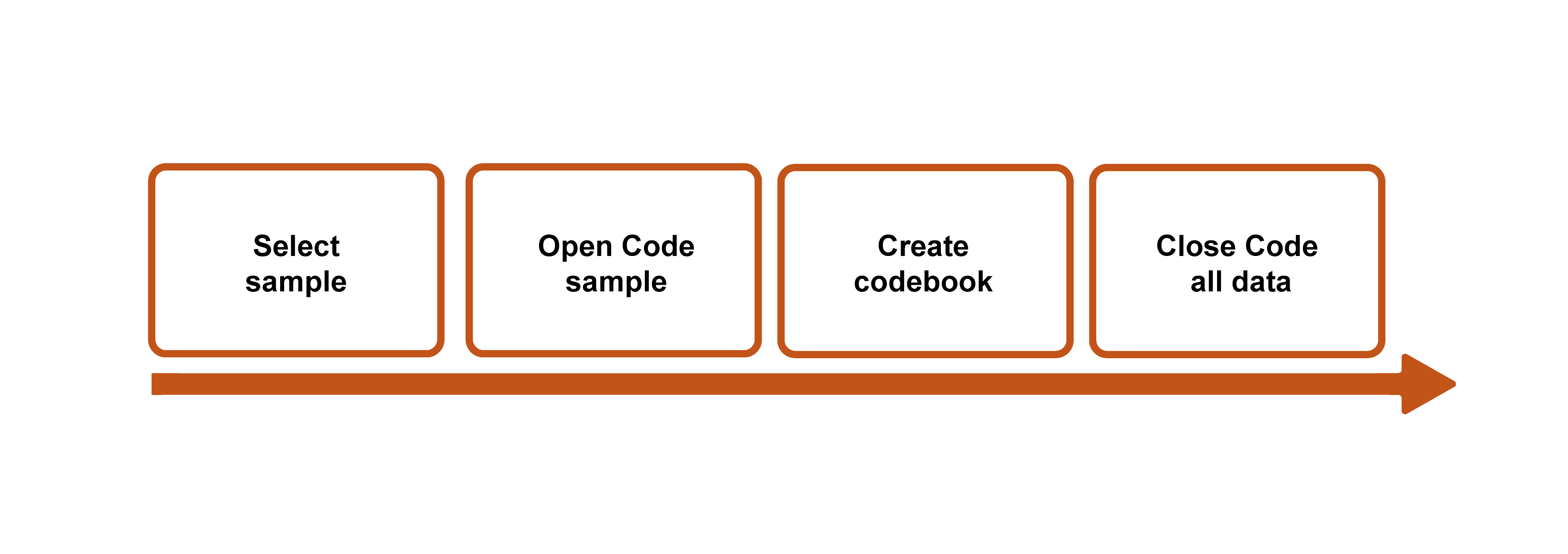
Second, code everything (“ open coding ”). See what emerges, and don’t limit yourself in any way. You will end up with a ton of codes, many more than you will end up with, but this is an excellent way to not foreclose an interesting finding too early in the analysis. Note the importance of starting with a sample of your collected data, because otherwise, open coding all your data is, frankly, impossible and counterproductive. You will just get stuck in the weeds.
Third, pare down your coding list. Where you may have begun with fifty (or more!) codes, you probably want no more than twenty remaining. Go back through the weeds and pull out everything that does not have the potential to bloom into a nicely shaped garden. Note that you should do this before tackling all of your data . Sometimes, however, you might need to rethink the sample you chose. Let’s say that the graduate student interview brought up some interesting gender issues that were pertinent to female-identifying sociologists, but both the junior and the senior faculty members identified as male. In that case, I might read through and open code at least one other interview transcript, perhaps a female-identifying senior faculty member, before paring down my list of codes.
This is also the time to create a codebook if you are using one, a master guide to the codes you are using, including examples (see Sample Codebooks 1 and 2 ). A codebook is simply a document that lists and describes the codes you are using. It is easy to forget what you meant the first time you penciled a coded notation next to a passage, so the codebook allows you to be clear and consistent with the use of your codes. There is not one correct way to create a codebook, but generally speaking, the codebook should include (1) the code (either name or identification number or both), (2) a description of what the code signifies and when and where it should be applied, and (3) an example of the code to help clarify (2). Listing all the codes down somewhere also allows you to organize and reorganize them, which can be part of the analytical process. It is possible that your twenty remaining codes can be neatly organized into five to seven master “themes.” Codebooks can and should develop as you recursively read through and code your collected material. [3]
Fourth, using the pared-down list of codes (or codebook), read through and code all the data. I know many qualitative researchers who work without a codebook, but it is still a good practice, especially for beginners. At the very least, read through your list of codes before you begin this “ closed coding ” step so that you can minimize the chance of missing a passage or section that needs to be coded. The final step is…to do it all again. Or, at least, do closed coding (step four) again. All of this takes a great deal of time, and you should plan accordingly.
Researcher Note
People often say that qualitative research takes a lot of time. Some say this because qualitative researchers often collect their own data. This part can be time consuming, but to me, it’s the analytical process that takes the most time. I usually read every transcript twice before starting to code, then it usually takes me six rounds of coding until I’m satisfied I’ve thoroughly coded everything. Even after the coding, it usually takes me a year to figure out how to put the analysis together into a coherent argument and to figure out what language to use. Just deciding what name to use for a particular group or idea can take months. Understanding this going in can be helpful so that you know to be patient with yourself.
—Jessi Streib, author of The Power of the Past and Privilege Lost
Note that there is no magic in any of this, nor is there any single “right” way to code or any “correct” codes. What you see in the data will be prompted by your position as a researcher and your scholarly interests. Where the above codes on a preschooler solving a puzzle emerged from my own interest in puzzle solving, another researcher might focus on something wholly different. A scholar of linguistics, for example, may focus instead on the verbalizations made by the child during the discovery process, perhaps even noting particular vocalizations (incidence of grrrs and gritting of the teeth, for example). Your recording of the codes you used is the important part, as it allows other researchers to assess the reliability and validity of your analyses based on those codes. Chapter 19 will provide more details about the kinds of codes you might develop.
Saldaña ( 2014 ) lists seven “necessary personal attributes” for successful coding. To paraphrase, they are the following:
- Having (or practicing) good organizational skills
- Perseverance
- The ability and willingness to deal with ambiguity
- Flexibility
- Creativity, broadly understood, which includes “the ability to think visually, to think symbolically, to think in metaphors, and to think of as many ways as possible to approach a problem” (20)
- Commitment to being rigorously ethical
- Having an extensive vocabulary [4]
Writing Analytic Memos during/after Coding
Coding the data you have collected is only one aspect of analyzing it. Too many beginners have coded their data and then wondered what to do next. Coding is meant to help organize your data so that you can see it more clearly, but it is not itself an analysis. Thinking about the data, reviewing the coded data, and bringing in the previous literature (here is where you use your literature review and theory) to help make sense of what you have collected are all important aspects of data analysis. Analytic memos are notes you write to yourself about the data. They can be short (a single page or even a paragraph) or long (several pages). These memos can themselves be the subject of subsequent analytic memoing as part of the recursive process that is qualitative data analysis.
Short analytic memos are written about impressions you have about the data, what is emerging, and what might be of interest later on. You can write a short memo about a particular code, for example, and why this code seems important and where it might connect to previous literature. For example, I might write a paragraph about a “cultural capital” code that I use whenever a working-class sociologist says anything about “not fitting in” with their peers (e.g., not having the right accent or hairstyle or private school background). I could then write a little bit about Bourdieu, who originated the notion of cultural capital, and try to make some connections between his definition and how I am applying it here. I can also use the memo to raise questions or doubts I have about what I am seeing (e.g., Maybe the type of school belongs somewhere else? Is this really the right code?). Later on, I can incorporate some of this writing into the theory section of my final paper or article. Here are some types of things that might form the basis of a short memo: something you want to remember, something you noticed that was new or different, a reaction you had, a suspicion or hunch that you are developing, a pattern you are noticing, any inferences you are starting to draw. Rubin ( 2021 ) advises, “Always include some quotation or excerpt from your dataset…that set you off on this idea. It’s happened to me so many times—I’ll have a really strong reaction to a piece of data, write down some insight without the original quotation or context, and then [later] have no idea what I was talking about and have no way of recreating my insight because I can’t remember what piece of data made me think this way” ( 203 ).
All CAQDAS programs include spaces for writing, generating, and storing memos. You can link a memo to a particular transcript, for example. But you can just as easily keep a notebook at hand in which you write notes to yourself, if you prefer the more tactile approach. Drawing pictures that illustrate themes and patterns you are beginning to see also works. The point is to write early and write often, as these memos are the building blocks of your eventual final product (chapter 20).
In the next chapter (chapter 19), we will go a little deeper into codes and how to use them to identify patterns and themes in your data. This chapter has given you an idea of the process of data analysis, but there is much yet to learn about the elements of that process!
Qualitative Data-Analysis Samples
The following three passages are examples of how qualitative researchers describe their data-analysis practices. The first, by Harvey, is a useful example of how data analysis can shift the original research questions. The second example, by Thai, shows multiple stages of coding and how these stages build upward to conceptual themes and theorization. The third example, by Lamont, shows a masterful use of a variety of techniques to generate theory.
Example 1: “Look Someone in the Eye” by Peter Francis Harvey ( 2022 )
I entered the field intending to study gender socialization. However, through the iterative process of writing fieldnotes, rereading them, conducting further research, and writing extensive analytic memos, my focus shifted. Abductive analysis encourages the search for unexpected findings in light of existing literature. In my early data collection, fieldnotes, and memoing, classed comportment was unmistakably prominent in both schools. I was surprised by how pervasive this bodily socialization proved to be and further surprised by the discrepancies between the two schools.…I returned to the literature to compare my empirical findings.…To further clarify patterns within my data and to aid the search for disconfirming evidence, I constructed data matrices (Miles, Huberman, and Saldaña 2013). While rereading my fieldnotes, I used ATLAS.ti to code and recode key sections (Miles et al. 2013), punctuating this process with additional analytic memos. ( 2022:1420 )
Example 2:” Policing and Symbolic Control” by Mai Thai ( 2022 )
Conventional to qualitative research, my analyses iterated between theory development and testing. Analytical memos were written throughout the data collection, and my analyses using MAXQDA software helped me develop, confirm, and challenge specific themes.…My early coding scheme which included descriptive codes (e.g., uniform inspection, college trips) and verbatim codes of the common terms used by field site participants (e.g., “never quit,” “ghetto”) led me to conceptualize valorization. Later analyses developed into thematic codes (e.g., good citizens, criminality) and process codes (e.g., valorization, criminalization), which helped refine my arguments. ( 2022:1191–1192 )
Example 3: The Dignity of Working Men by Michèle Lamont ( 2000 )
To analyze the interviews, I summarized them in a 13-page document including socio-demographic information as well as information on the boundary work of the interviewees. To facilitate comparisons, I noted some of the respondents’ answers on grids and summarized these on matrix displays using techniques suggested by Miles and Huberman for standardizing and processing qualitative data. Interviews were also analyzed one by one, with a focus on the criteria that each respondent mobilized for the evaluation of status. Moreover, I located each interviewee on several five-point scales pertaining to the most significant dimensions they used to evaluate status. I also compared individual interviewees with respondents who were similar to and different from them, both within and across samples. Finally, I classified all the transcripts thematically to perform a systematic analysis of all the important themes that appear in the interviews, approaching the latter as data against which theoretical questions can be explored. ( 2000:256–257 )
Sample Codebook 1
This is an abridged version of the codebook used to analyze qualitative responses to a question about how class affects careers in sociology. Note the use of numbers to organize the flow, supplemented by highlighting techniques (e.g., bolding) and subcoding numbers.
01. CAPS: Any reference to “capitals” in the response, even if the specific words are not used
01.1: cultural capital 01.2: social capital 01.3: economic capital
(can be mixed: “0.12”= both cultural and asocial capital; “0.23”= both social and economic)
01. CAPS: a reference to “capitals” in which the specific words are used [ bold : thus, 01.23 means that both social capital and economic capital were mentioned specifically
02. DEBT: discussion of debt
02.1: mentions personal issues around debt 02.2: discusses debt but in the abstract only (e.g., “people with debt have to worry”)
03. FirstP: how the response is positioned
03.1: neutral or abstract response 03.2: discusses self (“I”) 03.3: discusses others (“they”)
Sample Coded Passage:
| “I was really hurt when I didn’t get that scholarship. It was going to cost me thousands of dollars to stay in the program, and I was going to have to borrow all of it. My faculty advisor wasn’t helpful at all. They told | 03.2 |
| me not to worry about it, because it wasn’t really that much money! I almost fell over when they said that! Like, do they not understand what it’s like to be poor? I just felt so isolated then. I was on my own. | 02.1. 01.3 |
| I couldn’t talk to anyone about it, because no one else seemed to worry about it. Talk about economic capital!” |
* Question: What other codes jump out to you here? Shouldn’t there be a code for feelings of loneliness or alienation? What about an emotions code ?
Sample Codebook 2
| CODE | DEFINITION | WHEN TO APPLY | IN VIVO EXAMPLE |
|---|---|---|---|
| ALIENATION | Feeling out of place in academia | Any time uses the word alienation or impostor syndrome or feeling out of place | “I was so lonely in graduate school. It was an alienating experience.” |
| CULTURAL CAPITAL | Knowledge or other cultural resources that affect success in academia | When “cultural capital” is used but also when knowledge or lack of knowledge about cultural things are discussed | “We went to a fancy restaurant after my job interview and I was paralyzed with fear because I did not know which fork I was supposed to be using. Yikes!” |
| SOCIAL CAPITAL | Social networks that advance success in academia | When “social capital” is used but also when social networks are discussed or knowing the right people | “I didn’t know who to turn to. It seemed like everyone else had parents who could help them and I didn’t know anyone else who had ever even gone to college!” |
This is an example that uses "word" categories only, with descriptions and examples for each code
Further Readings
Elliott, Victoria. 2018. “Thinking about the Coding Process in Qualitative Analysis.” Qualitative Report 23(11):2850–2861. Address common questions those new to coding ask, including the use of “counting” and how to shore up reliability.
Friese, Susanne. 2019. Qualitative Data Analysis with ATLAS.ti. 3rd ed. A good guide to ATLAS.ti, arguably the most used CAQDAS program. Organized around a series of “skills training” to get you up to speed.
Jackson, Kristi, and Pat Bazeley. 2019. Qualitative Data Analysis with NVIVO . 3rd ed. Thousand Oaks, CA: SAGE. If you want to use the CAQDAS program NVivo, this is a good affordable guide to doing so. Includes copious examples, figures, and graphic displays.
LeCompte, Margaret D. 2000. “Analyzing Qualitative Data.” Theory into Practice 39(3):146–154. A very practical and readable guide to the entire coding process, with particular applicability to educational program evaluation/policy analysis.
Miles, Matthew B., and A. Michael Huberman. 1994. Qualitative Data Analysis: An Expanded Sourcebook . 2nd ed. Thousand Oaks, CA: SAGE. A classic reference on coding. May now be superseded by Miles, Huberman, and Saldaña (2019).
Miles, Matthew B., A. Michael Huberman, and Johnny Saldaña. 2019. Qualitative Data Analysis: A Methods Sourcebook . 4th ed. Thousand Oaks, CA; SAGE. A practical methods sourcebook for all qualitative researchers at all levels using visual displays and examples. Highly recommended.
Saldaña, Johnny. 2014. The Coding Manual for Qualitative Researchers . 2nd ed. Thousand Oaks, CA: SAGE. The most complete and comprehensive compendium of coding techniques out there. Essential reference.
Silver, Christina. 2014. Using Software in Qualitative Research: A Step-by-Step Guide. 2nd ed. Thousand Oaks, CA; SAGE. If you are unsure which CAQDAS program you are interested in using or want to compare the features and usages of each, this guidebook is quite helpful.
Vogt, W. Paul, Elaine R. Vogt, Diane C. Gardner, and Lynne M. Haeffele2014. Selecting the Right Analyses for Your Data: Quantitative, Qualitative, and Mixed Methods . New York: The Guilford Press. User-friendly reference guide to all forms of analysis; may be particularly helpful for those engaged in mixed-methods research.
- When you have collected content (historical, media, archival) that interests you because of its communicative aspect, content analysis (chapter 17) is appropriate. Whereas content analysis is both a research method and a tool of analysis, coding is a tool of analysis that can be used for all kinds of data to address any number of questions. Content analysis itself includes coding. ↵
- Scientific research, whether quantitative or qualitative, demands we keep an open mind as we conduct our research, that we are “neutral” regarding what is actually there to find. Students who are trained in non-research-based disciplines such as the arts or philosophy or who are (admirably) focused on pursuing social justice can too easily fall into the trap of thinking their job is to “demonstrate” something through the data. That is not the job of a researcher. The job of a researcher is to present (and interpret) findings—things “out there” (even if inside other people’s hearts and minds). One helpful suggestion: when formulating your research question, if you already know the answer (or think you do), scrap that research. Ask a question to which you do not yet know the answer. ↵
- Codebooks are particularly useful for collaborative research so that codes are applied and interpreted similarly. If you are working with a team of researchers, you will want to take extra care that your codebooks remain in synch and that any refinements or developments are shared with fellow coders. You will also want to conduct an “intercoder reliability” check, testing whether the codes you have developed are clearly identifiable so that multiple coders are using them similarly. Messy, unclear codes that can be interpreted differently by different coders will make it much more difficult to identify patterns across the data. ↵
- Note that this is important for creating/denoting new codes. The vocabulary does not need to be in English or any particular language. You can use whatever words or phrases capture what it is you are seeing in the data. ↵
A first-cycle coding process in which gerunds are used to identify conceptual actions, often for the purpose of tracing change and development over time. Widely used in the Grounded Theory approach.
A first-cycle coding process in which terms or phrases used by the participants become the code applied to a particular passage. It is also known as “verbatim coding,” “indigenous coding,” “natural coding,” “emic coding,” and “inductive coding,” depending on the tradition of inquiry of the researcher. It is common in Grounded Theory approaches and has even given its name to one of the primary CAQDAS programs (“NVivo”).
Computer-assisted qualitative data-analysis software. These are software packages that can serve as a repository for qualitative data and that enable coding, memoing, and other tools of data analysis. See chapter 17 for particular recommendations.
The purposeful selection of some data to prove a preexisting expectation or desired point of the researcher where other data exists that would contradict the interpretation offered. Note that it is not cherry picking to select a quote that typifies the main finding of a study, although it would be cherry picking to select a quote that is atypical of a body of interviews and then present it as if it is typical.
A preliminary stage of coding in which the researcher notes particular aspects of interest in the data set and begins creating codes. Later stages of coding refine these preliminary codes. Note: in Grounded Theory , open coding has a more specific meaning and is often called initial coding : data are broken down into substantive codes in a line-by-line manner, and incidents are compared with one another for similarities and differences until the core category is found. See also closed coding .
A set of codes, definitions, and examples used as a guide to help analyze interview data. Codebooks are particularly helpful and necessary when research analysis is shared among members of a research team, as codebooks allow for standardization of shared meanings and code attributions.
The final stages of coding after the refinement of codes has created a complete list or codebook in which all the data is coded using this refined list or codebook. Compare to open coding .
A first-cycle coding process in which emotions and emotionally salient passages are tagged.
Introduction to Qualitative Research Methods Copyright © 2023 by Allison Hurst is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
The Coding Manual for Qualitative Researchers
Student resources.
Welcome to the companion website for The Coding Manual for Qualitative Research , third edition, by Johnny Saldaña. This website offers a wealth of additional resources to support students and lecturers including:
CAQDAS links giving guidance and links to a variety of qualitative data analysis software.
Code lists including data extracted from the author’s study, “Lifelong Learning Impact: Adult Perceptions of Their High School Speech and/or Theatre Participation” (McCammon, Saldaña, Hines, & Omasta, 2012), which you can download and make your own practice manipulations to the data.
Coding examples from SAGE journals providing actual examples of coding at work, giving you insight into coding procedures.
Three sample interview transcripts that allow you to test your coding skills.
Group exercises for small and large groups encourage you to get to grips with basic principles of coding, partner development, categorization and qualitative data analysis
Flashcard glossary of terms enables you to test your knowledge of the terminology commonly used in qualitative research and coding.
About the book
Johnny Saldaña’s unique and invaluable manual demystifies the qualitative coding process with a comprehensive assessment of different coding types, examples and exercises. The ideal reference for students, teachers, and practitioners of qualitative inquiry, it is essential reading across the social sciences and neatly guides you through the multiple approaches available for coding qualitative data.
Its wide array of strategies, from the more straightforward to the more complex, is skilfully explained and carefully exemplified, providing a complete toolkit of codes and skills that can be applied to any research project. For each code Saldaña provides information about the method's origin, gives a detailed description of the method, demonstrates its practical applications, and sets out a clearly illustrated example with analytic follow up.
This international bestseller is an extremely usable, robust manual and is a must-have resource for qualitative researchers at all levels.
This website may contain links to both internal and external websites. All links included were active at the time the website was launched. SAGE does not operate these external websites and does not necessarily endorse the views expressed within them. SAGE cannot take responsibility for the changing content or nature of linked sites, as these sites are outside of our control and subject to change without our knowledge. If you do find an inactive link to an external website, please try to locate that website by using a search engine. SAGE will endeavour to update inactive or broken links when possible.

Qualitative Coding Examples
Real-world examples of process, values and in vivo coding
By: Derek Jansen (MBA) | Reviewers: Dr Eunice Rautenbach | May 2024

We’ve spoken about qualitative coding approaches and techniques quite extensively, but this is one of those topics that can feel a little conceptual and fluffy at times. So, in this post, we’ll walk through some practical examples of textual data that’s been coded using various techniques, including process , values and in vivo coding.
Overview: Coding Examples
- Qualitative coding 101
- Example: Process coding
- Example: Values coding
- Example: In vivo coding
How to fast-track your coding
Qualitative coding 101.
Before we jump into examples of various qualitative coding techniques, it’s useful to quickly define what exactly we mean by “qualitative coding”.
Simply put, qualitative coding is the process of systematically assigning labels (codes) to segments of qualitative data (usually text). These codes capture key concepts, ideas, or patterns within the data. By organising and categorising the data in this way, we lay the foundation for qualitative analysis (for example, thematic analysis or content analysis). So, coding is an essential foundational step in the analysis process.
At a high level, coding can be approached inductively (bottom up), deductively (top down) or abductively (a hybrid approach). In the video below, we unpack and explain these three approaches in simple terms.
Process Coding Example
With process coding, the focus is on actions and behaviours . This coding technique helps us understand not just what people say, but how they interact and behave, providing deeper insights into their experiences.
Let’s look at an example of how a transcript could be coded using process coding.
Interviewer :
Can you describe a typical day at your job?
Interviewee :
Sure! I usually start my day by checking emails. After that, I have a team meeting where we discuss our goals for the day. Once the meeting is over, I work on my tasks, which often involves coordinating with different departments. Around lunchtime, I take a break and then continue with my work, usually focusing on completing projects or attending additional meetings. Before I leave, I review my work and plan for the next day.
For this extract, we might code as follows:

As you can see, each code represents a distinct action or process the interviewee engages in during a typical workday. Therefore, this coding approach could be very useful for research aims and questions that involve understanding the workflow and identifying patterns in the interviewee’s activities.

Example: Values Coding
As the name suggests, values coding involves identifying and coding the values, beliefs, and attitudes expressed by participants. This coding technique can help us understand the underlying principles and motivations guiding participants’ behaviours and decisions.
Let’s look at a practical example.
What motivates you to stay in your current job?
A few things. I find a lot of satisfaction in helping my team grow and succeed. Seeing their progress and knowing I contributed to their development is incredibly rewarding. I also value the flexibility my job offers, which allows me to balance my work and personal life.
The company’s commitment to innovation and continuous improvement aligns with my personal belief in always striving to be better. Oh, and I also appreciate the strong sense of community and support among my colleagues; it really makes coming to work every day a positive experience.
As you can see, this extract is rich in values, attitudes, and beliefs, making it ideal for values coding. In this case, we might code as follows:

Based on these codes, we can identify the interviewee’s core values to better understand what drives their job satisfaction and motivation. Therefore, this coding technique would be particularly useful for research aims that focused on these factors.
Need a helping hand?
Example: In Vivo Coding
In vivo coding (not to be confused with NVivo, the software package) involves using the exact words or phrases from the participants as codes . Using this technique ensures that the participants’ voices and perspectives are directly reflected in the analysis, which can be especially important when working with a multicultural sample.
Interviewer:
How do you handle challenges at work?
Interviewee:
Well, when a challenge arises, I first try to stay calm! It’s important not to panic. I then take a step back and analyze the situation. I often find it helpful to discuss the problem with my colleagues to get different perspectives.
Sometimes, just talking about it gives me new ideas. Once I have a plan, I focus on one step at a time to resolve the issue.
With in vivo coding, we’d use the exact language of the interviewee to capture key concepts. Here’s what that might look like:

As you can see in this example, in vivo coding allows us to capture the authentic language and insights of employees, providing a rich understanding of their experiences and approaches to overcoming challenges in the workplace. This could be particularly useful for studies where the research aims and questions involve understanding coping techniques in the workplace.
If you want to fast-track your qualitative coding (or just make sure it’s 100% on point), check out our premium coding service , where our team of PhD-qualified experts code your data for you.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Qualitative Data Coding
- Conference: Qualitative Data Coding
- At: 8th International Eurasian Educational Research Congress ONLINE

- Center for Research Methods Consulting
Abstract and Figures

Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- Patrik Zander
- Valentin Zieglmeier

- Barbara M. Wildemuth
- Edmund G. Husserl
- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
Qualitative Data Coding
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
Coding is the process of analyzing qualitative data (usually text) by assigning labels (codes) to chunks of data that capture their essence or meaning. It allows you to condense, organize and interpret your data.
A code is a word or brief phrase that captures the essence of why you think a particular bit of data may be useful. A good analogy is that a code describes data like a hashtag describes a tweet.

Coding is an iterative process, with researchers refining and revising their codes as their understanding of the data evolves.
The ultimate goal is to develop a coherent and meaningful coding scheme that captures the richness and complexity of the participants’ experiences and helps answer the research questions.
Step 1: Familiarize yourself with the data
- Read through your data (interview transcripts, field notes, documents, etc.) several times. This process is called immersion.
- Think and reflect on what may be important in the data before making any firm decisions about ideas, or potential patterns.
Step 2: Decide on your coding approach
- Will you use predefined deductive codes (based on theory or prior research), or let codes emerge from the data (inductive coding)?
- Will a piece of data have one code or multiple?
- Will you code everything or selectively? Broader research questions may warrant coding more comprehensively.
If you decide not to code everything, it’s crucial to:
- Have clear criteria for what you will and won’t code
- Be transparent about your selection process in research reports
- Remain open to revisiting uncoded data later in analysis
Step 3: Do a first round of coding
- Go through the data and assign initial codes to chunks that stand out
- Create a code name (a word or short phrase) that captures the essence of each chunk
- Keep a codebook – a list of your codes with descriptions or definitions
- Be open to adding, revising or combining codes as you go
Descriptive codes
- In vivo coding / Semantic coding : This method uses words or short phrases directly from the participant’s own language as codes. It deals with the surface-level content, labeling what participants directly say or describe. It identifies keywords, phrases, or sentences that capture the literal content. Participant : “I was just so overwhelmed with everything.” Code : “overwhelmed”
- Process coding : Uses gerunds (“-ing” words) to connote observable or conceptual action in the data. Participant : “I started by brainstorming ideas, then I narrowed them down.” Codes : “brainstorming ideas,” “narrowing down”
- Open coding : A form of initial coding where the researcher remains open to any possible theoretical directions indicated by the data. Participant : “I found the class really challenging, but I learned a lot.” Codes : “challenging class,” “learning experience”
- Descriptive coding : Summarizes the primary topic of a passage in a word or short phrase. Participant : “I usually study in the library because it’s quiet.” Code : “study environment”
Step 4: Review and refine codes
- Look over your initial codes and see if any can be combined, split up, or revised
- Ensure your code names clearly convey the meaning of the data
- Check if your codes are applied consistently across the dataset
- Get a second opinion from a peer or advisor if possible
Interpretive codes
Interpretive codes go beyond simple description and reflect the researcher’s understanding of the underlying meanings, experiences, or processes captured in the data.
These codes require the researcher to interpret the participants’ words and actions in light of the research questions and theoretical framework.
For example, latent coding is a type of interpretive coding which goes beyond surface meaning in data. It digs for underlying emotions, motivations, or unspoken ideas the participant might not explicitly state
Latent coding looks for subtext, interprets the “why” behind what’s said, and considers the context (e.g. cultural influences, or unconscious biases).
- Example: A participant might say, “Whenever I see a spider, I feel like I’m going to pass out. It takes me back to a bad experience as a kid.” A latent code here could be “Feelings of Panic Triggered by Spiders” because it goes beyond the surface fear and explores the emotional response and potential cause.
It’s useful to ask yourself the following questions:
- What are the assumptions made by the participants?
- What emotions or feelings are expressed or implied in the data?
- How do participants relate to or interact with others in the data?
- How do the participants’ experiences or perspectives change over time?
- What is surprising, unexpected, or contradictory in the data?
- What is not being said or shown in the data? What are the silences or absences?
Theoretical codes
Theoretical codes are the most abstract and conceptual type of codes. They are used to link the data to existing theories or to develop new theoretical insights.
Theoretical codes often emerge later in the analysis process, as researchers begin to identify patterns and connections across the descriptive and interpretive codes.
- Structural coding : Applies a content-based phrase to a segment of data that relates to a specific research question. Research question : What motivates students to succeed? Participant : “I want to make my parents proud and be the first in my family to graduate college.” Interpretive Code : “family motivation” Theoretical code : “Social identity theory”
- Value coding : This method codes data according to the participants’ values, attitudes, and beliefs, representing their perspectives or worldviews. Participant : “I believe everyone deserves access to quality healthcare.” Interpretive Code : “healthcare access” (value) Theoretical code : “Distributive justice”
Pattern codes
Pattern coding is often used in the later stages of data analysis, after the researcher has thoroughly familiarized themselves with the data and identified initial descriptive and interpretive codes.
By identifying patterns and relationships across the data, pattern codes help to develop a more coherent and meaningful understanding of the phenomenon and can contribute to theory development or refinement.
For Example
Let’s say a researcher is studying the experiences of new mothers returning to work after maternity leave. They conduct interviews with several participants and initially use descriptive and interpretive codes to analyze the data. Some of these codes might include:
- “Guilt about leaving baby”
- “Struggle to balance work and family”
- “Support from colleagues”
- “Flexible work arrangements”
- “Breastfeeding challenges”
As the researcher reviews the coded data, they may notice that several of these codes relate to the broader theme of “work-family conflict.”
They might create a pattern code called “Navigating work-family conflict” that pulls together the various experiences and challenges described by the participants.

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Qualitative Data Analysis
21 Qualitative Coding
Mikaila Mariel Lemonik Arthur
Codes are words or phrases that capture a central or notable attribute of a particular segment of text or visual data (Saldaña 2016). Coding , then, is the process of applying codes to texts or visuals. It is one of the most common strategies for data reduction and analysis of qualitative data, though many qualitative projects do not require or use coding. This chapter will provide an overview of approaches based in coding, including how to develop codes and how to go through the coding process.
In order to understand coding, it is essential to think about what it means for something to be a code. To analogize to social media, codes might function a bit like tags or hashtags. They are words or phrases that convey content, ideas, perspectives, or other key elements of segments of text. Codes are not the same as themes. Themes are broader than codes—they are concepts or topics around which a discussion, analysis, or text focuses. Themes are more general and more explanatory—often, once we code, we find themes emerge as ideas to explore in our further analysis (Saldaña 2016). Codes are also different from descriptors. Descriptors are words or phrases that describe characteristics of the entire text and/or the person who created it. For example, if we note the profession of an interview respondent, whether an article is news or opinion, or the type of camera used to take a photograph, those would be descriptors. Saldaña (2016) instead calls these attributes . The term attributes more typically refers to the possible answer choices or options for a variable, so it is possible to think about descriptors as variables (or perhaps their attributes) as well.

Let’s consider an example. Imagine that you were conducting an interview-based study looking at minor-league athletes’ workplace experiences and later-life career plans. In this study, themes might be broad ideas like “aspirations” or “work experiences.” There would be a vast array of codes, but they might include things like “short-term goals,” “educational plans,” “pay,” “team bonding,” “travel,” “treatment by managers,” “family demands,” and many more. Descriptors might include the athlete’s gender and what sport they play.
Developing a Coding System
While all approaches to coding have in common the idea that codes are applied to segments of text or visuals, there are many different ways to go about coding. These approaches differ in terms of when they occur during the research process and how codes are developed. First of all, there is a distinction between first- and second-cycle coding approaches (Saldaña 2016). First-cycle coding happens early in the research process and is really a bridge from data reduction to data analysis, while second-cycle coding occurs later in the research process and is more analytical in nature. Another version of this distinction is the comparison between rough, analytic, and focused coding. Rough coding is really part of the process of data reduction. It often involves little more than putting a few words near each segment of text to make clear what is important in that segment, with the approach being further refined as coding continues. In contrast, analytic coding involves more detailed techniques designed to move towards the development of themes and findings. Finally, focused coding involves selecting ideas of interest and going back and re-coding your texts to orient your approach more specifically around these ideas (Bergin 2018).
A second set of distinctions concerns whether the data drives the development of codes or whether codes are instead developed in advance. If codes are determined in advance, or predetermined, researchers develop a set of codes based on their theory, hypothesis, or research question. This sort of coding is typically called deductive coding or closed coding . In contrast, open coding or inductive coding refers to a process in which researchers develop codes based on what they observe in their data, grounding their codes in the texts. This second approach is more common, though by no means universal, in qualitative data analysis. In both types of coding, however, researcher may rely upon ideas generated by writing theoretical memos as they work through the connections between concepts, theory, and data (Saldaña 2016).
Finally, a third set of distinctions focuses on what is coded. Manifest coding refers to the coding of surface-level and easily observable elements of texts (Berg 2009). In contrast, latent coding is a more interpretive approach based on looking deeply into texts for the meanings that are encoded within or symbolized by them (Berg 2009). For example, consider a research project focused on gender in car advertisements. A manifest approach might count the number of men versus women who appear in the ads. A latent approach would instead focus on the use of gendered language and the extent to which men and women are depicted in gender-stereotyped ways.
Researchers need to answer two more questions as they develop their coding systems. First, what to code, and second, how many codes. When thinking about what to code, researchers can look at the level of individual words, characters or actors in the text, paragraphs, entire textual items (like complete books or articles), or really any unit of text (Berg 2009), but the most useful procedure is to look for chunks of words that together express a thought or idea, here referred to as “segments of text” or “textual segments,” and then code to represent the ideas, concepts, emotions, or other relevant thoughts expressed in those chunks.
How many codes should a particular coding system have? There is no simple answer to this question. Some researchers develop complex coding systems with many codes and may have over a hundred different codes. Others may use no more than 25, perhaps fewer, even for the same size project (Saldaña 2016). Some researchers nest codes into code trees, with several related “child” codes (or subcodes) under a single “parent” code. For example, a code “negative emotions” could be the parent code for a series of codes like “anger,” “frustration,” “sadness,” and “fear.” This approach enables researcher to use a smaller or larger number of codes in their analysis as seems fit after coding is complete. While there is no formula for determining the right number of codes for a particular project, researchers should be attentive to overgrowth in the number of codes. Codes have limited analytical value if they are used only once or twice—if a coding system includes many codes that are applied only a small number of times, consider whether there are larger categories of codes that might be more useful. Occasionally, there are codes worth keeping but applying rarely, for example when there is a rare but important phenomenon that arises in the data. But for the most part, codes should be used with some degree of frequency in order for them to be useful for uncovering themes and patterns.
Types of Codes
A wide variety of different types of codes can be used in coding systems. The discussion below, which draws heavily on the work of Saldaña (2016), details a variety of different approaches to coding and code development. Researchers do not need to choose just one of these approaches—most researchers combine multiple coding approaches to create an overall system that is right for the texts they are coding and the project they are conducting. The approaches detailed here are presented roughly in order of the degree of complexity they represent.
At the most basic level is descriptive coding . Descriptive codes are nouns or phrases describing the content covered in a segment of text or the topic the segment of text focuses on. All studies can use descriptive coding, but it often is less productive of rich data for analysis than other approaches might be. Descriptive coding is often used as part of rough coding and data reduction to prepare for later iterations of coding that delve more deeply into the texts. So, for instance, that study of sexism in advertisements might involve some rough coding in which the researcher notes what type of product or service is being advertised in each advertisement.
Structural coding , in contrast, attends more closely to the research question rather than to the ideas in the text. In structural coding, codes indicate which specific research question, part of a research question, or hypothesis is being addressed by a particular segment of text. This may be most useful as part of rough coding to help researchers ensure that their data addresses the questions and foci central to their project.
In vivo coding captures short phrases derived from participants’ own language, typically action-oriented. This is particularly important when researchers are studying subcultural groups that use language in different ways than researchers are accustomed to and where this language is important for subsequent analysis (Manning 2017). In this approach, researchers choose actual portions of respondents’ words and use those as codes. In vivo coding can be used as part of both rough and analytical coding processes.
A related approach is process coding , which involves “the use of gerunds to label actual or conceptual actions relayed by participants” (Saldaña 2016:77). ( Gerunds are verb forms that end in -ing and can function grammatically as if they are nouns when used in sentences). Process coding draws researchers’ attention to actions, but in contrast to in vivo coding it uses the researcher’s vocabulary to build the coding system. So, for instance, in the study of minor league athletes discussed earlier in the chapter, process codes might include “traveling,” “planning,” “exercising,” “competing,” and “socializing.”
Concept coding involves codes consisting of words or short phrases that represent broader concepts or ideas rather than tangible objects or actions. Sticking with the minor league athletes example, concept codes might include “for the love of the game,” “youth,” and “exploitation.” A combination of concept, process, and descriptive coding may be useful if researchers want their coding system to result in an inventory of the ideas, objects, and actions discussed in the texts.

Emotion codes are codes indicating the emotions participants discuss in or that are evoked by a segment of text. A more contemporary version of emotion codes relies on “emoticodes” or the emoji that express specific kinds of emotions, as shown in Figure 2.
Values coding involves the use of codes designed to represent the “perspectives or worldview” of a respondent by conveying participants’ “values, attitudes, and beliefs” (Saldaña 2016:131). For example, a project on elementary school teachers’ workplace satisfaction might include values codes like “equity,” “learning,” “commitment,” and “the pursuit of excellence.” Do note that choices made in values coding are, even more so than in other forms of coding, likely to reflect the values and worldviews of the coder. Thus, it can be essential to use a team of multiple coders with different backgrounds and perspectives in order to ensure a values coding approach that reflects the contents of the texts rather than the ideas of the coders.
Versus coding requires the construction of a series of binary oppositions and then the application of one or the other of the items in the binary as a code to each relevant segment of text. This may be a particularly useful approach for deductive coding, as the researcher can set out a series of hypothesized binaries to use as the basis for coding. For example, the project on elementary school teachers’ workplace satisfaction might use binaries like feeling supported vs. feeling unsupported, energized vs. tired, unfulfilled needs vs. fulfilled needs, kids ready to learn vs. kids needing services, academic vs non-academic concerns, and so on.
Evaluation coding is used to signify what is and is not working in the policy, program, or endeavor that respondents are discussing or that the research focuses on. This approach is obviously especially useful in evaluation research designed to assess the merit or functioning of particular policies or programs. For example, if the project about elementary school teachers was part of a mentoring program designed to keep new teachers in the education profession, codes might include “future orientation” to flag portions of the text in which teachers discuss their longer-term plans and “mentor/mentee match” to flag portions in which they explore how they feel about their mentors, both key elements of the program and its goals.
There are a variety of other approaches more common outside of sociology, such as dramaturgical coding , which is a coding approach that treats interview transcripts or fieldnotes as if they are scripts for a play, coding such things as actors, attitudes, conflicts, and subtexts; coding approaches relying on terms and ideas from literary analysis; and those drawn from communications studies, which focus on facets of verbal exchange. Finally, some researchers have outlined very specific coding strategies and procedures such that someone else could pick up their methods and apply them exactly. This sort of approach is typically deductive, as it requires the advance specification of the decisions that will be made about coding.
Some coding strategies incorporate measures of weight or intensity, and this can be combined with many of the approaches detailed above. For example, consider a project collecting narratives of people’s experiences with losing their jobs. Respondents might include a variety of emotional content in their narratives, whether sadness, fear, stress, relief, or something else. But the emotions they discuss will vary not only in type, they will also vary in extent. A worker who is fired from a job they liked well enough but who knows they will be able to find another job soon may express sadness while a worker whose company closed after she worked there for 20 years and who has few other equivalent employment opportunities in the region may express devastation. Code weights help account for these differences.
A final question researchers must consider is whether they will apply only one code per segment of text or will permit overlapping codes. Overlapping codes make data analysis more complex but can facilitate the process of looking for relationships between different concepts or ideas in the data.
As a coding system is developed and certainly upon its completion, researchers create documents known as codebooks . As is the case with survey research, codebooks lay out the details of how the measurement instrument works to capture data and measure it. For surveys, a codebook tells researchers how to transform the multiple-choice and short-answer responses to survey questions into the numerical data used for quantitative analysis. For qualitative coding, codebooks instead explain when and how to use each of the codes included in the project. Codebooks are an important part of the coding process because they remind the researcher, and any other coders working on the project, what each code means, what types of data it is meant to apply to, and when it should and should not be used (Luker 2008). Even if a researcher is coding without others, it is easy to lose sight of what you were thinking when you initially developed your coding system, and so the codebook serves as an important reminder.
For each code, the codebook should state the name of the code, include a couple of sentences describing the code and what it should be used for, any information about when the code should not be used, examples of both typical and atypical conditions under which the code would be used, and a discussion of the role the code plays in analysis (Saldaña 2016). Codebooks thus serve as instruction manuals for when and how to apply codes. They can also help researchers think about taxonomies of codes as they organize the code book, with higher-level ideas serving as categories for groups of child, or more precise, codes.
The Process of Coding
So, what does the process of coding look like? While qualitative research can and does involve deductive approaches, the process that will be detailed here is an inductive approach, as this is more common in qualitative research. This discussion will lay out a series of steps in the coding process as well as some additional questions researchers and analysts must consider as they develop and carry out their coding.
The first step in inductive coding is to completely and thoroughly read through the data several times while taking detailed notes. To Saldaña (2016), the most important question to ask during this initial read is what is especially interesting or surprising or otherwise stands out. In addition, researchers might contemplate the actions people take, how people go about accomplishing things, how people use language or understand the world, and what people seem to be thinking. The notes should include anything and everything—objects, people, emotions, actions, theoretical ideas, questions—really anything, whether it comes up again and again in the data or only once, though it is useful to flag or highlight those concepts that seem to recur frequently in the data.
Next, researchers need to organize these notes into a coding system. This involves deciding which coding approach(es) to incorporate, whether or not to use parent and child codes, and what sort of vocabulary to use for codes. Remember that readers will not see the coding system except insofar as the researcher chooses to convey it, so vocabulary and terms should be chosen based on the extent to which they make sense to the research team. Once a coding system has been developed, the researcher must create a codebook. If paper coding will be used, a paper codebook should be created. If researchers will be using CAQDAS, or computer-aided qualitative data analysis software, to do their coding, it is often the case that the codebook can be built into the software itself.
Next, the researcher or research team should rough code, applying codes to the text while taking notes to reflect upon missing pieces in the coding system, ways to reorganize the codes or combine them to enhance meaning, and relevant theoretical ideas and insights. Upon completing the rough coding process, researchers should revise the coding system and codebook to fully reflect the data and the project’s needs.
At this point, researchers are ready to engage in coding using the revised codebook. They should always have someone else code a portion of the texts—usually a minimum of 10%—for interrater reliability checks, and if a larger research team is used, 10% of the texts should be coded in common by all coders who are part of the research team. Even in cases where researchers are working alone, it truly strengthens data analysis to be able to check for interrater reliability, so most analysts suggest having a portion of the data coded by another coder, using the codebook. If at all possible, additional coding staff should not be told what the hypothesis or research question is, as one of the strengths of this approach is that additional coding staff will be less likely to be influenced by preexisting ideas about what the data should show (Luker 2008). There are various quantitative measures, such as Chronbach’s alpha and Kappa , that researchers use to calculate interrater reliability, the measure of how closely the ratings of multiple coders correspond. All coders should keep detailed notes about their coding process and any obstacles or difficulties they encounter.
How do researchers know they are done coding? Not just because they have gone through each text once or twice! Researchers may need to continue repeating this process of revision and re-coding until additional coding does not reveal anything more. This repetition is an essential part of coding, as coding always requires refinement and rethinking (Saldaña 2016). In Berg’s (2009:354-55) words, it is essential to “code minutely,” beginning with a rough view of the entire text and then refining as you go until you are examining each detail of a text. Then, researchers think about why and how they developed their codes and what jumps out at them as important from the research as they delve into findings, making sure that nothing has been left out of the coding process before they move towards data analysis.
One interesting question is whether the identities and standpoints (as discussed in the chapter “The Qualitative Approach”) of coders matter to the coding process. Eduardo Bonila-Silva (Zuberi and Bonilla-Silva 2008:17) has described how, after a presentation discussing his research on racism, a colleague asked whether the coders were White or Black—and he responded by asking the colleague “if he asked such questions across the board or only to researchers saying race matters.” As Bonilla-Silva’s question suggests, race (like other aspects of identity and experience, such as gender, immigration status, disability status, age, and social class, just to name a few) very well might shape the way coders see and understand data, functioning as part of a particular coding filter (Saldaña 2016). But that shaping extends broadly across all issues, not just those we might assume are particularly salient in relationship to identities. Thus, it is best for research teams to be diverse so as to ensure that a variety of perspectives are brought to bear on the data and that the findings reflect more than just a narrow set of ideas about how the world works.
Coding and What Comes After
If researchers will code by hand, they will need multiple copies of their data, one for reference and one for writing on (Luker 2008). On the copy that will be written on, researchers use a note-taking system that makes sense to them—whether different-colored markers, Roman numerals in the margins, a complex series of sticky notes, or whatever—to mark the application of various codes to sections of your data. You can see an example of what hand coding might look like in Figure 3 below, which is taken from a study of the comments faculty members make on student writing. Segments of text are highlighted in different colors, with codes noted in the margins next to the text. You can see how codes are repeated but in different combinations. Once the initial coding process is complete, researchers often cut apart the pieces of paper to make chunks of text with individual codes and sort the pieces of paper by code (if multiple codes appear in individual chunks of text, additional copies might be needed). Then, each pile is organized and used as the basis for writing theoretical memos. Another option for coding by hand is to use an index sheet (Berg 2009). This approach entails developing a set of codes and categories, arranging them on paper, and entering transcript, page, and paragraph information to identify where relevant quotes can be found.
For more complex analytical processes, researchers will likely want to use software, though there are limitations to software. Luker (2008), for instance, argues that when coding manually, she tends to start with big themes and only breaks them into their constituent parts later, while coding using software leads her to start with the smallest possible codes. (One solution to this, offered by some software packages, is upcoding, where a so-called “parent” code is simultaneously applied to all of the “child” codes under it. For instance, you might have a parent code of “activism” and then child codes that you apply to different kinds of activism, whether protest, legislative advocacy, community organizing, or whatever.)

Coding does not stand on its own, and thus simply completing the coding process does not move a research project from data to analysis. While the analysis process will be discussed in more detail in a subsequent chapter, there are several steps researchers take alongside coding or immediately after completing coding that facilitate analysis and are thus useful to discuss in the context of coding. Many of these are best understood as part of the process of data reduction. One of the most important of these is categorizing codes into larger groupings, a step that helps to enable the development of themes. These larger groupings, sometimes called “parent” codes, can collapse related but not identical ideas. This is always useful, but it is especially useful in cases where researchers have used a large number of codes and each one is applied only a few times. Once parent codes have been created, researchers then go back and ensure that the appropriate parent code is assigned to all segments of text that were initially coded with the relevant “child” codes (a step that can be automated in CAQDAS). If appropriate, researchers may repeat this process to see if parent codes can be further grouped. An alternative approach to this grouping process is to wait until coding is complete, and then create more analytical categories that make sense as thematic groupings for the codes that have been utilized in the project so far (Saldaña 2016).
There are a variety of other approaches researchers may take as part of data reduction or preliminary analysis after completing coding. They may outline the codes that have occurred most frequently for specific participants or texts, or for the entire body of data, or the codes that are most likely to co-occur in the same segment of text or in the same document. They may print out or photocopy documents or segments of text and rearrange them on a surface until the arrangement is analytically meaningful. They may develop diagrams or models of the relationships between codes. In doing this, it is especially helpful to focus on the use of verbs or other action words to specify the nature of these relationships—not just stating that relationships exist, but exploring what the relationships do and how they work.
In inductive coding especially, it is often useful to write theoretical and analytical memos while coding occurs, and after coding is completed it is a good time to go back and review and refine these memos. Here, researchers both clearly articulate to themselves how the coding process occurred and what methodological choices they made as well as what preliminary ideas they have about analysis and potential findings. It can be very useful to summarize one’s thinking and any patterns that might have been observed so far as a step in moving towards analysis. However, it is extremely important to remember the data and not just the codes. Qualitative researchers always go back to the actual text and not just the summaries or categories. So a final step in the process of moving toward analysis might be to flag quotes or data excerpts that seem particularly noteworthy, meaningful, or analytically useful, as researchers need these examples to make their data come alive during analysis and when they ultimately present their results.
Becoming a Coder
This chapter has provided an overview of how to develop a coding system and apply that system to the task of conducting qualitative coding as part of a research project. Many new researchers find it easy—if sometimes time-consuming and not always fascinating—to get engaged with the coding process. But what does it take to become an effective coder? Saldaña (2016) emphasizes personality attributes and skills that can help. Some of these are attributes and skills that are important for anyone who is involved in any aspect of research and data analysis: organization, to keep track of data, ideas, and procedures; perseverance, to ensure that one keeps going even when the going is tough, as is often the case in research; and ethics, to ensure proper treatment of research participants, appropriate data security behaviors, and integrity in the use of sources. In most aspects of data analysis, creativity is also important, though there are some roles in quantitative data analysis that require more in the way of technical skills and ability to follow directions. In qualitative data analysis, creativity remains important because of the need to think deeply and differently about the data as analysis continues. Flexibility and the ability to deal with ambiguity are much more important in qualitative research, as the data itself is more variable and less concrete; quantitative research tends to place more emphasis on rules and procedures. A final strength that is particularly important for those working in qualitative coding is having a strong vocabulary, as vocabulary both helps researchers understand the data and enhances their ability to create effective and useful coding systems. The best way to develop a stronger vocabulary is to read more, especially within your discipline or field but broadly as well, so researchers should be sure to stay engaged with reading, learning, and growing.
Reading, learning, and growing, along with a lot of practice, is of course how researchers enhance their data collection, coding, and data analysis skills, so keep working at it. Qualitative research can indeed be easy to get started with, but it takes time to become an expert. Put in the time, and you, too, can become a skilled qualitative data analyst.
- Female respondent
- The relationship between poverty and social control
- The process of divorce
- Social hierarchies
- Pick a research topic you find interesting and determine which of the approaches to coding detailed in this chapter might be most appropriate for your topic, then write a paragraph about why this approach is the best.
- Sticking with the same topic you used to respond to Exercise 2, brainstorm some codes that might be useful for coding texts related to this topic. Then, write appropriate text for a codebook for each of those codes.
- Select a hashtag of interest on a particular social media site and randomly sample every other post using that hashtag until you have selected 15 tweets. Then inductively code those posts and engage in summarization or classification to determine what the most important themes they express might be.
- Create a codebook based on what you did in Exercise 4. Exchange codebooks and tweets with a classmate and code each other’s tweets according to the instructions in the codebook. Compare your results—how often did your coding decisions agree and how often did they disagree? What does this tell you about interrater reliability, codebook construction, and coder training?
Media Attributions
- codes themes descriptors © Mikaila Mariel Lemonik Arthur is licensed under a CC BY-NC (Attribution NonCommercial) license
- Emoticodes © AnnaliseArt is licensed under a CC BY (Attribution) license
- Hand Coding Example © Mikaila Mariel Lemonik Arthur is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
Words or phrases that capture a central or notable attribute of a particular segment of textual or visual data.
The process of assigning observations to categories.
Concepts, topics, or ideas around which a discussion, analysis, or text focuses.
A category in an information storage system; more specifically in Dedoose, a characteristic of an author or entire text. Also, the word used to indicate that category or characteristic.
The possible levels or response choices of a given variable.
Coding that occurs early in the research process as part of a bridge from data reduction to data analysis.
Analytical coding that occurs later in the data analysis process.
Coding for data reduction or as part of an initial pass through the data.
Coding designed to move analysis towards the development of themes and findings.
Selective coding designed to orient an analytical approach around certain ideas.
Coding in which the researcher developed a coding system in advance based on their theory, hypothesis, or research question.
Coding in which the researcher develops codes based on what they observe in the data they have collected.
Coding of surface-level and/or easily observable elements of texts.
Interpretive coding that focuses on meanings within texts.
Coding that relies on nouns or phrases describing the content or topic of a segment of text.
Coding that indicates which research question or hypothesis is being addressed by a given segment of text.
Coding that relies on research participants' own language.
Coding in which gerunds are applied to actions that are described in segments of text.
Verb forms that end in -ing and function grammatically in sentences as if they are nouns.
Coding using words or phrases that represent concepts or ideas.
Codes indicating emotions discussed by or present in the text, sometimes indicated by the use of emoji/emoticons.
Coding that relies on codes indicating the perspective, worldview, values, attitudes, and/or beliefs of research participants.
Coding that relies on a series of binary oppositions, one of which must be applied to each segment of text.
A coding system used to indicate what is or is not working in a program or policy.
Coding that treats texts as if they are scripts for a play.
Elements of a coding strategy that help identify the intensity or degree of presence of a code in a text.
Documents that lay out the details of measurement. Codebooks may be used in surveys to indicate the way survey questions and responses are entered into data analysis software. Codebooks may be used in coding to lay out details about how and when to use each code that has been developed.
A measure of association especially likely to be used for testing interrater reliability.
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.

Coding Qualitative Data: A Beginner’s How-To + Examples

When gathering feedback, whether it’s from surveys , online reviews, or social mentions , the most valuable insights usually come from free-form or open-ended responses.
Though these types of responses allow for more detailed feedback, they are also difficult to measure and analyse on a large scale. Coding qualitative data allows you to transform these unique responses into quantitative metrics that can be compared to the rest of your data set.
Read on to learn about this process.
What is Qualitative Data Coding?

Qualitative data coding is the process of assigning quantitative tags to the pieces of data. This is necessary for any type of large-scale analysis because you 1) need to have a consistent way to compare and contrast each piece of qualitative data, and 2) will be able to use tools like Excel and Google Sheets to manipulate quantitative data.
For example, if a customer writes a Yelp review stating “The atmosphere was great for a Friday night, but the food was a bit overpriced,” you can assign quantitative tags based on a scale or sentiment. We’ll get into how exactly to assign these tags in the next section.
Inductive Coding vs Deductive Coding

When deciding how you will scale and code your data, you’ll first have to choose between the inductive or deductive methods. We cover the pros and cons of each method below.
Inductive Coding
Inductive coding is when you don’t already have a set scale or measurement with which to tag the data. If you’re analysing a large amount of qualitative data for the first time, such as the first round of a customer feedback survey, then you will likely need to start with inductive coding since you don’t know exactly what you will be measuring yet.
Inductive coding can be a lengthy process, as you’ll need to comb through your data manually. Luckily, things get easier the second time around when you’re able to use deductive coding.
Deductive Coding
Deductive coding is when you already have a predetermined scale or set of tags that you want to use on your data. This is usually if you’ve already analysed a set of qualitative data with inductive reasoning and want to use the same metrics.
To continue from the example above, say you noticed in the first round that a lot of Yelp reviews mentioned the price of food, and, using inductive coding, you were able to create a scale of 1-5 to measure appetisers, entrees, and desserts.
When analysing new Yelp reviews six months later, you’ll be able to keep the same scale and tag the new responses based on deductive coding, and therefore compare the data to the first round of analysis.
3 Steps for Coding Qualitative Data From the Top-Down

For this section, we will assume that we’re using inductive coding.
1. Start with Broad Categories
The first thing you will want to do is sort your data into broad categories. Think of each of these categories as specific aspects you want to know more about.
To continue with the restaurant example, your categories could include food quality, food price, atmosphere, location, service, etc.
Or for a business in the B2B space, your categories could look something like product quality, product price, customer service, chatbot quality, etc.
2. Assign Emotions or Sentiments
The next step is to then go through each category and assign a sentiment or emotion to each piece of data. In the broadest terms, you can start with just positive emotion and negative emotion.
Remember that when using inductive coding, you’re figuring out your scale and measurements as you go, so you can always start with broad analysis and drill down deeper as you become more familiar with your data.
3. Combine Categories and Sentiments to Draw Conclusions
Once you’ve sorted your data into categories and assigned sentiments, you can start comparing the numbers and drawing conclusions.
For example, perhaps you see that out of the 500 Yelp reviews you’ve analysed, 300 fall into the food price/negative sentiment section of your data. That’s a pretty clear indication that customers think your food is too expensive, and you may see an improvement in customer retention by dropping prices.
The three steps outlined above cover just the very basics of coding qualitative data, so you can understand the theory behind the analysis.
In order to gain more detailed conclusions, you’ll likely need to dig deeper into the data by assigning more complex sentiment tags and breaking down the categories further. We cover some useful tips and a coding qualitative data example below.
4 Tips to Keep in Mind for Accurate Qualitative Data Coding

Here are some helpful reminders to keep on hand when going through the three steps outlined above.
1. Start with a Small Sample of the Data
You’ll want to start with a small sample of your data to make sure the tags you’re using will be applicable to the rest of the set. You don’t want to waste time by going through and manually tagging each piece of data, only to realise at the end that the tags you’ve been using actually aren’t accurate.
Once you’ve broken up your qualitative data into the different categories, choose 10-20% of responses in each category to tag using inductive coding.
Then, continue onto the analysis phase using just that 10-20%.
If you’re able to find takeaways and easily compare the data with that small sample size , then you can continue coding the rest of the data in that same way, adding additional tags where needed.
2. Use Numerical Scales for Deeper Analysis
Instead of just assigning positive and negative sentiments to your data points, you can break this down even further by utilising numerical scales.
Exactly how negative or how positive was the piece of feedback? In the Yelp review example from the beginning of this article, the reviewer stated that the food was “a bit overpriced.” If you’re using a scale of 1-5 to tag the category “food price,” you could tag this as a ⅗ rating.
You’ll likely need to adjust your scales as you work through your initial sample and get a clearer picture of the review landscape.
Having access to more nuanced data like this is important for making accurate decisions about your business.
If you decided to stick with just positive and negative tags, your “food price” category might end up being 50% negative, indicating that a massive change to your pricing structure is needed immediately.
But if it turns out that most of those negative reviews are actually ⅗’s and not ⅕’s, then the situation isn’t as dire as it might have appeared at first glance.
3. Remember That Each Data Point Can Contain Multiple Pieces of Information
Remember that qualitative data can have multiple sentiments and multiple categories (such as the Yelp review example mentioning both atmosphere and price), so you may need to double or even triple-sort some pieces of data.
That’s the beauty of and the struggle with handling open-ended or free-form responses.
However, these responses allow for more accurate insights into your business vs narrow multiple-choice questions.
4. Be Mindful of Having Too Many Tags
Remember, you’re able to draw conclusions from your qualitative data by combining category tags and sentiment tags.
An easy mistake for data analysis newcomers to make is to end up with so many tags that comparing them becomes impossible. This usually stems from an overabundance of caution that you’re tagging responses accurately.
For example, say you’re tagging a review that’s discussing a restaurant host’s behavior. You put it in the category “host/hostess behavior” and tag it as a ⅗ for the sentiment.
Then, you come across another review discussing a server’s behaviour that’s slightly more positive, so you tag this as “server behaviour” for the category and 3.75/5 for the sentiment.
By getting this granular, you’re going to end up with very few data points in the same category and sentiment, which defeats the purpose of coding qualitative data.
In this example, unless you’re very specifically looking at the behaviour of individual restaurant positions, you’re better off tagging both responses as “customer service” for the category and ⅗ for the sentiment for consistency’s sake.
Coding Qualitative Data Example
Below we’ll walk through an example of coding qualitative data, utilising the steps and tips detailed above.

Step 1: Read through your data and define your categories. For this example, we’ll use “customer service,” “product quality,” and “price.”
Step 2: Sort a sample of the data into the above categories. Remember that each data point can be included in multiple categories.
- “This software is amazing, does exactly what I need it to [Product Quality]. However, I do wish they’d stop raising prices every year as it’s starting to get a little out of my budget [Price].”
- “Love the product [Product Quality], but honestly I can’t deal with the terrible customer service anymore [Customer Service]. I’ll be shopping around for a new solution.”
- “Meh, this software is okay [Product Quality] but cheaper competitors [Price] are just as good with much better customer service [Customer Service].”
Step 3: Assign sentiments to the sample. For more in-depth analysis, use a numerical scale. We’ll use 1-5 in this example, with 1 being the lowest satisfaction and 5 being the highest.
- Product Quality:
- “This software is amazing, does exactly what I need it to do” [5/5]
- “Love the product” [5/5]
- “Meh, this software is okay [⅖]
- Customer Service:
- “Honestly I can’t deal with the terrible customer service anymore [⅕]
- “...Much better customer service,” [⅖]
- “However, I do wish they’d stop raising prices every year as it’s starting to get a little out of my budget.” [⅗]
- “Cheaper competitors are just as good.” [⅖]
Step 4: After confirming that the established category and sentiment tags are accurate, continue steps 1-3 for the rest of your data, adding tags where necessary.
Step 5: Identify recurring patterns using data analysis. You can combine your insights with other types of data , like demographic and psychographic customer profiles.
Step 6: Take action based on what you find! For example, you may discover that customers aged 20-30 were the most likely to provide negative feedback on your customer service team, equating to ⅖ or ⅕ on your coding scale. You may be able to conclude that younger customers need a more streamlined way to communicate with your company, perhaps through an automated chatbot service.
Step 7: Repeat this process with more specific research goals in mind to continue digging deeper into what your customers are thinking and feeling . For example, if you uncover the above insight through coding qualitative data from online reviews, you could send out a customer feedback survey specifically asking free-form questions about how your customers would feel interacting with a chatbot instead.
How AI tools help with Coding Qualitative Data

Now that you understand the work that goes into coding qualitative data, you’re probably wondering if there’s an easier solution than manually sorting through every response.
The good news is that, yes, there is. Advanced AI-backed tools are available to help companies quickly and accurately analyse qualitative data at scale, such as customer surveys and online reviews.
These tools can not only code data based on a set of rules you determine, but they can even do their own inductive coding to determine themes and create the most accurate tags as they go.
These capabilities allow business owners to make accurate decisions about their business based on actual data and free up the necessary time and employee bandwidth to act on these insights.
The infographic below gives a visual summary of how to code qualitative data and why it’s essential for businesses to learn how:

Try Chattermill today today to learn how our AI-powered software can help you make smarter business decisions.
Related articles.
How HelloFresh Leverages Customer Insights to Improve Operational Efficiency for Supply Chain Management
We spoke with Stefan Platteau, Associate Director of Global Product Strategy and Analytics, to learn how Chattermill helped HelloFresh optimize its Operations, Logistics, and Supply Chain Management.

How HelloFresh Turned Product Feedback into New Revenue Streams, Growing to a €7B Business
Learn how HelloFresh partnered with Chattermill to make strategic product decisions based on customer feedback, and drive more efficient business growth.

Video Panel: How top brands use AI to impact customer experience
We were joined by more than 35 customers, partners, and friends who wanted to make sure that their choice of AI drives their business outcomes.
See Chattermill in action
Understand the voice of your customers in realtime with Customer Feedback Analytics from Chattermill.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Standards for reporting qualitative research: a synthesis of recommendations
Affiliation.
- 1 Dr. O'Brien is assistant professor, Department of Medicine and Office of Research and Development in Medical Education, University of California, San Francisco, School of Medicine, San Francisco, California. Dr. Harris is professor and head, Department of Medical Education, University of Illinois at Chicago College of Medicine, Chicago, Illinois. Dr. Beckman is professor of medicine and medical education, Department of Medicine, Mayo Clinic College of Medicine, Rochester, Minnesota. Dr. Reed is associate professor of medicine and medical education, Department of Medicine, Mayo Clinic College of Medicine, Rochester, Minnesota. Dr. Cook is associate director, Mayo Clinic Online Learning, research chair, Mayo Multidisciplinary Simulation Center, and professor of medicine and medical education, Mayo Clinic College of Medicine, Rochester, Minnesota.
- PMID: 24979285
- DOI: 10.1097/ACM.0000000000000388
Purpose: Standards for reporting exist for many types of quantitative research, but currently none exist for the broad spectrum of qualitative research. The purpose of the present study was to formulate and define standards for reporting qualitative research while preserving the requisite flexibility to accommodate various paradigms, approaches, and methods.
Method: The authors identified guidelines, reporting standards, and critical appraisal criteria for qualitative research by searching PubMed, Web of Science, and Google through July 2013; reviewing the reference lists of retrieved sources; and contacting experts. Specifically, two authors reviewed a sample of sources to generate an initial set of items that were potentially important in reporting qualitative research. Through an iterative process of reviewing sources, modifying the set of items, and coding all sources for items, the authors prepared a near-final list of items and descriptions and sent this list to five external reviewers for feedback. The final items and descriptions included in the reporting standards reflect this feedback.
Results: The Standards for Reporting Qualitative Research (SRQR) consists of 21 items. The authors define and explain key elements of each item and provide examples from recently published articles to illustrate ways in which the standards can be met.
Conclusions: The SRQR aims to improve the transparency of all aspects of qualitative research by providing clear standards for reporting qualitative research. These standards will assist authors during manuscript preparation, editors and reviewers in evaluating a manuscript for potential publication, and readers when critically appraising, applying, and synthesizing study findings.
PubMed Disclaimer
Similar articles
- The Single-Case Reporting Guideline In BEhavioural Interventions (SCRIBE) 2016 Statement. Tate RL, Perdices M, Rosenkoetter U, Shadish W, Vohra S, Barlow DH, Horner R, Kazdin A, Kratochwill T, McDonald S, Sampson M, Shamseer L, Togher L, Albin R, Backman C, Douglas J, Evans JJ, Gast D, Manolov R, Mitchell G, Nickels L, Nikles J, Ownsworth T, Rose M, Schmid CH, Wilson B. Tate RL, et al. J Clin Epidemiol. 2016 May;73:142-52. doi: 10.1016/j.jclinepi.2016.04.006. Epub 2016 Apr 19. J Clin Epidemiol. 2016. PMID: 27101888
- The Single-Case Reporting Guideline In Behavioural Interventions (SCRIBE) 2016 statement. Tate RL, Perdices M, Rosenkoetter U, Shadish W, Vohra S, Barlow DH, Horner R, Kazdin A, Kratochwill T, McDonald S, Sampson M, Shamseer L, Togher L, Albin R, Backman C, Douglas J, Evans JJ, Gast D, Manolov R, Mitchell G, Nickels L, Nikles J, Ownsworth T, Rose M, Schmid CH, Wilson B. Tate RL, et al. Can J Occup Ther. 2016 Jun;83(3):184-95. doi: 10.1177/0008417416648124. Can J Occup Ther. 2016. PMID: 27231387
- [Procedures and methods of benefit assessments for medicines in Germany]. Bekkering GE, Kleijnen J. Bekkering GE, et al. Dtsch Med Wochenschr. 2008 Dec;133 Suppl 7:S225-46. doi: 10.1055/s-0028-1100954. Epub 2008 Nov 25. Dtsch Med Wochenschr. 2008. PMID: 19034813 German.
- Procedures and methods of benefit assessments for medicines in Germany. Bekkering GE, Kleijnen J. Bekkering GE, et al. Eur J Health Econ. 2008 Nov;9 Suppl 1:5-29. doi: 10.1007/s10198-008-0122-5. Eur J Health Econ. 2008. PMID: 18987905
- The Single-Case Reporting Guideline In BEhavioural Interventions (SCRIBE) 2016 Statement. Tate RL, Perdices M, Rosenkoetter U, Shadish W, Vohra S, Barlow DH, Horner R, Kazdin A, Kratochwill T, McDonald S, Sampson M, Shamseer L, Togher L, Albin R, Backman C, Douglas J, Evans JJ, Gast D, Manolov R, Mitchell G, Nickels L, Nikles J, Ownsworth T, Rose M, Schmid CH, Wilson B. Tate RL, et al. Am J Occup Ther. 2016 Jul-Aug;70(4):7004320010p1-11. doi: 10.5014/ajot.2016.704002. Am J Occup Ther. 2016. PMID: 27294998
- Health effects and user perceptions of the US Customs and Border Patrol One™ mobile application: A qualitative analysis among asylum seekers at the Mexico-US border. Reynolds CW, Tucker B, Bishop S, Draugelis S, Heisler M, Mohareb AM. Reynolds CW, et al. J Migr Health. 2024 Aug 8;10:100265. doi: 10.1016/j.jmh.2024.100265. eCollection 2024. J Migr Health. 2024. PMID: 39224871 Free PMC article.
- Exploring student preferences for implementing a digital mental health intervention in a university setting: Qualitative study within a randomised controlled trial. Jackson HM, Gulliver A, Hasking P, Leach L, Batterham PJ, Calear AL, Farrer LM. Jackson HM, et al. Digit Health. 2024 Aug 30;10:20552076241277175. doi: 10.1177/20552076241277175. eCollection 2024 Jan-Dec. Digit Health. 2024. PMID: 39224795 Free PMC article.
- Individuals' perceptions of the factors linked to everyday soft drink consumption among university students: qualitative study. Sarhan MM, Aljohani SA, Alnazzawi YA, Alharbi NA, Alotaibi SE, Alhujaili AS, Alwadi MAM. Sarhan MM, et al. Front Nutr. 2024 Aug 19;11:1388918. doi: 10.3389/fnut.2024.1388918. eCollection 2024. Front Nutr. 2024. PMID: 39224179 Free PMC article.
- Navigating the crossroads of aging, caregiving and technology: Insights from a southern Spain about video-based technology in the care context. Mujirishvili T, Cabrero-Garćıa J, Fló Rez-Revuelta F, Richart-Mart Inez M. Mujirishvili T, et al. Digit Health. 2024 Aug 28;10:20552076241271856. doi: 10.1177/20552076241271856. eCollection 2024 Jan-Dec. Digit Health. 2024. PMID: 39221088 Free PMC article.
- Perceptions of multi-cancer early detection tests among communities facing barriers to health care. Roybal KL, Husa RA, Connolly M, Dinh C, Bensley KMK, Wendt SJ. Roybal KL, et al. Health Aff Sch. 2024 Aug 16;2(9):qxae102. doi: 10.1093/haschl/qxae102. eCollection 2024 Sep. Health Aff Sch. 2024. PMID: 39220580 Free PMC article.
Publication types
- Search in MeSH
LinkOut - more resources
Full text sources.
- Ovid Technologies, Inc.
- Wolters Kluwer
Other Literature Sources
- scite Smart Citations
Miscellaneous
- NCI CPTAC Assay Portal

- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
Log in using your username and password
- Search More Search for this keyword Advanced search
- Latest content
- For authors
- Browse by collection
- BMJ Journals
You are here
- Volume 14, Issue 9
- Qualitative study of UK health and care professionals to determine resources and processes that can support actions to improve quality of data used to address and monitor health inequalities
- Article Text
- Article info
- Citation Tools
- Rapid Responses
- Article metrics
- http://orcid.org/0000-0002-7790-2630 Sowmiya Moorthie 1 , 2 ,
- Emre Oguzman 3 , 4 ,
- Sian Evans 5 ,
- Carol Brayne 1 ,
- Louise LaFortune 1
- 1 University of Cambridge , Cambridge , UK
- 2 PHG Foundation , Cambridge , UK
- 3 Hertfordshire County Council (HCC) , Hertford , UK
- 4 Hertfordshire Partnership University NHS Foundation Trust , Hatfield , UK
- 5 Local Knowledge and Intelligence Service (LKIS) East , Office for Health Improvement and Disparities , Cambridge , UK
- Correspondence to Dr Sowmiya Moorthie; sam71{at}medschl.cam.ac.uk
Introduction Health inequalities in the UK are investigated and addressed by analysing data across socioeconomic factors, geography and specific characteristics, including those protected under law. It is acknowledged that the quality of data underpinning these analyses can be improved. The objective of this work was to gain insights from professionals working across the health and care sector in England into the type(s) of resource(s) that can be instrumental in implementing mechanisms to improve data quality into practice.
Design Qualitative study based on semistructured interviews involving health and care professionals.
Setting England.
Participants A total of 16 professionals, mainly from the East of England.
Results Awareness of mechanisms that could be put in place to improve quality of data related to health inequalities was high among interviewees. However, logistical (eg, workforce time, capacity and funding) as well as data usage (eg, differences in data granularity, information governance structures) barriers impacted on implementation of many mechanisms. Participants also acknowledged that concepts and priorities around health inequalities can vary across the system. While there are resources already available that can aid in improving data quality, finding them and ensuring they are suited to needs was time-consuming. Our analysis indicates that resources to support the creation of a shared understanding of what health inequalities are and share knowledge of specific initiatives to improve data quality between systems, organisations and individuals are useful.
Conclusions Different resources are needed to support actions to improve quality of data used to investigate heath inequalities. These include those aimed at raising awareness about mechanisms to improve data quality as well as those addressing system-level issues that impact on implementation. The findings of this work provide insights into actionable steps local health and care services can take to improve the quality of data used to address health inequalities.
- health equity
- health policy
- qualitative research
Data availability statement
Data are available upon reasonable request. The datasets generated and analysed during this study are not publicly available due to ensuring participant confidentiality. Annoymised transcripts can be made available upon request from the corresponding author on reasonable request.
This is an open access article distributed in accordance with the Creative Commons Attribution 4.0 Unported (CC BY 4.0) license, which permits others to copy, redistribute, remix, transform and build upon this work for any purpose, provided the original work is properly cited, a link to the licence is given, and indication of whether changes were made. See: https://creativecommons.org/licenses/by/4.0/ .
https://doi.org/10.1136/bmjopen-2024-084352
Statistics from Altmetric.com
Request permissions.
If you wish to reuse any or all of this article please use the link below which will take you to the Copyright Clearance Center’s RightsLink service. You will be able to get a quick price and instant permission to reuse the content in many different ways.
STRENGTHS AND LIMITATIONS OF THIS STUDY
Semistructured interview questions enabled collection of rich data on health and care professionals’ perspectives on actions to improve quality of data in relation to health inequalities.
Inclusion of a range of participants across health and social care in the East of England.
The study is limited by not being able to interveiw the full spectrum of those involved in health inequality data to decision pathway(s).
Introduction
The COVID-19 pandemic has highlighted the long-standing inequalities in health in the UK. 1–3 There is now a renewed emphasis on the need for action to address these at both the national and system levels. 4 5 This is reflected in the prioritisation of health inequalities in National Health System (NHS) England’s Long-Term Plan 5 and in assigning Integrated Care Systems (ICSs) responsibility to proactively reduce health inequalities. 6
Identifying the locations where health inequalities occur, establishing mechanisms to address them and assessing the impact of interventions depends on good-quality data. 7 8 Criteria on what constitutes ‘good’ can vary, but essentially data need to be fit for purpose. This can be determined by considering characteristics such as completeness, accuracy, relevance, availability and timeliness. 9 Many health-related datasets exist in the UK, and analysis of this data across socioeconomic factors, geography and specific characteristics including those protected by law such as sex, ethnicity or disability and socially excluded groups assist in endeavours to address health inequalities. However, the health data landscape is complex, with variations in data that are collected, its flow across the health and social care system and accessibilty. 10 Furthermore, many datasets either do not routinely collect important information that can assist in identifying, monitoring and addressing health inequalities or are limited by poor quality. 11 12 This means that available data may not always be used to the best extent. 13 Action to ensure datasets are complete and timely was identified as one of five key priorities for the NHS in 2021/2022. 14 15 At present, there is limited guidance available for those working in local health and care services on best practice approaches to improving the quality of data used to address health inequalities.
We previously undertook a scoping review of published scientific and grey literature to identify evidence-based approaches to improving the quality of data used to monitor and address health inequalities. 16 A variety of actions to improve data quality were identified. While most of the studies we identified focused on ethnicity data, the findings were generalisable across other characteristics such as sexual orientation and gender. The identified mechanisms worked across different points of the data to decision-making pathway, and it was evident that often a multilayered approach is needed to ensure data quality is fit for purpose. For example, actions such as mandating data collection and implementing legal safeguards to ensure non-discrimination were important actions upstream of data collection that impacted on data quality by influencing the ability to collect data of a sensitive nature. Staff training to ensure understanding of what data is required and why ensures more effective data collection and completion. Following data collection, approaches such as linking and imputation could be employed to ensure completeness and enable use for analysis and insight. 16
Given the renewed emphasis on efforts to address health inequalities at both a national and a system levels, and the significant role data can play in this context, it is crucial to understand how systems can easily implement the mechanisms described in our review. The objective of this research was to gain insights from professionals working across the health and care sector in England into the types of resources that can be instrumental to implement mechanisms to improve data quality.
Study design
We conducted qualitative research using semistructured interviews to gain insights into the perspectives of professionals working in local health and care and public health systems. The interviews were conducted to investigate their understanding of mechanisms to improve quality of data used to investigate health inequalities and uncover effective strategies to communicate and transition the evidence from our scoping review 16 into practice. The interviews utilised open-ended questions, and a topic guide ( online supplemental file 1 ) was designed prior to interview to guide data collection. The Standards for Reporting Qualitative Research reporting 17 guidelines were used where applicable ( online supplemental file 2 ). The study was designed and conducted by a research team that included both academic and service partners.
Supplemental material
Sampling and recruitment.
Participants included in the study were professionals that had a role in public sector health and social care, public health or third sector organisations in England. Participants had to have as part of their role a responsibility to (1) address health inequalities and/or (2) collect and/or analyse and/or monitor and/or report data that can be used to understand health trends and inequalities at the organisation or regional level.
We worked with key contacts within the National Institutes for Health and Care Research NIHR Applied Research Collaborative East of England (NIHR ARC EoE) and employed purposive sampling using information available in the public domain to recruit relevant and, where appropriate, a sample representative of different roles. This allowed compilations of an initial list of individuals in collaboration with our service partners. In addition, we used a snowballing approach to identify further participants. To ensure participants were able and willing to contribute to the study, eligibility was ascertained by personal communication prior to data collection.
Data collection
Data collection was undertaken through interviews conducted and recorded online via Zoom to provide greater time and location flexibility for participants. This enabled contributions from participants across the East of England. In the participant information sheet, participants were offered in-person or online options. All participants opted for online. Interviews were conversational, thus enabling participants to answer broad questions around their role, understanding of health inequalities, mechanisms to improve data quality and resources or tools that could enable improvements in data quality. Interviews lasted between 45 min and 60 min and two members of the research team, one academic (SM) and one practice-based (EO) undertook each interview to reduce bias and ensure robustness in data collection. Interviews were conducted between January 2023 and May 2023. Data were analysed continuously and recruitment stopped once data saturation was reached.
Interviews were transcribed by the research team (EO and SM) and transcripts anonymised to remove any identifying features. Thematic analysis was carried out using NVivo V.12 software. A deductive approach to coding interview data was initially taken based on the topic guide to categorise the interview data. Three interviews were coded independently by two of the team (SM and EO), coded data were discussed and reviewed. A common coding framework was developed and applied to remaining transcripts. Each transcript was doubly coded, and any discrepancies were resolved by discussion. The coded data were then analysed, an inductive approach used to identify themes and links across themes was identified to extend the findings and help structure and summarise the findings into a coherent and practice-focused narrative. We tabulated frequencies of theme elements to enable visualisation of findings.
Patient and public involvement
Patients and the public were not involved in the design and conduct of this study.
Participants
The characteristics of the 16 interview participants were organised in terms of their organisational representativeness, regional coverage, knowledge of health inequalities and relationship to the data-to-decision-making pathway ( table 1 ). Most participants worked in an organisation from a county within the East of England (87.5%, n=14). All but one participant (93.75%, n=15) expressed some knowledge of health inequalities. Over half the participants worked in the NHS (62.5%, n=10) and were involved in an analyst role (68.75%, n=11).
- View inline
Participant characteristics
Thematic analysis
Findings are grouped under three themes that were drawn from the topic guide. These were:
Awareness of actions to improve data quality.
Challenges in implementation of actions to improve data quality.
Resources that can aid implementation of actions to improve data quality.
Theme 1: Awareness of actions to improve data quality
This theme describes participants’ awareness of mechanisms to improve data quality and which, if any, they have implemented. It also considers the resources used or created to enable improvements in data quality. This question was posed to participants to gain a better understanding of the current state of practice regarding mechanisms to improve data quality.
Most participants we interviewed were aware of mechanisms that could be implemented to enable improvement in data quality (n=13). Two participants acknowledged their awareness of data quality issues, but not of mechanisms for improvements.
Participants cited many of the actions that we had identified in our underlying scoping review, 16 along with specific mechanisms in place to achieve them. The most cited actions to improve data quality were data linkage and staff training programmes ( figure 1 ). The least cited were mechanisms to demonstrate the value or impact of data collection on service provision to a wider audience, for example, senior leaders or the public and patients. Processes that were implemented to maintain the accuracy and completeness of datasets obtained from sources both within and external to participants’ organisations were also not widely cited.
- Download figure
- Open in new tab
- Download powerpoint
Mechanisms to improve data quality. DC, data collection.
The extent to which actions were put into practice varied by organisation (eg, NHS vs council) and in the specifics of the mechanisms described. For example, in relation to staff training programmes, some described the creation of a health inequalities intranet with educational resources, others described approaching this through awareness raising mechanisms such as forums and staff networks. Such resources were developed to improve staff understanding of health inequalities and rationale in collecting data on protected characteristics such as ethnicity.
I think locally what we try to do, for those who are collecting data and sometimes when you speak to GP practices, or at least in the past when we did this. Once you have explained how this information could be used, and the importance of it being right first time. People actually made more of a conscious effort then to make sure it was right the first time, and I think educating or explaining to people who are working, collecting that information and inputting it in the first place, you can put quite a lot of checks in. P3 And because we realized that, you know, people staff are quite uncomfortable asking about ethnicity…. So we gave people a card which we did co-produce a bit with XXX public health, didn't we? …. But a really simple card that had the categories on one side and then on the other there was some basic answers. If people asked why this was needed, a really simple data Protection type level about kind of what you're gonna use this for. P1
This reflected organisations’ development of their own mechanisms depending on specific priorities, needs and circumstances. For example: data needs; stage of organisations in creating and using integrated datasets; stage of developing information governance practices to enable linkage and analysis. These factors influenced the specific resources that were used, created or needed.
Theme 2: Challenges in implementing mechanisms to improve data quality
Factors that were felt to impede efforts to implement actions to improve data quality and undertake work on health inequalities were gathered under this theme. These were further categorised into three broad categories of either organisational issues that resulted in poor data collection, data input or data-related issues that created challenges in optimal data usage and analysis ( figure 2 ).
Challenges in implementing mechanisms to improve data quality. PDC: poor data collection, IG: information governance
Organisational issues that impact on data collection
Participants identified logistical barriers to implementing mechanisms to improve data quality within their organisations. These included workforce time, capacity and funding constraints and team structures that impacted on cross-team or cross-organisational working. A quarter of participants stated that the quality of data deteriorated when data collectors faced time constraints and reduced capacity (n=4). Some NHS professionals attributed poor data collection to lack of incentives and funding (n=2). There was the perception of a bias that larger NHS organisations, due to their greater financial resources, have reporting infrastructures that can adequately capture and record more data, whereas this was not possible for smaller organisations. These workforce time, capacity and funding constraints were not found to be exclusive to the collection stage. Similar issues were cited as impacting analysis, outreach activities across the system and reporting for work on health inequalities (n=3).
Among some NHS professionals, there was a perception that health inequalities were not fully understood within the health system (n=2).
I think health inequalities is poorly understood in the main, I think, for those people that sort of live and breathe it and or actively sort of talking about it. They understand it. But actually, if you talk about health inequalities with frontline clinicians, their view is likely to be very, very different, and I think that’s the biggest hurdle to overcome, and it’s just trying to almost educate the wider workforce around. Why, it’s important for this topic to be understood more broadly. P15
This lack of deep understanding was argued to produce data reporting structures that provided limited information on patient demographics. For example, half of participants related poor data quality to data collectors not knowing what to ask (n=6). This was most often viewed as an issue of prioritisation, where organisations had set collection standards for only a few variables, particularly ethnicity, while neglecting others. One participant noted that there were no established targets for physical disability within their organisation, and so ‘ nobody bother(ed) collecting that data’ .
There was recognition that putting in place mechanisms to improve data quality required leadership and involvement of those across the data-to-decision-making pathway. Some participants described a disconnect between organisational groups working at different stages of the pathway (n=2). Some postulated that those who used intelligence from data such as managers or executives had a better appreciation for a need to implement actions to improve data quality, as they could see the impact of good data on improved care. As one participant in social care reflected:
I think there might be a disconnect, maybe between the people at the top that probably see the value of it, and the people in the frontline that probably don’t have the capacity to be able to collect that information. P5
Conversely, some data intelligence users suggested that senior-level buy-in was typically achieved by reporting the success of work on health inequalities (n=2). This was reported to be a ‘ difficulty’ and a ‘ challenge’ because addressing health inequalities was viewed as a long-term task and immediate impact was hard to evidence. These users felt that they had to provide answers to senior groups and leaders within a short timeframe and show that any actions they implemented were doing the right thing .
Data usage barriers
Issues related to the use and handling of data were also described, namely with reference to datasets. This included the existence of invalid, vague or irrelevant observations in datasets (n=4). These features were recognised as irreparable, despite the availability of quality improvement tools, such as postcode look-ups, for example. In the context of using UK postcodes to measure social deprivation, one analyst noted:
(With postcodes), if they don’t have a space, it’s not such an issue for us (…) we have lots of different lookups that we use to (add or remove spaces) (…) We have issues when someone’s entered a postcode that doesn’t exist. And it’s like, well, you can’t really do anything with that… P1
Two participants cited lack of granularity, where information for health inequality variables exists but is not sufficiently detailed. For example, there was an acknowledged awareness and use of national and interorganisational datasets that had been compiled and distributed for analytical work on health inequalities. However, participants could not exploit datasets in some cases due to data over-aggregation and the presence of broad variable categories. For example, the aggregation of data across large geographical areas such as local authority level, when it was often desired at the district level. Aggregation of ethnicity data into categories such as ‘Asian’ as opposed to ‘Pakistani’, ‘Indian’ etc. These factors were deemed to hinder work on identifying target populations or geographic areas of concern within participants’ region of operation.
Participants also stated that wider interorganisational structures and practices impacted on the ability to link and make use of existing data. This included poor data interoperability between healthcare organisations and systems (n=5) and inconsistency in patient records between different organisations, including community services, the NHS and local authorities. Some attributed the inconsistency to the complexity of service delivery . One participant noted how screening services were provided by several community providers who collect, process and release data through different processes and at varying time points. Despite success in gathering data from these providers, the ability to mobilise this data to address health inequalities was impeded due to fields not being coded congruously.
Information governance rules and costs were also perceived as a barrier for data linkage (n=4). Many participants recognised the value of data from primary care, which was seen as having a higher level of granularity that was not found within local authority or secondary care datasets. They expressed frustration with having to first persuade general practitioners (GPs) to share data and then pay for extraction and linkage, often managed by a third party. It was reported by some participants that GPs may be concerned with data sharing because it was not an action that patients actually agree to be part of explicitly . Some participants cited a lack of trust on the part of patient groups as a barrier for data completeness (n=3). They perceived a poor relationship between patients and staff as an issue within their organisations; and that ethnic minority groups would be more likely to decline providing an ethnicity due to fear or stigma . This issue was also related to discrepancies in data completeness between organisations. As one participant commented:
I also know that people get fed up of always having to tick the boxes (…) ‘I already told my GP, why are you asking me again?’ And then they go to the community services and have to tick the box again. I totally understand why people might be like: ‘I’m not having to do this for the third time as part of my pathway. P16
The absence of a national framework on data sharing was found to be a barrier for data sharing and reporting (n=2). In the case of sharing, this meant that data linkage and accessibility was a complicated and case by case process bound by local organisation-specific information governance rules. One participant from social care attributed “(reporting) inconsistencies across NHS trusts to the absence of a national framework, which could propose guidelines for developing and reporting common measures.
Two participants argued that data were not appropriately used due to lack of data skills such as analytical abilities to understand the data and devise suitable metrics. In cases where the skillset was present, some found that there was little guidance on what variables they should consider during analysis (n=2). One participant had knowledge of relevant methodologies, such as benchmarking or using proxy measures, to investigate hard-to-reach or disadvantaged populations. But this was only applied for ethnicity, and guidance was needed on other variables, such as homelessness and disability.
Theme 3: resources that could aid improve quality of data
Participants were asked to provide examples of resources that are particularly helpful or lacking in efforts to either raise awareness of mechanisms or put in place actions to improve data quality. This was to understand current availability of resources and any gaps or needs that could be addressed.
Currently available resources and gaps
Some participants acknowledged that a wide variety of resources and tools were already available that could aid in efforts to improve data quality. These ranged from information sources on health inequalities and explanation of indicators. These can help by improving awareness around health inequalities and data collection efforts. In addition, for those involved in analysing data, packages that can aid in data analysis and forums for discussion of analytical approaches were available. However, participants also indicated that these resources were created by different groups and organisations, therefore not collated or catalogued and accessible from a single reliable source.
I think that would be helpful to kind of have the one place to go to where you could get like you say, all the information and kind of different steps that you could take all the other people have taken which I don't really well, doesn't exist at the moment. So if it does exist, maybe it needs to be public. P1
This meant that while many resources were available, finding them and ensuring they were appropriate were time-consuming. One participant expressed difficulty in choosing a resource from several available options. They found that it was difficult to navigate what’s new and what’s a repeat during interorganisational meetings.
Desired resources
As participants who were interviewed were for the most part aware of mechanisms that could be put in place to improve data quality, the resources they requested were in supporting delivery of these efforts. Specific suggestions that were put forward by participants were grouped under four categories ( table 2 ) and are discussed below.
Categories of resources suggested by interview participants
National guidance, standards and frameworks to support action along the data to decision pathway
National guidance in different areas was put forward as being needed, in particular, for a shared understanding of health inequalities. Many interview participants cited the fact that ‘health inequalities’ was a broad term, with variation across the health and social care system on how it is viewed and conceptualised. This is also reflected by differences in particular aspects or questions in relation to health inequalities that are the focus of different organisations and groups or teams across the health and care system. Therefore, how health inequalities are conceptualised, impacts on data requirements and whether data quality is considered fit for purpose. In addition, while addressing health inequalities was a policy priority, there were differences, and sometimes a lack in understanding of what this meant, especially for many who do not directly work on tackling inequalities but nevertheless contribute to the data to impact pathway, for example, data collectors such as clinicians or high-level decision-makers such as hospital medical directors or those who sit on boards for ICSs. Therefore, a shared understanding around health inequalities can also aid individuals who are involved either directly or indirectly in the data to decision pathway implement actions and efforts to improve data quality.
Because how you see health inequalities from different lens, and everyone is contributing to it. But it is slightly different, and you know, and everyone have to play their part to bridge this gap. Having that clarity would really help people to do that. P8
Many participants, especially analysts, stated that while they were aware of mechanisms that can support actions to improve data quality, it was unclear what was best practice in relation to these. In particular, best practice in relation to the following was reported as being useful:
Categorisation of particular variables such as ethnicity.
Methodological approaches to data analysis.
Data collection and ensuring data completion.
Sharing of what works/lessons learnt between organisations and systems.
Many participants discussed how sharing of strategies and mechanisms employed by other organisations could inform the resources they develop or practices they undertake in improving data quality. This was perceived as being especially useful where organisations and/or systems were at different stages of achieving integrated data and taking different approaches to solving common issues. For example, navigating information governance processes across organisations was an oft-cited barrier ( figure 2 ). In addition, incomplete data were also a common problem faced by different teams and organisations. Therefore, sharing approaches that had been taken in addressing common issues would be useful learning.
Communication across the data to decision pathway within organisations and groups.
Participants also stated that communication across different individuals, teams and organisations was required to enable improvements in data quality. Many cited case studies to demonstrate the value of data and data-to-impact pathway as a means to enact change.
The more we sort of say, you know that the importance of using data to form evidence-based sort of outcomes, or projects and programs the more they’ll become more embedded in all programmes at work. P15
However, they also acknowledged that such case studies would have to be adapted to meet the needs of the different roles along this pathway and take into consideration different data to decision-making pathways.
Participants also stated that the role of data and its impact need to be better communicated. This is because achieving senior-level buy-in, encouraging better data collection and contribution from patients and the public requires demonstration of impact. Therefore, developing resources that could demonstrate the value of the data and its impact is important for incentivisation. Inclusion of information on how data is processed or analysed to address inequalities was also put forward as an important aspect. This was seen as being useful in addressing concerns on uses of the data and in improving understanding and trust of how data are handled and processed. It could also provide an opportunity to demonstrate how different stakeholders contribute to the data to decision-making pathway and in improving data quality. In addition, this was felt as particularly important for users of health intelligence, as it enables them to better understand how improvements in data quality can impact on producing informative intelligence.
I would really like to see if it’s available on a website that would be great, where you've got the sort of the whole process from data collection all the way through to potentially interpretation. So that then you can make decisions based on the information that comes out of it after processing all that data and doing all the analytics. And it'd be really nice to have that quality step along the entire analytical pathway. P4
Tools to aid health inequalities data analysis
Many participants stated that practical resources to aid analyses pertaining to health inequalities would also be helpful. For example, a data catalogue that had information on different data sources available, meta-data on the variables and suitability for use in different types of analysis were proposed. Participants also noted that there were similarities in the types of questions asked across organisations, therefore best practice guidance in answering common or routine questions, data that can be utilised for this, and caveats in available data would be useful.
Addressing and monitoring health inequalities continue to be an important policy goal that is reliant on good-quality data. A variety of mechanisms exist to improve the quality of data used for this purpose. 16 This study was conducted to explore effective ways to improve knowledge and implement these mechanisms in practice.
Interviews with health and care professionals suggest that most are aware of the mechanisms we identified in our scoping review. We also evidenced examples of how these mechanisms had been embedded in practice. However, it was apparent that the evolving health and care data ecosystem in the East of England and nationally meant that different organisations were at different stages of addressing data quality issues and were taking different approaches to do so. It was recognised that more needed to be done and several barriers that impeded efforts to improve data quality were cited. This included logistical factors such as having a data-skilled workforce, capacity and functioning issues in a resource-constrained environment, and system-level issues such as creating interoperable data systems and information governance structures to support better data use. Many of these have been cited as issues in previous work on better use of data for healthcare. 18–20
This study identified that different approaches were needed to both increase awareness of the variety of mechanisms that could be employed to improve data quality as well as support their delivery. When asked about resources that could support current practice, suggestions included developing national guidance, standards and frameworks to support action along the data to decision-making pathway. For example, some participants argued that the absence of a national framework was a perceived barrier for data sharing and reporting on health inequalities. Some national frameworks have considered improvements to the quality of health data. 21 22 For instance, the NHS England operating framework asks National Programme teams to set expectations and guidance on data standards. 22 This suggests that current national guidance, while useful in acknowledging the importance of data quality, may need to extend beyond data collection and collation to more comprehensive guidance on data usage and be promoted within organisations as much as possible.
It was evident from our interviews that individuals and teams often created their own resources to enable engagement on mechanisms to improve data quality. This is unsurprising given the complex data landscape. 10 Participants stated that sharing strategies and mechanisms employed by other organisations such as different NHS Trusts across the country would be helpful. This includes strategies employed to improve data collection, information governance structures that work well and tools that can be used in data analysis, for example, in the specific context of population health management. 23 24 Learning from these would be useful in enabling a more consistent approach. Case studies were suggested as one mechanism through which examples of approaches taken could be shared among different individuals, organisations and systems.
Overall, resources that can aid in creating a shared understanding around health inequalities and improving mechanisms to share knowledge between different systems, organisations and individuals were key. A better understanding of inequalities can also help frame and formulate appropriate questions, which in turn enables assessment of data quality parameters. Data quality is characterised by completeness, accuracy, relevance, accessibility and timeliness. 9 While there was consensus that mechanisms could be put in place to improve factors such as data collection and granularity of data, there was also a recognition that for some purposes data quality was adequate. This understanding is also required to enable interpretation of intelligence gained from data analysis.
Differences in understanding of what health inequalities means both conceptually and from various practice perspectives have been raised by others as an issue that impacts on practical actions that are taken. 25 26 Furthermore, the importance of framing inequalities in a way that is relevant for different organisations and individuals across the health sector has also been raised to enable more effective action. 27 28 Understanding is also needed by the wider public, as it can aid in creating trust and a better understanding of how data are used. This is a critical building block to enable better data collection, especially around protected characteristics, and to address concerns around stigmatisation. 8 29 30 The need for deliberation and engagement with the wider public to design the best approaches to collect sensitive data, as well as with data collectors to improve health inequality literacy, was one of the actions identified by our previous review to improve data quality. 31 32
Improving communication between individuals across the data to decision pathway was also felt to be an important action to achieve improvements in data quality. This is because a variety of health professionals are involved across different pathways and differentially contribute to improving data quality. For example, data collection is often undertaken by front-line staff, whereas analysis and use of data intelligence will be led by other professionals. Some participants noted that users of data intelligence may have a better appreciation for a need to implement actions to improve data quality than collectors. This demonstrates the importance for organisations to introduce communication channels between both groups when absent, and support channels that have developed, to enable better collection and use of data. Indeed, efforts to improve data quality require input from a variety of individuals across the data to decision pathway, and data quality improvement strategies often require assessing this pathway. 33
Most participants worked in an analytical role; hence resources to assist with data analysis were also deemed important. Suggestions put forward, were repositories that could support data analysis such as those providing information on suitable data sets and methodological approaches that could be applied in data analysis. In addition, while many participants were aware of common knowledge sharing platforms (eg, FutureNHS) and data collections (eg, Fingertips), there is still a need for improving this awareness across groups and organisations.
Strengths and limitations of this study
Using a qualitative approach has allowed us to explore the needs of health and care professionals and identify key features and types of resources that can aid in embedding practices to improve data quality. Our approach of using open-ended questions in the interviews, allowed participants to speak openly and enabled gathering of rich data. Data coding was carried out independently initially, and following development of a coding frame, all transcripts were double-coded to ensure consistency. Interpretation of findings were discussed among the team and further validated by sharing with interviewees.
The study included a range of participants; however, we were not able to interview the full spectrum of roles involved in health inequality data to decision pathways. In particular, those involved in senior decision-making roles, data collectors and data managers were not represented in our sample. In addition, given the variety in data to decision-making pathways in existence, it is likely that the needs of each pathway may differ. Thus, our findings may not reflect the full spectrum of perspectives across the health and care system. Also most of our participants were based in the East of England region, potentially influencing generalisability of findings, especially to international contexts. Nevertheless, the core functions of any resources that would help embed evidence-based mechanisms to improve data quality may be applicable to a range of settings.
Conclusions
This study identified the types of tools or resources that could help embed mechanisms to improve the quality of data used to monitor and address health inequalities. These resources would have to take a variety of shapes, given the diversity of health and care professionals who contribute to data quality improvement efforts. The development of case studies to engage with the broad range of individuals who contribute to the data to decision pathway was highlighted as a potentially useful resource. We are currently working on developing and testing the impact of such case studies. Finally, while good-quality data are important in efforts to investigate and address health inequalities, it forms part of a larger landscape of efforts needed. 27
Ethics statements
Patient consent for publication.
Not applicable.
Ethics approval
The study was approved by the Humanities and Social Sciences Research Ethics Committee (HSSREC) at the University of Cambridge (HSS rec reference 22.313). Participants gave informed consent to participate in the study before taking part.
Acknowledgments
We would like to thank all the health and care professionals who gave their time to participate in this study.
- Riordan R ,
- Ford J , et al
- Goldblatt P , et al
- NHS England Providers
- Spencer J ,
- The Government Data Quality Hub
- Gallifant J , et al
- Office for National Statistics (ONS)
- Shimkhada R ,
- Adkins-Jackson PB
- Moorthie S ,
- Evans S , et al
- O’Brien BC ,
- Harris IB ,
- Beckman TJ , et al
- Goldacre B ,
- Steventon A
- Zhang Y , et al
- Barrett J ,
- Fennessy C , et al
- NHS England
- Steenkamer BM ,
- Drewes HW ,
- Heijink R , et al
- van Ede AFTM ,
- Minderhout RN ,
- Stein KV , et al
- Olivera JN ,
- Sowden S , et al
- Marcellus L , et al
- Olivera J , et al
- Shahram SZ ,
- Dang PTH , et al
- Parbery-Clark C ,
- Nicholls R ,
- McSweeney L , et al
- Ventura-DiPersia C , et al
- Stockdale R
Contributors SM and LL conceived of the study. Protocol development was led by SM and LL, with contributions from SE, EO and CB. SM and EO led the data collection and analysis, all authors discussed the findings and interpretation. Manuscript writing was led by SM and EO with contributions from all other authors. All authors approved the final version. The guarantor of the study is LL; accepts full responsibility for the finished work and/or the conduct of the study, had access to the data and controlled the decision to publish.
Funding SM, EO, LL and SE are supported in part by the NIHR Applied Research Collaboration East of England (ARC EoE). The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health and Social Care or Cambridgeshire County Council. NIHR Applied Research Collaboration East of England, grant number G104017.
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer-reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.
Read the full text or download the PDF:
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
A patient-centered conceptual model of aya cancer survivorship care informed by a qualitative interview study.

Simple Summary
1. introduction, 2.1. recruitment, 2.2. interview approach, 2.3. analysis, 3.1. overall themes, 3.2. care coordination and healthcare system navigation support.
“So there really wasn’t much time. Or was there? I didn’t know to ask that question. Okay, I know this is growing—is there enough time for me to get a consultation? I don’t know if maybe I could have waited a few days. I just don’t know, because I didn’t know that question to ask... But I just went ahead and signed away because I felt like I was—I hate to say the word bullied, but I felt like I was in a corner. I was like oh my god—this cancer’s bigger than me, just get it out, kill it! Do what you need to do.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“I, I mostly blamed myself for my inexperience in hospitals, I guess. But yeah, I felt like people weren’t necessarily completely clear, well, telling me exactly what I had to do. What I should do. Like when I should ask for help or when I didn’t need to, that sort of thing.”— Participant 2, female, renal cell carcinoma, 30–39 years old at diagnosis .
“I felt like I had to be the care coordinator. I had to make sure everybody knew what the other was doing. Proactively ask for appointments—like okay, I’m going to have to get radiation next. And they’re like oh, you can wait for that until the week before, and I was like, but what if I don’t like [the provider]? You’re going to put me in a box. So I had to just be proactive to get the kind of care that I wanted to get. And I felt like my care coordinator, which is exhausting.”— Participant 4, female, breast cancer, 30–39 years old at diagnosis .
“I was first getting treatment somewhere and I didn’t feel completely taken care of there. As a nurse practitioner, I felt like I was asking—I was supposed to be a patient then, I wasn’t supposed to be a health care provider. So I felt like I was directing my care and I was reminding them of things. It didn’t feel like the right fit for me with my oncologist and the care team, so I ended up after getting a second opinion switching to another hospital.”— Participant 3, female, Hodgkin’s lymphoma, 20–29 years old at diagnosis .
“Gosh, that’s really why I became an advocate—I just couldn’t believe the lack of treating me as a holistic person. I understand that I guess to be an oncologist you’re going to meet patients who ultimately die from it, and I get that they’re trying to make sure that you don’t die, and that is of course great, you kind of need that. But what about a nurse navigator or even like the nurse? There was no follow up... there needs to be a middle person. Whether it be that nurse or that social worker, and it should be mandatory that every AYA... have an initial conversation [with them] and then determine if you want to work with them...The follow ups just go through the cracks.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“I felt like my oncologist was very good at giving me medications to deal with nausea and other side effects when I needed them...But I had to research online what are things that I could use and then go and ask for it, as opposed to someone presenting me with “these are all the resources” or “these are things you should consider, let us know what you need”. I felt like the latter would have been much more helpful. I went to [other specialty cancer centers, and] both of those hospitals did provide that. Like “here’s your coordinator, here’s a whole pamphlet, here’s all the resources we have. Here’s how you use each one”. So I thought that was really cool.”— Participant 4, female, breast cancer, 30–39 years old at diagnosis .
3.3. Mental Health Support
“Definitely anxiety, depression for sure. I think those would be the biggest two that I’ve had to deal with. It’s an everyday struggle … Anxious about my cancer getting worse or also having cancer in my family or friends, since I already know what it feels like, having cancer. I wouldn’t want any of my loved ones to go through the same thing.”— Participant 6, female, breast cancer, 30–39 years old at diagnosis .
“Cancer is trauma, and even though a lot may not equate it with that term, because they just don’t know, a lot of us have PTSD. And that’s not talked about enough… every experience in the AYA community matters. So that might be why someone would not [talk to a researcher about their cancer experience], because they might feel like you could talk to someone better. It’s really about insecurity, but also too how they’ve been treated throughout their treatment. It can be hard to discuss and be traumatic. I can now verbally talk about it without bursting into tears, but not everyone can.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“Obviously having cancer kind of like fucks you up mentally. But I’ve been going to therapy, I actually take an antianxiety med now.”— Participant 8, female, Hodgkin’s lymphoma, 15–19 years old at diagnosis .
“Like I thought, I thought I was alone for like five years … Post treatment I actually had a really bad depressive episode, because I was just in such despair because I thought I was alone and no one else was like me. And I did hours of searching and finally found a couple of organizations that led me to other things. But I would have liked to have those resources [earlier], I wouldn’t have felt so alone.”— Participant 8, female, Hodgkin’s lymphoma, 15–19 years old at diagnosis .
“I actually learned about the support groups from Instagram … just as a young Black woman, [it was important] to see other women of color that were young and that looked like me, because I was not seeing that at my cancer center. So that was a huge support for me. Also, just by sharing my story, it allowed me to pay it forward to other young adults and also inspired me to get involved in advocacy work.”— Participant 9, female, breast cancer, 30–39 years old at diagnosis .
3.4. Peer Support and Making “Cancer Friends”
“It’s bad enough I’m an AYA, it’s bad enough I’m Black, it’s bad enough I’m a woman, it’s bad enough that I am an only child. I feel like all of these things were hitting me—and I have cancer, and now I literally have no one? It’s been hard.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“So, I think at the time the quintessential experience of being the youngest person at the cancer center in the waiting room, you know, not seeing anybody else my age unless they were in a caregiver capacity... And just feeling like I was the only person my age that had cancer and was getting treatment. And so the experience was very different when you are under 40. I didn’t know other people that had gone through that at the time.”— Participant 10, male, testicular cancer, 30–39 years old at diagnosis .
“As I was nearing the end of chemotherapy, I was feeling like I couldn’t really talk to my friends the same, and I didn’t really have people to relate to, and I felt like an astronaut. My brain was foggy, I really wanted to talk to someone about [my side effects and stuff] without worrying people. I remember Stupid Cancer was the big [AYA organization] at the time, and I saw that they had in-person Meetups. I decided to go … and then I instantly was like oh, maybe this [is] a window into a community I didn’t even know existed. I didn’t picture people in their 20s and 30s with cancer hanging out before this. That was the beginning of making cancer friends, [we have fun but] also if someone does need to vent about their situation, treatment, insurance, or relationships going away because of cancer, you’re the perfect [person] to talk to about it.”— Participant 11, male, testicular cancer, 30–39 years old at diagnosis .
“I went through a lot of side effects. I literally had the motherlode of side effects and what was very hurtful was when my oncologist would be like yeah, you know, a lot of patients get that. Well, it’s my first time seeing my tongue turn black, so you might want to have some sort of—I don’t know, like compassion for how freaked out I would be. Even my throat would swell and I had difficulty swallowing. ‘Oh, I’ve seen it before, I’ve seen worse.’ Well, I’ve never seen worse.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“I wish that that there was an AYA program at the hospital to tell me about these resources. To tell me like, hey, there’s a Gilda’s Club, it’s 10 to 15 min from here. There’s a meeting once a month. You can go and meet people your own age. It’s safe. People are really cool. Check it out. And now you can join these virtually. Just having somebody to say to me that is totally normal to feel that way. There are other people your age that get treatment here and you can meet them. That would have been really awesome.”— Participant 10, male, testicular cancer, 30–39 years old at diagnosis .
“I think just introducing for patients, that adolescent young adult oncology exists, and there is support out there for AYA’s. I didn’t really dive into the AYA support community until after treatment and got connected to a lot of resources and a lot of friends that way. But I think if I had known that resources like that existed while I was going through treatment, it would have been helpful just to know that I wasn’t alone and all these amazing organizations exist.”— Participant 12, female, osteosarcoma, 15–19 years old at diagnosis .
3.5. Empathic Communication about Fertility Preservation
“When I got diagnosed in the hospital … they had brought in a blood specialist and he described leukemia to me … After he left one of the interns immediately asked me, like so do you have any kids? And I was like no. And he was like, have you thought about freezing your eggs? And I’m like, dude, this dude just told me about cancer, like I haven’t, I can’t talk about kids right now like. You know?”— Participant 13, female, leukemia, 20–29 years old at diagnosis .
“The timing was rushed because it was overwhelming. I feel like if you sit down with anybody, man, woman, whatever, and tell them you might not be able to have kids, that’s pretty heavy and something you want to sit with. And … it’s not like it was free to go get the sperm banking done and have it stored. But I was like well, if I don’t do this, that might be it, I might never have kids. Even if I don’t want them at the moment, taking the option off just seemed scary. So yeah, I would have liked to have had more time.”— Participant 11, male, testicular cancer, 30–39 years old at diagnosis .
“Everything for me happened within like three days, so there was no, no ability to like, I don’t even know what it’s called. But to … freeze my eggs, I didn’t have that option because of the type of cancer I had everything had to be done so quickly. The only thing I was told in regards to fertility is you may not be able to have kids. There’s a high likelihood with the chemotherapy you are receiving that you may not be able to have children after this. There was no offering of like any type of resources. I only found that out afterwards, [about] all like the different type of programs for patients.”— Participant 15, female, leukemia, 20–29 years old at diagnosis .
“We talked about [fertility preservation] in [my support] group before and I guess, well, I mean for guys it’s easy, so they’re super on top of it as far as when we spoke about it. But a lot of [women] who were in similar positions to me where it was all just really sad. From my experience [the doctors] were like, okay, you’re here now, here’s your doctor, here’s your treatment. Oh, by the way there’s this [fertility preservation option], we kind of want to get started right now, so could you just not [have kids] … It wasn’t a huge deal, but I was a little sad.”— Participant 14, female, leukemia, 20–29 years old at diagnosis .
“There should have been a follow up call [after my diagnosis]. Because that was a really intense moment. My first time as the patient … Why wasn’t there a follow up? Like hey, I know you just heard a lot of information, let’s talk about this. I feel like I should have at least been required to get a consultation with an infertility specialist, even though it wouldn’t have been covered under my insurance. I feel that conversation should at least have been had so they could make sure I was really making the best decision for myself at that time. Sorry, I get really passionate and very angered about it.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“I lost my fertility. No one prepared me for that. I didn’t receive initial counseling going into that surgery or coming out of it. I didn’t expect to experience that kind of grief, because I was single all this time, and childless, and now I am chronically single and barren forever. None of my doctors cared to see how that would affect me.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
“I don’t really have trouble communicating with [doctors]. I’m a lawyer and I did a lot of research, so I generally got the comments that ‘oh, you’re so knowledgeable, you’re an easy patient.’ [But] I don’t think they necessarily answered all my questions, or gave me all the resources that were available, or were upfront about side effects, which I found frustrating…[the doctors failed] to mention fertility resources [so] I found my own stuff … I certainly wouldn’t say I got most of my information from my oncologist, but I found it in other places.”— Participant 4, female, breast cancer, 30–39 years old at diagnosis .
“My oncologist is very respectful of my wishes in terms of wanting to have another baby … but then [she] also wasn’t afraid to tell me, you know, we can only do one round of harvesting your eggs, because it’s not safe to do more. She did a really good job acknowledging my dream and weighing that accordingly, [so] I’m not risking life … but I’m still able to try to, you know, preserve my fertility before having this definitive surgery.”— Participant 5, female, ovarian cancer, 30–39 years old at diagnosis .
“Before I started chemo, my social worker came to talk to me in the hospital room and she just wanted me to know like hey, your doctors want you to do chemo, but you don’t have to do it right now, you can work on the fertility thing, if it’s important to you. So she made me feel comfortable that it was okay to delay the treatment.”— Participant 7, female, leukemia, 20–29 years old at diagnosis .
3.6. Financial Burden and Need for Support
“We needed help, we had help from family and friends, but again, the financial burden … is just a nightmare. You got the financial burden, you got the paperwork. You’re supposed to be focusing on your health.”— Participant 5, female, ovarian cancer, 30–39 years old at diagnosis .
“I worked in fine dining and didn’t have any insurance … And then the diagnosis alone racked up I think tens of thousands of [dollars in] debt and I was just through biopsies and scans and you know. I was going to, which is laughable, but it was called free clinic. It took a long time before I was diagnosed; go get bloodwork, come back in two weeks, schedule another appointment for two weeks later. And debt was mounting.”— Participant 16, male, Hodgkin’s lymphoma, 20–29 years old at diagnosis .
“I probably know more about the American health services than I ever wanted to know … it’s just not the way I would have liked to have learned it.”— Participant 8, female, Hodgkin’s lymphoma, 15–19 years old at diagnosis .
“With my age I am able to be on my dad’s insurance and it is a really good insurance plan. So it hasn’t been like insanely expensive or anything … But as I approach my 26th birthday, the cutoff [of staying on my parents’ insurance], I have lots of concerns with finding good health care on my own.”— Participant 14, female, leukemia, 20–29 years old at diagnosis .
3.7. Quality of Life
“When I was first diagnosed I was studying for a board license for civil engineering. I was still thinking I’m going to be in chemo for eight hours, I’ll have a lot of time to study at the hospital. It wasn’t like that at all. That’s when I was in denial, and I think after that, that’s when depression hit me. I was like you know what? It’s over, I’m just going to keep my job now. There’s no way I can study for the exam … Sometimes in my back of my mind I’m still thinking I want to be a licensed engineer and all I have to do is pass that exam. I start dreaming that when I pass the exam, I’m going to get my promotion and travel more, which I used to do before diagnosis … I guess career-wise I still think about getting my license, even if I don’t keep working in the engineering field, I want to feel accomplished. I want to be able to say even through or despite cancer, I was still able to accomplish that.”— Participant 6, female, breast cancer, 30–39 years old at diagnosis .
“So because I got sick, at least with my internship hours, I could have been done last December. But I was going through treatment. And my friend and I were collecting hours and going to school at the same time. She already finished herself, got certified, she’s my boss right now. She’s my supervisor. We were like at the same level, she’s already above me. So and she doesn’t treat me any lower, but I’m still a little upset sometimes because I could have been there by now if I hadn’t gotten sick.”— Participant 13, female, leukemia, 20–29 years old at diagnosis .
“I’ve been a dog groomer on and off for about 10 years. And I when I was finally able to get back into work [right after my surgery], I felt like they didn’t understand what I was going through. Like I was very anxious, and there’s a lot of sounds in a grooming salon. And it was really putting me on edge. And I started to wear earplugs to deal with that. And then I started getting like looks from my coworkers and like I just started to feel less and less welcome there. And I just gave up on it and I ended up quitting that job. I just didn’t feel very good there anymore.”— Participant 2, female, renal cell carcinoma, 30–39 years old at diagnosis .
“I did officially go back up to my regular hours, but there are some days that I take time off for appointments. I try to schedule for example my scans in one day, for example, so I only have to take one day off whenever I can…It’s not just cancer that we deal with, we still have to deal with what other people go through as well, for example taking time out for dental and eye doctor appointments. I still have to take time off for that.”— Participant 6, female, breast cancer, 30–39 years old at diagnosis .
“I had never been to the hospital before. And so I had to go through getting my diagnosis. Going through all these different procedures. And every one alone. They transferred me because they didn’t have the resources where I live to treat me. They transferred me to Houston, so my life got uprooted. My job put on hold. I had to move about five hours away so I could get treatment.”— Participant 13, female, leukemia, 20–29 years old at diagnosis .
3.8. Information about and Support Mitigating Side Effects and Late Effects
“The important elements for young adult cancer care compared to the typical cancer patient that you think of, like 50, 60, 70, they’re worried more about the here and now, and they don’t necessarily have to worry about side effects 20, 30 years down the road, because life expectancy, they won’t be there. I was diagnosed at 25. God willing, I’ll be alive for 50 more years beyond that. I don’t want to be dealing with side effects for years on end, so if there’s an option that’s a little bit more conservative treatment, which will possibly result in less side effects but maybe instead of saying it’s 100% certain, it’s 80% certain. That’s a 20% difference, so I think addressing that in terms that are easily understood by young adults, and also not in a talk down to manner, is super important.”— Participant 17, male, testicular cancer, 20–29 years old at diagnosis .
“Oh, and then the thing I always forget are the other secondary effects of treatment. I had to have both shoulders and both hips replaced, and I had no idea that was going to be in my future whatsoever, at the time of treatment.”— Participant 18, female, leukemia, 20–29 years old at diagnosis .
“I have osteoporosis and I’m not even 25 yet, so that’s kind of concerning for the future.”— Participant 14, female, leukemia, 20–29 years old at diagnosis .
“The one thing I do deal with is, because of all the surgery I’ve had, I have chronic nerve pain, nerve damage, so that’s not fun to deal with. I wish I would have known that it was a possibility, because I was not told that it was a possibility that this could happen.”— Participant 19, female, sarcoma, 15–19 years old at diagnosis .
“I’ve got major issues with the majority of my organs. I have liver damage. I have heart failure. I was in a wheelchair for a while. I was on bedrest for a very long time right after everything. I am disabled. I am on disability. And I do not have the energy I once did. Napping and every couple days just being totally exhausted is kind of part of my life.”— Participant 20, female, leukemia, 30–39 years old at diagnosis .
“I have permanent damage—I don’t feel my feet, my toes from the upper balls to my toes. Sometimes the numbness goes up my legs… and I’ve fallen, actually almost fractured my ankle in January because I didn’t feel my foot. It was so sudden and severe, and … no one seemed to take it as seriously as I did, which is frustrating.”— Participant 1, female, breast cancer, 30–39 years old at diagnosis .
3.9. Attention to the Unique Needs of Young Adults
“[My center had] an AYA program. Granted, they have so much volume because they have a special unit, so I think volume begets resources. But they have providers who are knowledgeable and not just oncologists, but lots of different providers who are knowledgeable about issues that AYA’s face, especially fertility. Sometimes we respond differently to drugs. If every center could have somebody who has a special research focus, to keep up to date on AYA’s. Or a pamphlet, a website, that even would have been helpful. I feel like there’s many ways to skin the cat, but it’s just providing age-appropriate information.”— Participant 4, female, breast cancer, 30–39 years old at diagnosis .
“But I definitely wanted more [young adult] support specifically. And not just in general cancer support, I went through this huge ordeal; it’s completely life changing. And I just, to me the more support I’m getting I feel more in control and I have more power.”— Participant 5, female, ovarian cancer, 30–39 years old at diagnosis .
4. Discussion
4.1. care coordination and healthcare system navigation, 4.2. mental health support, 4.3. aya peer support, 4.4. empathic communication about fertility preservation, 4.5. financial burden, 4.6. quality of life, 4.7. education and support regarding side effects and late effects, 4.8. attention to the unique needs of young adults, 4.9. limitations, 4.10. implications for cancer survivors, 5. conclusions, supplementary materials, author contributions, institutional review board statement, informed consent statement, data availability statement, acknowledgments, conflicts of interest.
- Nekhlyudov, L.; Mollica, M.A.; Jacobsen, P.B.; Mayer, D.K.; Shulman, L.N.; Geiger, A.M. Developing a Quality of Cancer Survi-vorship Care Framework: Implications for Clinical Care, Research, and Policy. J. Natl. Cancer Inst. 2019 , 111 , djz089. [ Google Scholar ] [ CrossRef ]
- Andersen, R.M. Revisiting the Behavioral Model and Access to Medical Care: Does it Matter? J. Health Soc. Behav. 1995 , 36 , 1–10. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Moore, A.R. Qualitative Study of Factors Contributing to Fertility Service Use Among Cancer Survivors of Reproductive Age in the US. Ph.D. Thesis, Georgia Southern University, Statesboro, GA, USA, 2021. Volume 2353. [ Google Scholar ]
- Canzona, M.R.; Victorson, D.E.; Murphy, K.; Clayman, M.L.; Patel, B.; Puccinelli-Ortega, N.; McLean, T.W.; Harry, O.; Little-Greene, D.; Salsman, J.M. A Conceptual Model of Fertility Concerns Among Adolescents and Young Adults with Cancer. Psycho-Oncology 2021 , 30 , 1383–1392. [ Google Scholar ] [ CrossRef ]
- Bober, S.L.; Varela, V.S. Sexuality in Adult Cancer Survivors: Challenges and Intervention. J. Clin. Oncol. 2012 , 30 , 3712–3719. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Danhauer, S.C.; Canzona, M.; Tucker-Seeley, R.D.; Reeve, B.B.; Nightingale, C.L.; Howard, D.S.; Puccinelli-Ortega, N.; Little-Greene, D.; Salsman, J.M. Stakeholder-Informed Conceptual Framework for Financial Burden Among Adolescents and Young Adults with Cancer. Psycho-Oncology 2021 , 31 , 597–605. [ Google Scholar ] [ CrossRef ]
- Courneya, K.S.; Friedenreich, C.M. Framework PEACE: An organizational model for examining physical exercise across the cancer experience. Ann. Behav. Med. 2001 , 23 , 263–272. [ Google Scholar ] [ CrossRef ]
- Strauser, D.R.; Jones, A.; Chiu, C.-Y.; Tansey, T.; Chan, F. Career Development of Young Adult Cancer Survivors: A Conceptual Framework. J. Vocat. Rehabil. 2015 , 42 , 167–176. [ Google Scholar ] [ CrossRef ]
- Le Boutillier, C.; Archer, S.; Barry, C.; King, A.; Mansfield, L.; Urch, C. Conceptual Framework for Living with and Beyond Cancer: A Systematic Review and Narrative Synthesis. Psycho-Oncology 2019 , 28 , 948–959. [ Google Scholar ] [ CrossRef ]
- Matheson, L.; Boulton, M.; Lavender, V.; Collins, G.; Mitchell-Floyd, T.; Watson, E. The Experiences of Young Adults with Hodgkin Lymphoma Transitioning to Survivorship: A Grounded Theory Study. Oncol. Nurs. Forum 2016 , 43 , E195–E2014. [ Google Scholar ] [ CrossRef ]
- Haase, J.E. The Adolescent Resilience Model as a Guide to Interventions. J. Pediatr. Oncol. Nurs. 2004 , 21 , 289–299. [ Google Scholar ] [ CrossRef ]
- Kroenke, C.H. A Conceptual Model of Social Networks and Mechanisms of Cancer Mortality, and Potential Strategies to Improve Survival. Transl. Behav. Med. 2018 , 8 , 629–642. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Luberto, C.M.; Hall, D.L.; Chad-Friedman, E.; Park, E.R. Theoretical Rationale and Case Illustration of Mindfulness-Based Cognitive Therapy for Fear of Cancer Recurrence. J. Clin. Psychol. Med. Settings 2019 , 26 , 449–460. [ Google Scholar ] [ CrossRef ]
- Warner, E.L.; Kent, E.E.; Trevino, K.M.; Parsons, H.M.; Zebrack, B.J.; Kirchhoff, A.C. Social Well-Being Among Adolescents and Young Adults with Cancer: A Systematic Review. Cancer 2016 , 122 , 1029–1037. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Clinical Oncology Society of Australia Model of Survivorship Care Working Group. Model of Survivorship Care: Critical Components of Cancer Survivorship Care in Australia Position Statement ; Clinical Oncology Society of Australia Model of Survivorship Care Working Group: Sydney, Australia, 2016. [ Google Scholar ]
- Taylor, R.M.; Pearce, S.; Gibson, F.; Fern, L.; Whelan, J. Developing a Conceptual Model of Teenage and Young Adult Experiences of Cancer through Meta-Synthesis. Int. J. Nurs. Stud. 2013 , 50 , 832–846. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Fern, L.A.; Taylor, R.M.; Whelan, J.; Pearce, S.; Grew, T.; Brooman, K.; Starkey, C.; Millington, H.; Ashton, J.; Gibson, F. The Art of Age-Appropriate Care: Reflecting on a Conceptual Model of the Cancer Experience for Teenagers and Young Adults. Cancer Nurs. 2013 , 36 , E27–E38. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hammond, C. Against a Singular Message of Distinctness: Challenging Dominant Representations of Adolescents and Young Adults in Oncology. J. Adolesc. Young-Adult Oncol. 2017 , 6 , 45–49. [ Google Scholar ] [ CrossRef ]
- Braun, V.; Clarke, V. Reflecting on reflexive thematic analysis. Qual. Res. Sport Exerc. Health 2019 , 11 , 589–597. [ Google Scholar ] [ CrossRef ]
- Byrne, D. A worked example of Braun and Clarke’s approach to reflexive thematic analysis. Qual. Quant. 2021 , 56 , 1391–1412. [ Google Scholar ] [ CrossRef ]
- Neubauer, B.E.; Witkop, C.T.; Varpio, L. How phenomenology can help us learn from the experiences of others. Perspect. Med. Educ. 2019 , 8 , 90–97. [ Google Scholar ] [ CrossRef ]
- Tong, A.; Sainsbury, P.; Craig, J. Consolidated criteria for reporting qualitative research (COREQ): A 32-item checklist for interviews and focus groups. Int. J. Qual. Health Care 2007 , 19 , 349–357. [ Google Scholar ] [ CrossRef ]
- Cactus Cancer Society. About Us. 2022. Available online: https://cactuscancer.org/about/ (accessed on 11 May 2022).
- Palinkas, L.A.; Horwitz, S.M.; Green, C.A.; Wisdom, J.P.; Duan, N.; Hoagwood, K. Purposeful sampling for qualitative data collection and analysis in mixed method implementation research. Adm. Policy Ment. Health Ment. Health Serv. Res. 2015 , 42 , 533–544. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Institute, N.C. Adolescents and Young Adults with Cancer. 2024. Available online: https://www.cancer.gov/types/aya (accessed on 23 August 2024).
- Black & White Cancer Survivors Foundation. BWCSF. 2014. Available online: https://www.blackandwhitecancersurvivorsfoundation.com/ (accessed on 11 May 2022).
- Teen Cancer America. Teen Cancer America. Available online: https://teencanceramerica.org/ (accessed on 11 May 2022).
- Young Adult Survivors United. Young Adult Survivors United. 2022. Available online: https://www.yasurvivors.org/ (accessed on 11 May 2022).
- Testicular Cancer Foundation. TCF. 2022. Available online: https://www.testicularcancer.org/ (accessed on 11 May 2022).
- Sisters Network Inc. A National African American Breast Cancer Survivorship Organization. 2022. Available online: https://www.sistersnetworkinc.org/ (accessed on 11 May 2022).
- Imerman Angels. Imerman Angels Your One-on-One Cancer Support Community. 2020. Available online: https://imermanangels.org/ (accessed on 11 May 2022).
- Creswell, J.W.; Klassen, A.C.; Clark, V.L.P.; Smith, K.C.; The Office of Behavioral and Social Sciences Research. Best Practices for Mixed Methods Research in Health Sciences , 2nd ed.; National Institutes of Health: Bethesda, MD, USA, 2011.
- Creswell, J.W.; Poth, C.N. Qualitative Inquiry & Research Design: Choosing among Five Approaches ; SAGE: Thousand Oaks, CA, USA, 2018. [ Google Scholar ]
- Ryan, G.W.; Stern, S.A.; Hilton, L.; Tucker, J.S.; Kennedy, D.P.; Golinelli, D.; Wenzel, S.L. When, where, why and with whom homeless women engage in risky sexual behaviors: A framework for understanding complex and varied decision-making processes. Sex Roles 2009 , 61 , 536–553. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bronfenbrenner, U. Toward an Experimental Ecology of Human Development. Am. Psychol. 1977 , 32 , 513–531. [ Google Scholar ] [ CrossRef ]
- Spradley, J.P. Asking Descriptive Questions, in The Ethnographic Interview ; Wadsworth Group: St Albans Ln, NC, USA, 1979. [ Google Scholar ]
- Leech, B.L. Asking Questions: Techniques for Semistructured Interviews. PS Polit. Sci. Polit. 2002 , 35 , 665–668. [ Google Scholar ] [ CrossRef ]
- Saunders, B.; Sim, J.; Kingstone, T.; Baker, S.; Waterfield, J.; Bartlam, B.; Burroughs, H.; Jinks, C. Saturation in qualitative research: Exploring its conceptualization and operationalization. Qual. Quant. 2018 , 52 , 1893–1907. [ Google Scholar ] [ CrossRef ]
- Guba, E.G. ERIC/ECTJ Annual Review Paper: Criteria for Assessing the Trustworthiness of Naturalistic Inquiries. Educ. Commun. Technol. 1981 , 29 , 75–91. [ Google Scholar ] [ CrossRef ]
- Krefting, L. Rigor in qualitative research: The assessment of trustworthiness. Am. J. Occup. Ther. 1991 , 45 , 214–222. [ Google Scholar ] [ CrossRef ]
- Crozier, G.; Denzin, N.; Lincoln, Y. Handbook of Qualitative Research , 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2000. [ Google Scholar ]
- Hamilton, A.B.; Finley, E.P. Qualitative methods in implementation research: An introduction. Psychiatry Res. 2019 , 280 , 112516. [ Google Scholar ] [ CrossRef ]
- Maietta, R.; Mihas, P.; Swartout, K.; Petruzzelli, J.; Hamilton, A. Sort and Sift, Think and Shift: Let the Data Be Your Guide an Applied Approach to Working With, Learning From, and Privileging Qualitative Data. Qual. Rep. 2021 , 26 , 2045–2060. [ Google Scholar ] [ CrossRef ]
- Friese, S. Qualitative Data Analysis with ATLAS.ti , 2nd ed.; SAGE Publications: London, UK, 2014. [ Google Scholar ]
- Saldaña, J. The Coding Manual for Qualitative Researchers , 2nd ed.; SAGE Publications: Thousand Oaks, CA, USA, 2013. [ Google Scholar ]
- Cheung, C.K.; Zebrack, B. What do adolescents and young adults want from cancer resources? Insights from a Delphi panel of AYA patients. Support. Care Cancer 2017 , 25 , 119–126. [ Google Scholar ] [ CrossRef ]
- Avutu, V.; Lynch, K.A.; Barnett, M.E.; Vera, J.A.; Glade Bender, J.L.; Tap, W.D.; Atkinson, T.M. Psychosocial Needs and Pref-erences for Care among Adolescent and Young Adult Cancer Patients (Ages 15–39): A Qualitative Study. Cancers 2022 , 14 , 710. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Osborn, M.; Johnson, R.; Thompson, K.; Anazodo, A.; Albritton, K.; Ferrari, A.; Stark, D. Models of care for adolescent and young adult cancer programs. Pediatr. Blood Cancer 2019 , 66 , e27991. [ Google Scholar ] [ CrossRef ]
- Bibby, H.; White, V.; Thompson, K.; Anazodo, A. What Are the Unmet Needs and Care Experiences of Adolescents and Young Adults with Cancer? A Systematic Review. J. Adolesc. Young-Adult Oncol. 2017 , 6 , 6–30. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Magni, C.; Veneroni, L.; Silva, M.; Casanova, M.; Chiaravalli, S.; Massimino, M.; Clerici, C.A.; Ferrari, A. Model of Care for Ado-lescents and Young Adults with Cancer: The Youth Project in Milan. Front. Pediatr. 2016 , 4 , 88. [ Google Scholar ] [ CrossRef ]
- Gorin, S.S.; Haggstrom, D.; Han, P.K.J.; Fairfield, K.M.; Krebs, P.; Clauser, S.B. Cancer Care Coordination: A Systematic Review and Meta-Analysis of Over 30 Years of Empirical Studies. Ann. Behav. Med. 2017 , 51 , 532–546. [ Google Scholar ] [ CrossRef ]
- Smith, S.; Mooney, S.; Cable, M.; Taylor, R.M. The Blueprint of Care for Teenagers and Young Adults with Cancer , 2nd ed.; Teenage Cancer Trust: London, UK, 2016. [ Google Scholar ]
- Gupta, A.A.; Papadakos, J.K.; Jones, J.M.; Amin, L.; Chang, E.K.; Korenblum, C.; Mina, D.S.; McCabe, L.; Mitchell, L.; Giuliani, M.E. Reimagining care for adolescent and young adult cancer programs: Moving with the times. Cancer 2016 , 122 , 1038–1046. [ Google Scholar ] [ CrossRef ]
- Shapiro, J. “Violence” in medicine: Necessary and unnecessary, intentional and unintentional. Philos. Ethics Hum. Ities Med. 2018 , 13 , 7. [ Google Scholar ] [ CrossRef ]
- Salmond, S.; Dorsen, C. Time to Reflect and Take Action on Health Disparities and Health Inequities. Orthop. Nurs. 2022 , 41 , 64–85. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Casanova-Perez, R.; Apodaca, C.; Bascom, E.; Mohanraj, D.; Lane, C.; Vidyarthi, D.; Beneteau, E.; Sabin, J.; Pratt, W.; Weibel, N.; et al. Broken down by bias: Healthcare biases experienced by BIPOC and LGBTQ+ patients. AMIA Annu. Symp. Proc. 2021 , 2021 , 275–284. [ Google Scholar ]
- Gannon, T.; Phillips, B.; Saunders, D.; Berner, A.M. Knowing to Ask and Feeling Safe to Tell-Understanding the Influences of HCP-Patient Interactions in Cancer Care for LGBTQ+ Children and Young People. Front. Oncol. 2022 , 12 , 891874. [ Google Scholar ] [ CrossRef ]
- Desai, M.J.; Gold, R.S.; Jones, C.K.; Din, H.; Dietz, A.C.; Shliakhtsitsava, K.; Martinez, M.E.; Vaida, F.; Su, H.-C.I. Mental Health Outcomes in Adolescent and Young Adult Female Cancer Survivors of a Sexual Minority. J. Adolesc. Young-Adult Oncol. 2021 , 10 , 148–155. [ Google Scholar ] [ CrossRef ]
- Eisape, A.; Nogueira, A. See Change: Overcoming Anti-Black Racism in Health Systems. Front. Public Health 2022 , 10 , 895684. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Alegría, M.; Green, J.G.; McLaughlin, K.A.; Loder, S. Disparities in Child and Adolescent Mental Health and Mental Health Services in the US ; William, T., Ed.; Grant Foundation: New York, NY, USA, 2015. [ Google Scholar ]
- Wang, P.S.; Lane, M.; Olfson, M.; Pincus, H.A.; Wells, K.B.; Kessler, R.C. Twelve-Month Use of Mental Health Services in the United States: Results from the National Comorbidity Survey Replication. Arch. Gen. Psychiatry 2005 , 62 , 629–640. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Schellinger, S.E.; Anderson, E.W.; Frazer, M.S.; Cain, C.L. Patient Self-Defined Goals: Essentials of Person-Centered Care for Serious Illness. Am. J. Hosp. Palliat. Med. 2018 , 35 , 159–165. [ Google Scholar ] [ CrossRef ]
- Zebrack, B. Information and service needs for young adult cancer patients. Support. Care Cancer 2008 , 16 , 1353–1360. [ Google Scholar ] [ CrossRef ]
- LaRosa, K.N.; Stern, M.; Bleck, J.; Lynn, C.; Hudson, J.; Reed, D.R.; Quinn, G.P.; Donovan, K.A. Adolescent and Young Adult Patients with Cancer: Perceptions of Care. J. Adolesc. Young-Adult Oncol. 2017 , 6 , 512–518. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Yabroff, K.R.; Gansler, T.; Wender, R.C.; Cullen, K.J.; Brawley, O.W.; Gansler, T. Minimizing the burden of cancer in the United States: Goals for a high-performing health care system. CA A Cancer J. Clin. 2019 , 69 , 166–183. [ Google Scholar ] [ CrossRef ]
- Reed, D.; Block, R.G.; Johnson, R. Creating an Adolescent and Young Adult Cancer Program: Lessons Learned from Pediatric and Adult Oncology Practice Bases. J. Natl. Compr. Cancer Netw. 2014 , 12 , 1409–1415. [ Google Scholar ] [ CrossRef ]
- Ferrari, A.; Thomas, D.; Franklin, A.R.K.; Hayes-Lattin, B.M.; Mascarin, M.; van der Graaf, W.; Albritton, K.H. Starting an Ad-olescent and Young Adult Program: Some Success Stories and Some Obstacles to Overcome. J. Clin. Oncol. 2010 , 28 , 4850–4857. [ Google Scholar ] [ CrossRef ]
- Zebrack, B.J.; Corbett, V.; Embry, L.; Aguilar, C.; Meeske, K.A.; Hayes-Lattin, B.; Block, R.; Zeman, D.T.; Cole, S. Psychological distress and unsatisfied need for psychosocial support in adolescent and young adult cancer patients during the first year fol-lowing diagnosis. Psychooncology 2014 , 23 , 1267–1275. [ Google Scholar ] [ CrossRef ]
- Tai, E.; Buchanan, N.; Townsend, J.; Fairley, T.; Moore, A.; Richardson, L.C. Health status of adolescent and young adult cancer survivors. Cancer 2012 , 118 , 4884–4891. [ Google Scholar ] [ CrossRef ]
- Kent, E.E.; Parry, C.; Montoya, M.J.; Sender, L.S.; Morris, R.A.; Anton-Culver, H. “You’re too young for this”: Adolescent and young adults’ perspectives on cancer survivorship. J. Psychosoc. Oncol. 2012 , 30 , 260–279. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Miedema, B.; Hamilton, R.; Easley, J. From “invincibility” to “normalcy”: Coping strategies of young adults during the cancer journey. Palliat. Support Care 2007 , 5 , 41–49. [ Google Scholar ] [ CrossRef ]
- Zebrack, B.; Kent, E.E.; Keegan, T.H.; Kato, I.; Smith, A.W.; AYA Hope Study Collaborative Group. “Cancer sucks,” and other ponderings by adolescent and young adult cancer survivors. J. Psychosoc. Oncol. 2014 , 32 , 1–15. [ Google Scholar ] [ CrossRef ]
- Pannier, S.T.; Warner, E.L.; Fowler, B.; Fair, D.; Salmon, S.K.; Kirchhoff, A.C. Age-Specific Patient Navigation Preferences Among Adolescents and Young Adults with Cancer. J. Cancer Educ. 2019 , 34 , 242–251. [ Google Scholar ] [ CrossRef ]
- Zebrack, B.J. Psychological, social, and behavioral issues for young adults with cancer. Cancer 2011 , 117 (Suppl. S10), 2289–2294. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Zebrack, B.J.; Block, R.; Hayes-Lattin, B.; Embry, L.; Aguilar, C.; Meeske, K.A.; Li, Y.; Butler, M.; Cole, S. Psychosocial service use and unmet need among recently diagnosed adolescent and young adult cancer patients. Cancer 2013 , 119 , 201–214. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- D’agostino, N.M.; Edelstein, K. Psychosocial challenges and resource needs of young adult cancer survivors: Implications for program development. J. Psychosoc. Oncol. 2013 , 31 , 585–600. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bender, J.L.; Puri, N.; Salih, S.; D’agostino, N.M.; Tsimicalis, A.; Howard, A.F.; Garland, S.N.; Chalifour, K.; Drake, E.K.; Marrato, A.; et al. Peer Support Needs and Preferences for Digital Peer Navigation among Adolescent and Young Adults with Cancer: A Canadian Cross-Sectional Survey. Curr. Oncol. 2022 , 29 , 1163–1175. [ Google Scholar ] [ CrossRef ]
- Zebrack, B.; Bleyer, A.; Albritton, K.; Medearis, S.; Tang, J. Assessing the health care needs of adolescent and young adult cancer patients and survivors. Cancer 2006 , 107 , 2915–2923. [ Google Scholar ] [ CrossRef ]
- Choi, E.; Becker, H.; Kim, S. Unmet needs in adolescents and young adults with cancer: A mixed-method study using social media. J. Pediatr. Nurs. 2022 , 64 , 31–41. [ Google Scholar ] [ CrossRef ]
- Benedict, C.; Thom, B.; Friedman, D.N.; Pottenger, E.; Raghunathan, N.; Kelvin, J.F. Fertility information needs and concerns post-treatment contribute to lowered quality of life among young adult female cancer survivors. Support. Care Cancer 2018 , 26 , 2209–2215. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Benedict, C.; Shuk, E.; Ford, J.S. Fertility issues in adolescent and young adult cancer survivors. J. Adolesc. Young-Adult Oncol. 2016 , 5 , 48–57. [ Google Scholar ] [ CrossRef ]
- Guy, G.P.; Yabroff, K.R.; Ekwueme, D.U.; Smith, A.W.; Dowling, E.C.; Rechis, R.; Nutt, S.; Richardson, L.C. Estimating the health and economic burden of cancer among those diagnosed as adolescents and young adults. Health Aff. 2014 , 33 , 1024–1031. [ Google Scholar ] [ CrossRef ]
- Lu, A.D.; Zheng, Z.; Han, X.; Qi, R.; Zhao, J.; Yabroff, K.R.; Nathan, P.C. Medical Financial Hardship in Survivors of Adolescent and Young Adult Cancer in the United States. JNCI J. Natl. Cancer Inst. 2021 , 113 , 997–1004. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Centers for Medicare & Medicaid Services. Young Adults and the Affordable Care Act: Protecting Young Adults and Eliminating Burdens on Families and Businesses. Programs and Initiatives. 2022. Available online: https://www.cms.gov/CCIIO/Resources/Files/adult_child_fact_sheet (accessed on 11 May 2022).
- Ayanian, J.Z.; Weissman, J.S.; Schneider, E.C.; Ginsburg, J.A.; Zaslavsky, A.M. Unmet Health Needs of Uninsured Adults in the United States. JAMA 2000 , 284 , 2061–2069. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Landwehr, M.S.; Watson, S.E.; Macpherson, C.F.; Novak, K.A.; Johnson, R.H. The cost of cancer: A retrospective analysis of the financial impact of cancer on young adults. Cancer Med. 2016 , 5 , 863–870. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Han, X.; Jemal, A.D. The Affordable Care Act and Cancer Care for Young Adults. Cancer J. 2017 , 23 , 194–198. [ Google Scholar ] [ CrossRef ]
- Quinn, G.P.; Goncalves, V.; Sehovic, I.; Bowman, M.L.; Reed, D.R. Quality of life in adolescent and young adult cancer patients: A systematic review of the literature. Patient Relat. Outcome Meas. 2015 , 6 , 19–51. [ Google Scholar ] [ CrossRef ]
- Magasi, S.; Marshall, H.K.; Winters, C.; Victorson, D. Cancer Survivors’ Disability Experiences and Identities: A Qualitative Exploration to Advance Cancer Equity. Int. J. Environ. Res. Public Health 2022 , 19 , 3112. [ Google Scholar ] [ CrossRef ]
- Janssen, S.H.M.; van der Graaf, W.T.A.; van der Meer, D.J.; Manten-Horst, E.; Husson, O. Adolescent and Young Adult (AYA) Cancer Survivorship Practices: An Overview. Cancers 2021 , 13 , 4847. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- White, V.; Skaczkowski, G.; Thompson, K.; Bibby, H.; Coory, M.; Pinkerton, R.; Nicholls, W.; Orme, L.M.; Conyers, R.; Phillips, M.B.; et al. Experiences of Care of Adolescents and Young Adults with Cancer in Australia. J. Adolesc. Young-Adult Oncol. 2018 , 7 , 315–325. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wilkinson, J. Young people with cancer—How should their care be organized? Eur. J. Cancer Care 2003 , 12 , 65–70. [ Google Scholar ] [ CrossRef ]
- Albritton, K.H.; Wiggins, C.H.; Nelson, H.E.; Weeks, J.C. Site of Oncologic Specialty Care for Older Adolescents in Utah. J. Clin. Oncol. 2007 , 25 , 4616–4621. [ Google Scholar ] [ CrossRef ]
- Marshall, S.; Grinyer, A.; Limmer, M. The Experience of Adolescents and Young Adults Treated for Cancer in an Adult Setting: A Review of the Literature. J. Adolesc. Young-Adult Oncol. 2018 , 7 , 283–291. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Flanagin, A.; Frey, T.; Christiansen, S.L.; AMA Manual of Style Committee. Updated Guidance on the Reporting of Race and Ethnicity in Medical and Science Journals. JAMA 2021 , 326 , 621–627. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Linas, B.P.; Assoumou, S.A. Laying the Foundation for a New and Inclusive Science. JAMA Netw. Open 2022 , 5 , e2148540. [ Google Scholar ] [ CrossRef ]
- Stewart, J.; Krows, M.L.; Schaafsma, T.T.; Heller, K.B.; Brown, E.R.; Boonyaratanakornkit, J.; Brown, C.E.; Leingang, H.; Liou, C.; Bershteyn, A.; et al. Comparison of Racial, Ethnic, and Geographic Location Diversity of Participants Enrolled in Clinic-Based vs 2 Remote COVID-19 Clinical Trials. JAMA Netw. Open 2022 , 5 , e2148325. [ Google Scholar ] [ CrossRef ]
Click here to enlarge figure
| Number (%) | |
|---|---|
| Female | 21 (84) |
| Male | 4 (16) |
| White | 19 (76) |
| Black | 2 (8) |
| Middle Eastern/North African | 1 (4) |
| Other | 3 (12) |
| Hispanic/Latinx | 6 (24) |
| Not Hispanic/Latine/x | 19 (76) |
| 20–29 | 8 (32) |
| 30–39 | 12 (48) |
| 40–49 | 5 (20) |
| 15–19 | 4 (16) |
| 20–29 | 10 (40) |
| 30–39 | 11 (44) |
| Less than 2 years | 3 (12) |
| At least 2, but less than 5 years | 8 (32) |
| At least 5, but less than 10 years | 11 (44) |
| 10 or more years | 3 (12) |
| Less than 2 years | 5 (20) |
| More than 2, but less than 5 years | 12 (48) |
| More than 5, but less than 10 years | 5 (20) |
| 10 or more years | 3 (12) |
| Breast | 5 (20) |
| Chromophobe Renal Cell Carcinoma | 1 (4) |
| Hodgkin’s Lymphoma | 4 (16) |
| Leukemia | 7 (28) |
| Lung | 1 (4) |
| Myelodysplastic Syndromes (MDS) | 1 (4) |
| Osteosarcoma | 1 (4) |
| Ovarian | 1 (4) |
| Sarcoma | 1 (4) |
| Testicular | 3 (12) |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Figueroa Gray, M.S.; Shapiro, L.; Dorsey, C.N.; Randall, S.; Casperson, M.; Chawla, N.; Zebrack, B.; Fujii, M.M.; Hahn, E.E.; Keegan, T.H.M.; et al. A Patient-Centered Conceptual Model of AYA Cancer Survivorship Care Informed by a Qualitative Interview Study. Cancers 2024 , 16 , 3073. https://doi.org/10.3390/cancers16173073
Figueroa Gray MS, Shapiro L, Dorsey CN, Randall S, Casperson M, Chawla N, Zebrack B, Fujii MM, Hahn EE, Keegan THM, et al. A Patient-Centered Conceptual Model of AYA Cancer Survivorship Care Informed by a Qualitative Interview Study. Cancers . 2024; 16(17):3073. https://doi.org/10.3390/cancers16173073
Figueroa Gray, Marlaine S., Lily Shapiro, Caitlin N. Dorsey, Sarah Randall, Mallory Casperson, Neetu Chawla, Brad Zebrack, Monica M. Fujii, Erin E. Hahn, Theresa H. M. Keegan, and et al. 2024. "A Patient-Centered Conceptual Model of AYA Cancer Survivorship Care Informed by a Qualitative Interview Study" Cancers 16, no. 17: 3073. https://doi.org/10.3390/cancers16173073
Article Metrics
Article access statistics, supplementary material.
ZIP-Document (ZIP, 126 KiB)
Further Information
Mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
COMMENTS
Step 1 - Initial coding. The first step of the coding process is to identify the essence of the text and code it accordingly. While there are various qualitative analysis software packages available, you can just as easily code textual data using Microsoft Word's "comments" feature.
Coding is the process of labeling and organizing your qualitative data to identify different themes and the relationships between them. When coding customer feedback, you assign labels to words or phrases that represent important (and recurring) themes in each response. These labels can be words, phrases, or numbers; we recommend using words or ...
Deductive and Inductive Coding You create codes because you deem the identified topics/concepts/ideas as important and relevant to your study. Deductive Coding Codes emerge from your research question and/or the literature review. Inductive Coding Codes emerge through engagement with your actual data sources and/or data set.
Qualitative Data Analysis: Coding
Essential Guide to Coding Qualitative Data - Delve
A Guide to Coding Qualitative Research Data
Specifically, in this article, I outline a five-phase process of qualitative analysis that draws on deductive (codes developed a priori) and inductive (codes developed in the course of the analysis) coding strategies, as well as guided memoing, to help manage data and to support trustworthy, replicable, and actionable qualitative studies of ...
Coding Qualititive Data | Overview, Methods, Software
Simply put, coding is qualitative analysis. Coding is the analytical phase where researchers become immersed in their data, take the time to fully get to know it (Basit, 2003; Elliott, 2018), and allow its sense to be discerned.A code is "…a word or short phrase that symbolically assigns a summative, salient, essence-capturing, and/or evocative attribute for a portion of language-based or ...
Abstract. This chapter provides an overview of selected qualitative data analytic strategies with a particular focus on codes and coding. Preparatory strategies for a qualitative research study and data management are first outlined. Six coding methods are then profiled using comparable interview data: process coding, in vivo coding ...
How to collect qualitative data. Coding qualitative data effectively starts with having the right data to begin with. Here are a few common sources you can turn to to gather qualitative data for your research project: Interviews: Conducting structured, semi-structured, or unstructured interviews with individuals or groups is a great way to ...
Here are some resources for demonstrations on other methods for coding qualitative data: Qualitative Data Analysis [PDF] When writing up the analysis, it is best to "identify" participants through a number, alphabetical letter, or pseudonym in the write-up (e.g. Participant #3 stated …).
Having pooled our ex perience in coding qualitative material and teaching students how to. code, in this paper we synthesize the extensive literature on coding in the form of a hands-on. review ...
Chapter 18. Data Analysis and Coding - Oregon State University
Transparency is once again a central issue of debate across types of qualitative research. Ethnographers focus on whether to name people, places, or to share data (Contreras 2019; Guenther 2009; Jerolmack and Murphy 2017; Reyes 2018b) and whether our data actually match the claims we make (e.g., Jerolmack and Khan 2014).Work on how to conduct qualitative data analysis, on the other hand, walks ...
Welcome to the companion website for The Coding Manual for Qualitative Research, third edition, by Johnny Saldaña. This website offers a wealth of additional resources to support students and lecturers including: CAQDAS links giving guidance and links to a variety of qualitative data analysis software.. Code lists including data extracted from the author's study, "Lifelong Learning Impact ...
Qualitative Coding 101. Before we jump into examples of various qualitative coding techniques, it's useful to quickly define what exactly we mean by "qualitative coding". Simply put, qualitative coding is the process of systematically assigning labels (codes) to segments of qualitative data (usually text). These codes capture key concepts ...
(PDF) Qualitative Data Coding
Codes should be defined, just as variables in a quantitative study should be. The level of specificity will depend on various factors (e.g.,complexity of your coding scheme, whether you have a team of coders, requirements of your field) There a few commonthings to consider including: Inclusionsand Exclusions. Weighing Scale.
May 17, 2024. Reviewed by. Olivia Guy-Evans, MSc. Coding is the process of analyzing qualitative data (usually text) by assigning labels (codes) to chunks of data that capture their essence or meaning. It allows you to condense, organize and interpret your data. A code is a word or brief phrase that captures the essence of why you think a ...
Coding, then, is the process of applying codes to texts or visuals. It is one of the most common strategies for data reduction and analysis of qualitative data, though many qualitative projects do not require or use coding. This chapter will provide an overview of approaches based in coding, including how to develop codes and how to go through ...
Qualitative data coding is the process of assigning quantitative tags to the pieces of data. This is necessary for any type of large-scale analysis because you 1) need to have a consistent way to compare and contrast each piece of qualitative data, and 2) will be able to use tools like Excel and Google Sheets to manipulate quantitative data.
This technology allows us to work with a greater volume of data than ever before, but the increased volume of data frequently requires a large team to process and code. This paper presents insights on how to successfully structure and manage a team of staff in coding qualitative data. We draw on our experience in team-based coding of 154 ...
Purpose: Standards for reporting exist for many types of quantitative research, but currently none exist for the broad spectrum of qualitative research. The purpose of the present study was to formulate and define standards for reporting qualitative research while preserving the requisite flexibility to accommodate various paradigms, approaches, and methods.
The Standards for Reporting Qualitative Research reporting17 guidelines were used where applicable (online supplemental file 2). The study was designed and conducted by a research team that included both academic and service partners. ... Data coding was carried out independently initially, and following development of a coding frame, all ...
Purpose: Conceptual models provide frameworks to illustrate relationships among patient-, provider-, system-, and community-level factors that inform care delivery and research. Existing models of cancer survivorship care focus largely on pediatric or adult populations whose needs differ from adolescents and young adults (AYAs). We developed a patient-centered conceptual model of AYA ...