Data Representation in Computer: Number Systems, Characters, Audio, Image and Video
What is data representation in computer.
A computer uses a fixed number of bits to represent a piece of data which could be a number, a character, image, sound, video, etc. Data representation is the method used internally to represent data in a computer. Let us see how various types of data can be represented in computer memory.
Before discussing data representation of numbers, let us see what a number system is.

Number Systems
Number systems are the technique to represent numbers in the computer system architecture, every value that you are saving or getting into/from computer memory has a defined number system.
The number 289 is pronounced as two hundred and eighty-nine and it consists of the symbols 2, 8, and 9. Similarly, there are other number systems. Each has its own symbols and method for constructing a number.
Let us discuss some of the number systems. Computer architecture supports the following number of systems:
Binary Number System
A Binary number system has only two digits that are 0 and 1. Every number (value) represents 0 and 1 in this number system. The base of the binary number system is 2 because it has only two digits.
Octal Number System
Decimal number system.
The decimal number system has only ten (10) digits from 0 to 9. Every number (value) represents with 0,1,2,3,4,5,6, 7,8 and 9 in this number system. The base of decimal number system is 10, because it has only 10 digits.
Hexadecimal Number System
Data representation of characters.
There are different methods to represent characters . Some of them are discussed below:
The code called ASCII (pronounced ‘’.S-key”), which stands for American Standard Code for Information Interchange, uses 7 bits to represent each character in computer memory. The ASCII representation has been adopted as a standard by the U.S. government and is widely accepted.
Since there are exactly 128 unique combinations of 7 bits, this 7-bit code can represent only128 characters. Another version is ASCII-8, also called extended ASCII, which uses 8 bits for each character, can represent 256 different characters.
If ASCII-coded data is to be used in a computer that uses EBCDIC representation, it is necessary to transform ASCII code to EBCDIC code. Similarly, if EBCDIC coded data is to be used in an ASCII computer, EBCDIC code has to be transformed to ASCII.
Using 8-bit ASCII we can represent only 256 characters. This cannot represent all characters of written languages of the world and other symbols. Unicode is developed to resolve this problem. It aims to provide a standard character encoding scheme, which is universal and efficient.
Data Representation of Audio, Image and Video
In most cases, we may have to represent and process data other than numbers and characters. This may include audio data, images, and videos. We can see that like numbers and characters, the audio, image, and video data also carry information.
For example, an image is most popularly stored in Joint Picture Experts Group (JPEG ) file format. An image file consists of two parts – header information and image data. Information such as the name of the file, size, modified data, file format, etc. is stored in the header part.
Numerous such techniques are used to achieve compression. Depending on the application, images are stored in various file formats such as bitmap file format (BMP), Tagged Image File Format (TIFF), Graphics Interchange Format (GIF), Portable (Public) Network Graphic (PNG).
Similarly, video is also stored in different files such as AVI (Audio Video Interleave) – a file format designed to store both audio and video data in a standard package that allows synchronous audio with video playback, MP3, JPEG-2, WMV, etc.
FAQs About Data Representation in Computer
What is number system with example, you might also like, what is c++ programming language c++ character set, c++ tokens, what is artificial intelligence functions, 6 benefits, applications of ai, what is microprocessor evolution of microprocessor, types, features, 10 evolution of computing machine, history, what are decision making statements in c types, what are c++ keywords set of 59 keywords in c ++, what is cloud computing classification, characteristics, principles, types of cloud providers, generations of computer first to fifth, classification, characteristics, features, examples, types of computer software: systems software, application software, what are operators in c different types of operators in c, types of storage devices, advantages, examples, 10 types of computers | history of computers, advantages, what is operating system functions, types, types of user interface, advantages and disadvantages of operating system, advantages and disadvantages of flowcharts, what is flowchart in programming symbols, advantages, preparation, what is problem solving algorithm, steps, representation, what are data types in c++ types, data and information: definition, characteristics, types, channels, approaches, what are expressions in c types, leave a reply cancel reply.
- Computer Concepts Tutorial
- Computer Concepts - Home
- Introduction to Computer
- Introduction to GUI based OS
- Elements of Word Processing
- Spread Sheet
- Introduction to Internet, WWW, Browsers
- Communication & Collaboration
- Application of Presentations
- Application of Digital Financial Services
- Computer Concepts Resources
- Computer Concepts - Quick Guide
- Computer Concepts - Useful Resources
- Computer Concepts - Discussion
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
Representation of Data/Information
Computers do not understand human language; they understand data within the prescribed form. Data representation is a method to represent data and encode it in a computer system. Generally, a user inputs numbers, text, images, audio, and video etc types of data to process but the computer converts this data to machine language first and then processes it.
Some Common Data Representation Methods Include

Data representation plays a vital role in storing, process, and data communication. A correct and effective data representation method impacts data processing performance and system compatibility.
Computers represent data in the following forms
Number system.
A computer system considers numbers as data; it includes integers, decimals, and complex numbers. All the inputted numbers are represented in binary formats like 0 and 1. A number system is categorized into four types −
- Binary − A binary number system is a base of all the numbers considered for data representation in the digital system. A binary number system consists of only two values, either 0 or 1; so its base is 2. It can be represented to the external world as (10110010) 2 . A computer system uses binary digits (0s and 1s) to represent data internally.
- Octal − The octal number system represents values in 8 digits. It consists of digits 0,12,3,4,5,6, and 7; so its base is 8. It can be represented to the external world as (324017) 8 .
- Decimal − Decimal number system represents values in 10 digits. It consists of digits 0, 12, 3, 4, 5, 6, 7, 8, and 9; so its base is 10. It can be represented to the external world as (875629) 10 .
The below-mentioned table below summarises the data representation of the number system along with their Base and digits.
| Number System | ||
|---|---|---|
| System | Base | Digits |
| Binary | 2 | 0 1 |
| Octal | 8 | 0 1 2 3 4 5 6 7 |
| Decimal | 10 | 0 1 2 3 4 5 6 7 8 9 |
| Hexadecimal | 16 | 0 1 2 3 4 5 6 7 8 9 A B C D E F |
Bits and Bytes
A bit is the smallest data unit that a computer uses in computation; all the computation tasks done by the computer systems are based on bits. A bit represents a binary digit in terms of 0 or 1. The computer usually uses bits in groups. It's the basic unit of information storage and communication in digital computing.
A group of eight bits is called a byte. Half of a byte is called a nibble; it means a group of four bits is called a nibble. A byte is a fundamental addressable unit of computer memory and storage. It can represent a single character, such as a letter, number, or symbol using encoding methods such as ASCII and Unicode.
Bytes are used to determine file sizes, storage capacity, and available memory space. A kilobyte (KB) is equal to 1,024 bytes, a megabyte (MB) is equal to 1,024 KB, and a gigabyte (GB) is equal to 1,024 MB. File size is roughly measured in KBs and availability of memory space in MBs and GBs.

The following table shows the conversion of Bits and Bytes −
| Byte Value | Bit Value |
|---|---|
| 1 Byte | 8 Bits |
| 1024 Bytes | 1 Kilobyte |
| 1024 Kilobytes | 1 Megabyte |
| 1024 Megabytes | 1 Gigabyte |
| 1024 Gigabytes | 1 Terabyte |
| 1024 Terabytes | 1 Petabyte |
| 1024 Petabytes | 1 Exabyte |
| 1024 Exabytes | 1 Zettabyte |
| 1024 Zettabytes | 1 Yottabyte |
| 1024 Yottabytes | 1 Brontobyte |
| 1024 Brontobytes | 1 Geopbytes |
A Text Code is a static code that allows a user to insert text that others will view when they scan it. It includes alphabets, punctuation marks and other symbols. Some of the most commonly used text code systems are −
Extended ASCII
EBCDIC stands for Extended Binary Coded Decimal Interchange Code. IBM developed EBCDIC in the early 1960s and used it in their mainframe systems like System/360 and its successors. To meet commercial and data processing demands, it supports letters, numbers, punctuation marks, and special symbols. Character codes distinguish EBCDIC from other character encoding methods like ASCII. Data encoded in EBCDIC or ASCII may not be compatible with computers; to make them compatible, we need to convert with systems compatibility. EBCDIC encodes each character as an 8-bit binary code and defines 256 symbols. The below-mentioned table depicts different characters along with their EBCDIC code.

ASCII stands for American Standard Code for Information Interchange. It is an 8-bit code that specifies character values from 0 to 127. ASCII is a standard for the Character Encoding of Numbers that assigns numerical values to represent characters, such as letters, numbers, exclamation marks and control characters used in computers and communication equipment that are using data.
ASCII originally defined 128 characters, encoded with 7 bits, allowing for 2^7 (128) potential characters. The ASCII standard specifies characters for the English alphabet (uppercase and lowercase), numerals from 0 to 9, punctuation marks, and control characters for formatting and control tasks such as line feed, carriage return, and tab.
| ASCII Tabular column | ||
|---|---|---|
| ASCII Code | Decimal Value | Character |
| 0000 0000 | 0 | Null prompt |
| 0000 0001 | 1 | Start of heading |
| 0000 0010 | 2 | Start of text |
| 0000 0011 | 3 | End of text |
| 0000 0100 | 4 | End of transmit |
| 0000 0101 | 5 | Enquiry |
| 0000 0110 | 6 | Acknowledge |
| 0000 0111 | 7 | Audible bell |
| 0000 1000 | 8 | Backspace |
| 0000 1001 | 9 | Horizontal tab |
| 0000 1010 | 10 | Line Feed |
Extended American Standard Code for Information Interchange is an 8-bit code that specifies character values from 128 to 255. Extended ASCII encompasses different character encoding normal ASCII character set, consisting of 128 characters encoded in 7 bits, some additional characters that utilise full 8 bits of a byte; there are a total of 256 potential characters.
Different extended ASCII exist, each introducing more characters beyond the conventional ASCII set. These additional characters may encompass symbols, letters, and special characters to a specific language or location.
Extended ASCII Tabular column

It is a worldwide character standard that uses 4 to 32 bits to represent letters, numbers and symbols. Unicode is a standard character encoding which is specifically designed to provide a consistent way to represent text in nearly all of the world's writing systems. Every character is assigned a unique numeric code, program, or language. Unicode offers a wide variety of characters, including alphabets, ideographs, symbols, and emojis.
Unicode Tabular Column

Data representation
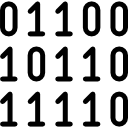
Computers use binary - the digits 0 and 1 - to store data. A binary digit, or bit, is the smallest unit of data in computing. It is represented by a 0 or a 1. Binary numbers are made up of binary digits (bits), eg the binary number 1001. The circuits in a computer's processor are made up of billions of transistors. A transistor is a tiny switch that is activated by the electronic signals it receives. The digits 1 and 0 used in binary reflect the on and off states of a transistor. Computer programs are sets of instructions. Each instruction is translated into machine code - simple binary codes that activate the CPU. Programmers write computer code and this is converted by a translator into binary instructions that the processor can execute. All software, music, documents, and any other information that is processed by a computer, is also stored using binary. [1]
To include strings, integers, characters and colours. This should include considering the space taken by data, for instance the relation between the hexadecimal representation of colours and the number of colours available.
This video is superb place to understand this topic
- 1 How a file is stored on a computer
- 2 How an image is stored in a computer
- 3 The way in which data is represented in the computer.
- 6 Standards
- 7 References
How a file is stored on a computer [ edit ]
How an image is stored in a computer [ edit ]
The way in which data is represented in the computer. [ edit ].
To include strings, integers, characters and colours. This should include considering the space taken by data, for instance the relation between the hexadecimal representation of colours and the number of colours available [3] .
This helpful material is used with gratitude from a computer science wiki under a Creative Commons Attribution 3.0 License [4]
Sound [ edit ]
- Let's look at an oscilloscope
- The BBC has an excellent article on how computers represent sound
See Also [ edit ]
Standards [ edit ].
- Outline the way in which data is represented in the computer.
References [ edit ]
- ↑ http://www.bbc.co.uk/education/guides/zwsbwmn/revision/1
- ↑ https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- ↑ IBO Computer Science Guide, First exams 2014
- ↑ https://compsci2014.wikispaces.com/2.1.10+Outline+the+way+in+which+data+is+represented+in+the+computer
A unit of abstract mathematical system subject to the laws of arithmetic.
A natural number, a negative of a natural number, or zero.
Give a brief account.
- Computer organization
- Very important ideas in computer science
Teach Computer Science
Data Representation
Topics include binary, decimal, and hexadecimal numbers, and the conversions between them.
Computational Thinking
We may think that computers “think” and that they outsmart humans “just like that”. However that’s not the case, computers do exactly what we humans tell them to do, or better said, what we program them to do. Once programmed a computer can only execute problems and produce solutions more efficiently than humans. Computational thinking …
For Data Units, candidates should be able to: define the terms bit, nibble, byte, kilobyte, megabyte, gigabyte, terabyte understand that data needs to be converted into a binary format to be processed by a computer. Data units in computer systems Bit This is a single unit of memory and can only store 2 possible binary …
Image Representation
For Image Representation, candidates should be able to: explain the representation of an image as a series of pixels represented in binary explain the need for metadata to be included in the file such as height, width and colour depth discuss the effect of colour depth and resolution on the size of an image file. …
Sound Representation
For Sound Representation, candidates should be able to: explain how sound can be sampled and stored in digital form explain how sampling intervals and other considerations affect the size of a sound file and the quality of its playback. How can sound be sampled and stored in digital form? A microphone converts sound waves into …
Number Systems
For Number Systems, candidates should be able to: convert positive denary whole numbers (0-255) into 8-bit binary numbers and vice versa add two 8-bit binary integers and explain overflow errors which may occur convert positive denary whole numbers (0-255) into 2-digit hexadecimal numbers and vice versa convert between binary and hexadecimal equivalents of the same …
Character Sets
Candidates should be able to: explain the use of binary codes to represent characters explain the term character set describe with examples (for example ASCII and Unicode) the relationship between the number of bits per character in a character set and the number of characters which can be represented. How are binary codes used to …
Computer Instructions
In regards to computer instructions, candidates should be able to: explain how instructions are coded as bit patterns explain how the computer distinguishes between instructions and data. Computer Instructions: How are program instructions coded? Machine code instructions are binary numbers and are coded as bit patterns, for example, a 16 bit machine code instruction could …
Converting Decimal to Binary
Converting Decimal to Binary: The Decimal Numbering System Decimal is a base 10 numbering Binary Numbering System Binary is a base 2 numbering system that is made up of two numbers: 0 and 1. 0 means OFF and 1 means ON. The computer’s central processing unit (CPU) only recognizes these two states – ON and …
Converting Hexadecimal to Decimal
Hexadecimal Numbering System Hexadecimal is a base 16 numbering system that is made up of 16 digits: 0 – 9 and six more, which is A through F. Uses of Hexadecimal The hexadecimal numbering system is often used by programmers to simplify the binary numbering system. Since 16 is equivalent to 24, there is a …
Converting Hexadecimal to Binary
Converting Hexadecimal to Binary Hexadecimal Numbering System Hexadecimal is a base 16 numbering system which is made up of 16 digits: 0 – 9 and six more, which is A through F. Uses of Hexadecimal Hexadecimal numbering system is often used by programmers to simplify the binary numbering system. Since 16 is equivalent to 24, …
Converting Decimal to Hexadecimal
Converting Decimal to Hexadecimal: The Decimal Numbering System Decimal is a base 10 numbering system that is made up of 10 numbers: 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9. It is the most commonly used numbering system. The reason behind that is convenience. We have 10 fingers that we use for …
Uses of Hexadecimal
Hexadecimal Numbering System Hexadecimal is a base 16 numbering system that is made up of 16 digits: 0 – 9 and six more, which is A through F.The table below shows how the hexadecimal system works and its equivalent decimal number: Hexadecimal Decimal Hexadecimal Decimal 0 0 11 = (1 x 16) + …
Converting Binary to Hexadecimal
Binary Numbering System Binary is a base 2 numbering system which is made up of two numbers: 0 and 1. 0 means OFF and 1 means ON. The computer’s central processing unit (CPU) only recognizes these two states – ON and OFF. It is the foundation for all binary code, which is used in computer …
Converting Binary to Decimal
Converting Binary to Decimal: The Binary Numbering System Binary is a base 2 numbering system that is made up of two numbers: 0 and 1. 0 means OFF and 1 means ON. The computer’s central processing unit (CPU) only recognizes these two states – ON and OFF. It is the foundation for all binary code, …
Bitmap Image and Colour Depth Quiz
Further Readings: Bitmap Color depth
Colour Depth Gap Fill Exercise
Further Readings: Color depth
Data Units Gap Fill Exercise
Further Readings: Units of information
Data Units Multi-Choice Quiz
Colour mapping and direct colour.
Pupil Resources – EXTENSION TOPIC What is the difference between Colour Mapping and Direct Colour? Colour mapping With low colour depths (up to 8-bit) it is practical to map every colour to a binary code. 1-bit colour mapping – (2 colours) monochrome, often black and white. 2-bit colour mapping – (4 colours) CGA – used …
Instructions
Candidates should be able to: explain how instructions are coded as bit patterns explain how the computer distinguishes between instructions and data. How are program instructions coded? Machine code instructions are binary numbers and are coded as bit patterns, for example, a 16-bit machine code instruction could be coded as 001010101101001011. In machine code, the …
Sound – Quality, Size & Storing Solutions
Candidates should be able to: How can sound be sampled and stored in digital form? A microphone converts sound waves into voltage changes. If a microphone is plugged into a sound card then the voltage can be sampled at regular intervals (the sample rate) and each value converted into a binary number. This digitising of …

- Data representation
Bytes of memory
- Abstract machine
Unsigned integer representation
Signed integer representation, pointer representation, array representation, compiler layout, array access performance, collection representation.
- Consequences of size and alignment rules
Uninitialized objects
Pointer arithmetic, undefined behavior.
- Computer arithmetic
Arena allocation
This course is about learning how computers work, from the perspective of systems software: what makes programs work fast or slow, and how properties of the machines we program impact the programs we write. We want to communicate ideas, tools, and an experimental approach.
The course divides into six units:
- Assembly & machine programming
- Storage & caching
- Kernel programming
- Process management
- Concurrency
The first unit, data representation , is all about how different forms of data can be represented in terms the computer can understand.
Computer memory is kind of like a Lite Brite.

A Lite Brite is big black backlit pegboard coupled with a supply of colored pegs, in a limited set of colors. You can plug in the pegs to make all kinds of designs. A computer’s memory is like a vast pegboard where each slot holds one of 256 different colors. The colors are numbered 0 through 255, so each slot holds one byte . (A byte is a number between 0 and 255, inclusive.)
A slot of computer memory is identified by its address . On a computer with M bytes of memory, and therefore M slots, you can think of the address as a number between 0 and M −1. My laptop has 16 gibibytes of memory, so M = 16×2 30 = 2 34 = 17,179,869,184 = 0x4'0000'0000 —a very large number!
The problem of data representation is the problem of representing all the concepts we might want to use in programming—integers, fractions, real numbers, sets, pictures, texts, buildings, animal species, relationships—using the limited medium of addresses and bytes.
Powers of ten and powers of two. Digital computers love the number two and all powers of two. The electronics of digital computers are based on the bit , the smallest unit of storage, which a base-two digit: either 0 or 1. More complicated objects are represented by collections of bits. This choice has many scale and error-correction advantages. It also refracts upwards to larger choices, and even into terminology. Memory chips, for example, have capacities based on large powers of two, such as 2 30 bytes. Since 2 10 = 1024 is pretty close to 1,000, 2 20 = 1,048,576 is pretty close to a million, and 2 30 = 1,073,741,824 is pretty close to a billion, it’s common to refer to 2 30 bytes of memory as “a giga byte,” even though that actually means 10 9 = 1,000,000,000 bytes. But for greater precision, there are terms that explicitly signal the use of powers of two. 2 30 is a gibibyte : the “-bi-” component means “binary.”
Virtual memory. Modern computers actually abstract their memory spaces using a technique called virtual memory . The lowest-level kind of address, called a physical address , really does take on values between 0 and M −1. However, even on a 16GiB machine like my laptop, the addresses we see in programs can take on values like 0x7ffe'ea2c'aa67 that are much larger than M −1 = 0x3'ffff'ffff . The addresses used in programs are called virtual addresses . They’re incredibly useful for protection: since different running programs have logically independent address spaces, it’s much less likely that a bug in one program will crash the whole machine. We’ll learn about virtual memory in much more depth in the kernel unit ; the distinction between virtual and physical addresses is not as critical for data representation.
Most programming languages prevent their users from directly accessing memory. But not C and C++! These languages let you access any byte of memory with a valid address. This is powerful; it is also very dangerous. But it lets us get a hands-on view of how computers really work.
C++ programs accomplish their work by constructing, examining, and modifying objects . An object is a region of data storage that contains a value, such as the integer 12. (The standard specifically says “a region of data storage in the execution environment, the contents of which can represent values”.) Memory is called “memory” because it remembers object values.
In this unit, we often use functions called hexdump to examine memory. These functions are defined in hexdump.cc . hexdump_object(x) prints out the bytes of memory that comprise an object named x , while hexdump(ptr, size) prints out the size bytes of memory starting at a pointer ptr .
For example, in datarep1/add.cc , we might use hexdump_object to examine the memory used to represent some integers:
This display reports that a , b , and c are each four bytes long; that a , b , and c are located at different, nonoverlapping addresses (the long hex number in the first column); and shows us how the numbers 1, 2, and 3 are represented in terms of bytes. (More on that later.)
The compiler, hardware, and standard together define how objects of different types map to bytes. Each object uses a contiguous range of addresses (and thus bytes), and objects never overlap (objects that are active simultaneously are always stored in distinct address ranges).
Since C and C++ are designed to help software interface with hardware devices, their standards are transparent about how objects are stored. A C++ program can ask how big an object is using the sizeof keyword. sizeof(T) returns the number of bytes in the representation of an object of type T , and sizeof(x) returns the size of object x . The result of sizeof is a value of type size_t , which is an unsigned integer type large enough to hold any representable size. On 64-bit architectures, such as x86-64 (our focus in this course), size_t can hold numbers between 0 and 2 64 –1.
Qualitatively different objects may have the same data representation. For example, the following three objects have the same data representation on x86-64, which you can verify using hexdump :
In C and C++, you can’t reliably tell the type of an object by looking at the contents of its memory. That’s why tricks like our different addf*.cc functions work.
An object can have many names. For example, here, local and *ptr refer to the same object:
The different names for an object are sometimes called aliases .
There are five objects here:
- ch1 , a global variable
- ch2 , a constant (non-modifiable) global variable
- ch3 , a local variable
- ch4 , a local variable
- the anonymous storage allocated by new char and accessed by *ch4
Each object has a lifetime , which is called storage duration by the standard. There are three different kinds of lifetime.
- static lifetime: The object lasts as long as the program runs. ( ch1 , ch2 )
- automatic lifetime: The compiler allocates and destroys the object automatically as the program runs, based on the object’s scope (the region of the program in which it is meaningful). ( ch3 , ch4 )
- dynamic lifetime: The programmer allocates and destroys the object explicitly. ( *allocated_ch )
Objects with dynamic lifetime aren’t easy to use correctly. Dynamic lifetime causes many serious problems in C programs, including memory leaks, use-after-free, double-free, and so forth. Those serious problems cause undefined behavior and play a “disastrously central role” in “our ongoing computer security nightmare” . But dynamic lifetime is critically important. Only with dynamic lifetime can you construct an object whose size isn’t known at compile time, or construct an object that outlives the function that created it.
The compiler and operating system work together to put objects at different addresses. A program’s address space (which is the range of addresses accessible to a program) divides into regions called segments . Objects with different lifetimes are placed into different segments. The most important segments are:
- Code (also known as text or read-only data ). Contains instructions and constant global objects. Unmodifiable; static lifetime.
- Data . Contains non-constant global objects. Modifiable; static lifetime.
- Heap . Modifiable; dynamic lifetime.
- Stack . Modifiable; automatic lifetime.
The compiler decides on a segment for each object based on its lifetime. The final compiler phase, which is called the linker , then groups all the program’s objects by segment (so, for instance, global variables from different compiler runs are grouped together into a single segment). Finally, when a program runs, the operating system loads the segments into memory. (The stack and heap segments grow on demand.)
We can use a program to investigate where objects with different lifetimes are stored. (See cs61-lectures/datarep2/mexplore0.cc .) This shows address ranges like this:
Object declaration | Lifetime | Segment | Example address range |
|---|---|---|---|
Constant global | Static | Code (or Text) | 0x40'0000 (≈1 × 2 ) |
Global | Static | Data | 0x60'0000 (≈1.5 × 2 ) |
Local | Automatic | Stack | 0x7fff'448d'0000 (≈2 = 2 × 2 ) |
Anonymous, returned by | Dynamic | Heap | 0x1a0'0000 (≈8 × 2 ) |
Constant global data and global data have the same lifetime, but are stored in different segments. The operating system uses different segments so it can prevent the program from modifying constants. It marks the code segment, which contains functions (instructions) and constant global data, as read-only, and any attempt to modify code-segment memory causes a crash (a “Segmentation violation”).
An executable is normally at least as big as the static-lifetime data (the code and data segments together). Since all that data must be in memory for the entire lifetime of the program, it’s written to disk and then loaded by the OS before the program starts running. There is an exception, however: the “bss” segment is used to hold modifiable static-lifetime data with initial value zero. Such data is common, since all static-lifetime data is initialized to zero unless otherwise specified in the program text. Rather than storing a bunch of zeros in the object files and executable, the compiler and linker simply track the location and size of all zero-initialized global data. The operating system sets this memory to zero during the program load process. Clearing memory is faster than loading data from disk, so this optimization saves both time (the program loads faster) and space (the executable is smaller).
Abstract machine and hardware
Programming involves turning an idea into hardware instructions. This transformation happens in multiple steps, some you control and some controlled by other programs.
First you have an idea , like “I want to make a flappy bird iPhone game.” The computer can’t (yet) understand that idea. So you transform the idea into a program , written in some programming language . This process is called programming.
A C++ program actually runs on an abstract machine . The behavior of this machine is defined by the C++ standard , a technical document. This document is supposed to be so precisely written as to have an exact mathematical meaning, defining exactly how every C++ program behaves. But the document can’t run programs!
C++ programs run on hardware (mostly), and the hardware determines what behavior we see. Mapping abstract machine behavior to instructions on real hardware is the task of the C++ compiler (and the standard library and operating system). A C++ compiler is correct if and only if it translates each correct program to instructions that simulate the expected behavior of the abstract machine.
This same rough series of transformations happens for any programming language, although some languages use interpreters rather than compilers.
A bit is the fundamental unit of digital information: it’s either 0 or 1.
C++ manages memory in units of bytes —8 contiguous bits that together can represent numbers between 0 and 255. C’s unit for a byte is char : the abstract machine says a byte is stored in char . That means an unsigned char holds values in the inclusive range [0, 255].
The C++ standard actually doesn’t require that a byte hold 8 bits, and on some crazy machines from decades ago , bytes could hold nine bits! (!?)
But larger numbers, such as 258, don’t fit in a single byte. To represent such numbers, we must use multiple bytes. The abstract machine doesn’t specify exactly how this is done—it’s the compiler and hardware’s job to implement a choice. But modern computers always use place–value notation , just like in decimal numbers. In decimal, the number 258 is written with three digits, the meanings of which are determined both by the digit and by their place in the overall number:
\[ 258 = 2\times10^2 + 5\times10^1 + 8\times10^0 \]
The computer uses base 256 instead of base 10. Two adjacent bytes can represent numbers between 0 and \(255\times256+255 = 65535 = 2^{16}-1\) , inclusive. A number larger than this would take three or more bytes.
\[ 258 = 1\times256^1 + 2\times256^0 \]
On x86-64, the ones place, the least significant byte, is on the left, at the lowest address in the contiguous two-byte range used to represent the integer. This is the opposite of how decimal numbers are written: decimal numbers put the most significant digit on the left. The representation choice of putting the least-significant byte in the lowest address is called little-endian representation. x86-64 uses little-endian representation.
Some computers actually store multi-byte integers the other way, with the most significant byte stored in the lowest address; that’s called big-endian representation. The Internet’s fundamental protocols, such as IP and TCP, also use big-endian order for multi-byte integers, so big-endian is also called “network” byte order.
The C++ standard defines five fundamental unsigned integer types, along with relationships among their sizes. Here they are, along with their actual sizes and ranges on x86-64:
Type | Size | Size | Range |
|---|---|---|---|
| 1 | 1 | [0, 255] = [0, 2 −1] |
| ≥1 | 2 | [0, 65,535] = [0, 2 −1] |
| ≥ | 4 | [0, 4,294,967,295] = [0, 2 −1] |
| ≥ | 8 | [0, 18,446,744,073,709,551,615] = [0, 2 −1] |
| ≥ | 8 | [0, 18,446,744,073,709,551,615] = [0, 2 −1] |
Other architectures and operating systems implement different ranges for these types. For instance, on IA32 machines like Intel’s Pentium (the 32-bit processors that predated x86-64), sizeof(long) was 4, not 8.
Note that all values of a smaller unsigned integer type can fit in any larger unsigned integer type. When a value of a larger unsigned integer type is placed in a smaller unsigned integer object, however, not every value fits; for instance, the unsigned short value 258 doesn’t fit in an unsigned char x . When this occurs, the C++ abstract machine requires that the smaller object’s value equals the least -significant bits of the larger value (so x will equal 2).
In addition to these types, whose sizes can vary, C++ has integer types whose sizes are fixed. uint8_t , uint16_t , uint32_t , and uint64_t define 8-bit, 16-bit, 32-bit, and 64-bit unsigned integers, respectively; on x86-64, these correspond to unsigned char , unsigned short , unsigned int , and unsigned long .
This general procedure is used to represent a multi-byte integer in memory.
- Write the large integer in hexadecimal format, including all leading zeros required by the type size. For example, the unsigned value 65534 would be written 0x0000FFFE . There will be twice as many hexadecimal digits as sizeof(TYPE) .
- Divide the integer into its component bytes, which are its digits in base 256. In our example, they are, from most to least significant, 0x00, 0x00, 0xFF, and 0xFE.
In little-endian representation, the bytes are stored in memory from least to most significant. If our example was stored at address 0x30, we would have:
In big-endian representation, the bytes are stored in the reverse order.
Computers are often fastest at dealing with fixed-length numbers, rather than variable-length numbers, and processor internals are organized around a fixed word size . A word is the natural unit of data used by a processor design . In most modern processors, this natural unit is 8 bytes or 64 bits , because this is the power-of-two number of bytes big enough to hold those processors’ memory addresses. Many older processors could access less memory and had correspondingly smaller word sizes, such as 4 bytes (32 bits).
The best representation for signed integers—and the choice made by x86-64, and by the C++20 abstract machine—is two’s complement . Two’s complement representation is based on this principle: Addition and subtraction of signed integers shall use the same instructions as addition and subtraction of unsigned integers.
To see what this means, let’s think about what -x should mean when x is an unsigned integer. Wait, negative unsigned?! This isn’t an oxymoron because C++ uses modular arithmetic for unsigned integers: the result of an arithmetic operation on unsigned values is always taken modulo 2 B , where B is the number of bits in the unsigned value type. Thus, on x86-64,
-x is simply the number that, when added to x , yields 0 (mod 2 B ). For example, when unsigned x = 0xFFFFFFFFU , then -x == 1U , since x + -x equals zero (mod 2 32 ).
To obtain -x , we flip all the bits in x (an operation written ~x ) and then add 1. To see why, consider the bit representations. What is x + (~x + 1) ? Well, (~x) i (the i th bit of ~x ) is 1 whenever x i is 0, and vice versa. That means that every bit of x + ~x is 1 (there are no carries), and x + ~x is the largest unsigned integer, with value 2 B -1. If we add 1 to this, we get 2 B . Which is 0 (mod 2 B )! The highest “carry” bit is dropped, leaving zero.
Two’s complement arithmetic uses half of the unsigned integer representations for negative numbers. A two’s-complement signed integer with B bits has the following values:
- If the most-significant bit is 1, the represented number is negative. Specifically, the represented number is – (~x + 1) , where the outer negative sign is mathematical negation (not computer arithmetic).
- If every bit is 0, the represented number is 0.
- If the most-significant but is 0 but some other bit is 1, the represented number is positive.
The most significant bit is also called the sign bit , because if it is 1, then the represented value depends on the signedness of the type (and that value is negative for signed types).
Another way to think about two’s-complement is that, for B -bit integers, the most-significant bit has place value 2 B –1 in unsigned arithmetic and negative 2 B –1 in signed arithmetic. All other bits have the same place values in both kinds of arithmetic.
The two’s-complement bit pattern for x + y is the same whether x and y are considered as signed or unsigned values. For example, in 4-bit arithmetic, 5 has representation 0b0101 , while the representation 0b1100 represents 12 if unsigned and –4 if signed ( ~0b1100 + 1 = 0b0011 + 1 == 4). Let’s add those bit patterns and see what we get:
Note that this is the right answer for both signed and unsigned arithmetic : 5 + 12 = 17 = 1 (mod 16), and 5 + -4 = 1.
Subtraction and multiplication also produce the same results for unsigned arithmetic and signed two’s-complement arithmetic. (For instance, 5 * 12 = 60 = 12 (mod 16), and 5 * -4 = -20 = -4 (mod 16).) This is not true of division. (Consider dividing the 4-bit representation 0b1110 by 2. In signed arithmetic, 0b1110 represents -2, so 0b1110/2 == 0b1111 (-1); but in unsigned arithmetic, 0b1110 is 14, so 0b1110/2 == 0b0111 (7).) And, of course, it is not true of comparison. In signed 4-bit arithmetic, 0b1110 < 0 , but in unsigned 4-bit arithmetic, 0b1110 > 0 . This means that a C compiler for a two’s-complement machine can use a single add instruction for either signed or unsigned numbers, but it must generate different instruction patterns for signed and unsigned division (or less-than, or greater-than).
There are a couple quirks with C signed arithmetic. First, in two’s complement, there are more negative numbers than positive numbers. A representation with sign bit is 1, but every other bit 0, has no positive counterpart at the same bit width: for this number, -x == x . (In 4-bit arithmetic, -0b1000 == ~0b1000 + 1 == 0b0111 + 1 == 0b1000 .) Second, and far worse, is that arithmetic overflow on signed integers is undefined behavior .
Type | Size | Size | Range |
|---|---|---|---|
| 1 | 1 | [−128, 127] = [−2 , 2 −1] |
| = | 2 | [−32,768, 32,767] = [−2 , 2 −1] |
| = | 4 | [−2,147,483,648, 2,147,483,647] = [−2 , 2 −1] |
| = | 8 | [−9,223,372,036,854,775,808, 9,223,372,036,854,775,807] = [−2 , 2 −1] |
| = | 8 | [−9,223,372,036,854,775,808, 9,223,372,036,854,775,807] = [−2 , 2 −1] |
The C++ abstract machine requires that signed integers have the same sizes as their unsigned counterparts.
We distinguish pointers , which are concepts in the C abstract machine, from addresses , which are hardware concepts. A pointer combines an address and a type.
The memory representation of a pointer is the same as the representation of its address value. The size of that integer is the machine’s word size; for example, on x86-64, a pointer occupies 8 bytes, and a pointer to an object located at address 0x400abc would be stored as:
The C++ abstract machine defines an unsigned integer type uintptr_t that can hold any address. (You have to #include <inttypes.h> or <cinttypes> to get the definition.) On most machines, including x86-64, uintptr_t is the same as unsigned long . Cast a pointer to an integer address value with syntax like (uintptr_t) ptr ; cast back to a pointer with syntax like (T*) addr . Casts between pointer types and uintptr_t are information preserving, so this assertion will never fail:
Since it is a 64-bit architecture, the size of an x86-64 address is 64 bits (8 bytes). That’s also the size of x86-64 pointers.
To represent an array of integers, C++ and C allocate the integers next to each other in memory, in sequential addresses, with no gaps or overlaps. Here, we put the integers 0, 1, and 258 next to each other, starting at address 1008:
Say that you have an array of N integers, and you access each of those integers in order, accessing each integer exactly once. Does the order matter?
Computer memory is random-access memory (RAM), which means that a program can access any bytes of memory in any order—it’s not, for example, required to read memory in ascending order by address. But if we run experiments, we can see that even in RAM, different access orders have very different performance characteristics.
Our arraysum program sums up all the integers in an array of N integers, using an access order based on its arguments, and prints the resulting delay. Here’s the result of a couple experiments on accessing 10,000,000 items in three orders, “up” order (sequential: elements 0, 1, 2, 3, …), “down” order (reverse sequential: N , N −1, N −2, …), and “random” order (as it sounds).
| order | trial 1 | trial 2 | trial 3 |
|---|---|---|---|
| , up | 8.9ms | 7.9ms | 7.4ms |
| , down | 9.2ms | 8.9ms | 10.6ms |
| , random | 316.8ms | 352.0ms | 360.8ms |
Wow! Down order is just a bit slower than up, but random order seems about 40 times slower. Why?
Random order is defeating many of the internal architectural optimizations that make memory access fast on modern machines. Sequential order, since it’s more predictable, is much easier to optimize.
Foreshadowing. This part of the lecture is a teaser for the Storage unit, where we cover access patterns and caching, including the processor caches that explain this phenomenon, in much more depth.
The C++ programming language offers several collection mechanisms for grouping subobjects together into new kinds of object. The collections are arrays, structs, and unions. (Classes are a kind of struct. All library types, such as vectors, lists, and hash tables, use combinations of these collection types.) The abstract machine defines how subobjects are laid out inside a collection. This is important, because it lets C/C++ programs exchange messages with hardware and even with programs written in other languages: messages can be exchanged only when both parties agree on layout.
Array layout in C++ is particularly simple: The objects in an array are laid out sequentially in memory, with no gaps or overlaps. Assume a declaration like T x[N] , where x is an array of N objects of type T , and say that the address of x is a . Then the address of element x[i] equals a + i * sizeof(T) , and sizeof(a) == N * sizeof(T) .
Sidebar: Vector representation
The C++ library type std::vector defines an array that can grow and shrink. For instance, this function creates a vector containing the numbers 0 up to N in sequence:
Here, v is an object with automatic lifetime. This means its size (in the sizeof sense) is fixed at compile time. Remember that the sizes of static- and automatic-lifetime objects must be known at compile time; only dynamic-lifetime objects can have varying size based on runtime parameters. So where and how are v ’s contents stored?
The C++ abstract machine requires that v ’s elements are stored in an array in memory. (The v.data() method returns a pointer to the first element of the array.) But it does not define std::vector ’s layout otherwise, and C++ library designers can choose different layouts based on their needs. We found these to hold for the std::vector in our library:
sizeof(v) == 24 for any vector of any type, and the address of v is a stack address (i.e., v is located in the stack segment).
The first 8 bytes of the vector hold the address of the first element of the contents array—call it the begin address . This address is a heap address, which is as expected, since the contents must have dynamic lifetime. The value of the begin address is the same as that of v.data() .
Bytes 8–15 hold the address just past the contents array—call it the end address . Its value is the same as &v.data()[v.size()] . If the vector is empty, then the begin address and the end address are the same.
Bytes 16–23 hold an address greater than or equal to the end address. This is the capacity address . As a vector grows, it will sometimes outgrow its current location and move its contents to new memory addresses. To reduce the number of copies, vectors usually to request more memory from the operating system than they immediately need; this additional space, which is called “capacity,” supports cheap growth. Often the capacity doubles on each growth spurt, since this allows operations like v.push_back() to execute in O (1) time on average.
Compilers must also decide where different objects are stored when those objects are not part of a collection. For instance, consider this program:
The abstract machine says these objects cannot overlap, but does not otherwise constrain their positions in memory.
On Linux, GCC will put all these variables into the stack segment, which we can see using hexdump . But it can put them in the stack segment in any order , as we can see by reordering the declarations (try declaration order i1 , c1 , i2 , c2 , c3 ), by changing optimization levels, or by adding different scopes (braces). The abstract machine gives the programmer no guarantees about how object addresses relate. In fact, the compiler may move objects around during execution, as long as it ensures that the program behaves according to the abstract machine. Modern optimizing compilers often do this, particularly for automatic objects.
But what order does the compiler choose? With optimization disabled, the compiler appears to lay out objects in decreasing order by declaration, so the first declared variable in the function has the highest address. With optimization enabled, the compiler follows roughly the same guideline, but it also rearranges objects by type—for instance, it tends to group char s together—and it can reuse space if different variables in the same function have disjoint lifetimes. The optimizing compiler tends to use less space for the same set of variables. This is because it’s arranging objects by alignment.
The C++ compiler and library restricts the addresses at which some kinds of data appear. In particular, the address of every int value is always a multiple of 4, whether it’s located on the stack (automatic lifetime), the data segment (static lifetime), or the heap (dynamic lifetime).
A bunch of observations will show you these rules:
| Type | Size | Address restrictions | ( ) |
|---|---|---|---|
| ( , ) | 1 | No restriction | 1 |
| ( ) | 2 | Multiple of 2 | 2 |
| ( ) | 4 | Multiple of 4 | 4 |
| ( ) | 8 | Multiple of 8 | 8 |
| 4 | Multiple of 4 | 4 | |
| 8 | Multiple of 8 | 8 | |
| 16 | Multiple of 16 | 16 | |
| 8 | Multiple of 8 | 8 |
These are the alignment restrictions for an x86-64 Linux machine.
These restrictions hold for most x86-64 operating systems, except that on Windows, the long type has size and alignment 4. (The long long type has size and alignment 8 on all x86-64 operating systems.)
Just like every type has a size, every type has an alignment. The alignment of a type T is a number a ≥1 such that the address of every object of type T must be a multiple of a . Every object with type T has size sizeof(T) —it occupies sizeof(T) contiguous bytes of memory; and has alignment alignof(T) —the address of its first byte is a multiple of alignof(T) . You can also say sizeof(x) and alignof(x) where x is the name of an object or another expression.
Alignment restrictions can make hardware simpler, and therefore faster. For instance, consider cache blocks. CPUs access memory through a transparent hardware cache. Data moves from primary memory, or RAM (which is large—a couple gigabytes on most laptops—and uses cheaper, slower technology) to the cache in units of 64 or 128 bytes. Those units are always aligned: on a machine with 128-byte cache blocks, the bytes with memory addresses [127, 128, 129, 130] live in two different cache blocks (with addresses [0, 127] and [128, 255]). But the 4 bytes with addresses [4n, 4n+1, 4n+2, 4n+3] always live in the same cache block. (This is true for any small power of two: the 8 bytes with addresses [8n,…,8n+7] always live in the same cache block.) In general, it’s often possible to make a system faster by leveraging restrictions—and here, the CPU hardware can load data faster when it can assume that the data lives in exactly one cache line.
The compiler, library, and operating system all work together to enforce alignment restrictions.
On x86-64 Linux, alignof(T) == sizeof(T) for all fundamental types (the types built in to C: integer types, floating point types, and pointers). But this isn’t always true; on x86-32 Linux, double has size 8 but alignment 4.
It’s possible to construct user-defined types of arbitrary size, but the largest alignment required by a machine is fixed for that machine. C++ lets you find the maximum alignment for a machine with alignof(std::max_align_t) ; on x86-64, this is 16, the alignment of the type long double (and the alignment of some less-commonly-used SIMD “vector” types ).
We now turn to the abstract machine rules for laying out all collections. The sizes and alignments for user-defined types—arrays, structs, and unions—are derived from a couple simple rules or principles. Here they are. The first rule applies to all types.
1. First-member rule. The address of the first member of a collection equals the address of the collection.
Thus, the address of an array is the same as the address of its first element. The address of a struct is the same as the address of the first member of the struct.
The next three rules depend on the class of collection. Every C abstract machine enforces these rules.
2. Array rule. Arrays are laid out sequentially as described above.
3. Struct rule. The second and subsequent members of a struct are laid out in order, with no overlap, subject to alignment constraints.
4. Union rule. All members of a union share the address of the union.
In C, every struct follows the struct rule, but in C++, only simple structs follow the rule. Complicated structs, such as structs with some public and some private members, or structs with virtual functions, can be laid out however the compiler chooses. The typical situation is that C++ compilers for a machine architecture (e.g., “Linux x86-64”) will all agree on a layout procedure for complicated structs. This allows code compiled by different compilers to interoperate.
That next rule defines the operation of the malloc library function.
5. Malloc rule. Any non-null pointer returned by malloc has alignment appropriate for any type. In other words, assuming the allocated size is adequate, the pointer returned from malloc can safely be cast to T* for any T .
Oddly, this holds even for small allocations. The C++ standard (the abstract machine) requires that malloc(1) return a pointer whose alignment is appropriate for any type, including types that don’t fit.
And the final rule is not required by the abstract machine, but it’s how sizes and alignments on our machines work.
6. Minimum rule. The sizes and alignments of user-defined types, and the offsets of struct members, are minimized within the constraints of the other rules.
The minimum rule, and the sizes and alignments of basic types, are defined by the x86-64 Linux “ABI” —its Application Binary Interface. This specification standardizes how x86-64 Linux C compilers should behave, and lets users mix and match compilers without problems.
Consequences of the size and alignment rules
From these rules we can derive some interesting consequences.
First, the size of every type is a multiple of its alignment .
To see why, consider an array with two elements. By the array rule, these elements have addresses a and a+sizeof(T) , where a is the address of the array. Both of these addresses contain a T , so they are both a multiple of alignof(T) . That means sizeof(T) is also a multiple of alignof(T) .
We can also characterize the sizes and alignments of different collections .
- The size of an array of N elements of type T is N * sizeof(T) : the sum of the sizes of its elements. The alignment of the array is alignof(T) .
- The size of a union is the maximum of the sizes of its components (because the union can only hold one component at a time). Its alignment is also the maximum of the alignments of its components.
- The size of a struct is at least as big as the sum of the sizes of its components. Its alignment is the maximum of the alignments of its components.
Thus, the alignment of every collection equals the maximum of the alignments of its components.
It’s also true that the alignment equals the least common multiple of the alignments of its components. You might have thought lcm was a better answer, but the max is the same as the lcm for every architecture that matters, because all fundamental alignments are powers of two.
The size of a struct might be larger than the sum of the sizes of its components, because of alignment constraints. Since the compiler must lay out struct components in order, and it must obey the components’ alignment constraints, and it must ensure different components occupy disjoint addresses, it must sometimes introduce extra space in structs. Here’s an example: the struct will have 3 bytes of padding after char c , to ensure that int i2 has the correct alignment.
Thanks to padding, reordering struct components can sometimes reduce the total size of a struct. Padding can happen at the end of a struct as well as the middle. Padding can never happen at the start of a struct, however (because of Rule 1).
The rules also imply that the offset of any struct member —which is the difference between the address of the member and the address of the containing struct— is a multiple of the member’s alignment .
To see why, consider a struct s with member m at offset o . The malloc rule says that any pointer returned from malloc is correctly aligned for s . Every pointer returned from malloc is maximally aligned, equalling 16*x for some integer x . The struct rule says that the address of m , which is 16*x + o , is correctly aligned. That means that 16*x + o = alignof(m)*y for some integer y . Divide both sides by a = alignof(m) and you see that 16*x/a + o/a = y . But 16/a is an integer—the maximum alignment is a multiple of every alignment—so 16*x/a is an integer. We can conclude that o/a must also be an integer!
Finally, we can also derive the necessity for padding at the end of structs. (How?)
What happens when an object is uninitialized? The answer depends on its lifetime.
- static lifetime (e.g., int global; at file scope): The object is initialized to 0.
- automatic or dynamic lifetime (e.g., int local; in a function, or int* ptr = new int ): The object is uninitialized and reading the object’s value before it is assigned causes undefined behavior.
Compiler hijinks
In C++, most dynamic memory allocation uses special language operators, new and delete , rather than library functions.
Though this seems more complex than the library-function style, it has advantages. A C compiler cannot tell what malloc and free do (especially when they are redefined to debugging versions, as in the problem set), so a C compiler cannot necessarily optimize calls to malloc and free away. But the C++ compiler may assume that all uses of new and delete follow the rules laid down by the abstract machine. That means that if the compiler can prove that an allocation is unnecessary or unused, it is free to remove that allocation!
For example, we compiled this program in the problem set environment (based on test003.cc ):
The optimizing C++ compiler removes all calls to new and delete , leaving only the call to m61_printstatistics() ! (For instance, try objdump -d testXXX to look at the compiled x86-64 instructions.) This is valid because the compiler is explicitly allowed to eliminate unused allocations, and here, since the ptrs variable is local and doesn’t escape main , all allocations are unused. The C compiler cannot perform this useful transformation. (But the C compiler can do other cool things, such as unroll the loops .)
One of C’s more interesting choices is that it explicitly relates pointers and arrays. Although arrays are laid out in memory in a specific way, they generally behave like pointers when they are used. This property probably arose from C’s desire to explicitly model memory as an array of bytes, and it has beautiful and confounding effects.
We’ve already seen one of these effects. The hexdump function has this signature (arguments and return type):
But we can just pass an array as argument to hexdump :
When used in an expression like this—here, as an argument—the array magically changes into a pointer to its first element. The above call has the same meaning as this:
C programmers transition between arrays and pointers very naturally.
A confounding effect is that unlike all other types, in C arrays are passed to and returned from functions by reference rather than by value. C is a call-by-value language except for arrays. This means that all function arguments and return values are copied, so that parameter modifications inside a function do not affect the objects passed by the caller—except for arrays. For instance: void f ( int a[ 2 ]) { a[ 0 ] = 1 ; } int main () { int x[ 2 ] = { 100 , 101 }; f(x); printf( "%d \n " , x[ 0 ]); // prints 1! } If you don’t like this behavior, you can get around it by using a struct or a C++ std::array . #include <array> struct array1 { int a[ 2 ]; }; void f1 (array1 arg) { arg.a[ 0 ] = 1 ; } void f2 (std :: array < int , 2 > a) { a[ 0 ] = 1 ; } int main () { array1 x = {{ 100 , 101 }}; f1(x); printf( "%d \n " , x.a[ 0 ]); // prints 100 std :: array < int , 2 > x2 = { 100 , 101 }; f2(x2); printf( "%d \n " , x2[ 0 ]); // prints 100 }
C++ extends the logic of this array–pointer correspondence to support arithmetic on pointers as well.
Pointer arithmetic rule. In the C abstract machine, arithmetic on pointers produces the same result as arithmetic on the corresponding array indexes.
Specifically, consider an array T a[n] and pointers T* p1 = &a[i] and T* p2 = &a[j] . Then:
Equality : p1 == p2 if and only if (iff) p1 and p2 point to the same address, which happens iff i == j .
Inequality : Similarly, p1 != p2 iff i != j .
Less-than : p1 < p2 iff i < j .
Also, p1 <= p2 iff i <= j ; and p1 > p2 iff i > j ; and p1 >= p2 iff i >= j .
Pointer difference : What should p1 - p2 mean? Using array indexes as the basis, p1 - p2 == i - j . (But the type of the difference is always ptrdiff_t , which on x86-64 is long , the signed version of size_t .)
Addition : p1 + k (where k is an integer type) equals the pointer &a[i + k] . ( k + p1 returns the same thing.)
Subtraction : p1 - k equals &a[i - k] .
Increment and decrement : ++p1 means p1 = p1 + 1 , which means p1 = &a[i + 1] . Similarly, --p1 means p1 = &a[i - 1] . (There are also postfix versions, p1++ and p1-- , but C++ style prefers the prefix versions.)
No other arithmetic operations on pointers are allowed. You can’t multiply pointers, for example. (You can multiply addresses by casting the pointers to the address type, uintptr_t —so (uintptr_t) p1 * (uintptr_t) p2 —but why would you?)
From pointers to iterators
Let’s write a function that can sum all the integers in an array.
This function can compute the sum of the elements of any int array. But because of the pointer–array relationship, its a argument is really a pointer . That allows us to call it with subarrays as well as with whole arrays. For instance:
This way of thinking about arrays naturally leads to a style that avoids sizes entirely, using instead a sentinel or boundary argument that defines the end of the interesting part of the array.
These expressions compute the same sums as the above:
Note that the data from first to last forms a half-open range . iIn mathematical notation, we care about elements in the range [first, last) : the element pointed to by first is included (if it exists), but the element pointed to by last is not. Half-open ranges give us a simple and clear way to describe empty ranges, such as zero-element arrays: if first == last , then the range is empty.
Note that given a ten-element array a , the pointer a + 10 can be formed and compared, but must not be dereferenced—the element a[10] does not exist. The C/C++ abstract machines allow users to form pointers to the “one-past-the-end” boundary elements of arrays, but users must not dereference such pointers.
So in C, two pointers naturally express a range of an array. The C++ standard template library, or STL, brilliantly abstracts this pointer notion to allow two iterators , which are pointer-like objects, to express a range of any standard data structure—an array, a vector, a hash table, a balanced tree, whatever. This version of sum works for any container of int s; notice how little it changed:
Some example uses:
Addresses vs. pointers
What’s the difference between these expressions? (Again, a is an array of type T , and p1 == &a[i] and p2 == &a[j] .)
The first expression is defined analogously to index arithmetic, so d1 == i - j . But the second expression performs the arithmetic on the addresses corresponding to those pointers. We will expect d2 to equal sizeof(T) * d1 . Always be aware of which kind of arithmetic you’re using. Generally arithmetic on pointers should not involve sizeof , since the sizeof is included automatically according to the abstract machine; but arithmetic on addresses almost always should involve sizeof .
Although C++ is a low-level language, the abstract machine is surprisingly strict about which pointers may be formed and how they can be used. Violate the rules and you’re in hell because you have invoked the dreaded undefined behavior .
Given an array a[N] of N elements of type T :
Forming a pointer &a[i] (or a + i ) with 0 ≤ i ≤ N is safe.
Forming a pointer &a[i] with i < 0 or i > N causes undefined behavior.
Dereferencing a pointer &a[i] with 0 ≤ i < N is safe.
Dereferencing a pointer &a[i] with i < 0 or i ≥ N causes undefined behavior.
(For the purposes of these rules, objects that are not arrays count as single-element arrays. So given T x , we can safely form &x and &x + 1 and dereference &x .)
What “undefined behavior” means is horrible. A program that executes undefined behavior is erroneous. But the compiler need not catch the error. In fact, the abstract machine says anything goes : undefined behavior is “behavior … for which this International Standard imposes no requirements.” “Possible undefined behavior ranges from ignoring the situation completely with unpredictable results, to behaving during translation or program execution in a documented manner characteristic of the environment (with or without the issuance of a diagnostic message), to terminating a translation or execution (with the issuance of a diagnostic message).” Other possible behaviors include allowing hackers from the moon to steal all of a program’s data, take it over, and force it to delete the hard drive on which it is running. Once undefined behavior executes, a program may do anything, including making demons fly out of the programmer’s nose.
Pointer arithmetic, and even pointer comparisons, are also affected by undefined behavior. It’s undefined to go beyond and array’s bounds using pointer arithmetic. And pointers may be compared for equality or inequality even if they point to different arrays or objects, but if you try to compare different arrays via less-than, like this:
that causes undefined behavior.
If you really want to compare pointers that might be to different arrays—for instance, you’re writing a hash function for arbitrary pointers—cast them to uintptr_t first.
Undefined behavior and optimization
A program that causes undefined behavior is not a C++ program . The abstract machine says that a C++ program, by definition, is a program whose behavior is always defined. The C++ compiler is allowed to assume that its input is a C++ program. (Obviously!) So the compiler can assume that its input program will never cause undefined behavior. Thus, since undefined behavior is “impossible,” if the compiler can prove that a condition would cause undefined behavior later, it can assume that condition will never occur.
Consider this program:
If we supply a value equal to (char*) -1 , we’re likely to see output like this:
with no assertion failure! But that’s an apparently impossible result. The printout can only happen if x + 1 > x (otherwise, the assertion will fail and stop the printout). But x + 1 , which equals 0 , is less than x , which is the largest 8-byte value!
The impossible happens because of undefined behavior reasoning. When the compiler sees an expression like x + 1 > x (with x a pointer), it can reason this way:
“Ah, x + 1 . This must be a pointer into the same array as x (or it might be a boundary pointer just past that array, or just past the non-array object x ). This must be so because forming any other pointer would cause undefined behavior.
“The pointer comparison is the same as an index comparison. x + 1 > x means the same thing as &x[1] > &x[0] . But that holds iff 1 > 0 .
“In my infinite wisdom, I know that 1 > 0 . Thus x + 1 > x always holds, and the assertion will never fail.
“My job is to make this code run fast. The fastest code is code that’s not there. This assertion will never fail—might as well remove it!”
Integer undefined behavior
Arithmetic on signed integers also has important undefined behaviors. Signed integer arithmetic must never overflow. That is, the compiler may assume that the mathematical result of any signed arithmetic operation, such as x + y (with x and y both int ), can be represented inside the relevant type. It causes undefined behavior, therefore, to add 1 to the maximum positive integer. (The ubexplore.cc program demonstrates how this can produce impossible results, as with pointers.)
Arithmetic on unsigned integers is much safer with respect to undefined behavior. Unsigned integers are defined to perform arithmetic modulo their size. This means that if you add 1 to the maximum positive unsigned integer, the result will always be zero.
Dividing an integer by zero causes undefined behavior whether or not the integer is signed.
Sanitizers, which in our makefiles are turned on by supplying SAN=1 , can catch many undefined behaviors as soon as they happen. Sanitizers are built in to the compiler itself; a sanitizer involves cooperation between the compiler and the language runtime. This has the major performance advantage that the compiler introduces exactly the required checks, and the optimizer can then use its normal analyses to remove redundant checks.
That said, undefined behavior checking can still be slow. Undefined behavior allows compilers to make assumptions about input values, and those assumptions can directly translate to faster code. Turning on undefined behavior checking can make some benchmark programs run 30% slower [link] .
Signed integer undefined behavior
File cs61-lectures/datarep5/ubexplore2.cc contains the following program.
What will be printed if we run the program with ./ubexplore2 0x7ffffffe 0x7fffffff ?
0x7fffffff is the largest positive value can be represented by type int . Adding one to this value yields 0x80000000 . In two's complement representation this is the smallest negative number represented by type int .
Assuming that the program behaves this way, then the loop exit condition i > n2 can never be met, and the program should run (and print out numbers) forever.
However, if we run the optimized version of the program, it prints only two numbers and exits:
The unoptimized program does print forever and never exits.
What’s going on here? We need to look at the compiled assembly of the program with and without optimization (via objdump -S ).
The unoptimized version basically looks like this:
This is a pretty direct translation of the loop.
The optimized version, though, does it differently. As always, the optimizer has its own ideas. (Your compiler may produce different results!)
The compiler changed the source’s less than or equal to comparison, i <= n2 , into a not equal to comparison in the executable, i != n2 + 1 (in both cases using signed computer arithmetic, i.e., modulo 2 32 )! The comparison i <= n2 will always return true when n2 == 0x7FFFFFFF , the maximum signed integer, so the loop goes on forever. But the i != n2 + 1 comparison does not always return true when n2 == 0x7FFFFFFF : when i wraps around to 0x80000000 (the smallest negative integer), then i equals n2 + 1 (which also wrapped), and the loop stops.
Why did the compiler make this transformation? In the original loop, the step-6 jump is immediately followed by another comparison and jump in steps 1 and 2. The processor jumps all over the place, which can confuse its prediction circuitry and slow down performance. In the transformed loop, the step-7 jump is never followed by a comparison and jump; instead, step 7 goes back to step 4, which always prints the current number. This more streamlined control flow is easier for the processor to make fast.
But the streamlined control flow is only a valid substitution under the assumption that the addition n2 + 1 never overflows . Luckily (sort of), signed arithmetic overflow causes undefined behavior, so the compiler is totally justified in making that assumption!
Programs based on ubexplore2 have demonstrated undefined behavior differences for years, even as the precise reasons why have changed. In some earlier compilers, we found that the optimizer just upgraded the int s to long s—arithmetic on long s is just as fast on x86-64 as arithmetic on int s, since x86-64 is a 64-bit architecture, and sometimes using long s for everything lets the compiler avoid conversions back and forth. The ubexplore2l program demonstrates this form of transformation: since the loop variable is added to a long counter, the compiler opportunistically upgrades i to long as well. This transformation is also only valid under the assumption that i + 1 will not overflow—which it can’t, because of undefined behavior.
Using unsigned type prevents all this undefined behavior, because arithmetic overflow on unsigned integers is well defined in C/C++. The ubexplore2u.cc file uses an unsigned loop index and comparison, and ./ubexplore2u and ./ubexplore2u.noopt behave exactly the same (though you have to give arguments like ./ubexplore2u 0xfffffffe 0xffffffff to see the overflow).
Computer arithmetic and bitwise operations
Basic bitwise operators.
Computers offer not only the usual arithmetic operators like + and - , but also a set of bitwise operators. The basic ones are & (and), | (or), ^ (xor/exclusive or), and the unary operator ~ (complement). In truth table form:
| (and) | ||
|---|---|---|
| 0 | 0 | |
| 0 | 1 |
| (or) | ||
|---|---|---|
| 0 | 1 | |
| 1 | 1 |
| (xor) | ||
|---|---|---|
| 0 | 1 | |
| 1 | 0 |
| (complement) | |
|---|---|
| 1 | |
| 0 |
In C or C++, these operators work on integers. But they work bitwise: the result of an operation is determined by applying the operation independently at each bit position. Here’s how to compute 12 & 4 in 4-bit unsigned arithmetic:
These basic bitwise operators simplify certain important arithmetics. For example, (x & (x - 1)) == 0 tests whether x is zero or a power of 2.
Negation of signed integers can also be expressed using a bitwise operator: -x == ~x + 1 . This is in fact how we define two's complement representation. We can verify that x and (-x) does add up to zero under this representation:
Bitwise "and" ( & ) can help with modular arithmetic. For example, x % 32 == (x & 31) . We essentially "mask off", or clear, higher order bits to do modulo-powers-of-2 arithmetics. This works in any base. For example, in decimal, the fastest way to compute x % 100 is to take just the two least significant digits of x .
Bitwise shift of unsigned integer
x << i appends i zero bits starting at the least significant bit of x . High order bits that don't fit in the integer are thrown out. For example, assuming 4-bit unsigned integers
Similarly, x >> i appends i zero bits at the most significant end of x . Lower bits are thrown out.
Bitwise shift helps with division and multiplication. For example:
A modern compiler can optimize y = x * 66 into y = (x << 6) + (x << 1) .
Bitwise operations also allows us to treat bits within an integer separately. This can be useful for "options".
For example, when we call a function to open a file, we have a lot of options:
- Open for reading?
- Open for writing?
- Read from the end?
- Optimize for writing?
We have a lot of true/false options.
One bad way to implement this is to have this function take a bunch of arguments -- one argument for each option. This makes the function call look like this:
The long list of arguments slows down the function call, and one can also easily lose track of the meaning of the individual true/false values passed in.
A cheaper way to achieve this is to use a single integer to represent all the options. Have each option defined as a power of 2, and simply | (or) them together and pass them as a single integer.
Flags are usually defined as powers of 2 so we set one bit at a time for each flag. It is less common but still possible to define a combination flag that is not a power of 2, so that it sets multiple bits in one go.
File cs61-lectures/datarep5/mb-driver.cc contains a memory allocation benchmark. The core of the benchmark looks like this:
The benchmark tests the performance of memnode_arena::allocate() and memnode_arena::deallocate() functions. In the handout code, these functions do the same thing as new memnode and delete memnode —they are wrappers for malloc and free . The benchmark allocates 4096 memnode objects, then free-and-then-allocates them for noperations times, and then frees all of them.
We only allocate memnode s, and all memnode s are of the same size, so we don't need metadata that keeps track of the size of each allocation. Furthermore, since all dynamically allocated data are freed at the end of the function, for each individual memnode_free() call we don't really need to return memory to the system allocator. We can simply reuse these memory during the function and returns all memory to the system at once when the function exits.
If we run the benchmark with 100000000 allocation, and use the system malloc() , free() functions to implement the memnode allocator, the benchmark finishes in 0.908 seconds.
Our alternative implementation of the allocator can finish in 0.355 seconds, beating the heavily optimized system allocator by a factor of 3. We will reveal how we achieved this in the next lecture.
We continue our exploration with the memnode allocation benchmark introduced from the last lecture.
File cs61-lectures/datarep6/mb-malloc.cc contains a version of the benchmark using the system new and delete operators.
In this function we allocate an array of 4096 pointers to memnode s, which occupy 2 3 *2 12 =2 15 bytes on the stack. We then allocate 4096 memnode s. Our memnode is defined like this:
Each memnode contains a std::string object and an unsigned integer. Each std::string object internally contains a pointer points to an character array in the heap. Therefore, every time we create a new memnode , we need 2 allocations: one to allocate the memnode itself, and another one performed internally by the std::string object when we initialize/assign a string value to it.
Every time we deallocate a memnode by calling delete , we also delete the std::string object, and the string object knows that it should deallocate the heap character array it internally maintains. So there are also 2 deallocations occuring each time we free a memnode.
We make the benchmark to return a seemingly meaningless result to prevent an aggressive compiler from optimizing everything away. We also use this result to make sure our subsequent optimizations to the allocator are correct by generating the same result.
This version of the benchmark, using the system allocator, finishes in 0.335 seconds. Not bad at all.
Spoiler alert: We can do 15x better than this.
1st optimization: std::string
We only deal with one file name, namely "datarep/mb-filename.cc", which is constant throughout the program for all memnode s. It's also a string literal, which means it as a constant string has a static life time. Why can't we just simply use a const char* in place of the std::string and let the pointer point to the static constant string? This saves us the internal allocation/deallocation performed by std::string every time we initialize/delete a string.
The fix is easy, we simply change the memnode definition:
This version of the benchmark now finishes in 0.143 seconds, a 2x improvement over the original benchmark. This 2x improvement is consistent with a 2x reduction in numbers of allocation/deallocation mentioned earlier.
You may ask why people still use std::string if it involves an additional allocation and is slower than const char* , as shown in this benchmark. std::string is much more flexible in that it also deals data that doesn't have static life time, such as input from a user or data the program receives over the network. In short, when the program deals with strings that are not constant, heap data is likely to be very useful, and std::string provides facilities to conveniently handle on-heap data.
2nd optimization: the system allocator
We still use the system allocator to allocate/deallocate memnode s. The system allocator is a general-purpose allocator, which means it must handle allocation requests of all sizes. Such general-purpose designs usually comes with a compromise for performance. Since we are only memnode s, which are fairly small objects (and all have the same size), we can build a special- purpose allocator just for them.
In cs61-lectures/datarep5/mb2.cc , we actually implement a special-purpose allocator for memnode s:
This allocator maintains a free list (a C++ vector ) of freed memnode s. allocate() simply pops a memnode off the free list if there is any, and deallocate() simply puts the memnode on the free list. This free list serves as a buffer between the system allocator and the benchmark function, so that the system allocator is invoked less frequently. In fact, in the benchmark, the system allocator is only invoked for 4096 times when it initializes the pointer array. That's a huge reduction because all 10-million "recycle" operations in the middle now doesn't involve the system allocator.
With this special-purpose allocator we can finish the benchmark in 0.057 seconds, another 2.5x improvement.
However this allocator now leaks memory: it never actually calls delete ! Let's fix this by letting it also keep track of all allocated memnode s. The modified definition of memnode_arena now looks like this:
With the updated allocator we simply need to invoke arena.destroy_all() at the end of the function to fix the memory leak. And we don't even need to invoke this method manually! We can use the C++ destructor for the memnode_arena struct, defined as ~memnode_arena() in the code above, which is automatically called when our arena object goes out of scope. We simply make the destructor invoke the destroy_all() method, and we are all set.
Fixing the leak doesn't appear to affect performance at all. This is because the overhead added by tracking the allocated list and calling delete only affects our initial allocation the 4096 memnode* pointers in the array plus at the very end when we clean up. These 8192 additional operations is a relative small number compared to the 10 million recycle operations, so the added overhead is hardly noticeable.
Spoiler alert: We can improve this by another factor of 2.
3rd optimization: std::vector
In our special purpose allocator memnode_arena , we maintain an allocated list and a free list both using C++ std::vector s. std::vector s are dynamic arrays, and like std::string they involve an additional level of indirection and stores the actual array in the heap. We don't access the allocated list during the "recycling" part of the benchmark (which takes bulk of the benchmark time, as we showed earlier), so the allocated list is probably not our bottleneck. We however, add and remove elements from the free list for each recycle operation, and the indirection introduced by the std::vector here may actually be our bottleneck. Let's find out.
Instead of using a std::vector , we could use a linked list of all free memnode s for the actual free list. We will need to include some extra metadata in the memnode to store pointers for this linked list. However, unlike in the debugging allocator pset, in a free list we don't need to store this metadata in addition to actual memnode data: the memnode is free, and not in use, so we can use reuse its memory, using a union:
We then maintain the free list like this:
Compared to the std::vector free list, this free list we always directly points to an available memnode when it is not empty ( free_list !=nullptr ), without going through any indirection. In the std::vector free list one would first have to go into the heap to access the actual array containing pointers to free memnode s, and then access the memnode itself.
With this change we can now finish the benchmark under 0.3 seconds! Another 2x improvement over the previous one!
Compared to the benchmark with the system allocator (which finished in 0.335 seconds), we managed to achieve a speedup of nearly 15x with arena allocation.
Code With C
The Way to Programming
- C Tutorials
- Java Tutorials
- Python Tutorials
- PHP Tutorials
- Java Projects
Understanding Bits and Bytes: Exploring Data Representation
Understanding Bits and Bytes
Hey there, tech-savvy pals! Today, we’re going to unravel the mysteries of data representation by delving into the realm of bits and bytes. 🤓 Let’s break it down like never before!
Definition of Bits and Bytes
First things first, let’s talk about what bits and bytes actually are. Bits are the smallest units of data in computing, represented as either a 0 or a 1. On the other hand, a byte consists of 8 bits . Yep, you heard that right, 8 bits cozying up together in a byte!
Purpose and Importance of Understanding Bits and Bytes
Now, you might be wondering, “Why do I need to wrap my head around these bits and bytes?” Well, buckle up because understanding them is like holding the key to a secret coding treasure chest! From programming to data storage , bits and bytes are the building blocks of the digital world.
Data Representation with 8 Bits in a Byte
Understanding the binary system.
Ah, the binary system, where everything boils down to 0s and 1s. It’s like the yin and yang of the computing world, representing off and on states. With just two digits, the binary system works wonders in storing and processing data efficiently .
How 8 Bits in a Byte Represent Data
Picture this: each bit in a byte is like a tiny switch that can either be off (0) or on (1). By combining 8 of these switches, we can create unique patterns to represent different characters, numbers, or instructions in a computer.
Number of Possible Values with 8 Bits in a Byte
Understanding the concept of combinations and permutations.
Now, let’s dive into the math realm for a bit. To calculate the number of possible values with 8 bits in a byte, we need to unleash the power of combinations and permutations. It’s all about the art of arranging those 0s and 1s in various ways!
Calculation of Possible Values with 8 Bits in a Byte
So, the burning question is, how many possible values can we have with the 8 bits snugly nestled in a byte? Drumroll, please! 🥁 It’s a whopping 256 different values! That’s right, from 00000000 to 11111111, the possibilities are endless.
Comparison with Other Data Representation Systems
Comparison with decimal and hexadecimal systems.
Let’s shake things up a bit by comparing our trusty 8-bit byte with other data representation systems like decimal and hexadecimal. While decimal uses 10 digits (0-9) and hexadecimal employs 16 characters (0-9, A-F), our byte stands strong with its compact yet powerful 8-bit structure.
Advantages and Disadvantages of Using 8 Bits in a Byte for Data Representation
Ah, the age-old debate of pros and cons! The 8-bit byte offers a balance between efficiency and complexity. It’s great for representing a wide range of values efficiently, but it might fall short when handling large datasets that require more precision.
Applications of Data Representation with 8 Bits in a Byte
Use of 8 bits in a byte in computer systems.
From processing instructions to storing images and text, the humble 8-bit byte plays a crucial role in the inner workings of computer systems. It’s like the unsung hero silently powering our digital world behind the scenes.
Impact of Data Representation on Computer Processing and Storage
Imagine a world without efficient data representation—chaos, right? By optimizing how data is represented using 8 bits in a byte, we can enhance computer processing speed, reduce storage requirements, and pave the way for smarter technologies.
Overall, understanding the basics of bits and bytes opens up a treasure trove of possibilities in the vast landscape of computing. So, embrace the binary charm, dive into the world of data representation, and remember: when it doubt, byte it out! 💻✨
Random Fact: Did you know that the term “byte” was coined by Dr. Werner Buchholz in 1956 while working on the IBM Stretch computer? 🤯
In closing, keep coding, keep exploring, and may the bits be ever in your favor! 🚀
Program Code – Understanding Bits and Bytes: Exploring Data Representation
Code output:, code explanation:.
This program is all about working with the inner bits and bytes, the OG Morse code of computing if y’know what I mean. So grab your coder goggles; it’s about to get bit-y.
First, we’ve got to_binary() . This bad boy takes an integer and spits out a binary string so neat you could tie it with a bow. You can even set the number of bits for extra fun.
Next on deck is to_hex() . Ever need to cook up an integer in hex form with that chef’s kiss ‘0x’ garnish? This function has got your back.
If you’re drowning in a sea of binary with binary_to_int() , this lifeboat turns that ‘101010’ SOS into a cozy integer island you can land on.
But wait, there’s more! hex_to_int() is like your hex translator, turning those wacky ‘0x’ phrases into plain old integers you can understand.
Let’s talk text messages—old school style with ascii_to_binary() . Give it a string and bam, you have a binary sequence that practically telegraphs your message.
And if you ever need to decode those binary smoke signals back into text, binary_to_ascii() is the rescue chopper bringing you back to civilization aka ASCII land.
The main event is all about showing off these functions like proud parents at a school play. We’ve got number play, binary banter, hex chit-chat, and even a lovely ASCII-bian dramatization.
So in a nutshell, this code is the ultimate translator, bridging the gap between human-friendly and computer-lingo. Creating this and trying to explain it feels like teaching your grandma to Snapchat… but hey, I hope y’all find it as nifty as a new Spotify playlist! Thanks for tuning in, and keep on coding in the free world! ✌️👩💻
You Might Also Like
Creating a google sheet to track google drive files: step-by-step guide, revolutionary feedback control project for social networking: enhancing information spread, the evolution of web development: past, present, and future, defining the future: an overview of software services, exploring the layers: the multifaceted world of software.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Latest Posts

Cutting-Edge Artificial Intelligence Project Unveiled in Machine Learning World

Enhancing Exams with Image Processing: E-Assessment Project

Cutting-Edge Blockchain Projects for Cryptocurrency Enthusiasts – Project

Artificial Intelligence Marvel: Cutting-Edge Machine Learning Project
Privacy overview.
Sign in to your account
Username or Email Address
Remember Me
TABLE OF CONTENTS (HIDE)
A tutorial on data representation, integers, floating-point numbers, and characters, number systems.
Human beings use decimal (base 10) and duodecimal (base 12) number systems for counting and measurements (probably because we have 10 fingers and two big toes). Computers use binary (base 2) number system, as they are made from binary digital components (known as transistors) operating in two states - on and off. In computing, we also use hexadecimal (base 16) or octal (base 8) number systems, as a compact form for representing binary numbers.
Decimal (Base 10) Number System
Decimal number system has ten symbols: 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , and 9 , called digit s. It uses positional notation . That is, the least-significant digit (right-most digit) is of the order of 10^0 (units or ones), the second right-most digit is of the order of 10^1 (tens), the third right-most digit is of the order of 10^2 (hundreds), and so on, where ^ denotes exponent. For example,
We shall denote a decimal number with an optional suffix D if ambiguity arises.
Binary (Base 2) Number System
Binary number system has two symbols: 0 and 1 , called bits . It is also a positional notation , for example,
We shall denote a binary number with a suffix B . Some programming languages denote binary numbers with prefix 0b or 0B (e.g., 0b1001000 ), or prefix b with the bits quoted (e.g., b'10001111' ).
A binary digit is called a bit . Eight bits is called a byte (why 8-bit unit? Probably because 8=2 3 ).
Hexadecimal (Base 16) Number System
Hexadecimal number system uses 16 symbols: 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , A , B , C , D , E , and F , called hex digits . It is a positional notation , for example,
We shall denote a hexadecimal number (in short, hex) with a suffix H . Some programming languages denote hex numbers with prefix 0x or 0X (e.g., 0x1A3C5F ), or prefix x with hex digits quoted (e.g., x'C3A4D98B' ).
Each hexadecimal digit is also called a hex digit . Most programming languages accept lowercase 'a' to 'f' as well as uppercase 'A' to 'F' .
Computers uses binary system in their internal operations, as they are built from binary digital electronic components with 2 states - on and off. However, writing or reading a long sequence of binary bits is cumbersome and error-prone (try to read this binary string: 1011 0011 0100 0011 0001 1101 0001 1000B , which is the same as hexadecimal B343 1D18H ). Hexadecimal system is used as a compact form or shorthand for binary bits. Each hex digit is equivalent to 4 binary bits, i.e., shorthand for 4 bits, as follows:
| Hexadecimal | Binary | Decimal |
|---|---|---|
| 0 | 0000 | 0 |
| 1 | 0001 | 1 |
| 2 | 0010 | 2 |
| 3 | 0011 | 3 |
| 4 | 0100 | 4 |
| 5 | 0101 | 5 |
| 6 | 0110 | 6 |
| 7 | 0111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| A | 1010 | 10 |
| B | 1011 | 11 |
| C | 1100 | 12 |
| D | 1101 | 13 |
| E | 1110 | 14 |
| F | 1111 | 15 |
Conversion from Hexadecimal to Binary
Replace each hex digit by the 4 equivalent bits (as listed in the above table), for examples,
Conversion from Binary to Hexadecimal
Starting from the right-most bit (least-significant bit), replace each group of 4 bits by the equivalent hex digit (pad the left-most bits with zero if necessary), for examples,
It is important to note that hexadecimal number provides a compact form or shorthand for representing binary bits.
Conversion from Base r to Decimal (Base 10)
Given a n -digit base r number: d n-1 d n-2 d n-3 ...d 2 d 1 d 0 (base r), the decimal equivalent is given by:
For examples,
Conversion from Decimal (Base 10) to Base r
Use repeated division/remainder. For example,
The above procedure is actually applicable to conversion between any 2 base systems. For example,
Conversion between Two Number Systems with Fractional Part
- Separate the integral and the fractional parts.
- For the integral part, divide by the target radix repeatably, and collect the remainder in reverse order.
- For the fractional part, multiply the fractional part by the target radix repeatably, and collect the integral part in the same order.
Example 1: Decimal to Binary
Example 2: Decimal to Hexadecimal
Exercises (Number Systems Conversion)
- 101010101010
Answers: You could use the Windows' Calculator ( calc.exe ) to carry out number system conversion, by setting it to the Programmer or scientific mode. (Run "calc" ⇒ Select "Settings" menu ⇒ Choose "Programmer" or "Scientific" mode.)
- 1101100B , 1001011110000B , 10001100101000B , 6CH , 12F0H , 2328H .
- 218H , 80H , AAAH , 536D , 128D , 2730D .
- 10101011110011011110B , 1001000110100B , 100000001111B , 703710D , 4660D , 2063D .
- ?? (You work it out!)
Computer Memory & Data Representation
Computer uses a fixed number of bits to represent a piece of data, which could be a number, a character, or others. A n -bit storage location can represent up to 2^ n distinct entities. For example, a 3-bit memory location can hold one of these eight binary patterns: 000 , 001 , 010 , 011 , 100 , 101 , 110 , or 111 . Hence, it can represent at most 8 distinct entities. You could use them to represent numbers 0 to 7, numbers 8881 to 8888, characters 'A' to 'H', or up to 8 kinds of fruits like apple, orange, banana; or up to 8 kinds of animals like lion, tiger, etc.
Integers, for example, can be represented in 8-bit, 16-bit, 32-bit or 64-bit. You, as the programmer, choose an appropriate bit-length for your integers. Your choice will impose constraint on the range of integers that can be represented. Besides the bit-length, an integer can be represented in various representation schemes, e.g., unsigned vs. signed integers. An 8-bit unsigned integer has a range of 0 to 255, while an 8-bit signed integer has a range of -128 to 127 - both representing 256 distinct numbers.
It is important to note that a computer memory location merely stores a binary pattern . It is entirely up to you, as the programmer, to decide on how these patterns are to be interpreted . For example, the 8-bit binary pattern "0100 0001B" can be interpreted as an unsigned integer 65 , or an ASCII character 'A' , or some secret information known only to you. In other words, you have to first decide how to represent a piece of data in a binary pattern before the binary patterns make sense. The interpretation of binary pattern is called data representation or encoding . Furthermore, it is important that the data representation schemes are agreed-upon by all the parties, i.e., industrial standards need to be formulated and straightly followed.
Once you decided on the data representation scheme, certain constraints, in particular, the precision and range will be imposed. Hence, it is important to understand data representation to write correct and high-performance programs.
Rosette Stone and the Decipherment of Egyptian Hieroglyphs

Egyptian hieroglyphs (next-to-left) were used by the ancient Egyptians since 4000BC. Unfortunately, since 500AD, no one could longer read the ancient Egyptian hieroglyphs, until the re-discovery of the Rosette Stone in 1799 by Napoleon's troop (during Napoleon's Egyptian invasion) near the town of Rashid (Rosetta) in the Nile Delta.
The Rosetta Stone (left) is inscribed with a decree in 196BC on behalf of King Ptolemy V. The decree appears in three scripts: the upper text is Ancient Egyptian hieroglyphs , the middle portion Demotic script, and the lowest Ancient Greek . Because it presents essentially the same text in all three scripts, and Ancient Greek could still be understood, it provided the key to the decipherment of the Egyptian hieroglyphs.
The moral of the story is unless you know the encoding scheme, there is no way that you can decode the data.
Reference and images: Wikipedia.
Integer Representation
Integers are whole numbers or fixed-point numbers with the radix point fixed after the least-significant bit. They are contrast to real numbers or floating-point numbers , where the position of the radix point varies. It is important to take note that integers and floating-point numbers are treated differently in computers. They have different representation and are processed differently (e.g., floating-point numbers are processed in a so-called floating-point processor). Floating-point numbers will be discussed later.
Computers use a fixed number of bits to represent an integer. The commonly-used bit-lengths for integers are 8-bit, 16-bit, 32-bit or 64-bit. Besides bit-lengths, there are two representation schemes for integers:
- Unsigned Integers : can represent zero and positive integers.
- Sign-Magnitude representation
- 1's Complement representation
- 2's Complement representation
You, as the programmer, need to decide on the bit-length and representation scheme for your integers, depending on your application's requirements. Suppose that you need a counter for counting a small quantity from 0 up to 200, you might choose the 8-bit unsigned integer scheme as there is no negative numbers involved.
n -bit Unsigned Integers
Unsigned integers can represent zero and positive integers, but not negative integers. The value of an unsigned integer is interpreted as " the magnitude of its underlying binary pattern ".
Example 1: Suppose that n =8 and the binary pattern is 0100 0001B , the value of this unsigned integer is 1×2^0 + 1×2^6 = 65D .
Example 2: Suppose that n =16 and the binary pattern is 0001 0000 0000 1000B , the value of this unsigned integer is 1×2^3 + 1×2^12 = 4104D .
Example 3: Suppose that n =16 and the binary pattern is 0000 0000 0000 0000B , the value of this unsigned integer is 0 .
An n -bit pattern can represent 2^ n distinct integers. An n -bit unsigned integer can represent integers from 0 to (2^ n )-1 , as tabulated below:
| n | Minimum | Maximum |
|---|---|---|
| 8 | 0 | (2^8)-1 (=255) |
| 16 | 0 | (2^16)-1 (=65,535) |
| 32 | 0 | (2^32)-1 (=4,294,967,295) (9+ digits) |
| 64 | 0 | (2^64)-1 (=18,446,744,073,709,551,615) (19+ digits) |
Signed Integers
Signed integers can represent zero, positive integers, as well as negative integers. Three representation schemes are available for signed integers:
In all the above three schemes, the most-significant bit (msb) is called the sign bit . The sign bit is used to represent the sign of the integer - with 0 for positive integers and 1 for negative integers. The magnitude of the integer, however, is interpreted differently in different schemes.
n -bit Sign Integers in Sign-Magnitude Representation
In sign-magnitude representation:
- The most-significant bit (msb) is the sign bit , with value of 0 representing positive integer and 1 representing negative integer.
- The remaining n -1 bits represents the magnitude (absolute value) of the integer. The absolute value of the integer is interpreted as "the magnitude of the ( n -1)-bit binary pattern".
Example 1 : Suppose that n =8 and the binary representation is 0 100 0001B . Sign bit is 0 ⇒ positive Absolute value is 100 0001B = 65D Hence, the integer is +65D
Example 2 : Suppose that n =8 and the binary representation is 1 000 0001B . Sign bit is 1 ⇒ negative Absolute value is 000 0001B = 1D Hence, the integer is -1D
Example 3 : Suppose that n =8 and the binary representation is 0 000 0000B . Sign bit is 0 ⇒ positive Absolute value is 000 0000B = 0D Hence, the integer is +0D
Example 4 : Suppose that n =8 and the binary representation is 1 000 0000B . Sign bit is 1 ⇒ negative Absolute value is 000 0000B = 0D Hence, the integer is -0D

The drawbacks of sign-magnitude representation are:
- There are two representations ( 0000 0000B and 1000 0000B ) for the number zero, which could lead to inefficiency and confusion.
- Positive and negative integers need to be processed separately.
n -bit Sign Integers in 1's Complement Representation
In 1's complement representation:
- Again, the most significant bit (msb) is the sign bit , with value of 0 representing positive integers and 1 representing negative integers.
- for positive integers, the absolute value of the integer is equal to "the magnitude of the ( n -1)-bit binary pattern".
- for negative integers, the absolute value of the integer is equal to "the magnitude of the complement ( inverse ) of the ( n -1)-bit binary pattern" (hence called 1's complement).
Example 1 : Suppose that n =8 and the binary representation 0 100 0001B . Sign bit is 0 ⇒ positive Absolute value is 100 0001B = 65D Hence, the integer is +65D
Example 2 : Suppose that n =8 and the binary representation 1 000 0001B . Sign bit is 1 ⇒ negative Absolute value is the complement of 000 0001B , i.e., 111 1110B = 126D Hence, the integer is -126D
Example 3 : Suppose that n =8 and the binary representation 0 000 0000B . Sign bit is 0 ⇒ positive Absolute value is 000 0000B = 0D Hence, the integer is +0D
Example 4 : Suppose that n =8 and the binary representation 1 111 1111B . Sign bit is 1 ⇒ negative Absolute value is the complement of 111 1111B , i.e., 000 0000B = 0D Hence, the integer is -0D

Again, the drawbacks are:
- There are two representations ( 0000 0000B and 1111 1111B ) for zero.
- The positive integers and negative integers need to be processed separately.
n -bit Sign Integers in 2's Complement Representation
In 2's complement representation:
- for negative integers, the absolute value of the integer is equal to "the magnitude of the complement of the ( n -1)-bit binary pattern plus one " (hence called 2's complement).
Example 2 : Suppose that n =8 and the binary representation 1 000 0001B . Sign bit is 1 ⇒ negative Absolute value is the complement of 000 0001B plus 1 , i.e., 111 1110B + 1B = 127D Hence, the integer is -127D
Example 4 : Suppose that n =8 and the binary representation 1 111 1111B . Sign bit is 1 ⇒ negative Absolute value is the complement of 111 1111B plus 1 , i.e., 000 0000B + 1B = 1D Hence, the integer is -1D

Computers use 2's Complement Representation for Signed Integers
We have discussed three representations for signed integers: signed-magnitude, 1's complement and 2's complement. Computers use 2's complement in representing signed integers. This is because:
- There is only one representation for the number zero in 2's complement, instead of two representations in sign-magnitude and 1's complement.
- Positive and negative integers can be treated together in addition and subtraction. Subtraction can be carried out using the "addition logic".
Example 1: Addition of Two Positive Integers: Suppose that n=8, 65D + 5D = 70D
Example 2: Subtraction is treated as Addition of a Positive and a Negative Integers: Suppose that n=8, 65D - 5D = 65D + (-5D) = 60D
Example 3: Addition of Two Negative Integers: Suppose that n=8, -65D - 5D = (-65D) + (-5D) = -70D
Because of the fixed precision (i.e., fixed number of bits ), an n -bit 2's complement signed integer has a certain range. For example, for n =8 , the range of 2's complement signed integers is -128 to +127 . During addition (and subtraction), it is important to check whether the result exceeds this range, in other words, whether overflow or underflow has occurred.
Example 4: Overflow: Suppose that n=8, 127D + 2D = 129D (overflow - beyond the range)
Example 5: Underflow: Suppose that n=8, -125D - 5D = -130D (underflow - below the range)
The following diagram explains how the 2's complement works. By re-arranging the number line, values from -128 to +127 are represented contiguously by ignoring the carry bit.

Range of n -bit 2's Complement Signed Integers
An n -bit 2's complement signed integer can represent integers from -2^( n -1) to +2^( n -1)-1 , as tabulated. Take note that the scheme can represent all the integers within the range, without any gap. In other words, there is no missing integers within the supported range.
| n | minimum | maximum |
|---|---|---|
| 8 | -(2^7) (=-128) | +(2^7)-1 (=+127) |
| 16 | -(2^15) (=-32,768) | +(2^15)-1 (=+32,767) |
| 32 | -(2^31) (=-2,147,483,648) | +(2^31)-1 (=+2,147,483,647)(9+ digits) |
| 64 | -(2^63) (=-9,223,372,036,854,775,808) | +(2^63)-1 (=+9,223,372,036,854,775,807)(18+ digits) |
Decoding 2's Complement Numbers
- Check the sign bit (denoted as S ).
- If S=0 , the number is positive and its absolute value is the binary value of the remaining n -1 bits.
- If S=1 , the number is negative. you could "invert the n -1 bits and plus 1" to get the absolute value of negative number. Alternatively, you could scan the remaining n -1 bits from the right (least-significant bit). Look for the first occurrence of 1. Flip all the bits to the left of that first occurrence of 1. The flipped pattern gives the absolute value. For example, n = 8, bit pattern = 1 100 0100B S = 1 → negative Scanning from the right and flip all the bits to the left of the first occurrence of 1 ⇒ 011 1 100B = 60D Hence, the value is -60D
Big Endian vs. Little Endian
Modern computers store one byte of data in each memory address or location, i.e., byte addressable memory. An 32-bit integer is, therefore, stored in 4 memory addresses.
The term"Endian" refers to the order of storing bytes in computer memory. In "Big Endian" scheme, the most significant byte is stored first in the lowest memory address (or big in first), while "Little Endian" stores the least significant bytes in the lowest memory address.
For example, the 32-bit integer 12345678H (305419896 10 ) is stored as 12H 34H 56H 78H in big endian; and 78H 56H 34H 12H in little endian. An 16-bit integer 00H 01H is interpreted as 0001H in big endian, and 0100H as little endian.
Exercise (Integer Representation)
- What are the ranges of 8-bit, 16-bit, 32-bit and 64-bit integer, in "unsigned" and "signed" representation?
- Give the value of 88 , 0 , 1 , 127 , and 255 in 8-bit unsigned representation.
- Give the value of +88 , -88 , -1 , 0 , +1 , -128 , and +127 in 8-bit 2's complement signed representation.
- Give the value of +88 , -88 , -1 , 0 , +1 , -127 , and +127 in 8-bit sign-magnitude representation.
- Give the value of +88 , -88 , -1 , 0 , +1 , -127 and +127 in 8-bit 1's complement representation.
- [TODO] more.
- The range of unsigned n -bit integers is [0, 2^n - 1] . The range of n -bit 2's complement signed integer is [-2^(n-1), +2^(n-1)-1] ;
- 88 (0101 1000) , 0 (0000 0000) , 1 (0000 0001) , 127 (0111 1111) , 255 (1111 1111) .
- +88 (0101 1000) , -88 (1010 1000) , -1 (1111 1111) , 0 (0000 0000) , +1 (0000 0001) , -128 (1000 0000) , +127 (0111 1111) .
- +88 (0101 1000) , -88 (1101 1000) , -1 (1000 0001) , 0 (0000 0000 or 1000 0000) , +1 (0000 0001) , -127 (1111 1111) , +127 (0111 1111) .
- +88 (0101 1000) , -88 (1010 0111) , -1 (1111 1110) , 0 (0000 0000 or 1111 1111) , +1 (0000 0001) , -127 (1000 0000) , +127 (0111 1111) .
Floating-Point Number Representation
A floating-point number (or real number) can represent a very large value (e.g., 1.23×10^88 ) or a very small value (e.g., 1.23×10^-88 ). It could also represent very large negative number (e.g., -1.23×10^88 ) and very small negative number (e.g., -1.23×10^-88 ), as well as zero, as illustrated:

A floating-point number is typically expressed in the scientific notation, with a fraction ( F ), and an exponent ( E ) of a certain radix ( r ), in the form of F×r^E . Decimal numbers use radix of 10 ( F×10^E ); while binary numbers use radix of 2 ( F×2^E ).
Representation of floating point number is not unique. For example, the number 55.66 can be represented as 5.566×10^1 , 0.5566×10^2 , 0.05566×10^3 , and so on. The fractional part can be normalized . In the normalized form, there is only a single non-zero digit before the radix point. For example, decimal number 123.4567 can be normalized as 1.234567×10^2 ; binary number 1010.1011B can be normalized as 1.0101011B×2^3 .
It is important to note that floating-point numbers suffer from loss of precision when represented with a fixed number of bits (e.g., 32-bit or 64-bit). This is because there are infinite number of real numbers (even within a small range of says 0.0 to 0.1). On the other hand, a n -bit binary pattern can represent a finite 2^ n distinct numbers. Hence, not all the real numbers can be represented. The nearest approximation will be used instead, resulted in loss of accuracy.
It is also important to note that floating number arithmetic is very much less efficient than integer arithmetic. It could be speed up with a so-called dedicated floating-point co-processor . Hence, use integers if your application does not require floating-point numbers.
In computers, floating-point numbers are represented in scientific notation of fraction ( F ) and exponent ( E ) with a radix of 2, in the form of F×2^E . Both E and F can be positive as well as negative. Modern computers adopt IEEE 754 standard for representing floating-point numbers. There are two representation schemes: 32-bit single-precision and 64-bit double-precision.
IEEE-754 32-bit Single-Precision Floating-Point Numbers
In 32-bit single-precision floating-point representation:
- The most significant bit is the sign bit ( S ), with 0 for positive numbers and 1 for negative numbers.
- The following 8 bits represent exponent ( E ).
- The remaining 23 bits represents fraction ( F ).

Normalized Form
Let's illustrate with an example, suppose that the 32-bit pattern is 1 1000 0001 011 0000 0000 0000 0000 0000 , with:
- E = 1000 0001
- F = 011 0000 0000 0000 0000 0000
In the normalized form , the actual fraction is normalized with an implicit leading 1 in the form of 1.F . In this example, the actual fraction is 1.011 0000 0000 0000 0000 0000 = 1 + 1×2^-2 + 1×2^-3 = 1.375D .
The sign bit represents the sign of the number, with S=0 for positive and S=1 for negative number. In this example with S=1 , this is a negative number, i.e., -1.375D .
In normalized form, the actual exponent is E-127 (so-called excess-127 or bias-127). This is because we need to represent both positive and negative exponent. With an 8-bit E, ranging from 0 to 255, the excess-127 scheme could provide actual exponent of -127 to 128. In this example, E-127=129-127=2D .
Hence, the number represented is -1.375×2^2=-5.5D .
De-Normalized Form
Normalized form has a serious problem, with an implicit leading 1 for the fraction, it cannot represent the number zero! Convince yourself on this!
De-normalized form was devised to represent zero and other numbers.
For E=0 , the numbers are in the de-normalized form. An implicit leading 0 (instead of 1) is used for the fraction; and the actual exponent is always -126 . Hence, the number zero can be represented with E=0 and F=0 (because 0.0×2^-126=0 ).
We can also represent very small positive and negative numbers in de-normalized form with E=0 . For example, if S=1 , E=0 , and F=011 0000 0000 0000 0000 0000 . The actual fraction is 0.011=1×2^-2+1×2^-3=0.375D . Since S=1 , it is a negative number. With E=0 , the actual exponent is -126 . Hence the number is -0.375×2^-126 = -4.4×10^-39 , which is an extremely small negative number (close to zero).
In summary, the value ( N ) is calculated as follows:
- For 1 ≤ E ≤ 254, N = (-1)^S × 1.F × 2^(E-127) . These numbers are in the so-called normalized form. The sign-bit represents the sign of the number. Fractional part ( 1.F ) are normalized with an implicit leading 1. The exponent is bias (or in excess) of 127 , so as to represent both positive and negative exponent. The range of exponent is -126 to +127 .
- For E = 0, N = (-1)^S × 0.F × 2^(-126) . These numbers are in the so-called denormalized form. The exponent of 2^-126 evaluates to a very small number. Denormalized form is needed to represent zero (with F=0 and E=0 ). It can also represents very small positive and negative number close to zero.
- For E = 255 , it represents special values, such as ±INF (positive and negative infinity) and NaN (not a number). This is beyond the scope of this article.
Example 1: Suppose that IEEE-754 32-bit floating-point representation pattern is 0 10000000 110 0000 0000 0000 0000 0000 .
Example 2: Suppose that IEEE-754 32-bit floating-point representation pattern is 1 01111110 100 0000 0000 0000 0000 0000 .
Example 3: Suppose that IEEE-754 32-bit floating-point representation pattern is 1 01111110 000 0000 0000 0000 0000 0001 .
Example 4 (De-Normalized Form): Suppose that IEEE-754 32-bit floating-point representation pattern is 1 00000000 000 0000 0000 0000 0000 0001 .
Exercises (Floating-point Numbers)
- Compute the largest and smallest positive numbers that can be represented in the 32-bit normalized form.
- Compute the largest and smallest negative numbers can be represented in the 32-bit normalized form.
- Repeat (1) for the 32-bit denormalized form.
- Repeat (2) for the 32-bit denormalized form.
- Largest positive number: S=0 , E=1111 1110 (254) , F=111 1111 1111 1111 1111 1111 . Smallest positive number: S=0 , E=0000 00001 (1) , F=000 0000 0000 0000 0000 0000 .
- Same as above, but S=1 .
- Largest positive number: S=0 , E=0 , F=111 1111 1111 1111 1111 1111 . Smallest positive number: S=0 , E=0 , F=000 0000 0000 0000 0000 0001 .
Notes For Java Users
You can use JDK methods Float.intBitsToFloat(int bits) or Double.longBitsToDouble(long bits) to create a single-precision 32-bit float or double-precision 64-bit double with the specific bit patterns, and print their values. For examples,
IEEE-754 64-bit Double-Precision Floating-Point Numbers
The representation scheme for 64-bit double-precision is similar to the 32-bit single-precision:
- The following 11 bits represent exponent ( E ).
- The remaining 52 bits represents fraction ( F ).

The value ( N ) is calculated as follows:
- Normalized form: For 1 ≤ E ≤ 2046, N = (-1)^S × 1.F × 2^(E-1023) .
- Denormalized form: For E = 0, N = (-1)^S × 0.F × 2^(-1022) . These are in the denormalized form.
- For E = 2047 , N represents special values, such as ±INF (infinity), NaN (not a number).
More on Floating-Point Representation
There are three parts in the floating-point representation:
- The sign bit ( S ) is self-explanatory (0 for positive numbers and 1 for negative numbers).
- For the exponent ( E ), a so-called bias (or excess ) is applied so as to represent both positive and negative exponent. The bias is set at half of the range. For single precision with an 8-bit exponent, the bias is 127 (or excess-127). For double precision with a 11-bit exponent, the bias is 1023 (or excess-1023).
- The fraction ( F ) (also called the mantissa or significand ) is composed of an implicit leading bit (before the radix point) and the fractional bits (after the radix point). The leading bit for normalized numbers is 1; while the leading bit for denormalized numbers is 0.
Normalized Floating-Point Numbers
In normalized form, the radix point is placed after the first non-zero digit, e,g., 9.8765D×10^-23D , 1.001011B×2^11B . For binary number, the leading bit is always 1, and need not be represented explicitly - this saves 1 bit of storage.
In IEEE 754's normalized form:
- For single-precision, 1 ≤ E ≤ 254 with excess of 127. Hence, the actual exponent is from -126 to +127 . Negative exponents are used to represent small numbers (< 1.0); while positive exponents are used to represent large numbers (> 1.0). N = (-1)^S × 1.F × 2^(E-127)
- For double-precision, 1 ≤ E ≤ 2046 with excess of 1023. The actual exponent is from -1022 to +1023 , and N = (-1)^S × 1.F × 2^(E-1023)
Take note that n-bit pattern has a finite number of combinations ( =2^n ), which could represent finite distinct numbers. It is not possible to represent the infinite numbers in the real axis (even a small range says 0.0 to 1.0 has infinite numbers). That is, not all floating-point numbers can be accurately represented. Instead, the closest approximation is used, which leads to loss of accuracy .
The minimum and maximum normalized floating-point numbers are:
| Precision | Normalized N(min) | Normalized N(max) |
|---|---|---|
| Single | 0080 0000H 0 00000001 00000000000000000000000B E = 1, F = 0 N(min) = 1.0B × 2^-126 (≈1.17549435 × 10^-38) | 7F7F FFFFH 0 11111110 00000000000000000000000B E = 254, F = 0 N(max) = 1.1...1B × 2^127 = (2 - 2^-23) × 2^127 (≈3.4028235 × 10^38) |
| Double | 0010 0000 0000 0000H N(min) = 1.0B × 2^-1022 (≈2.2250738585072014 × 10^-308) | 7FEF FFFF FFFF FFFFH N(max) = 1.1...1B × 2^1023 = (2 - 2^-52) × 2^1023 (≈1.7976931348623157 × 10^308) |

Denormalized Floating-Point Numbers
If E = 0 , but the fraction is non-zero, then the value is in denormalized form, and a leading bit of 0 is assumed, as follows:
- For single-precision, E = 0 , N = (-1)^S × 0.F × 2^(-126)
- For double-precision, E = 0 , N = (-1)^S × 0.F × 2^(-1022)
Denormalized form can represent very small numbers closed to zero, and zero, which cannot be represented in normalized form, as shown in the above figure.
The minimum and maximum of denormalized floating-point numbers are:
| Precision | Denormalized D(min) | Denormalized D(max) |
|---|---|---|
| Single | 0000 0001H 0 00000000 00000000000000000000001B E = 0, F = 00000000000000000000001B D(min) = 0.0...1 × 2^-126 = 1 × 2^-23 × 2^-126 = 2^-149 (≈1.4 × 10^-45) | 007F FFFFH 0 00000000 11111111111111111111111B E = 0, F = 11111111111111111111111B D(max) = 0.1...1 × 2^-126 = (1-2^-23)×2^-126 (≈1.1754942 × 10^-38) |
| Double | 0000 0000 0000 0001H D(min) = 0.0...1 × 2^-1022 = 1 × 2^-52 × 2^-1022 = 2^-1074 (≈4.9 × 10^-324) | 001F FFFF FFFF FFFFH D(max) = 0.1...1 × 2^-1022 = (1-2^-52)×2^-1022 (≈4.4501477170144023 × 10^-308) |
Special Values
Zero : Zero cannot be represented in the normalized form, and must be represented in denormalized form with E=0 and F=0 . There are two representations for zero: +0 with S=0 and -0 with S=1 .
Infinity : The value of +infinity (e.g., 1/0 ) and -infinity (e.g., -1/0 ) are represented with an exponent of all 1's ( E = 255 for single-precision and E = 2047 for double-precision), F=0 , and S=0 (for +INF ) and S=1 (for -INF ).
Not a Number (NaN) : NaN denotes a value that cannot be represented as real number (e.g. 0/0 ). NaN is represented with Exponent of all 1's ( E = 255 for single-precision and E = 2047 for double-precision) and any non-zero fraction.
Character Encoding
In computer memory, character are "encoded" (or "represented") using a chosen "character encoding schemes" (aka "character set", "charset", "character map", or "code page").
For example, in ASCII (as well as Latin1, Unicode, and many other character sets):
- code numbers 65D (41H) to 90D (5AH) represents 'A' to 'Z' , respectively.
- code numbers 97D (61H) to 122D (7AH) represents 'a' to 'z' , respectively.
- code numbers 48D (30H) to 57D (39H) represents '0' to '9' , respectively.
It is important to note that the representation scheme must be known before a binary pattern can be interpreted. E.g., the 8-bit pattern " 0100 0010B " could represent anything under the sun known only to the person encoded it.
The most commonly-used character encoding schemes are: 7-bit ASCII (ISO/IEC 646) and 8-bit Latin-x (ISO/IEC 8859-x) for western european characters, and Unicode (ISO/IEC 10646) for internationalization (i18n).
A 7-bit encoding scheme (such as ASCII) can represent 128 characters and symbols. An 8-bit character encoding scheme (such as Latin-x) can represent 256 characters and symbols; whereas a 16-bit encoding scheme (such as Unicode UCS-2) can represents 65,536 characters and symbols.
7-bit ASCII Code (aka US-ASCII, ISO/IEC 646, ITU-T T.50)
- ASCII (American Standard Code for Information Interchange) is one of the earlier character coding schemes.
- ASCII is originally a 7-bit code. It has been extended to 8-bit to better utilize the 8-bit computer memory organization. (The 8th-bit was originally used for parity check in the early computers.)
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ |
| Dec | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | SP | ! | " | # | $ | % | & | ' | ||
| 4 | ( | ) | * | + | , | - | . | / | 0 | 1 |
| 5 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; |
| 6 | < | = | > | ? | @ | A | B | C | D | E |
| 7 | F | G | H | I | J | K | L | M | N | O |
| 8 | P | Q | R | S | T | U | V | W | X | Y |
| 9 | Z | [ | \ | ] | ^ | _ | ` | a | b | c |
| 10 | d | e | f | g | h | i | j | k | l | m |
| 11 | n | o | p | q | r | s | t | u | v | w |
| 12 | x | y | z | { | | | } | ~ |
- Code number 32D (20H) is the blank or space character.
- '0' to '9' : 30H-39H (0011 0001B to 0011 1001B) or (0011 xxxxB where xxxx is the equivalent integer value )
- 'A' to 'Z' : 41H-5AH (0101 0001B to 0101 1010B) or (010x xxxxB) . 'A' to 'Z' are continuous without gap.
- 'a' to 'z' : 61H-7AH (0110 0001B to 0111 1010B) or (011x xxxxB) . 'A' to 'Z' are also continuous without gap. However, there is a gap between uppercase and lowercase letters. To convert between upper and lowercase, flip the value of bit-5.
- 09H for Tab ( '\t' ).
- 0AH for Line-Feed or newline (LF or '\n' ) and 0DH for Carriage-Return (CR or 'r' ), which are used as line delimiter (aka line separator , end-of-line ) for text files. There is unfortunately no standard for line delimiter: Unixes and Mac use 0AH (LF or " \n "), Windows use 0D0AH (CR+LF or " \r\n "). Programming languages such as C/C++/Java (which was created on Unix) use 0AH (LF or " \n ").
- In programming languages such as C/C++/Java, line-feed ( 0AH ) is denoted as '\n' , carriage-return ( 0DH ) as '\r' , tab ( 09H ) as '\t' .
| DEC | HEX | Meaning | DEC | HEX | Meaning | ||
|---|---|---|---|---|---|---|---|
| 0 | 00 | NUL | Null | 17 | 11 | DC1 | Device Control 1 |
| 1 | 01 | SOH | Start of Heading | 18 | 12 | DC2 | Device Control 2 |
| 2 | 02 | STX | Start of Text | 19 | 13 | DC3 | Device Control 3 |
| 3 | 03 | ETX | End of Text | 20 | 14 | DC4 | Device Control 4 |
| 4 | 04 | EOT | End of Transmission | 21 | 15 | NAK | Negative Ack. |
| 5 | 05 | ENQ | Enquiry | 22 | 16 | SYN | Sync. Idle |
| 6 | 06 | ACK | Acknowledgment | 23 | 17 | ETB | End of Transmission |
| 7 | 07 | BEL | Bell | 24 | 18 | CAN | Cancel |
| 8 | 08 | BS | Back Space | 25 | 19 | EM | End of Medium |
| 26 | 1A | SUB | Substitute | ||||
| 27 | 1B | ESC | Escape | ||||
| 11 | 0B | VT | Vertical Feed | 28 | 1C | IS4 | File Separator |
| 12 | 0C | FF | Form Feed | 29 | 1D | IS3 | Group Separator |
| 30 | 1E | IS2 | Record Separator | ||||
| 14 | 0E | SO | Shift Out | 31 | 1F | IS1 | Unit Separator |
| 15 | 0F | SI | Shift In | ||||
| 16 | 10 | DLE | Datalink Escape | 127 | 7F | DEL | Delete |
8-bit Latin-1 (aka ISO/IEC 8859-1)
ISO/IEC-8859 is a collection of 8-bit character encoding standards for the western languages.
ISO/IEC 8859-1, aka Latin alphabet No. 1, or Latin-1 in short, is the most commonly-used encoding scheme for western european languages. It has 191 printable characters from the latin script, which covers languages like English, German, Italian, Portuguese and Spanish. Latin-1 is backward compatible with the 7-bit US-ASCII code. That is, the first 128 characters in Latin-1 (code numbers 0 to 127 (7FH)), is the same as US-ASCII. Code numbers 128 (80H) to 159 (9FH) are not assigned. Code numbers 160 (A0H) to 255 (FFH) are given as follows:
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | NBSP | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | SHY | ® | ¯ |
| B | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| C | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| D | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| E | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| F | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
ISO/IEC-8859 has 16 parts. Besides the most commonly-used Part 1, Part 2 is meant for Central European (Polish, Czech, Hungarian, etc), Part 3 for South European (Turkish, etc), Part 4 for North European (Estonian, Latvian, etc), Part 5 for Cyrillic, Part 6 for Arabic, Part 7 for Greek, Part 8 for Hebrew, Part 9 for Turkish, Part 10 for Nordic, Part 11 for Thai, Part 12 was abandon, Part 13 for Baltic Rim, Part 14 for Celtic, Part 15 for French, Finnish, etc. Part 16 for South-Eastern European.
Other 8-bit Extension of US-ASCII (ASCII Extensions)
Beside the standardized ISO-8859-x, there are many 8-bit ASCII extensions, which are not compatible with each others.
ANSI (American National Standards Institute) (aka Windows-1252 , or Windows Codepage 1252): for Latin alphabets used in the legacy DOS/Windows systems. It is a superset of ISO-8859-1 with code numbers 128 (80H) to 159 (9FH) assigned to displayable characters, such as "smart" single-quotes and double-quotes. A common problem in web browsers is that all the quotes and apostrophes (produced by "smart quotes" in some Microsoft software) were replaced with question marks or some strange symbols. It it because the document is labeled as ISO-8859-1 (instead of Windows-1252), where these code numbers are undefined. Most modern browsers and e-mail clients treat charset ISO-8859-1 as Windows-1252 in order to accommodate such mis-labeling.
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | € | ‚ | ƒ | „ | … | † | ‡ | ˆ | ‰ | Š | ‹ | Œ | Ž | |||
| 9 | ‘ | ’ | “ | ” | • | – | — | ™ | š | › | œ | ž | Ÿ |
EBCDIC (Extended Binary Coded Decimal Interchange Code): Used in the early IBM computers.
Unicode (aka ISO/IEC 10646 Universal Character Set)
Before Unicode, no single character encoding scheme could represent characters in all languages. For example, western european uses several encoding schemes (in the ISO-8859-x family). Even a single language like Chinese has a few encoding schemes (GB2312/GBK, BIG5). Many encoding schemes are in conflict of each other, i.e., the same code number is assigned to different characters.
Unicode aims to provide a standard character encoding scheme, which is universal, efficient, uniform and unambiguous. Unicode standard is maintained by a non-profit organization called the Unicode Consortium (@ www.unicode.org ). Unicode is an ISO/IEC standard 10646.
Unicode is backward compatible with the 7-bit US-ASCII and 8-bit Latin-1 (ISO-8859-1). That is, the first 128 characters are the same as US-ASCII; and the first 256 characters are the same as Latin-1.
Unicode originally uses 16 bits (called UCS-2 or Unicode Character Set - 2 byte), which can represent up to 65,536 characters. It has since been expanded to more than 16 bits, currently stands at 21 bits. The range of the legal codes in ISO/IEC 10646 is now from U+0000H to U+10FFFFH (21 bits or about 2 million characters), covering all current and ancient historical scripts. The original 16-bit range of U+0000H to U+FFFFH (65536 characters) is known as Basic Multilingual Plane (BMP), covering all the major languages in use currently. The characters outside BMP are called Supplementary Characters , which are not frequently-used.
Unicode has two encoding schemes:
- UCS-2 (Universal Character Set - 2 Byte): Uses 2 bytes (16 bits), covering 65,536 characters in the BMP. BMP is sufficient for most of the applications. UCS-2 is now obsolete.
- UCS-4 (Universal Character Set - 4 Byte): Uses 4 bytes (32 bits), covering BMP and the supplementary characters.

UTF-8 (Unicode Transformation Format - 8-bit)
The 16/32-bit Unicode (UCS-2/4) is grossly inefficient if the document contains mainly ASCII characters, because each character occupies two bytes of storage. Variable-length encoding schemes, such as UTF-8, which uses 1-4 bytes to represent a character, was devised to improve the efficiency. In UTF-8, the 128 commonly-used US-ASCII characters use only 1 byte, but some less-commonly characters may require up to 4 bytes. Overall, the efficiency improved for document containing mainly US-ASCII texts.
The transformation between Unicode and UTF-8 is as follows:
| Bits | Unicode | UTF-8 Code | Bytes |
|---|---|---|---|
| 7 | 00000000 0xxxxxxx | 0xxxxxxx | 1 (ASCII) |
| 11 | 00000yyy yyxxxxxx | 110yyyyy 10xxxxxx | 2 |
| 16 | zzzzyyyy yyxxxxxx | 1110zzzz 10yyyyyy 10xxxxxx | 3 |
| 21 | 000uuuuu zzzzyyyy yyxxxxxx | 11110uuu 10uuzzzz 10yyyyyy 10xxxxxx | 4 |
In UTF-8, Unicode numbers corresponding to the 7-bit ASCII characters are padded with a leading zero; thus has the same value as ASCII. Hence, UTF-8 can be used with all software using ASCII. Unicode numbers of 128 and above, which are less frequently used, are encoded using more bytes (2-4 bytes). UTF-8 generally requires less storage and is compatible with ASCII. The drawback of UTF-8 is more processing power needed to unpack the code due to its variable length. UTF-8 is the most popular format for Unicode.
- UTF-8 uses 1-3 bytes for the characters in BMP (16-bit), and 4 bytes for supplementary characters outside BMP (21-bit).
- The 128 ASCII characters (basic Latin letters, digits, and punctuation signs) use one byte. Most European and Middle East characters use a 2-byte sequence, which includes extended Latin letters (with tilde, macron, acute, grave and other accents), Greek, Armenian, Hebrew, Arabic, and others. Chinese, Japanese and Korean (CJK) use three-byte sequences.
- All the bytes, except the 128 ASCII characters, have a leading '1' bit. In other words, the ASCII bytes, with a leading '0' bit, can be identified and decoded easily.
Example : 您好 (Unicode: 60A8H 597DH)
UTF-16 (Unicode Transformation Format - 16-bit)
UTF-16 is a variable-length Unicode character encoding scheme, which uses 2 to 4 bytes. UTF-16 is not commonly used. The transformation table is as follows:
| Unicode | UTF-16 Code | Bytes |
|---|---|---|
| xxxxxxxx xxxxxxxx | Same as UCS-2 - no encoding | 2 |
| 000uuuuu zzzzyyyy yyxxxxxx (uuuuu≠0) | 110110ww wwzzzzyy 110111yy yyxxxxxx (wwww = uuuuu - 1) | 4 |
Take note that for the 65536 characters in BMP, the UTF-16 is the same as UCS-2 (2 bytes). However, 4 bytes are used for the supplementary characters outside the BMP.
For BMP characters, UTF-16 is the same as UCS-2. For supplementary characters, each character requires a pair 16-bit values, the first from the high-surrogates range, ( \uD800-\uDBFF ), the second from the low-surrogates range ( \uDC00-\uDFFF ).
UTF-32 (Unicode Transformation Format - 32-bit)
Same as UCS-4, which uses 4 bytes for each character - unencoded.
Formats of Multi-Byte (e.g., Unicode) Text Files
Endianess (or byte-order) : For a multi-byte character, you need to take care of the order of the bytes in storage. In big endian , the most significant byte is stored at the memory location with the lowest address (big byte first). In little endian , the most significant byte is stored at the memory location with the highest address (little byte first). For example, 您 (with Unicode number of 60A8H ) is stored as 60 A8 in big endian; and stored as A8 60 in little endian. Big endian, which produces a more readable hex dump, is more commonly-used, and is often the default.
BOM (Byte Order Mark) : BOM is a special Unicode character having code number of FEFFH , which is used to differentiate big-endian and little-endian. For big-endian, BOM appears as FE FFH in the storage. For little-endian, BOM appears as FF FEH . Unicode reserves these two code numbers to prevent it from crashing with another character.
Unicode text files could take on these formats:
- Big Endian: UCS-2BE, UTF-16BE, UTF-32BE.
- Little Endian: UCS-2LE, UTF-16LE, UTF-32LE.
- UTF-16 with BOM. The first character of the file is a BOM character, which specifies the endianess. For big-endian, BOM appears as FE FFH in the storage. For little-endian, BOM appears as FF FEH .
UTF-8 file is always stored as big endian. BOM plays no part. However, in some systems (in particular Windows), a BOM is added as the first character in the UTF-8 file as the signature to identity the file as UTF-8 encoded. The BOM character ( FEFFH ) is encoded in UTF-8 as EF BB BF . Adding a BOM as the first character of the file is not recommended, as it may be incorrectly interpreted in other system. You can have a UTF-8 file without BOM.
Formats of Text Files
Line Delimiter or End-Of-Line (EOL) : Sometimes, when you use the Windows NotePad to open a text file (created in Unix or Mac), all the lines are joined together. This is because different operating platforms use different character as the so-called line delimiter (or end-of-line or EOL). Two non-printable control characters are involved: 0AH (Line-Feed or LF) and 0DH (Carriage-Return or CR).
- Windows/DOS uses OD0AH (CR+LF or " \r\n ") as EOL.
- Unix and Mac use 0AH (LF or " \n ") only.
End-of-File (EOF) : [TODO]
Windows' CMD Codepage
Character encoding scheme (charset) in Windows is called codepage . In CMD shell, you can issue command "chcp" to display the current codepage, or "chcp codepage-number" to change the codepage.
Take note that:
- The default codepage 437 (used in the original DOS) is an 8-bit character set called Extended ASCII , which is different from Latin-1 for code numbers above 127.
- Codepage 1252 (Windows-1252), is not exactly the same as Latin-1. It assigns code number 80H to 9FH to letters and punctuation, such as smart single-quotes and double-quotes. A common problem in browser that display quotes and apostrophe in question marks or boxes is because the page is supposed to be Windows-1252, but mislabelled as ISO-8859-1.
- For internationalization and chinese character set: codepage 65001 for UTF8, codepage 1201 for UCS-2BE, codepage 1200 for UCS-2LE, codepage 936 for chinese characters in GB2312, codepage 950 for chinese characters in Big5.
Chinese Character Sets
Unicode supports all languages, including asian languages like Chinese (both simplified and traditional characters), Japanese and Korean (collectively called CJK). There are more than 20,000 CJK characters in Unicode. Unicode characters are often encoded in the UTF-8 scheme, which unfortunately, requires 3 bytes for each CJK character, instead of 2 bytes in the unencoded UCS-2 (UTF-16).
Worse still, there are also various chinese character sets, which is not compatible with Unicode:
- GB2312/GBK: for simplified chinese characters. GB2312 uses 2 bytes for each chinese character. The most significant bit (MSB) of both bytes are set to 1 to co-exist with 7-bit ASCII with the MSB of 0. There are about 6700 characters. GBK is an extension of GB2312, which include more characters as well as traditional chinese characters.
- BIG5: for traditional chinese characters BIG5 also uses 2 bytes for each chinese character. The most significant bit of both bytes are also set to 1. BIG5 is not compatible with GBK, i.e., the same code number is assigned to different character.
For example, the world is made more interesting with these many standards:
| Standard | Characters | Codes | |
|---|---|---|---|
| Simplified | GB2312 | 和谐 | BACD D0B3 |
| UCS-2 | 和谐 | 548C 8C10 | |
| UTF-8 | 和谐 | E5928C E8B090 | |
| Traditional | BIG5 | 和諧 | A94D BFD3 |
| UCS-2 | 和諧 | 548C 8AE7 | |
| UTF-8 | 和諧 | E5928C E8ABA7 |
Notes for Windows' CMD Users : To display the chinese character correctly in CMD shell, you need to choose the correct codepage, e.g., 65001 for UTF8, 936 for GB2312/GBK, 950 for Big5, 1201 for UCS-2BE, 1200 for UCS-2LE, 437 for the original DOS. You can use command " chcp " to display the current code page and command " chcp codepage_number " to change the codepage. You also have to choose a font that can display the characters (e.g., Courier New, Consolas or Lucida Console, NOT Raster font).
Collating Sequences (for Ranking Characters)
A string consists of a sequence of characters in upper or lower cases, e.g., "apple" , "BOY" , "Cat" . In sorting or comparing strings, if we order the characters according to the underlying code numbers (e.g., US-ASCII) character-by-character, the order for the example would be "BOY" , "apple" , "Cat" because uppercase letters have a smaller code number than lowercase letters. This does not agree with the so-called dictionary order , where the same uppercase and lowercase letters have the same rank. Another common problem in ordering strings is "10" (ten) at times is ordered in front of "1" to "9" .
Hence, in sorting or comparison of strings, a so-called collating sequence (or collation ) is often defined, which specifies the ranks for letters (uppercase, lowercase), numbers, and special symbols. There are many collating sequences available. It is entirely up to you to choose a collating sequence to meet your application's specific requirements. Some case-insensitive dictionary-order collating sequences have the same rank for same uppercase and lowercase letters, i.e., 'A' , 'a' ⇒ 'B' , 'b' ⇒ ... ⇒ 'Z' , 'z' . Some case-sensitive dictionary-order collating sequences put the uppercase letter before its lowercase counterpart, i.e., 'A' ⇒ 'B' ⇒ 'C' ... ⇒ 'a' ⇒ 'b' ⇒ 'c' ... . Typically, space is ranked before digits '0' to '9' , followed by the alphabets.
Collating sequence is often language dependent, as different languages use different sets of characters (e.g., á, é, a, α) with their own orders.
For Java Programmers - java.nio.Charset
JDK 1.4 introduced a new java.nio.charset package to support encoding/decoding of characters from UCS-2 used internally in Java program to any supported charset used by external devices.
Example : The following program encodes some Unicode texts in various encoding scheme, and display the Hex codes of the encoded byte sequences.
For Java Programmers - char and String
The char data type are based on the original 16-bit Unicode standard called UCS-2. The Unicode has since evolved to 21 bits, with code range of U+0000 to U+10FFFF. The set of characters from U+0000 to U+FFFF is known as the Basic Multilingual Plane ( BMP ). Characters above U+FFFF are called supplementary characters. A 16-bit Java char cannot hold a supplementary character.
Recall that in the UTF-16 encoding scheme, a BMP characters uses 2 bytes. It is the same as UCS-2. A supplementary character uses 4 bytes. and requires a pair of 16-bit values, the first from the high-surrogates range, ( \uD800-\uDBFF ), the second from the low-surrogates range ( \uDC00-\uDFFF ).
In Java, a String is a sequences of Unicode characters. Java, in fact, uses UTF-16 for String and StringBuffer . For BMP characters, they are the same as UCS-2. For supplementary characters, each characters requires a pair of char values.
Java methods that accept a 16-bit char value does not support supplementary characters. Methods that accept a 32-bit int value support all Unicode characters (in the lower 21 bits), including supplementary characters.
This is meant to be an academic discussion. I have yet to encounter the use of supplementary characters!
Displaying Hex Values & Hex Editors
At times, you may need to display the hex values of a file, especially in dealing with Unicode characters. A Hex Editor is a handy tool that a good programmer should possess in his/her toolbox. There are many freeware/shareware Hex Editor available. Try google "Hex Editor".
I used the followings:
- NotePad++ with Hex Editor Plug-in: Open-source and free. You can toggle between Hex view and Normal view by pushing the "H" button.
- PSPad: Freeware. You can toggle to Hex view by choosing "View" menu and select "Hex Edit Mode".
- TextPad: Shareware without expiration period. To view the Hex value, you need to "open" the file by choosing the file format of "binary" (??).
- UltraEdit: Shareware, not free, 30-day trial only.
Let me know if you have a better choice, which is fast to launch, easy to use, can toggle between Hex and normal view, free, ....
The following Java program can be used to display hex code for Java Primitives (integer, character and floating-point):
| System.out.println("Hex is " + Integer.toHexString(i)); // 3039 System.out.println("Binary is " + Integer.toBinaryString(i)); // 11000000111001 System.out.println("Octal is " + Integer.toOctalString(i)); // 30071 System.out.printf("Hex is %x\n", i); // 3039 System.out.printf("Octal is %o\n", i); // 30071 char c = 'a'; System.out.println("Character is " + c); // a System.out.printf("Character is %c\n", c); // a System.out.printf("Hex is %x\n", (short)c); // 61 System.out.printf("Decimal is %d\n", (short)c); // 97 float f = 3.5f; System.out.println("Decimal is " + f); // 3.5 System.out.println(Float.toHexString(f)); // 0x1.cp1 (Fraction=1.c, Exponent=1) f = -0.75f; System.out.println("Decimal is " + f); // -0.75 System.out.println(Float.toHexString(f)); // -0x1.8p-1 (F=-1.8, E=-1) double d = 11.22; System.out.println("Decimal is " + d); // 11.22 System.out.println(Double.toHexString(d)); // 0x1.670a3d70a3d71p3 (F=1.670a3d70a3d71 E=3) } } |
In Eclipse, you can view the hex code for integer primitive Java variables in debug mode as follows: In debug perspective, "Variable" panel ⇒ Select the "menu" (inverted triangle) ⇒ Java ⇒ Java Preferences... ⇒ Primitive Display Options ⇒ Check "Display hexadecimal values (byte, short, char, int, long)".
Summary - Why Bother about Data Representation?
Integer number 1 , floating-point number 1.0 character symbol '1' , and string "1" are totally different inside the computer memory. You need to know the difference to write good and high-performance programs.
- In 8-bit signed integer , integer number 1 is represented as 00000001B .
- In 8-bit unsigned integer , integer number 1 is represented as 00000001B .
- In 16-bit signed integer , integer number 1 is represented as 00000000 00000001B .
- In 32-bit signed integer , integer number 1 is represented as 00000000 00000000 00000000 00000001B .
- In 32-bit floating-point representation , number 1.0 is represented as 0 01111111 0000000 00000000 00000000B , i.e., S=0 , E=127 , F=0 .
- In 64-bit floating-point representation , number 1.0 is represented as 0 01111111111 0000 00000000 00000000 00000000 00000000 00000000 00000000B , i.e., S=0 , E=1023 , F=0 .
- In 8-bit Latin-1, the character symbol '1' is represented as 00110001B (or 31H ).
- In 16-bit UCS-2, the character symbol '1' is represented as 00000000 00110001B .
- In UTF-8, the character symbol '1' is represented as 00110001B .
If you "add" a 16-bit signed integer 1 and Latin-1 character '1' or a string "1", you could get a surprise.
Exercises (Data Representation)
For the following 16-bit codes:
Give their values, if they are representing:
- a 16-bit unsigned integer;
- a 16-bit signed integer;
- two 8-bit unsigned integers;
- two 8-bit signed integers;
- a 16-bit Unicode characters;
- two 8-bit ISO-8859-1 characters.
Ans: (1) 42 , 32810 ; (2) 42 , -32726 ; (3) 0 , 42 ; 128 , 42 ; (4) 0 , 42 ; -128 , 42 ; (5) '*' ; '耪' ; (6) NUL , '*' ; PAD , '*' .
REFERENCES & RESOURCES
- (Floating-Point Number Specification) IEEE 754 (1985), "IEEE Standard for Binary Floating-Point Arithmetic".
- (ASCII Specification) ISO/IEC 646 (1991) (or ITU-T T.50-1992), "Information technology - 7-bit coded character set for information interchange".
- (Latin-I Specification) ISO/IEC 8859-1, "Information technology - 8-bit single-byte coded graphic character sets - Part 1: Latin alphabet No. 1".
- (Unicode Specification) ISO/IEC 10646, "Information technology - Universal Multiple-Octet Coded Character Set (UCS)".
- Unicode Consortium @ http://www.unicode.org .
Last modified: January, 2014
Page Statistics
| Page Metric | # |
|---|---|
| Views | 0 |
| Avg. time spent | 0 s |
Table Of Contents
- Introduction to Functional Computer
- Fundamentals of Architectural Design
Data Representation
- Instruction Set Architecture : Instructions and Formats
- Instruction Set Architecture : Design Models
- Instruction Set Architecture : Addressing Modes
- Performance Measurements and Issues
- Computer Architecture Assessment 1
- Fixed Point Arithmetic : Addition and Subtraction
- Fixed Point Arithmetic : Multiplication
- Fixed Point Arithmetic : Division
- Floating Point Arithmetic
- Arithmetic Logic Unit Design
- CPU's Data Path
- CPU's Control Unit
- Control Unit Design
- Concepts of Pipelining
- Computer Architecture Assessment 2
- Pipeline Hazards
- Memory Characteristics and Organization
- Cache Memory
- Virtual Memory
- I/O Communication and I/O Controller
- Input/Output Data Transfer
- Direct Memory Access controller and I/O Processor
- CPU Interrupts and Interrupt Handling
- Computer Architecture Assessment 3
Course Computer Architecture
Digital computers store and process information in binary form as digital logic has only two values "1" and "0" or in other words "True or False" or also said as "ON or OFF". This system is called radix 2. We human generally deal with radix 10 i.e. decimal. As a matter of convenience there are many other representations like Octal (Radix 8), Hexadecimal (Radix 16), Binary coded decimal (BCD), Decimal etc.
Every computer's CPU has a width measured in terms of bits such as 8 bit CPU, 16 bit CPU, 32 bit CPU etc. Similarly, each memory location can store a fixed number of bits and is called memory width. Given the size of the CPU and Memory, it is for the programmer to handle his data representation. Most of the readers may be knowing that 4 bits form a Nibble, 8 bits form a byte. The word length is defined by the Instruction Set Architecture of the CPU. The word length may be equal to the width of the CPU.
The memory simply stores information as a binary pattern of 1's and 0's. It is to be interpreted as what the content of a memory location means. If the CPU is in the Fetch cycle, it interprets the fetched memory content to be instruction and decodes based on Instruction format. In the Execute cycle, the information from memory is considered as data. As a common man using a computer, we think computers handle English or other alphabets, special characters or numbers. A programmer considers memory content to be data types of the programming language he uses. Now recall figure 1.2 and 1.3 of chapter 1 to reinforce your thought that conversion happens from computer user interface to internal representation and storage.
- Data Representation in Computers
Information handled by a computer is classified as instruction and data. A broad overview of the internal representation of the information is illustrated in figure 3.1. No matter whether it is data in a numeric or non-numeric form or integer, everything is internally represented in Binary. It is up to the programmer to handle the interpretation of the binary pattern and this interpretation is called Data Representation . These data representation schemes are all standardized by international organizations.
Choice of Data representation to be used in a computer is decided by
- The number types to be represented (integer, real, signed, unsigned, etc.)
- Range of values likely to be represented (maximum and minimum to be represented)
- The Precision of the numbers i.e. maximum accuracy of representation (floating point single precision, double precision etc)
- If non-numeric i.e. character, character representation standard to be chosen. ASCII, EBCDIC, UTF are examples of character representation standards.
- The hardware support in terms of word width, instruction.
Before we go into the details, let us take an example of interpretation. Say a byte in Memory has value "0011 0001". Although there exists a possibility of so many interpretations as in figure 3.2, the program has only one interpretation as decided by the programmer and declared in the program.
- Fixed point Number Representation
Fixed point numbers are also known as whole numbers or Integers. The number of bits used in representing the integer also implies the maximum number that can be represented in the system hardware. However for the efficiency of storage and operations, one may choose to represent the integer with one Byte, two Bytes, Four bytes or more. This space allocation is translated from the definition used by the programmer while defining a variable as integer short or long and the Instruction Set Architecture.
In addition to the bit length definition for integers, we also have a choice to represent them as below:
- Unsigned Integer : A positive number including zero can be represented in this format. All the allotted bits are utilised in defining the number. So if one is using 8 bits to represent the unsigned integer, the range of values that can be represented is 28 i.e. "0" to "255". If 16 bits are used for representing then the range is 216 i.e. "0 to 65535".
- Signed Integer : In this format negative numbers, zero, and positive numbers can be represented. A sign bit indicates the magnitude direction as positive or negative. There are three possible representations for signed integer and these are Sign Magnitude format, 1's Compliment format and 2's Complement format .
Signed Integer – Sign Magnitude format: Most Significant Bit (MSB) is reserved for indicating the direction of the magnitude (value). A "0" on MSB means a positive number and a "1" on MSB means a negative number. If n bits are used for representation, n-1 bits indicate the absolute value of the number. Examples for n=8:
Examples for n=8:
0010 1111 = + 47 Decimal (Positive number)
1010 1111 = - 47 Decimal (Negative Number)
0111 1110 = +126 (Positive number)
1111 1110 = -126 (Negative Number)
0000 0000 = + 0 (Postive Number)
1000 0000 = - 0 (Negative Number)
Although this method is easy to understand, Sign Magnitude representation has several shortcomings like
- Zero can be represented in two ways causing redundancy and confusion.
- The total range for magnitude representation is limited to 2n-1, although n bits were accounted.
- The separate sign bit makes the addition and subtraction more complicated. Also, comparing two numbers is not straightforward.
Signed Integer – 1’s Complement format: In this format too, MSB is reserved as the sign bit. But the difference is in representing the Magnitude part of the value for negative numbers (magnitude) is inversed and hence called 1’s Complement form. The positive numbers are represented as it is in binary. Let us see some examples to better our understanding.
1101 0000 = - 47 Decimal (Negative Number)
1000 0001 = -126 (Negative Number)
1111 1111 = - 0 (Negative Number)
- Converting a given binary number to its 2's complement form
Step 1 . -x = x' + 1 where x' is the one's complement of x.
Step 2 Extend the data width of the number, fill up with sign extension i.e. MSB bit is used to fill the bits.
Example: -47 decimal over 8bit representation
As you can see zero is not getting represented with redundancy. There is only one way of representing zero. The other problem of the complexity of the arithmetic operation is also eliminated in 2’s complement representation. Subtraction is done as Addition.
More exercises on number conversion are left to the self-interest of readers.
- Floating Point Number system
The maximum number at best represented as a whole number is 2 n . In the Scientific world, we do come across numbers like Mass of an Electron is 9.10939 x 10-31 Kg. Velocity of light is 2.99792458 x 108 m/s. Imagine to write the number in a piece of paper without exponent and converting into binary for computer representation. Sure you are tired!!. It makes no sense to write a number in non- readable form or non- processible form. Hence we write such large or small numbers using exponent and mantissa. This is said to be Floating Point representation or real number representation. he real number system could have infinite values between 0 and 1.
Representation in computer
Unlike the two's complement representation for integer numbers, Floating Point number uses Sign and Magnitude representation for both mantissa and exponent . In the number 9.10939 x 1031, in decimal form, +31 is Exponent, 9.10939 is known as Fraction . Mantissa, Significand and fraction are synonymously used terms. In the computer, the representation is binary and the binary point is not fixed. For example, a number, say, 23.345 can be written as 2.3345 x 101 or 0.23345 x 102 or 2334.5 x 10-2. The representation 2.3345 x 101 is said to be in normalised form.
Floating-point numbers usually use multiple words in memory as we need to allot a sign bit, few bits for exponent and many bits for mantissa. There are standards for such allocation which we will see sooner.
- IEEE 754 Floating Point Representation
We have two standards known as Single Precision and Double Precision from IEEE. These standards enable portability among different computers. Figure 3.3 picturizes Single precision while figure 3.4 picturizes double precision. Single Precision uses 32bit format while double precision is 64 bits word length. As the name suggests double precision can represent fractions with larger accuracy. In both the cases, MSB is sign bit for the mantissa part, followed by Exponent and Mantissa. The exponent part has its sign bit.
It is to be noted that in Single Precision, we can represent an exponent in the range -127 to +127. It is possible as a result of arithmetic operations the resulting exponent may not fit in. This situation is called overflow in the case of positive exponent and underflow in the case of negative exponent. The Double Precision format has 11 bits for exponent meaning a number as large as -1023 to 1023 can be represented. The programmer has to make a choice between Single Precision and Double Precision declaration using his knowledge about the data being handled.
The Floating Point operations on the regular CPU is very very slow. Generally, a special purpose CPU known as Co-processor is used. This Co-processor works in tandem with the main CPU. The programmer should be using the float declaration only if his data is in real number form. Float declaration is not to be used generously.
- Decimal Numbers Representation
Decimal numbers (radix 10) are represented and processed in the system with the support of additional hardware. We deal with numbers in decimal format in everyday life. Some machines implement decimal arithmetic too, like floating-point arithmetic hardware. In such a case, the CPU uses decimal numbers in BCD (binary coded decimal) form and does BCD arithmetic operation. BCD operates on radix 10. This hardware operates without conversion to pure binary. It uses a nibble to represent a number in packed BCD form. BCD operations require not only special hardware but also decimal instruction set.
- Exceptions and Error Detection
All of us know that when we do arithmetic operations, we get answers which have more digits than the operands (Ex: 8 x 2= 16). This happens in computer arithmetic operations too. When the result size exceeds the allotted size of the variable or the register, it becomes an error and exception. The exception conditions associated with numbers and number operations are Overflow, Underflow, Truncation, Rounding and Multiple Precision . These are detected by the associated hardware in arithmetic Unit. These exceptions apply to both Fixed Point and Floating Point operations. Each of these exceptional conditions has a flag bit assigned in the Processor Status Word (PSW). We may discuss more in detail in the later chapters.
- Character Representation
Another data type is non-numeric and is largely character sets. We use a human-understandable character set to communicate with computer i.e. for both input and output. Standard character sets like EBCDIC and ASCII are chosen to represent alphabets, numbers and special characters. Nowadays Unicode standard is also in use for non-English language like Chinese, Hindi, Spanish, etc. These codes are accessible and available on the internet. Interested readers may access and learn more.
1. Track your progress [Earn 200 points]
Mark as complete
2. Provide your ratings to this chapter [Earn 100 points]
- Number System and Arithmetic
- Trigonometry
- Probability
- Mensuration
- Linear Algebra
- CBSE Class 8 Maths Formulas
- CBSE Class 9 Maths Formulas
- CBSE Class 10 Maths Formulas
- CBSE Class 11 Maths Formulas
What are the different ways of Data Representation?
The process of collecting the data and analyzing that data in large quantity is known as statistics. It is a branch of mathematics trading with the collection, analysis, interpretation, and presentation of numeral facts and figures.
It is a numerical statement that helps us to collect and analyze the data in large quantity the statistics are based on two of its concepts:
- Statistical Data
- Statistical Science
Statistics must be expressed numerically and should be collected systematically.
Data Representation
The word data refers to constituting people, things, events, ideas. It can be a title, an integer, or anycast. After collecting data the investigator has to condense them in tabular form to study their salient features. Such an arrangement is known as the presentation of data.
It refers to the process of condensing the collected data in a tabular form or graphically. This arrangement of data is known as Data Representation.
The row can be placed in different orders like it can be presented in ascending orders, descending order, or can be presented in alphabetical order.
Example: Let the marks obtained by 10 students of class V in a class test, out of 50 according to their roll numbers, be: 39, 44, 49, 40, 22, 10, 45, 38, 15, 50 The data in the given form is known as raw data. The above given data can be placed in the serial order as shown below: Roll No. Marks 1 39 2 44 3 49 4 40 5 22 6 10 7 45 8 38 9 14 10 50 Now, if you want to analyse the standard of achievement of the students. If you arrange them in ascending or descending order, it will give you a better picture. Ascending order: 10, 15, 22, 38, 39, 40, 44. 45, 49, 50 Descending order: 50, 49, 45, 44, 40, 39, 38, 22, 15, 10 When the row is placed in ascending or descending order is known as arrayed data.
Types of Graphical Data Representation
Bar chart helps us to represent the collected data visually. The collected data can be visualized horizontally or vertically in a bar chart like amounts and frequency. It can be grouped or single. It helps us in comparing different items. By looking at all the bars, it is easy to say which types in a group of data influence the other.
Now let us understand bar chart by taking this example Let the marks obtained by 5 students of class V in a class test, out of 10 according to their names, be: 7,8,4,9,6 The data in the given form is known as raw data. The above given data can be placed in the bar chart as shown below: Name Marks Akshay 7 Maya 8 Dhanvi 4 Jaslen 9 Muskan 6
A histogram is the graphical representation of data. It is similar to the appearance of a bar graph but there is a lot of difference between histogram and bar graph because a bar graph helps to measure the frequency of categorical data. A categorical data means it is based on two or more categories like gender, months, etc. Whereas histogram is used for quantitative data.
For example:
The graph which uses lines and points to present the change in time is known as a line graph. Line graphs can be based on the number of animals left on earth, the increasing population of the world day by day, or the increasing or decreasing the number of bitcoins day by day, etc. The line graphs tell us about the changes occurring across the world over time. In a line graph, we can tell about two or more types of changes occurring around the world.
For Example:
Pie chart is a type of graph that involves a structural graphic representation of numerical proportion. It can be replaced in most cases by other plots like a bar chart, box plot, dot plot, etc. As per the research, it is shown that it is difficult to compare the different sections of a given pie chart, or if it is to compare data across different pie charts.
Frequency Distribution Table
A frequency distribution table is a chart that helps us to summarise the value and the frequency of the chart. This frequency distribution table has two columns, The first column consist of the list of the various outcome in the data, While the second column list the frequency of each outcome of the data. By putting this kind of data into a table it helps us to make it easier to understand and analyze the data.
For Example: To create a frequency distribution table, we would first need to list all the outcomes in the data. In this example, the results are 0 runs, 1 run, 2 runs, and 3 runs. We would list these numerals in numerical ranking in the foremost queue. Subsequently, we ought to calculate how many times per result happened. They scored 0 runs in the 1st, 4th, 7th, and 8th innings, 1 run in the 2nd, 5th, and the 9th innings, 2 runs in the 6th inning, and 3 runs in the 3rd inning. We set the frequency of each result in the double queue. You can notice that the table is a vastly more useful method to show this data. Baseball Team Runs Per Inning Number of Runs Frequency 0 4 1 3 2 1 3 1
Sample Questions
Question 1: Considering the school fee submission of 10 students of class 10th is given below:
| Muskan | Paid |
| Kritika | Not paid |
| Anmol | Not paid |
| Raghav | Paid |
| Nitin | Paid |
| Dhanvi | Paid |
| Jasleen | Paid |
| Manas | Not paid |
| Anshul | Not paid |
| Sahil | Paid |
In order to draw the bar graph for the data above, we prepare the frequency table as given below. Fee submission No. of Students Paid 6 Not paid 4 Now we have to represent the data by using the bar graph. It can be drawn by following the steps given below: Step 1: firstly we have to draw the two axis of the graph X-axis and the Y-axis. The varieties of the data must be put on the X-axis (the horizontal line) and the frequencies of the data must be put on the Y-axis (the vertical line) of the graph. Step 2: After drawing both the axis now we have to give the numeric scale to the Y-axis (the vertical line) of the graph It should be started from zero and ends up with the highest value of the data. Step 3: After the decision of the range at the Y-axis now we have to give it a suitable difference of the numeric scale. Like it can be 0,1,2,3…….or 0,10,20,30 either we can give it a numeric scale like 0,20,40,60… Step 4: Now on the X-axis we have to label it appropriately. Step 5: Now we have to draw the bars according to the data but we have to keep in mind that all the bars should be of the same length and there should be the same distance between each graph
Question 2: Watch the subsequent pie chart that denotes the money spent by Megha at the funfair. The suggested colour indicates the quantity paid for each variety. The total value of the data is 15 and the amount paid on each variety is diagnosed as follows:
Chocolates – 3
Wafers – 3
Toys – 2
Rides – 7
To convert this into pie chart percentage, we apply the formula: (Frequency/Total Frequency) × 100 Let us convert the above data into a percentage: Amount paid on rides: (7/15) × 100 = 47% Amount paid on toys: (2/15) × 100 = 13% Amount paid on wafers: (3/15) × 100 = 20% Amount paid on chocolates: (3/15) × 100 = 20 %
Question 3: The line graph given below shows how Devdas’s height changes as he grows.
Given below is a line graph showing the height changes in Devdas’s as he grows. Observe the graph and answer the questions below.

(i) What was the height of Devdas’s at 8 years? Answer: 65 inches (ii) What was the height of Devdas’s at 6 years? Answer: 50 inches (iii) What was the height of Devdas’s at 2 years? Answer: 35 inches (iv) How much has Devdas’s grown from 2 to 8 years? Answer: 30 inches (v) When was Devdas’s 35 inches tall? Answer: 2 years.
Please Login to comment...
Similar reads.
- Mathematics
- School Learning
- Top 10 Fun ESL Games and Activities for Teaching Kids English Abroad in 2024
- Top Free Voice Changers for Multiplayer Games and Chat in 2024
- Best Monitors for MacBook Pro and MacBook Air in 2024
- 10 Best Laptop Brands in 2024
- 15 Most Important Aptitude Topics For Placements [2024]
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Computer Network
- Introduction
- Architecture
- Computer Network Types
- Transmission Modes
- TCP/IP Model
Physical Layer
- Digital Transmission
- Transmission Media
- Guided Media
- UnGuided Media
- Multiplexing
- Switching Modes
- Switching Techniques
- Data Link layer
- Error Detection
- Error Correction
- Data Link Controls
- Network Layer
- Network Addressing
- Network Layer Protocols
- Routing Algorithm
- Distance Vector
- Link State Routing
- Transport Layer
- Transport Layer Protocols
- Application Layer
- Client & Server Model
Application Protocols
Network security.
- Digital Signature
- What is Router
- OSI vs TCP/IP
- IPv4 vs IPv6
- ARP Packet Format
- Working of ARP
- FTP Commands
- I2P Protocol
- Sliding Window Protocol
- SPI Protocol
- ARP Commands
- ARP Request
- ARP - Address Resolution Protocol
- ARP and its types
- TCP Retransmission
- CAN Protocol
- HTTP Status Codes
- HTTP vs HTTPS
- RIP Protocol
- UDP Protocol
- ICMP Protocol
- MQTT Protocol
- OSPF Protocol
- Stop & Wait Protocol
- IMAP Protocol
- POP Protocol
- Go-Back-N ARQ
- Connection-Oriented vs Connectionless Service
- CDMA vs GSM
- What is MAC Address
- Modem vs Router
- Switch vs Router
- USB 2.0 vs USB 3.0
- CSMA CA vs CSMA CD
- Multiple Access Protocols
- IMAP vs. POP3
- SSH Meaning
- Status Code 400
- MIME Protocol
- What is a proxy server and how does it work
- How to set up and use a proxy server
- What is network security
- WWW is based on which model
- Proxy Server List
- Fundamentals of Computer Networking
- IP Address Format and Table
- Bus topology vs Ring topology
- Bus topology vs Star topology
- Circuit Switching vs Packet switching
- star vs ring topology
- Router vs Bridge
- TCP Connection Termination
- Image Steganography
- Network Neutrality
- Onion Routing
- ASA features
- Relabel-to-front Algorithm
- Types of Server Virtualization in Computer Network
- Access Lists (ACL)
- Digital Subscriber Line (DSL)
- Operating system based Virtualization
- Context based Access Control (CBAC)
- Cristian's Algorithm
- Service Set Identifier (SSID) in Computer Network
- Voice over Internet Protocol (VoIP)
- Challenge Response Authentication Mechanism (CRAM)
- Extended Access List
- Li-fi vs. Wi-fi
- Reflexive Access List
- Synchronous Optical Network (SONET)
- Wifi protected access (WPA)
- Wifi Protected Setup (WPS)
- Standard Access List
- Time Access List
- What is 3D Internet
- 4G Mobile Communication Technology
- Types of Wireless Transmission Media
- Best Computer Networking Courses
- Data Representation
- Network Criteria
- Classful vs Classless addressing
- Difference between BOOTP and RARP in Computer Networking
- What is AGP (Accelerated Graphics Port)
- Advantages and Disadvantages of Satellite Communication
- External IP Address
- Asynchronous Transfer Mode (ATM) in Computer Network
- Types of Authentication Protocols
- What is a CISCO Packet Tracer
- How does BOOTP work
- Subnetting in Computer Networks
- Mesh Topology Advantages and Disadvantages
- Ring Topology Advantages and Disadvantages
- Star Topology Advantages and Disadvantages
- Tree Topology Advantages and Disadvantages
- Zigbee Technology-The smart home protocol
- Network Layer in OSI Model
- Physical Layer in OSI Model
- Data Link Layer in OSI Model
- Internet explorer shortcut keys
- Network Layer Security | SSL Protocols
- Presentation Layer in OSI Model
- Session Layer in OSI Model
- SUBNET MASK
- Transport Layer Security | Secure Socket Layer (SSL) and SSL Architecture
- Functions, Advantages and Disadvantages of Network Layer
- Functions, Advantages and Disadvantages of the Physical Layer
- Types of Internet Connection
- Noisy and Noiseless Channel
- Advantages and Disadvantages of Bus Topology
- Advantages and Disadvantages of Ring Topology
- Advantages and Disadvantages of Star Topology
- Protocols in Noiseless and Noisy Channel
- Advantages and Disadvantages of Mesh Topology
- Cloud Networking - Managing and Optimizing Cloud-Based Networks
- Collision Domain and Broadcast Domain
- Count to Infinity Problem in Distance Vector Routing
- Difference Between Go-Back-N and Selective Repeat Protocol
- Difference between Stop and Wait, GoBackN, and Selective Repeat
- Network Function Virtualization (NFV): transforming Network Architecture with Virtualized Functions
- Network-Layer Security | IPSec Modes
- Network-Layer Security | IPSec Protocols and Services
- Ping vs Traceroute
- Software Defined Networking (SDN): Benefits and Challenges of Network Virtualization
- Software Defined Networking (SDN) vs. Network Function Virtualization (NFV)
- Virtual Circuits vs Datagram Networks
- BlueSmack Attack in Wireless Networks
- Bluesnarfing Attack in Wireless Networks
- Direct Sequence Spread Spectrum
- Warchalking in Wireless Networks
- WEP (Wired Equivalent Privacy)
- Wireless security encryption
- Wireless Security in an Enterprise
- Quantum Networking
- Network Automation
- Difference between MSS and MTU
- What is MTU
- Mesh Networks: A decentralized and Self-Organizing Approach to Networking
- What is Autonomous System
- What is MSS
- Cyber security and Software security
- Information security and Network security
- Security Engineer and Security Architect
- Protection Methods for Network Security
- Trusted Systems in Network Security
- What are Authentication Tokens in Network security
- Cookies in Network Security
- Intruders in Network Security
- Network Security Toolkit (NST) in virtual box
- Pivoting-Moving Inside a Network
- Security Environment in Computer Networks
- Voice Biometric technique in Network Security
- Advantages and Disadvantages of Conventional Testing
- Difference between Kerberos and LDAP
- Cyber security and Information Security
- GraphQL Attacks and Security
- Application Layer in OSI Model
- Applications of Remote Sensing
- Seven Layers of IT Security
- What is Ad Hoc TCP
- What is Server Name Indication(SNI)
- Difference Between Infrastructure and Infrastructure Less Network
- Collision Avoidance in Wireless Networks
- Difference Engine and Analytical Engine
- Hotspot 2.0
- Intrusion Prevention System (IPS)
- Modes of Connection Bluetooth
- Noisy Channel protocols
- Parzen Windows density Estimation Technique
- Principle of Information System Security
- What are Bots, Botnets, and Zombies
- Windows Memory Management
- Wireless dos attack on Wifi
- Design Principles of Security in Distributed Systems
- MAC Filtering
- Principles of Network Applications
- Time-to-Live (TTL)
- What is 1000 BASE-T
- What is the difference between 802.11ac and 802.11ax
- Differentiate between Circuit Switching, Message Switching, and Packet Switching
- What is Web 3.0
- Collision Detection in CSMA/CD
- Ipv4 Header in Computer Networks
- Layered Architecture in Computer Networks
- Define URL in Computer Networks
- MAN in Computer Networks
- Routing Protocols in Computer Networks
- Flooding in Computer Network
- CRC in Computer Network
- Application of Computer Network
- Computer Network Architect
- Design Issues for the Layers of Computer Networks
- What is AMD (Advanced Micro Devices)
- Protocol in Computer Network
- Computer Network Projects
- Different Types of Routers
- Wireless Distribution System (WDS)
- Network Time Protocol
- Address Resolution Protocol (ARP) and its types in Computer Network
- Automatic Repeat ReQuest (ARQ) in Computer Networks
- Bluetooth in Computer Networks
- Circuit Switching in Computer Network
- Computer Hardware and Networking Course
- Ring Topology in a Computer Network
- Token Ring in Computer Networks
- Medium Access Control in Computer Network
- Need for Computer Network
- Repeater in Computer Network
- Computer Networking: a Top Down Approach
- What is Multiplexing in Computer Network
- Body Area Network (BAN)
- INS AND OUT OF DATA STREAMING
- Streaming stored video
- Cellular Network
- How can devices on a Network be identified
- How Does the Internet Work
- Authentication Server
- What is Cloud Backup and How does it Work
- Communication Protocols In System Design
- Extensible Authentication Protocol (EAP)
- Role-Based Access Control (RBAC)
- Network Enumeration Tools
- Network Protocol Testing
- Windows Networking Commands
- Advantages and Disadvantages of WLAN
- Anonymous File Transfer Protocol (AFTP)
- Automatic Private IP Addressing
- What is Deep Web
- USB-C (USB Type C)
- User Authentication
- What is a vCard
- ipv4 Headers
- Difference between Token ring and Ethernet Token Ring
- Server Message Block protocol (SMB protocol)
- Session Border Controllers (SBC)
- Short Message Service Center (SMSC)
- What is a Mail Server
- What are Communication Networks
- Initialization Vector
- What is Fiber Optics
- Open Networking
- Access Ports Vs Trunk Ports
- Edge Routers
- IPTV (Internet Protocol Television)
- Wireless Internet Service Provider (WISP)
- Wireless Backhaul
- Define Protocol in Computer Network
- Virtual Network Adapter
- Virtual Routing and Forwarding
- Virtual Switches(vSwitches)
- VLAN (Virtual LAN)
- Wireless Mesh Network (WMN)
- What is Gateway in Computer Network
- Radio Access Network (RAN)
- What is File Sharing
- Passive Optical Network (PON)
- Private IP address
- Public Key Certificate
- What is Bridge in Computer Network
- Ping Sweep (ICMP Sweep)
- Print Server
- WIFI Pineapple
- Walled Garden
- Wireless ISP (wireless Internet service provider or WISP)
- Bridge vs Repeater
- Hardware Security Module (HSM)
- Public Switched Telephone Network
- Analog Telephone Adapter (ATA)
- Host Bus Adapter (HBA)
- ISCSI initiator
- Simplest Protocol
- Telecommunication Networks
- What is WPS in Wi-Fi
- What are the Most Important Email Security Protocols
- What is Data Governance and Why does it Matter
- Carrier Network
- Most Secure Network Protocol
- Network SMB
- BGP vs. EIGRP: What's the Difference
- Wireless Security: WEP, WPA, WPA2 and WPA3 differences
- Cloud Radio Access Network (C-RAN)
- Bits Per Second (bps or bit/sec)
- Blade Server
- command-and-control server (C&C server)
- Computer Network MCQ
- Computer Network MCQ Part2
Interview Questions
- Networking Questions
| A network is a collection of different devices connected and capable of communicating. For example, a company's local network connects employees' computers and devices like printers and scanners. Employees will be able to share information using the network and also use the common printer/ scanner via the network. Data to be transferred or communicated from one device to another comes in various formats like audio, video, etc. This tutorial explains how different data types are represented in a computer and transferred in a network.
Data in text format is represented using bit patterns (combinations of two binary bits - 0 and 1). Textual data is nothing but a string, and a string is a collection of characters. Each character is given a specific number according to an international standard called Unicode. The process of allocating numbers to characters is called "Coding," and these numbers are called "codes". Now, these codes are converted into binary bits to represent the textual data in a pattern of bits, and these bits are transferred as a stream via the network to other devices.
It is the universal standard of character encoding. It gives a unique code to almost all the characters in every language spoken in the world. It defines more than 1 40 000 characters. It even defined codes for emojis. The first 128 characters of Unicode point to ASCII characters. ASCII is yet another character encoding format, but it has only 128 codes to 128 characters. Hence, ASCII is a subset of Unicode.
.doc, .docx, .pdf, .txt, etc.
Word: H Unicode representation: U+0048 Numbers are directly converted into binary patterns by dividing by 2 without any encoding. The numbers we want to transfer generally will be of the decimal number system- ( ) . We need to convert the numbers from ( ) to a binary number system - ( )
Integers Date Boolean Decimal Fixed point Floating point
Number: 780 Binary representation: 1100001100 Image data is also transferred as a stream of bits like textual data. An image, also called a picture, is a collection of little elements called " ". A single pixel is the smallest addressable element of a picture, and it is like a dot with a size of 1/96 inch/ 0.26 mm. The dimensions of an image are given by the
A black-and-white/ Grayscale image consists of white, black, and all the shades in between. It can be considered as just . The intensity of the white color in a pixel is given by numbers called " ". The pixel value in a Grayscale image can be in the range , where 0 represents Black and 255 represents White, and all the numbers in the interval represent different shades. A matrix is created for the image with pixel values of all the pixels in the image. This matrix is called a " ".
representing three standard colors: . Any color known can be generated by using these three colors. Based on the intensity of a color in the pixel, three matrices/ channels for each color are generated. Suppose there is a colored image, and three matrices are created for Red, Green, and Blue colors in each pixel in the image: , and this bit stream is transferred to any other device in the network to communicate the image. N-bit streams are used to represent 2N possible colors. From 0 to 255, we can represent 256 shades of color with different 8-bit patterns. , an image consists of only either black or white colors, only one bit will be enough to represent the pixels: White - 1 Black - 0
.jpg, jpeg, .png, etc. Transferring an audio signal is different from other formats. Audio is broadcasting recorded sound or music. An audio signal is to be stored in a computer by representing the wave amplitude at moments in bits. Another parameter is the sample rate. It represents the number of samples or, in other words, samples saved. The audio quality depends and the . If more bits are used to represent the amplitudes in moments and more moments are captured accurately, we can save the audio with every detail accurately.
.mp3, .m4a, .WAV, .AAC, etc. A video is a with the same or different dimensions. These frames/ images are represented as matrices, as we discussed above. All the frames/ images are displayed continuously, one after the other, to show a video in movement. To represent a video, The computer will analyze data about the video like: (Frames per second)A video is mostly combined with an audio component, like a film or a video game.
.mp4, .MOV, .AVI, etc. |
Latest Courses

Javatpoint provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
Contact info
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
[email protected] .

Online Compiler
CHEPLASKEI BOYS HIGH SCHOOL
Data representation in a computer, 1. introduction.
- Computers are classified according to functionality, physical size and purpose .
- Functionality, Computers could be analog, digital or hybrid . Digital computers process data that is in discrete form whereas analog computers process data that is continuous in nature. Hybrid computers on the other hand can process data that is both discrete and continuous.
- In digital computers, the user input is first converted and transmitted as electrical pulses that can be represented by two unique states ON and OFF. The ON state may be represented by a “1” and the off state by a “0”.The sequence of ON’S and OFF’S forms the electrical signals that the computer can understand.
- A digital signal rises suddenly to a peak voltage of +1 for some time then suddenly drops -1 level on the other hand an analog signal rises to +1 and then drops to -1 in a continuous version.
- Although the two graphs look different in their appearance, notice that they repeat themselves at equal time intervals. Electrical signals or waveforms of this nature are said to be periodic.Generally,a periodic wave representing a signal can be described using the following parameters
- Amplitude(A)
- Frequency(f)
- periodic time(T)
- Amplitude (A): this is the maximum displacement that the waveform of an electric signal can attain.
- Frequency (f): is the number of cycles made by a signal in one second. It is measured in hertz.1hert is equivalent to 1 cycle/second.
- Periodic time (T): the time taken by a signal to complete one cycle is called periodic time. Periodic time is given by the formula T=1/f, where f is the frequency of the wave.
- When a digital signal is to be sent over analog telephone lines e.g. e-mail, it has to be converted to analog signal. This is done by connecting a device called a modem to the digital computer. This process of converting a digital signal to an analog signal is known as modulation . On the receiving end, the incoming analog signal is converted back to digital form in a process known as demodulation .
2. concepts of data representation in digital computers
- Data and instructions cannot be entered and processed directly into computers using human language. Any type of data be it numbers, letters, special symbols, sound or pictures must first be converted into machine-readable form i.e. binary form. Due to this reason, it is important to understand how a computer together with its peripheral devices handles data in its electronic circuits, on magnetic media and in optical devices.
Data representation in digital circuits
- Electronic components, such as microprocessor, are made up of millions of electronic circuits. The availability of high voltage(on) in these circuits is interpreted as ‘1’ while a low voltage (off) is interpreted as ‘0’.This concept can be compared to switching on and off an electric circuit. When the switch is closed the high voltage in the circuit causes the bulb to light (‘1’ state).on the other hand when the switch is open, the bulb goes off (‘0’ state). This forms a basis for describing data representation in digital computers using the binary number system.
Data representation on magnetic media
- The laser beam reflected from the land is interpreted, as 1.The laser entering the pot is not reflected. This is interpreted as 0.The reflected pattern of light from the rotating disk falls on a receiving photoelectric detector that transforms the patterns into digital form.The presence of a magnetic field in one direction on magnetic media is interpreted as 1; while the field in the opposite direction is interpreted as “0”.Magnetic technology is mostly used on storage devices that are coated with special magnetic materials such as iron oxide. Data is written on the media by arranging the magnetic dipoles of some iron oxide particles to face in the same direction and some others in the opposite direction
Data representation on optical media
In optical devices, the presence of light is interpreted as ‘1’ while its absence is interpreted as ‘0’.Optical devices use this technology to read or store data. Take example of a CD-ROM, if the shiny surface is placed under a powerful microscope, the surface is observed to have very tiny holes called pits . The areas that do not have pits are called land .
Reason for use of binary system in computers
- It has proved difficult to develop devices that can understand natural language directly due to the complexity of natural languages. However, it is easier to construct electric circuits based on the binary or ON and OFF logic. All forms of data can be represented in binary system format. Other reasons for the use of binary are that digital devices are more reliable, small and use less energy as compared to analog devices.
Bits, bytes, nibble and word
- The terms bits, bytes, nibble and word are used widely in reference to computer memory and data size.
- Bits: can be defined as either a binary, which can be 0, or 1.It is the basic unit of data or information in digital computers.
- Byte: a group of bits (8 bits) used to represent a character. A byte is considered as the basic unit of measuring memory size in computer.
- A nibble : is half a byte, which is usually a grouping of 4 bytes.
- Word: two or more bits make a word. The term word length is used as the measure of the number of bits in each word. For example, a word can have a length of 16 bits, 32 bits, 64 bits etc.
Types of data representation
- Computers not only process numbers, letters and special symbols but also complex types of data such as sound and pictures. However, these complex types of data take a lot of memory and processor time when coded in binary form.
- This limitation necessitates the need to develop better ways of handling long streams of binary digits.
Number systems and their representation
- A number system is a set of symbols used to represent values derived from a common base or radix.
- As far as computers are concerned, number systems can be classified into two major categories:
- decimal number system
- binary number system
- octal number system
- hexadecimal number system
Decimal number system
- The term decimal is derived from a Latin prefix deci, which means ten. Decimal number system has ten digits ranging from 0-9. Because this system has ten digits; it is also called a base ten number system or denary number system.
- A decimal number should always be written with a subscript 10 e.g. X 10
- But since this is the most widely used number system in the world, the subscript is usually understood and ignored in written work. However ,when many number systems are considered together, the subscript must always be put so as to differentiate the number systems.
- The magnitude of a number can be considered using these parameters.
- Absolute value
- Place value or positional value
- The absolute value is the magnitude of a digit in a number. for example the digit 5 in 7458 has an absolute value of 5 according to its value in the number line.
- The place value of a digit in a number refers to the position of the digit in that number i.e. whether; tens, hundreds, thousands etc.
- The total value of a number is the sum of the place value of each digit making the number.
- The base value of a number also k known as the radix , depends on the type of the number systems that is being used .The value of any number depends on the radix. for example the number 100 10 is not equivalent to 100 2 .
Binary number system
Octal number system
Consists of eight digits ranging from 0-7.the place value of octal numbers goes up in factors of eight from right to left.
Hexadecimal number system This is a base 16 number system that consists of sixteen digits ranging from 0-9 and letters A-F where A is equivalent to 10,B to 11 up to F which is equivalent to 15 in base ten system. The place value of hexadecimal numbers goes up in factors of sixteen.
- A hexadecimal number can be denoted using 16 as a subscript or capital letter H to the right of the number .For example, 94B can be written as 94B16 or 94BH.
Further conversion of numbers from one number system to another
- To convert numbers from one system to another. the following conversions will be considered.
- Converting between binary and decimal numbers.
- Converting octal numbers to decimal and binary form.
- Converting hexadecimal numbers to decimal and binary form.
- a) Conversion between binary and decimal number
- Converting binary numbers to decimal numbers
- To convert a binary number to a decimal number, we proceed as follows:
First, write the place values starting from the right hand side.
- Write each digit under its place value.
- Multiply each digit by its corresponding place value.
- Add up the products. The answer will be the decimal number in base ten.
Convert 101101 2 to base 10(or decimal) number
| Place value | 2 | 2 | 2 | 2 | 2 | 2 |
| Binary digits | 1 | 0 | 1 | 1 | 0 | 1 |
Multiply each digit by its place value
| N =(1*2 ) +(0*2 )+(1*2 )+(1*2 )+(0*2 )+(1*2 ) N =32+0+8+4+0+1
=45 |
8*1=8 4*1=4
NB: remember to indicate the base subscript since it is the value that distinguishes the different systems.
- The binary equivalent of the fractional part is extracted from the products by reading the respective integral digits from the top downwards as shown by the arrow next page.
- Combine the two parts together to set the binary equivalent.
Convert 0.375 10 into binary form
Read this digits
0.375×2=0.750
0.750×2=1.500
0.500×2=1.000 (fraction becomes zero)
Therefore 0.375 10 =0.011 2
NB: When converting a real number from binary to decimal, work out the integral part and the fractional parts separately then combine them.
Convert 11.011 2 to a decimal number.
Convert the integral and the fractional parts separately then add them up.
1×1= +1.000
| Weight | 2 | 2 |
| 2 | 2 | 2 |
| Binary digit | 1 | 1 |
| 0 | 1 | 1 |
| Values in base 10 | 2 | 1 |
| 0 | 0.25 | 0.125 |
0.50×0 =0.000
0.25×1 =0.250
0.125×1=+0.125
3.000 10 +0.375 10 = 3.375 10
Thus 11.011 2 =3.375 10
- iv) Converting a decimal fraction to binary
Divide the integral part continuously by 2.For the fractional part, proceed as follows:
Multiply the fractional part by 2 and note down the product
- Take the fractional part of the immediate product and multiply it by 2 again.
- Continue this process until the fractional part of the subsequent product is 0 or starts to repeat itself.
Convert octal number 321 8 to its binary equivalent
Working from left to the right, each octal number is represented using three digits and then combined we get the final binary equivalent. Therefore:
Combining the three from left to right
| 3 | 2 | 1 |
| 011 | 010 | 001 |
321 8 =011010001 2
Converting binary numbers to hexadecimal numbers
To convert binary numbers to their binary equivalents, simply group the digits of the binary number into groups of four from right to left e.g. 11010001.The next step is to write the hexadecimal equivalent of each group e.g.
The equivalent of 11010001 is D1H or D1 16
Converting hexadecimal numbers to decimal and binary numbers .
Converting hexadecimal numbers to decimal number
To convert hexadecimal number to base 10 equivalent we proceed as follows:
- If a digit is a letter such as ‘A’ write its decimal equivalent
- Multiply each hexadecimal digit with its corresponding place value and then add the products
The binary equivalent of the fractional part is extracted from the products by reading the respective integral digits from the top downwards as shown by the arrow next pag
Converting octal numbers to decimal and binary numbers
Converting octal numbers to decimal numbers
- To convert a base 8 number to its decimal equivalent we use the same method as we did with binary numbers. However, it is important to note that the maximum absolute value of a octal digit is 7.For example 982 Is not a valid octal number because digit 9 is not an octal digit, but 736 8 is valid because all the digits are in the range 0-7.Example shows how to convert an octal number to a decimal number.
Example 1.13
Convert 512 8 to its base 10 equivalent
| Place value | 8 | 8 | 8
|
| 64 | 8 | 1 | |
| Octal digit | 5 | 1 | 2 |
Write each number under its place value as shown below
Multiply each number by its place value.
|
N =(5 x 8 )+(1 x 8 )+(2 x 8 ) =(5 x 64)+8+2 =320+8+2 N =330
|
Therefore512 8 =330 10
Converting octal numbers to binary numbers
- To convert an octal number to binary, each digit is represented by three binary digits because the maximum octal digit i.e. 7 can be represented with a maximum of seven digits. See table:
| Octal digit | Binary equivalents |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
Convert the hexadecimal number 111 16 to its binary equivalent.
Place each number under its place value.
| 16
| 16
| 16
|
| 1
| 1
| 1
|
256 x1= 256
16 x 1 = 16
Therefore 111 16 =273 10
- The following examples illustrate how to convert hexadecimal number to a decimal number
Convert the hexadecimal number 111 16 to its binary equivalent
Converting hexadecimal numbers to binary numbers
- Since F is equivalent to a binary number1111 2 the hexadecimal number are therefore represented using4 digits as shown in the table below
| Hexadecimal digit | Decimal equivalent | Binary equivalent |
| 00 | 00 | 0000 |
| 01 | 01 | 0001 |
| 02 | 02 | 0010 |
| 03 | 03 | 0011 |
| 04 | 04 | 0100 |
| 05 | 05 | 0101 |
| 06 | 06 | 0110 |
| 07 | 07 | 0111 |
| 08 | 08 | 1000 |
| 09 | 09 | 1001 |
| A | 10 | 1010 |
| B | 11 | 1011 |
| C | 12 | 1100 |
| D | 13 | 1101 |
| E | 14 | 1110 |
| F | 15 | 1111 |
The simplest method of converting a hexadecimal number to binary is to express each hexadecimal digit as a four bit binary digit number and then arranging the group according to their corresponding positions as shown in example
Convert 321 16
| Hexadecimal digit | 3 | 2 | 1 |
| Binary equivalent | 0011 | 0010 | 0001 |
Combining the three sets of bits, we get 001100100001 2
321 16 = 001100100001 2
Convert 5E6 16 into binary
Hexadecimal digit
| 5 | E | 6 | |
| Binary equivalent | 0101 | 1110 | 0110 |
5E616 = 010111100110 2
Symbolic representation using coding schemes
- In computing, a single character such as a letter, a number or a symbol is represented by a group of bits. The number of bits per character depends on the coding scheme used.
- The most common coding schemes are:
- Binary Coded Decimal (BCD),
- Extended Binary Coded Decimal Interchange Code (EBCDIC) and
- American Standard Code for Information Interchange (ASCII).
Binary Coded Decimal
- Binary Coded Decimal is a 4-bit code used to represent numeric data only. For example, a number like 9 can be represented using Binary Coded Decimal as 1001 2 .
- Binary Coded Decimal is mostly used in simple electronic devices like calculators and microwaves. This is because it makes it easier to process and display individual numbers on their Liquid Crystal Display (LCD) screens.
- A standard Binary Coded Decimal , an enhanced format of Binary Coded Decimal, is a 6-bit representation scheme which can represent non-numeric characters. This allows 64 characters to be represented. For letter A can be represented as 110001 2 using standard Binary Coded Decimal
Extended Binary Coded Decimal Interchange code (EBCDIC)
- Extended Binary Coded Decimal Interchange code (EBCDIC) is an 8-bit character-coding scheme used primarily on IBM computers. A total of 256 (2 8 ) characters can be coded using this scheme. For example, the symbolic representation of letter A using Extended Binary Coded Decimal Interchange code is 11000001 2 .
American standard code for information interchange (ASCII)
- American standard code for information interchange (ASCII) is a 7-bit code, which means that only 128 characters i.e. 2 7 can be represented. However, manufactures have added an eight bit to this coding scheme, which can now provide for 256 characters.
- This 8-bit coding scheme is referred to as an 8-bit American standard code for information interchange. The symbolic representation of letter A using this scheme is 1000001 2 ..
Binary arithmetic operations
- In mathematics, the four basic arithmetic operations applied on numbers are addition, subtraction, multiplications and division.
- In computers, the same operations are performed inside the central processing unit by the arithmetic and logic unit (ALU). However, the arithmetic and logic unit cannot perform binary subtractions directly. It performs binary subtractions using a process known as For multiplication and division, the arithmetic and logic unit uses a method called shifting before adding the bits.
Representation of signed binary numbers
- In computer technology, there are three common ways of representing a signed binary number.
- Prefixing an extra sign bit to a binary number.
- Using ones compliment.
- Using twos compliment.
Prefixing an extra sign bit to a binary number
- In decimal numbers, a signed number has a prefix “+” for a positive number e.g. +27 10 and “-“ for a negative number e.g. - 27
- However, in binary, a negative number may be represented by prefixing a digit 1 to the number while a positive number may be represented by prefixing a digit 0. For example, the 7-bit binary equivalent of 127 is 1111111 2 . To indicate that it is positive, we add an extra bit (0) to the left of the number i.e. (0)1111111 2 .
- To indicate that it is negative number we add an extra bit (1) i.e. (1)1111111 2 .
- The problem of using this method is that the zero can be represented in two ways i.e.(0)0000000 2 and (1)0000000 2 .
Ones compliment
- The term compliment refers to a part which together with another makes up a whole . For example in geometry two complimentary angle (90 0 ).
- The idea of compliment is used to address the problem of signed numbers i.e. positive and negative.
- In decimal numbers (0 to 9), we talk of nine’s compliment. For example the nines compliment
- Of 9 is 0, that of 5 is 4 while 3 is 6.
- However, in binary numbers, the ones compliment is the bitwise NOT applied to the number. Bitwise NOT is a unary operator (operation on only one operand) that performs logical negation on each bit. For example the bitwise NOT of 1100 2 is 0011 2 e.
- 0s are negated to 1s while 1s are negated to 0s.
Twos compliment
- Twos compliment, equivalent to tens compliment in decimal numbers, is the most popular way of representing negative numbers in computer systems. The advantages of using this method are:
- There are no two ways of representing a zero as in the case with other two methods.
- Effective addition and subtraction can be done even with numbers that are represented with a sign bit without a need for circuitries to examine the sign of an operand.
- The twos compliment of a number is obtained by getting the ones compliment then adding a 1. For example, to get the twos compliment of a decimal number 45 10,
- First convert it to its binary equivalent then find its ones compliment. Add a 1 to ones compliment i.e.
45 10 =00101101 2
Bitwise NOT (00101101) =11010010
Two’s compliment = 11010010 2 +1 2
= 11010011 2
Binary addition
The five possible additions in binary are
- 0+ 1 2 = 1 2
- 1 2 + 0 = 1 2
- 1 2 + 1 2 = 10 2 (read as 0, carry 1)
Find the sum of 111 2 + 011 2
Arrange the bits vertically. 111
Working from the right to the left, we proceed as follows: + 011
Step 1 1 2 + 1 2 = 10 2 , (write down 0 and carry 1) 1010 2
Step 2 1 2 + 1 2 + 1 2 = 11 2 , (add and carry over digit to 1 + 1 in order to get 1 + 1
+1. From the sum, write down digit one the carry
Step 3 1 2 + 1 2 + 0 2 = 10 2 , (add the carry over digit to 1 + 0 in order to get
1 + 1 + 0.since this is the last step, write down 10)
Therefore 111 2 + 011 2 = 1010 2
This can be summarized in the table
| 1 number | 1 | 1 | 1 |
| 2 number | 0 | 1 | 1 |
| Carry digit | - | 1 | 1 |
| sum | 10 | 1 | 0 |
Add the following binary number
Add the first two numbers and then add the sum to the third number a follows:
Step 1 Step 2
10110 2 100001 2
+ 1011 2 + 111 2
100001 2 101000 2
Binary subtraction
Direct subtraction
The four possible subtractions in binary are:
- 1 2 – 0 = 1 2
- 1 2 – 1 2 = 0
- 10 2 – 1 2 = 1 2 ( borrow 1 from the next most significant digit to make 0 become 10 2 ,
hence 10 2 – 1 2 = 1 2 )
Subraction using ones compliment
The main purpose of using ones compliment in computers is to perform binary subtraction. For example to get the difference in 5 – 3, using the ones compliment, we proceed as follows:
- Rewrite the problem as 5 + (-3) to show that he computer binary subtraction by adding the binary equivalent of 5 to ones compliment of 3.
- Convert the absolute value of 3 into 8-bits equivalent i.e. 00000011 2 .
- Take the ones compliment of 00000011 2 e. 11111100 2 which is the binary representation of -3 10 .
- Add the binary equivalent of 5 to ones compliment of 3 i.e.
(1)00000001
Subtraction using twos compliments.
Like in ones compliment, the twos compliment of a number is obtained by negating a positive number to is negative counterpart. For example to get the difference in 5-3, using twos compliment, we proceed as follow:
- rewrite the problem as 5 + (-3)
- Convert the absolute value of 3 into 8-bit binary equivalent i.e. 00000011.
- Take the ones compliment of 00000011 i.e. 11111100.
- add a 1 to the ones compliment i.e. 11111100 to get 11111101
- add he binary equivalent of 5 to the twos compliment of 3 i.e.
(1)00000010 Ignoring the overflow bit, the resulting number is 00000010, which is directly read as a binary equivalent of +2.
Using twos compliment
31 10 - 17 10 in binary form.
17 10 in binary 00010001
1’s compliment 11101110
2’s compliment 11101111
31 10 = 00011111 2
00011111 + 11101111 = (1)00001110 2
IEEE Account
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
This week: the arXiv Accessibility Forum
Help | Advanced Search
Computer Science > Machine Learning
Title: high-dimensional sparse data low-rank representation via accelerated asynchronous parallel stochastic gradient descent.
Abstract: Data characterized by high dimensionality and sparsity are commonly used to describe real-world node interactions. Low-rank representation (LR) can map high-dimensional sparse (HDS) data to low-dimensional feature spaces and infer node interactions via modeling data latent associations. Unfortunately, existing optimization algorithms for LR models are computationally inefficient and slowly convergent on large-scale datasets. To address this issue, this paper proposes an Accelerated Asynchronous Parallel Stochastic Gradient Descent A2PSGD for High-Dimensional Sparse Data Low-rank Representation with three fold-ideas: a) establishing a lock-free scheduler to simultaneously respond to scheduling requests from multiple threads; b) introducing a greedy algorithm-based load balancing strategy for balancing the computational load among threads; c) incorporating Nesterov's accelerated gradient into the learning scheme to accelerate model convergence. Empirical studies show that A2PSGD outperforms existing optimization algorithms for HDS data LR in both accuracy and training time.
| Subjects: | Machine Learning (cs.LG); Distributed, Parallel, and Cluster Computing (cs.DC) |
| Cite as: | [cs.LG] |
| (or [cs.LG] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite |
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
IMAGES
VIDEO
COMMENTS
A computer uses a fixed number of bits to represent a piece of data which could be a number, a character, image, sound, video, etc. Data representation is the method used internally to represent data in a computer. Let us see how various types of data can be represented in computer memory. Before discussing data representation of numbers, let ...
Representation of Data/Information. Computers do not understand human language; they understand data within the prescribed form. Data representation is a method to represent data and encode it in a computer system. Generally, a user inputs numbers, text, images, audio, and video etc types of data to process but the computer converts this data ...
We also cover the basics of digital circuits and logic gates, and explain how they are used to represent and process data in computer systems. Our guide includes real-world examples and case studies to help you master data representation principles and prepare for your computer science exams. Check out the links below:
Data Representation • The 0s and 1s used to represent digital data are referred to as binary digits — from this term we get the word bit that stands for bi nary digi t. • A bit is a 0 or 1 used in the digital representation of data. • A digital file, usually referred to simply as a file, is a named collection of data that exits on
This is a hexadecimal (base-16) number indicating the value of the address of the object. A line contains one to sixteen bytes of memory starting at this address. The contents of memory starting at the given address, such as 3d 00 00 00. Memory is printed as a sequence of bytes, which are 8-bit numbers between 0 and 255.
2. add_item(): This method processes the inventory by adding an item. Again, we're manipulating the data within the GameCharacter object. 3. use_ability(): This method randomly selects an ability from the character's list of abilities and "uses" it. This is another example of data processing.
Signed Integers: 2's Complement Form. For non-negative integers, represent the value in base-2, using up to n - 1 bits, and pad to. 32 bits with leading 0's: 42: 101010 --> 0010 1010. For negative integers, take the base-2 representation of the value (ignoring the sign) pad with 0's to n - 1 bits, invert the bits and add 1: -42: 101010 ...
Data representation. Computers use binary - the digits 0 and 1 - to store data. A binary digit, or bit, is the smallest unit of data in computing. It is represented by a 0 or a 1. Binary numbers are made up of binary digits (bits), eg the binary number 1001. The circuits in a computer's processor are made up of billions of transistors.
Over 5,000 teachers have signed up to use our materials in their classroom. In short: everything you need to teach GCSE, KS3 & A-Level Computer Science: Data Representation Theory Notes & Resources. Topics include binary, decimal, and hexadecimal numbers, and the conversions between them. Perfect for Computer Science teachers.
The Processor Fundamentals section goes further to discuss how the processor uses the fundamentals of machine language and the Communication representation section it discusses how data is transferred from one machine to another. Introducing data representation for computer science students: Our comprehensive guide covers binary, BCD, negative ...
COMP2401 - Chapter 2 - Data Representation Fall 2020 - 44 - 2.1 Number Representation and Bit Models All data stored in a computer must somehow be represented numerically in some way whether it is numerical to begin with, a series of characters or an image. Ultimately, everything digitally breaks down to ones and zeros.
This general procedure is used to represent a multi-byte integer in memory. Write the large integer in hexadecimal format, including all leading zeros required by the type size. For example, the unsigned value 65534 would be written 0x0000FFFE. There will be twice as many hexadecimal digits as sizeof (TYPE).
Applications of Data Representation with 8 Bits in a Byte Use of 8 Bits in a Byte in Computer Systems. From processing instructions to storing images and text, the humble 8-bit byte plays a crucial role in the inner workings of computer systems. It's like the unsung hero silently powering our digital world behind the scenes.
Computer Memory & Data Representation. Computer uses a fixed number of bits to represent a piece of data, which could be a number, a character, ... EBCDIC (Extended Binary Coded Decimal Interchange Code): Used in the early IBM computers. Unicode (aka ISO/IEC 10646 Universal Character Set)
Data Representation Alexander Nelson September 16, 2019 University of Arkansas - Department of Computer Science and Computer Engineering. ... Byte Representation Computer Architectures started to use 8-bit bytes as the basic storage size Popularized by 1970s microprocessors (Intell 8008, predecessor of
DATA REPRESENTATION In computing, a single character such as a letter, a number or a symbol is represented by a group of bits. The number of bits per character depends on the coding scheme used. Data representation is the use of codes understood by the computer hardware and software to
Data Representation. ( 1 user ) Digital computers store and process information in binary form as digital logic has only two values "1" and "0" or in other words "True or False" or also said as "ON or OFF". This system is called radix 2. We human generally deal with radix 10 i.e. decimal.
How do computers store and process information? In this article, you will learn about the basic units of digital data, such as bits and bytes, and how they are used to represent different types of information. This is a foundational topic for anyone who wants to learn about computer science and programming. Khan Academy is a free online platform that offers courses in various subjects for ...
6. Histogram. A histogram is the graphical representation of data. It is similar to the appearance of a bar graph but there is a lot of difference between histogram and bar graph because a bar graph helps to measure the frequency of categorical data.
Data Representation in Computer Organization. In computer organization, data refers to the symbols that are used to represent events, people, things and ideas. Data Representation. The data can be represented in the following ways: Data. Data can be anything like a number, a name, notes in a musical composition, or the color in a photograph ...
So, we'd want to represent -1 as: -1: 1111 1111 1111 1111. 2's Complement Observations. To negate an integer, with one exception*, just invert the bits and add 1. 25985: 0110 0101 1000 0001. -25985: 1001 1010 0111 1111. --25985: 0110 0101 1000 0001. The sign of the integer is indicated by the leading bit.
File extensions: .doc, .docx, .pdf, .txt, etc. For example: Word: H. Unicode representation: U+0048. 2. Numerical data. Numbers are directly converted into binary patterns by dividing by 2 without any encoding. The numbers we want to transfer generally will be of the decimal number system- ( ) 10.
The terms bits, bytes, nibble and word are used widely in reference to computer memory and data size. Bits: can be defined as either a binary, which can be 0, or 1.It is the basic unit of data or information in digital computers. Byte: a group of bits (8 bits) used to represent a character.
By summarizing the code representation, the redundancy in the code is removed and the inconsistency between code and query statements is alleviated. For the explicit code representation summarization-based strategy, different views of contextual information are obtained and summarized based on different scales of pyramidal dilated convolution ...
Hallucination is a common issue in Multimodal Large Language Models (MLLMs), yet the underlying principles remain poorly understood. In this paper, we investigate which components of MLLMs contribute to object hallucinations. To analyze image representations while completely avoiding the influence of all other factors other than the image representation itself, we propose a parametric-free ...
Data characterized by high dimensionality and sparsity are commonly used to describe real-world node interactions. Low-rank representation (LR) can map high-dimensional sparse (HDS) data to low-dimensional feature spaces and infer node interactions via modeling data latent associations. Unfortunately, existing optimization algorithms for LR models are computationally inefficient and slowly ...