| b. | | *He sometimes to the cafe. | We can easily imagine a tagset in which the four distinct grammatical forms just discussed were all tagged as VB . Although this would be adequate for some purposes, a more fine-grained tagset provides useful information about these forms that can help other processors that try to detect patterns in tag sequences. The Brown tagset captures these distinctions, as summarized in 7.1 . | Form | Category | Tag |
|---|
| go | base | VB | | goes | 3rd singular present | VBZ | | gone | past participle | VBN | | going | gerund | VBG | | went | simple past | VBD | Table 7.1: Some morphosyntactic distinctions in the Brown tagset In addition to this set of verb tags, the various forms of the verb to be have special tags: be/BE, being/BEG, am/BEM, are/BER, is /BEZ, been/BEN, were/BED and was/BEDZ (plus extra tags for negative forms of the verb). All told, this fine-grained tagging of verbs means that an automatic tagger that uses this tagset is effectively carrying out a limited amount of morphological analysis . Most part-of-speech tagsets make use of the same basic categories, such as noun, verb, adjective, and preposition. However, tagsets differ both in how finely they divide words into categories, and in how they define their categories. For example, is might be tagged simply as a verb in one tagset; but as a distinct form of the lexeme be in another tagset (as in the Brown Corpus). This variation in tagsets is unavoidable, since part-of-speech tags are used in different ways for different tasks. In other words, there is no one 'right way' to assign tags, only more or less useful ways depending on one's goals. 8 Summary- Words can be grouped into classes, such as nouns, verbs, adjectives, and adverbs. These classes are known as lexical categories or parts of speech. Parts of speech are assigned short labels, or tags, such as NN , VB ,
- The process of automatically assigning parts of speech to words in text is called part-of-speech tagging, POS tagging, or just tagging.
- Automatic tagging is an important step in the NLP pipeline, and is useful in a variety of situations including: predicting the behavior of previously unseen words, analyzing word usage in corpora, and text-to-speech systems.
- Some linguistic corpora, such as the Brown Corpus, have been POS tagged.
- A variety of tagging methods are possible, e.g. default tagger, regular expression tagger, unigram tagger and n-gram taggers. These can be combined using a technique known as backoff.
- Taggers can be trained and evaluated using tagged corpora.
- Backoff is a method for combining models: when a more specialized model (such as a bigram tagger) cannot assign a tag in a given context, we backoff to a more general model (such as a unigram tagger).
- Part-of-speech tagging is an important, early example of a sequence classification task in NLP: a classification decision at any one point in the sequence makes use of words and tags in the local context.
- A dictionary is used to map between arbitrary types of information, such as a string and a number: freq[ 'cat' ] = 12 . We create dictionaries using the brace notation: pos = {} , pos = { 'furiously' : 'adv' , 'ideas' : 'n' , 'colorless' : 'adj' } .
- N-gram taggers can be defined for large values of n , but once n is larger than 3 we usually encounter the sparse data problem; even with a large quantity of training data we only see a tiny fraction of possible contexts.
- Transformation-based tagging involves learning a series of repair rules of the form "change tag s to tag t in context c ", where each rule fixes mistakes and possibly introduces a (smaller) number of errors.
9 Further ReadingExtra materials for this chapter are posted at http://nltk.org/ , including links to freely available resources on the web. For more examples of tagging with NLTK, please see the Tagging HOWTO at http://nltk.org/howto . Chapters 4 and 5 of (Jurafsky & Martin, 2008) contain more advanced material on n-grams and part-of-speech tagging. The "Universal Tagset" is described by (Petrov, Das, & McDonald, 2012) . Other approaches to tagging involve machine learning methods ( chap-data-intensive ). In 7. we will see a generalization of tagging called chunking in which a contiguous sequence of words is assigned a single tag. For tagset documentation, see nltk.help.upenn_tagset() and nltk.help.brown_tagset() . Lexical categories are introduced in linguistics textbooks, including those listed in 1. . There are many other kinds of tagging. Words can be tagged with directives to a speech synthesizer, indicating which words should be emphasized. Words can be tagged with sense numbers, indicating which sense of the word was used. Words can also be tagged with morphological features. Examples of each of these kinds of tags are shown below. For space reasons, we only show the tag for a single word. Note also that the first two examples use XML-style tags, where elements in angle brackets enclose the word that is tagged. - Speech Synthesis Markup Language (W3C SSML): That is a <emphasis>big</emphasis> car!
- SemCor: Brown Corpus tagged with WordNet senses: Space in any <wf pos= "NN" lemma= "form" wnsn= "4" >form</wf> is completely measured by the three dimensions. (Wordnet form/nn sense 4: "shape, form, configuration, contour, conformation")
- Morphological tagging, from the Turin University Italian Treebank: E ' italiano , come progetto e realizzazione , il primo (PRIMO ADJ ORDIN M SING) porto turistico dell' Albania .
Note that tagging is also performed at higher levels. Here is an example of dialogue act tagging, from the NPS Chat Corpus (Forsyth & Martell, 2007) included with NLTK. Each turn of the dialogue is categorized as to its communicative function: 10 Exercises- ☼ Search the web for "spoof newspaper headlines", to find such gems as: British Left Waffles on Falkland Islands , and Juvenile Court to Try Shooting Defendant . Manually tag these headlines to see if knowledge of the part-of-speech tags removes the ambiguity.
- ☼ Working with someone else, take turns to pick a word that can be either a noun or a verb (e.g. contest ); the opponent has to predict which one is likely to be the most frequent in the Brown corpus; check the opponent's prediction, and tally the score over several turns.
- ☼ Tokenize and tag the following sentence: They wind back the clock, while we chase after the wind . What different pronunciations and parts of speech are involved?
- ☼ Review the mappings in 3.1 . Discuss any other examples of mappings you can think of. What type of information do they map from and to?
- ☼ Using the Python interpreter in interactive mode, experiment with the dictionary examples in this chapter. Create a dictionary d , and add some entries. What happens if you try to access a non-existent entry, e.g. d[ 'xyz' ] ?
- ☼ Try deleting an element from a dictionary d , using the syntax del d[ 'abc' ] . Check that the item was deleted.
- ☼ Create two dictionaries, d1 and d2 , and add some entries to each. Now issue the command d1.update(d2) . What did this do? What might it be useful for?
- ☼ Create a dictionary e , to represent a single lexical entry for some word of your choice. Define keys like headword , part-of-speech , sense , and example , and assign them suitable values.
- ☼ Satisfy yourself that there are restrictions on the distribution of go and went , in the sense that they cannot be freely interchanged in the kinds of contexts illustrated in (3d) in 7 .
- ☼ Train a unigram tagger and run it on some new text. Observe that some words are not assigned a tag. Why not?
- ☼ Learn about the affix tagger (type help(nltk.AffixTagger) ). Train an affix tagger and run it on some new text. Experiment with different settings for the affix length and the minimum word length. Discuss your findings.
- ☼ Train a bigram tagger with no backoff tagger, and run it on some of the training data. Next, run it on some new data. What happens to the performance of the tagger? Why?
- ☼ We can use a dictionary to specify the values to be substituted into a formatting string. Read Python's library documentation for formatting strings http://docs.python.org/lib/typesseq-strings.html and use this method to display today's date in two different formats.
- ◑ Use sorted() and set() to get a sorted list of tags used in the Brown corpus, removing duplicates.
- Which nouns are more common in their plural form, rather than their singular form? (Only consider regular plurals, formed with the -s suffix.)
- Which word has the greatest number of distinct tags. What are they, and what do they represent?
- List tags in order of decreasing frequency. What do the 20 most frequent tags represent?
- Which tags are nouns most commonly found after? What do these tags represent?
- What happens to the tagger performance for the various model sizes when a backoff tagger is omitted?
- Consider the curve in 4.2 ; suggest a good size for a lookup tagger that balances memory and performance. Can you come up with scenarios where it would be preferable to minimize memory usage, or to maximize performance with no regard for memory usage?
- ◑ What is the upper limit of performance for a lookup tagger, assuming no limit to the size of its table? (Hint: write a program to work out what percentage of tokens of a word are assigned the most likely tag for that word, on average.)
- What proportion of word types are always assigned the same part-of-speech tag?
- How many words are ambiguous, in the sense that they appear with at least two tags?
- What percentage of word tokens in the Brown Corpus involve these ambiguous words?
- A tagger t takes a list of words as input, and produces a list of tagged words as output. However, t.evaluate() is given correctly tagged text as its only parameter. What must it do with this input before performing the tagging?
- Once the tagger has created newly tagged text, how might the evaluate() method go about comparing it with the original tagged text and computing the accuracy score?
- Now examine the source code to see how the method is implemented. Inspect nltk.tag.api.__file__ to discover the location of the source code, and open this file using an editor (be sure to use the api.py file and not the compiled api.pyc binary file).
- Produce an alphabetically sorted list of the distinct words tagged as MD .
- Identify words that can be plural nouns or third person singular verbs (e.g. deals , flies ).
- Identify three-word prepositional phrases of the form IN + DET + NN (eg. in the lab ).
- What is the ratio of masculine to feminine pronouns?
- ◑ In 3.1 we saw a table involving frequency counts for the verbs adore , love , like , prefer and preceding qualifiers absolutely and definitely . Investigate the full range of adverbs that appear before these four verbs.
- ◑ We defined the regexp_tagger that can be used as a fall-back tagger for unknown words. This tagger only checks for cardinal numbers. By testing for particular prefix or suffix strings, it should be possible to guess other tags. For example, we could tag any word that ends with -s as a plural noun. Define a regular expression tagger (using RegexpTagger() ) that tests for at least five other patterns in the spelling of words. (Use inline documentation to explain the rules.)
- ◑ Consider the regular expression tagger developed in the exercises in the previous section. Evaluate the tagger using its accuracy() method, and try to come up with ways to improve its performance. Discuss your findings. How does objective evaluation help in the development process?
- ◑ How serious is the sparse data problem? Investigate the performance of n-gram taggers as n increases from 1 to 6. Tabulate the accuracy score. Estimate the training data required for these taggers, assuming a vocabulary size of 10 5 and a tagset size of 10 2 .
- ◑ Obtain some tagged data for another language, and train and evaluate a variety of taggers on it. If the language is morphologically complex, or if there are any orthographic clues (e.g. capitalization) to word classes, consider developing a regular expression tagger for it (ordered after the unigram tagger, and before the default tagger). How does the accuracy of your tagger(s) compare with the same taggers run on English data? Discuss any issues you encounter in applying these methods to the language.
- ◑ 4.1 plotted a curve showing change in the performance of a lookup tagger as the model size was increased. Plot the performance curve for a unigram tagger, as the amount of training data is varied.
- ◑ Inspect the confusion matrix for the bigram tagger t2 defined in 5 , and identify one or more sets of tags to collapse. Define a dictionary to do the mapping, and evaluate the tagger on the simplified data.
- ◑ Experiment with taggers using the simplified tagset (or make one of your own by discarding all but the first character of each tag name). Such a tagger has fewer distinctions to make, but much less information on which to base its work. Discuss your findings.
- ◑ Recall the example of a bigram tagger which encountered a word it hadn't seen during training, and tagged the rest of the sentence as None . It is possible for a bigram tagger to fail part way through a sentence even if it contains no unseen words (even if the sentence was used during training). In what circumstance can this happen? Can you write a program to find some examples of this?
- ◑ Preprocess the Brown News data by replacing low frequency words with UNK , but leaving the tags untouched. Now train and evaluate a bigram tagger on this data. How much does this help? What is the contribution of the unigram tagger and default tagger now?
- ◑ Modify the program in 4.1 to use a logarithmic scale on the x -axis, by replacing pylab.plot() with pylab.semilogx() . What do you notice about the shape of the resulting plot? Does the gradient tell you anything?
- ◑ Consult the documentation for the Brill tagger demo function, using help(nltk.tag.brill.demo) . Experiment with the tagger by setting different values for the parameters. Is there any trade-off between training time (corpus size) and performance?
- ◑ Write code that builds a dictionary of dictionaries of sets. Use it to store the set of POS tags that can follow a given word having a given POS tag, i.e. word i → tag i → tag i+1 .
- Print a table with the integers 1..10 in one column, and the number of distinct words in the corpus having 1..10 distinct tags in the other column.
- For the word with the greatest number of distinct tags, print out sentences from the corpus containing the word, one for each possible tag.
- ★ Write a program to classify contexts involving the word must according to the tag of the following word. Can this be used to discriminate between the epistemic and deontic uses of must ?
- Create three different combinations of the taggers. Test the accuracy of each combined tagger. Which combination works best?
- Try varying the size of the training corpus. How does it affect your results?
- Create a new kind of unigram tagger that looks at the tag of the previous word, and ignores the current word. (The best way to do this is to modify the source code for UnigramTagger() , which presumes knowledge of object-oriented programming in Python.)
- Add this tagger to the sequence of backoff taggers (including ordinary trigram and bigram taggers that look at words), right before the usual default tagger.
- Evaluate the contribution of this new unigram tagger.
- ★ Consider the code in 5 which determines the upper bound for accuracy of a trigram tagger. Review Abney's discussion concerning the impossibility of exact tagging (Church, Young, & Bloothooft, 1996) . Explain why correct tagging of these examples requires access to other kinds of information than just words and tags. How might you estimate the scale of this problem?
- ★ Use some of the estimation techniques in nltk.probability , such as Lidstone or Laplace estimation, to develop a statistical tagger that does a better job than n-gram backoff taggers in cases where contexts encountered during testing were not seen during training.
- ★ Inspect the diagnostic files created by the Brill tagger rules.out and errors.out . Obtain the demonstration code by accessing the source code (at http://www.nltk.org/code ) and create your own version of the Brill tagger. Delete some of the rule templates, based on what you learned from inspecting rules.out . Add some new rule templates which employ contexts that might help to correct the errors you saw in errors.out .
- ★ Develop an n-gram backoff tagger that permits "anti-n-grams" such as [ "the" , "the" ] to be specified when a tagger is initialized. An anti-ngram is assigned a count of zero and is used to prevent backoff for this n-gram (e.g. to avoid estimating P( the | the ) as just P( the )).
- ★ Investigate three different ways to define the split between training and testing data when developing a tagger using the Brown Corpus: genre ( category ), source ( fileid ), and sentence. Compare their relative performance and discuss which method is the most legitimate. (You might use n-fold cross validation, discussed in 3 , to improve the accuracy of the evaluations.)
- ★ Develop your own NgramTagger class that inherits from NLTK's class, and which encapsulates the method of collapsing the vocabulary of the tagged training and testing data that was described in this chapter. Make sure that the unigram and default backoff taggers have access to the full vocabulary.
About this document... UPDATED FOR NLTK 3.0. This is a chapter from Natural Language Processing with Python , by Steven Bird , Ewan Klein and Edward Loper , Copyright © 2019 the authors. It is distributed with the Natural Language Toolkit [ http://nltk.org/ ], Version 3.0, under the terms of the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [ http://creativecommons.org/licenses/by-nc-nd/3.0/us/ ]. This document was built on Wed 4 Sep 2019 11:40:48 ACST  Part-of-speech tagging in NLP (with Python Examples)April 18, 2023  Part-of-speech (POS) tagging is a process that assigns a part of speech (noun, verb, adjective, etc.) to each word in a given text. This technique is used to understand the role of words in a sentence and is a critical component of many natural language processing (NLP) applications. In this article, we will explore the basics of POS tagging, its importance, and the techniques and tools used for it.  What is POS tagging?POS tagging is a process of labeling each word in a text with its corresponding part of speech. The goal is to assign the correct POS tag to each word based on its context. For example, in the sentence “The cat is sleeping,” the word “cat” is a noun, “is” is a verb, and “sleeping” is an adjective. POS tagging allows us to identify these roles and understand the meaning of the sentence. Getting StartedFor this Part-of-speech tagging tutorial, you will need to install Python along with the most popular natural language processing libraries used in this guide. Open the Terminal and type (might take a while to run): Understand POS Visually with PythonThis code will output the part-of-speech tagging and dependency parsing results for the text “Barack Obama was born in Hawaii”, using the pre-trained English model in Spacy. The first loop will print out each token in the text along with its part-of-speech tag, detailed part-of-speech tag, dependency relation and the head of the current token. The second part of the code will visualize the dependency parsing results in the text using the displacy module, which will display an interactive visualization of the syntactic dependencies between words in the sentence. The visualization will be rendered in the Jupyter notebook.  Importance of POS taggingPOS tagging is essential for various NLP tasks, including text-to-speech conversion, sentiment analysis , and machine translation. It helps in disambiguating the meaning of words in a sentence by identifying the context and their respective parts of speech. Accurate POS tagging can improve the accuracy of NLP models, leading to better results in many applications. Techniques for POS taggingThere are several techniques for POS tagging, including rule-based approaches, stochastic models, and deep learning . Rule-based approaches use hand-crafted rules to assign POS tags based on the word’s context, such as its surrounding words and the sentence structure. Stochastic models use probability distributions to predict the most likely POS tag for each word based on training data. Deep learning approaches, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), can learn the context and relationships between words to predict POS tags. Tools for POS taggingThere are several Python libraries available for POS tagging, including NLTK, spaCy, and TextBlob. NLTK provides several algorithms for POS tagging, including rule-based and stochastic models. spaCy uses a combination of rule-based and deep learning techniques for POS tagging, providing fast and accurate results. TextBlob is a simpler library that provides an easy-to-use interface for POS tagging and other NLP tasks. Challenges of POS taggingPOS tagging is a complex task that requires dealing with the ambiguity of natural language. Words can have multiple meanings, and their parts of speech can change depending on the context. In addition, some languages, such as Chinese and Japanese, do not have spaces between words, making it difficult to identify word boundaries. POS tagging also requires large amounts of annotated training data to achieve high accuracy . Useful Python Libraries for Part-of-speech tagging- NLTK: pos_tag()
- Spacy: pos_tag()
- TextBlob: tags, noun_phrases()
POS Tagging in NLTKVisualize Part-of-Speech Tagging.  If you don’t know what these tags mean, here is a full list of Part-of-speech tags in NLTK. POS Tagging in SpaCyIf you don’t know what these tags mean, here is a full list of Part-of-speech tags in spaCy. POS Tagging in TextBlobIn this example, we create a TextBlob object containing the text to be tagged, and then call the tags property on the TextBlob object to perform POS tagging. The resulting tags variable contains a list of tuples, where each tuple contains a word and its corresponding POS tag. Finally, we print out the tags for each word in the text using a for loop. The output will be something like:  If you don’t know what these tags mean, here is a full list of Part-of-speech tags in TextBlob. Datasets useful for Part-of-speech taggingPenn treebank, universal dependencies, to know before you learn part-of-speech tagging. - Basic understanding of machine learning algorithms
- Familiarity with Python programming language
- Knowledge of text pre-processing techniques such as tokenization and stemming
- Understanding of parts of speech and their roles in a sentence.
Important Concepts in Part-of-speech tagging- Language grammar rules
- POS tag sets and their definitions
- The ambiguity problem in POS tagging
- The role of machine learning in POS tagging
- Commonly used POS tagging algorithms
What’s Next?- Named Entity Recognition (NER)
- Chunking and Shallow Parsing
- Dependency Parsing
- Natural Language Understanding (NLU)
- Sentiment Analysis
- Text Classification
Relevant Entities| Entity | Properties |
|---|
| Text | Sequence of words to be tagged with parts of speech | | Part-of-speech tag | Label assigned to a word indicating its grammatical category | | Tagset | A collection of part-of-speech tags | | Corpus | A large collection of text used for training and evaluating POS taggers | | Tokenization | The process of breaking a text into words or tokens |
Frequently Asked QuestionsIdentification of word type Improve text understanding Noun, verb, adjective Improved accuracy Different objectives Ambiguity, context In conclusion, POS tagging is a crucial component of NLP applications that helps in identifying the role of words in a sentence. It allows us to disambiguate the meaning of words and understand the context of a text. There are several techniques and tools available for POS tagging, each with its strengths and weaknesses. While POS tagging can be challenging, accurate results can significantly improve the performance of NLP models. - NLTK documentation on Part-of-speech tagging: https://www.nltk.org/book/ch05.html
- spaCy documentation on Part-of-speech tagging: https://spacy.io/usage/linguistic-features#pos-tagging
- Stanford CoreNLP documentation on Part-of-speech tagging: https://stanfordnlp.github.io/CoreNLP/pos.html
- Part-of-speech tagging with Hidden Markov Models in Python: https://towardsdatascience.com/part-of-speech-tagging-with-hidden-markov-models-python-for-language-processing-56c9a0ab07d9
- A Comprehensive Guide to Part-of-speech Tagging: https://www.analyticsvidhya.com/blog/2021/05/a-comprehensive-guide-to-part-of-speech-tagging/
Related posts:SpaCy Part-of-Speech Tags- Named Entity Recognition in NLP (with Python Examples)
- Word Embeddings in NLP (with Python Examples)
Natural Language Processing (NLP) with Python ExamplesPython for NLP: Parts of Speech Tagging and Named Entity Recognition This is the 4th article in my series of articles on Python for NLP. In my previous article , I explained how the spaCy library can be used to perform tasks like vocabulary and phrase matching. In this article, we will study parts of speech tagging and named entity recognition in detail. We will see how the spaCy library can be used to perform these two tasks. - Parts of Speech (POS) Tagging
Parts of speech tagging simply refers to assigning parts of speech to individual words in a sentence, which means that, unlike phrase matching, which is performed at the sentence or multi-word level, parts of speech tagging is performed at the token level. Let's take a very simple example of parts of speech tagging. As usual, in the script above we import the core spaCy English model. Next, we need to create a spaCy document that we will be using to perform parts of speech tagging. The spaCy document object has several attributes that can be used to perform a variety of tasks. For instance, to print the text of the document, the text attribute is used. Similarly, the pos_ attribute returns the coarse-grained POS tag. To obtain fine-grained POS tags, we could use the tag_ attribute. And finally, to get the explanation of a tag, we can use the spacy.explain() method and pass it the tag name. Let's see this in action: The above script simply prints the text of the sentence. The output looks like this: Next, let's see pos_ attribute. We will print the POS tag of the word "hated", which is actually the seventh token in the sentence. You can see that POS tag returned for "hated" is a "VERB" since "hated" is a verb. Now let's print the fine-grained POS tag for the word "hated". To see what VBD means, we can use spacy.explain() method as shown below: The output shows that VBD is a verb in the past tense. Let's print the text, coarse-grained POS tags, fine-grained POS tags, and the explanation for the tags for all the words in the sentence. In the script above we improve the readability and formatting by adding 12 spaces between the text and coarse-grained POS tag and then another 10 spaces between the coarse-grained POS tags and fine-grained POS tags. A complete tag list for the parts of speech and the fine-grained tags, along with their explanation, is available at spaCy official documentation. - Why POS Tagging is Useful?
POS tagging can be really useful, particularly if you have words or tokens that can have multiple POS tags. For instance, the word "google" can be used as both a noun and verb, depending upon the context. While processing natural language, it is important to identify this difference. Fortunately, the spaCy library comes pre-built with machine learning algorithms that, depending upon the context (surrounding words), it is capable of returning the correct POS tag for the word. Let's see this in action. Execute the following script: In the script above we create spaCy document with the text "Can you google it?" Here the word "google" is being used as a verb. Next, we print the POS tag for the word "google" along with the explanation of the tag. The output looks like this: From the output, you can see that the word "google" has been correctly identified as a verb. Let's now see another example: Here in the above script the word "google" is being used as a noun as shown by the output: - Finding the Number of POS Tags
You can find the number of occurrences of each POS tag by calling the count_by on the spaCy document object. The method takes spacy.attrs.POS as a parameter value. In the output, you can see the ID of the POS tags along with their frequencies of occurrence. The text of the POS tag can be displayed by passing the ID of the tag to the vocabulary of the actual spaCy document. Now in the output, you will see the ID, the text, and the frequency of each tag as shown below: - Visualizing Parts of Speech Tags
Visualizing POS tags in a graphical way is extremely easy. The displacy module from the spacy library is used for this purpose. To visualize the POS tags inside the Jupyter notebook, you need to call the render method from the displacy module and pass it the spacy document, the style of the visualization, and set the jupyter attribute to True as shown below: Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it! In the output, you should see the following dependency tree for POS tags.  You can clearly see the dependency of each token on another along with the POS tag. If you want to visualize the POS tags outside the Jupyter notebook, then you need to call the serve method. The plot for POS tags will be printed in the HTML form inside your default browser. Execute the following script: Once you execute the above script, you will see the following message: To view the dependency tree, type the following address in your browser: http://127.0.0.1:5000/ . You will see the following dependency tree:  Named entity recognition refers to the identification of words in a sentence as an entity e.g. the name of a person, place, organization, etc. Let's see how the spaCy library performs named entity recognition. Look at the following script: In the script above we created a simple spaCy document with some text. To find the named entity we can use the ents attribute, which returns the list of all the named entities in the document. You can see that three named entities were identified. To see the detail of each named entity, you can use the text , label , and the spacy.explain method which takes the entity object as a parameter. In the output, you will see the name of the entity along with the entity type and a small description of the entity as shown below: You can see that "Manchester United" has been correctly identified as an organization, company, etc. Similarly, "Harry Kane" has been identified as a person and finally, "$90 million" has been correctly identified as an entity of type Money. You can also add new entities to an existing document. For instance in the following example, "Nesfruita" is not identified as a company by the spaCy library. From the output, you can see that only India has been identified as an entity. Now to add "Nesfruita" as an entity of type "ORG" to our document, we need to execute the following steps: First, we need to import the Span class from the spacy.tokens module. Next, we need to get the hash value of the ORG entity type from our document. After that, we need to assign the hash value of ORG to the span. Since "Nesfruita" is the first word in the document, the span is 0-1. Finally, we need to add the new entity span to the list of entities. Now if you execute the following script, you will see "Nesfruita" in the list of entities. The output of the script above looks like this: In the case of POS tags, we could count the frequency of each POS tag in a document using a special method sen.count_by . However, for named entities, no such method exists. We can manually count the frequency of each entity type. Suppose we have the following document along with its entities: To count the person type entities in the above document, we can use the following script: In the output, you will see 2 since there are 2 entities of type PERSON in the document. - Visualizing Named Entities
Like the POS tags, we can also view named entities inside the Jupyter notebook as well as in the browser. To do so, we will again use the displacy object. Look at the following example: You can see that the only difference between visualizing named entities and POS tags is that here in case of named entities we passed ent as the value for the style parameter. The output of the script above looks like this:  You can see from the output that the named entities have been highlighted in different colors along with their entity types. You can also filter which entity types to display. To do so, you need to pass the type of the entities to display in a list, which is then passed as a value to the ents key of a dictionary. The dictionary is then passed to the options parameter of the render method of the displacy module as shown below: In the script above, we specified that only the entities of type ORG should be displayed in the output. The output of the script above looks like this:  Finally, you can also display named entities outside the Jupyter notebook. The following script will display the named entities in your default browser. Execute the following script: Now if you go to the address http://127.0.0.1:5000/ in your browser, you should see the named entities. Parts of speech tagging and named entity recognition are crucial to the success of any NLP task. In this article, we saw how Python's spaCy library can be used to perform POS tagging and named entity recognition with the help of different examples. You might also like...- Python for NLP: Tokenization, Stemming, and Lemmatization with SpaCy Library
- Python for NLP: Vocabulary and Phrase Matching with SpaCy
- Simple NLP in Python with TextBlob: N-Grams Detection
- Sentiment Analysis in Python With TextBlob
- Python for NLP: Creating Bag of Words Model from Scratch
Improve your dev skills!Get tutorials, guides, and dev jobs in your inbox. No spam ever. Unsubscribe at any time. Read our Privacy Policy. Programmer | Blogger | Data Science Enthusiast | PhD To Be | Arsenal FC for Life In this article Monitor with Ping BotReliable monitoring for your app, databases, infrastructure, and the vendors they rely on. Ping Bot is a powerful uptime and performance monitoring tool that helps notify you and resolve issues before they affect your customers.  Vendor Alerts with Ping BotGet detailed incident alerts about the status of your favorite vendors. Don't learn about downtime from your customers, be the first to know with Ping Bot.  © 2013- 2024 Stack Abuse. All rights reserved.  Document text extractionOnline Tool To Extract Text From PDFs & Images nlp consultingBuilding Advanced Natural Language Processing (NLP) Applications API & custom applicationsCustom Machine Learning Models Extract Just What You Need AI for legal documentsThe Doc Hawk, Our Custom Application For Legal Documents log in to extract Natural Language ProcessingMachine learning, deep learning, neural networks, large language models, pre-processing, optimisation, learning types, part-of-speech (pos) tagging in nlp: 4 python how to tutorials. by Neri Van Otten | Jan 24, 2023 | Data Science , Natural Language Processing What is Part-of-speech (POS) tagging?Part-of-speech (POS) tagging is fundamental in natural language processing (NLP) and can be done in Python. It involves labelling words in a sentence with their corresponding POS tags. POS tags indicate the grammatical category of a word, such as noun, verb, adjective, adverb, etc. The goal of POS tagging is to determine a sentence’s syntactic structure and identify each word’s role in the sentence. Table of Contents There are two main types of POS tagging in NLP, and several Python libraries can be used for POS tagging, including NLTK, spaCy, and TextBlob. This article discusses the different types of POS taggers, the advantages and disadvantages of each, and provides code examples for the three most commonly used libraries in Python.  Several libraries do POS tagging in Python. Types of Part-of-speech (POS) tagging in NLPThere are two main types of part-of-speech (POS) tagging in natural language processing (NLP): - Rule-based POS tagging uses a set of linguistic rules and patterns to assign POS tags to words in a sentence. This method relies on a predefined set of grammatical rules, a dictionary of words, and their POS tags. The NLTK library’s pos_tag() function is an example of a rule-based POS tagger that uses the Penn Treebank POS tag set.
- Statistical POS tagging uses machine learning algorithms, such as Hidden Markov Models (HMM) or Conditional Random Fields (CRF), to predict POS tags based on the context of the words in a sentence. This method requires a large amount of training data to create models. The SpaCy library’s POS tagger is an example of a statistical POS tagger that uses a neural network-based model trained on the OntoNotes 5 corpus .
Both rule-based and statistical POS tagging have their advantages and disadvantages. Rule-based taggers are simpler to implement and understand but less accurate than statistical taggers. Statistical taggers, however, are more accurate but require a large amount of training data and computational resources. Advantages and disadvantages of the different types of Part-of-speech (POS) tagging for NLP in PythonRule-based part-of-speech (POS) taggers and statistical POS taggers are two different approaches to POS tagging in natural language processing (NLP). Each method has its advantages and disadvantages. The benefits of rule-based Part-of-speech (POS) tagging:- Simple to implement and understand
- It doesn’t require a lot of computational resources or training data
- It can be easily customized to specific domains or languages
Disadvantages of rule-based Part-of-speech (POS) tagging:- Less accurate than statistical taggers
- Limited by the quality and coverage of the rules
- It can be difficult to maintain and update
The Benefits of Statistical Part-of-speech (POS) Tagging:- More accurate than rule-based taggers
- Don’t require a lot of human-written rules
- Can learn from large amounts of training data
Disadvantages of statistical Part-of-speech (POS) Tagging:- Requires more computational resources and training data
- It can be difficult to interpret and debug
- Can be sensitive to the quality and diversity of the training data
In general, for most of the real-world use cases, it’s recommended to use statistical POS taggers, which are more accurate and robust. However, in some cases, the rule-based POS tagger is still useful, for example, for small or specific domains where the training data is unavailable or for specific languages that are not well-supported by existing statistical models. Rule-based Part-of-speech (POS) tagging for NLP in Python code1. nltk part-of-speech (pos) tagging. One common way to perform POS tagging in Python using the NLTK library is to use the pos_tag() function, which uses the Penn Treebank POS tag set. For example: This will make a list of tuples, each with a word and the POS tag that goes with it. It’s also possible to use other POS taggers, like Stanford POS Tagger, or others with better performance, like SpaCy POS Tagger, but they require additional setup and processing. NLTK POS tagger abbreviationsHere is a list of the available abbreviations and their meaning. | Abbreviation | Meaning |
|---|
| CC | coordinating conjunction | | CD | cardinal digit | | DT | determiner | | EX | existential there | | FW | foreign word | | IN | preposition/subordinating conjunction | | JJ | This NLTK POS Tag is an adjective (large) | | JJR | adjective, comparative (larger) | | JJS | adjective, superlative (largest) | | LS | list market | | MD | modal (could, will) | | NN | noun, singular (cat, tree) | | NNS | noun plural (desks) | | NNP | proper noun, singular (sarah) | | NNPS | proper noun, plural (indians or americans) | | PDT | predeterminer (all, both, half) | | POS | possessive ending (parent\ ‘s) | | PRP | personal pronoun (hers, herself, him, himself) | | PRP$ | possessive pronoun (her, his, mine, my, our ) | | RB | adverb (occasionally, swiftly) | | RBR | adverb, comparative (greater) | | RBS | adverb, superlative (biggest) | | RP | particle (about) | | TO | infinite marker (to) | | UH | interjection (goodbye) | | VB | verb (ask) | | VBG | verb gerund (judging) | | VBD | verb past tense (pleaded) | | VBN | verb past participle (reunified) | | VBP | verb, present tense not 3rd person singular(wrap) | | VBZ | verb, present tense with 3rd person singular (bases) | | WDT | wh-determiner (that, what) | | WP | wh- pronoun (who) | | WRB | wh- adverb (how) |
2. TextBlob Part-of-speech (POS) taggingHere is an example of how to use the part-of-speech (POS) tagging functionality in the TextBlob library in Python: This will output a list of tuples, where each tuple contains a word and its corresponding POS tag, using the pattern-based POS tagger. TextBlob also can tag using a statistical POS tagger. To use the NLTK POS Tagger, you can pass pos_tagger attribute to TextBlob, like this: Keep in mind that when using the NLTK POS Tagger, the NLTK library needs to be installed and the pos tagger downloaded. TextBlob is a useful library for conveniently performing everyday NLP tasks, such as POS tagging, noun phrase extraction, sentiment analysis, etc. It is built on top of NLTK and provides a simple and easy-to-use API. Statistical Part-of-speech (POS) tagging for NLP in Python code3. spacy part-of-speech (pos) tagging. Here is an example of how to use the part-of-speech (POS) tagging functionality in the spaCy library in Python: This will output the token text and the POS tag for each token in the sentence: The spaCy library’s POS tagger is based on a statistical model trained on the OntoNotes 5 corpus, and it can tag the text with high accuracy. It also can tag other features, like lemma, dependency, ner, etc. Note that before running the code, you need to download the model you want to use, in this case, en_core_web_sm . You can do this by running !python -m spacy download en_core_web_sm on your command line. 4. NLTK Part-of-speech (POS) taggingThe Averaged Perceptron Tagger in NLTK is a statistical part-of-speech (POS) tagger that uses a machine learning algorithm called Averaged Perceptron. Here is an example of how to use it in Python: This will output a list of tuples, where each tuple contains a word and its corresponding POS tag, using the Averaged Perceptron Tagger You can see that the output tags are different from the previous example because the Averaged Perceptron Tagger uses the universal POS tagset, which is different from the Penn Treebank POS tagset. The averaged perceptron tagger is trained on a large corpus of text, which makes it more robust and accurate than the default rule-based tagger provided by NLTK. It also allows you to specify the tagset, which is the set of POS tags that can be used for tagging; in this case, it’s using the ‘universal’ tagset, which is a cross-lingual tagset, useful for many NLP tasks in Python. It’s important to note that the Averaged Perceptron Tagger requires loading the model before using it, which is why it’s necessary to download it using the nltk.download() function. In conclusion, part-of-speech (POS) tagging is essential in natural language processing (NLP) and can be easily implemented using Python. The process involves labelling words in a sentence with their corresponding POS tags. There are two main types of POS tagging: rule-based and statistical. Rule-based POS taggers use a set of linguistic rules and patterns to assign POS tags to words in a sentence. They are simple to implement and understand but less accurate than statistical taggers. The NLTK library’s pos_tag() function is an example of a rule-based POS tagger that uses the Penn Treebank POS tag set. Statistical POS taggers use machine learning algorithms, such as Hidden Markov Models (HMM) or Conditional Random Fields (CRF), to predict POS tags based on the context of the words in a sentence. They are more accurate but require much training data and computational resources. The SpaCy library’s POS tagger is an example of a statistical POS tagger that uses a neural network-based model trained on the OntoNotes 5 corpus. Both rule-based and statistical POS tagging have their advantages and disadvantages. Rule-based taggers are simpler to implement and understand but less accurate than statistical taggers. Statistical taggers, however, are more accurate but require a large amount of training data and computational resources. In general, for most of the real-world use cases, it’s recommended to use statistical POS taggers, which are more accurate and robust. About the Author Neri Van OttenNeri Van Otten is the founder of Spot Intelligence, a machine learning engineer with over 12 years of experience specialising in Natural Language Processing (NLP) and deep learning innovation. Dedicated to making your projects succeed.  Neri Van Otten is a machine learning and software engineer with over 12 years of Natural Language Processing (NLP) experience. Dedicated to making your projects succeed. Popular posts Top 7 Ways of Implementing Document & Text Similarity Top 10 Open Source Large Language Models (LLM) Top 8 Most Useful Anomaly Detection Algorithms For Time Series Self-attention Made Easy And How To Implement It Top 3 Easy Ways To Remove Stop Word In Python Connect with us Join the NLP CommunityStay Updated With Our Newsletter Recent Articles Precision And Recall In Machine Learning Made Simple: How To Handle The Trade-offWhat is Precision and Recall? When evaluating a classification model's performance, it's crucial to understand its effectiveness at making predictions. Two essential...  Confusion Matrix: A Beginners Guide & How To Tutorial In PythonWhat is a Confusion Matrix? A confusion matrix is a fundamental tool used in machine learning and statistics to evaluate the performance of a classification model. At...  Understand Ordinary Least Squares: How To Beginner’s Guide [Tutorials In Python, R & Excell]What is Ordinary Least Squares (OLS)? Ordinary Least Squares (OLS) is a fundamental technique in statistics and econometrics used to estimate the parameters of a linear...  METEOR Metric In NLP: How It Works & How To Tutorial In PythonWhat is the METEOR Score? The METEOR score, which stands for Metric for Evaluation of Translation with Explicit ORdering, is a metric designed to evaluate the text...  BERTScore – A Powerful NLP Evaluation Metric Explained & How To Tutorial In PythonWhat is BERTScore? BERTScore is an innovative evaluation metric in natural language processing (NLP) that leverages the power of BERT (Bidirectional Encoder...  Perplexity In NLP: Understand How To Evaluate LLMs [Practical Guide]Introduction to Perplexity in NLP In the rapidly evolving field of Natural Language Processing (NLP), evaluating the effectiveness of language models is crucial. One of...  BLEU Score In NLP: What Is It & How To Implement In PythonWhat is the BLEU Score in NLP? BLEU, Bilingual Evaluation Understudy, is a metric used to evaluate the quality of machine-generated text in NLP, most commonly in...  ROUGE Metric In NLP: Complete Guide & How To Tutorial In PythonWhat is the ROUGE Metric? ROUGE, which stands for Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics used to evaluate the quality of summaries and...  Normalised Discounted Cumulative Gain (NDCG): Complete How To GuideWhat is Normalised Discounted Cumulative Gain (NDCG)? Normalised Discounted Cumulative Gain (NDCG) is a popular evaluation metric used to measure the effectiveness of... Submit a Comment Cancel replyYour email address will not be published. Required fields are marked * Save my name, email, and website in this browser for the next time I comment. Submit Comment  2024 NLP Expert Trend PredictionsGet a FREE PDF with expert predictions for 2024. How will natural language processing (NLP) impact businesses? What can we expect from the state-of-the-art models? Find out this and more by subscribing* to our NLP newsletter. You have Successfully Subscribed!* Unsubscribe to our weekly newsletter at any time. We comply with GDPR and do not share your data. By subscribing you agree to our terms & conditions. - Interview Questions
- Free Courses
- Career Guide
Recommended AI Courses  MIT No Code AI and Machine Learning ProgramLearn Artificial Intelligence & Machine Learning from University of Texas. Get a completion certificate and grow your professional career.  AI and ML Program from UT AustinEnroll in the PG Program in AI and Machine Learning from University of Texas McCombs. Earn PG Certificate and and unlock new opportunities What is Part of Speech (POS) tagging?Techniques for pos tagging, pos tagging with hidden markov model, optimizing hmm with viterbi algorithm , implementation using python, part of speech (pos) tagging with hidden markov model.  Back in elementary school, we have learned the differences between the various parts of speech tags such as nouns, verbs, adjectives, and adverbs. Associating each word in a sentence with a proper POS (part of speech) is known as POS tagging or POS annotation. POS tags are also known as word classes, morphological classes, or lexical tags. Back in the days, the POS annotation was manually done by human annotators but being such a laborious task, today we have automatic tools that are capable of tagging each word with an appropriate POS tag within a context. Nowadays, manual annotation is typically used to annotate a small corpus to be used as training data for the development of a new automatic POS tagger. Annotating modern multi-billion-word corpora manually is unrealistic and automatic tagging is used instead. POS tags give a large amount of information about a word and its neighbors. Their applications can be found in various tasks such as information retrieval, parsing, Text to Speech (TTS) applications, information extraction, linguistic research for corpora. They are also used as an intermediate step for higher-level NLP tasks such as parsing, semantics analysis, translation, and many more, which makes POS tagging a necessary function for advanced NLP applications. In this, you will learn how to use POS tagging with the Hidden Makrow model. Alternatively, you can also follow this link to learn a simpler way to do POS tagging. If you want to learn NLP, do check out our Free Course on Natural Language Processing at Great Learning Academy . There are various techniques that can be used for POS tagging such as - Rule-based POS tagging : The rule-based POS tagging models apply a set of handwritten rules and use contextual information to assign POS tags to words. These rules are often known as context frame rules. One such rule might be: “If an ambiguous/unknown word ends with the suffix ‘ing’ and is preceded by a Verb, label it as a Verb”.
- Transformation Based Tagging: The transformation-based approaches use a pre-defined set of handcrafted rules as well as automatically induced rules that are generated during training.
- Deep learning models : Various Deep learning models have been used for POS tagging such as Meta-BiLSTM which have shown an impressive accuracy of around 97 percent.
- Stochastic (Probabilistic) tagging : A stochastic approach includes frequency, probability or statistics. The simplest stochastic approach finds out the most frequently used tag for a specific word in the annotated training data and uses this information to tag that word in the unannotated text. But sometimes this approach comes up with sequences of tags for sentences that are not acceptable according to the grammar rules of a language. One such approach is to calculate the probabilities of various tag sequences that are possible for a sentence and assign the POS tags from the sequence with the highest probability. Hidden Markov Models (HMMs) are probabilistic approaches to assign a POS Tag.
HMM (Hidden Markov Model) is a Stochastic technique for POS tagging. Hidden Markov models are known for their applications to reinforcement learning and temporal pattern recognition such as speech, handwriting, gesture recognition, musical score following, partial discharges, and bioinformatics. Let us consider an example proposed by Dr.Luis Serrano and find out how HMM selects an appropriate tag sequence for a sentence.  In this example, we consider only 3 POS tags that are noun, model and verb. Let the sentence “ Ted will spot Will ” be tagged as noun, model, verb and a noun and to calculate the probability associated with this particular sequence of tags we require their Transition probability and Emission probability. The transition probability is the likelihood of a particular sequence for example, how likely is that a noun is followed by a model and a model by a verb and a verb by a noun. This probability is known as Transition probability. It should be high for a particular sequence to be correct. Now, what is the probability that the word Ted is a noun, will is a model, spot is a verb and Will is a noun. These sets of probabilities are Emission probabilities and should be high for our tagging to be likely. Let us calculate the above two probabilities for the set of sentences below - Mary Jane can see Will
- Spot will see Mary
- Will Jane spot Mary?
- Mary will pat Spot
Note that Mary Jane, Spot, and Will are all names. 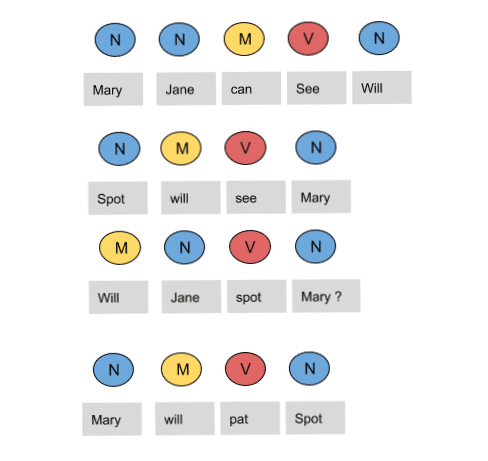 In the above sentences, the word Mary appears four times as a noun. To calculate the emission probabilities, let us create a counting table in a similar manner. | Words | Noun | Model | Verb | | Mary | 4 | 0 | 0 | | Jane | 2 | 0 | 0 | | Will | 1 | 3 | 0 | | Spot | 2 | 0 | 1 | | Can | 0 | 1 | 0 | | See | 0 | 0 | 2 | | pat | 0 | 0 | 1 |
Now let us divide each column by the total number of their appearances for example, ‘noun’ appears nine times in the above sentences so divide each term by 9 in the noun column. We get the following table after this operation. | Words | Noun | Model | Verb | | Mary | 4/9 | 0 | 0 | | Jane | 2/9 | 0 | 0 | | Will | 1/9 | 3/4 | 0 | | Spot | 2/9 | 0 | 1/4 | | Can | 0 | 1/4 | 0 | | See | 0 | 0 | 2/4 | | pat | 0 | 0 | 1 |
From the above table, we infer that The probability that Mary is Noun = 4/9 The probability that Mary is Model = 0 The probability that Will is Noun = 1/9 The probability that Will is Model = 3/4 In a similar manner, you can figure out the rest of the probabilities. These are the emission probabilities. Next, we have to calculate the transition probabilities, so define two more tags <S> and <E>. <S> is placed at the beginning of each sentence and <E> at the end as shown in the figure below.  Let us again create a table and fill it with the co-occurrence counts of the tags.
| N | M | V | <E> | | <S> | 3 | 1 | 0 | 0 | | N | 1 | 3 | 1 | 4 | | M | 1 | 0 | 3 | 0 | | V | 4 | 0 | 0 | 0 |
In the above figure, we can see that the <S> tag is followed by the N tag three times, thus the first entry is 3.The model tag follows the <S> just once, thus the second entry is 1. In a similar manner, the rest of the table is filled. Next, we divide each term in a row of the table by the total number of co-occurrences of the tag in consideration, for example, The Model tag is followed by any other tag four times as shown below, thus we divide each element in the third row by four. 
| N | M | V | <E> | | <S> | 3/4 | 1/4 | 0 | 0 | | N | 1/9 | 3/9 | 1/9 | 4/9 | | M | 1/4 | 0 | 3/4 | 0 | | V | 4/4 | 0 | 0 | 0 |
These are the respective transition probabilities for the above four sentences. Now how does the HMM determine the appropriate sequence of tags for a particular sentence from the above tables? Let us find it out. Take a new sentence and tag them with wrong tags. Let the sentence, ‘ Will can spot Mary’ be tagged as- - Will as a model
- Can as a verb
- Spot as a noun
- Mary as a noun
Now calculate the probability of this sequence being correct in the following manner.  The probability of the tag Model (M) comes after the tag <S> is ¼ as seen in the table. Also, the probability that the word Will is a Model is 3/4. In the same manner, we calculate each and every probability in the graph. Now the product of these probabilities is the likelihood that this sequence is right. Since the tags are not correct, the product is zero. 1/4*3/4*3/4*0*1*2/9*1/9*4/9*4/9=0 When these words are correctly tagged, we get a probability greater than zero as shown below  Calculating the product of these terms we get, 3/4*1/9*3/9*1/4*3/4*1/4*1*4/9*4/9= 0.00025720164 For our example, keeping into consideration just three POS tags we have mentioned, 81 different combinations of tags can be formed. In this case, calculating the probabilities of all 81 combinations seems achievable. But when the task is to tag a larger sentence and all the POS tags in the Penn Treebank project are taken into consideration, the number of possible combinations grows exponentially and this task seems impossible to achieve. Now let us visualize these 81 combinations as paths and using the transition and emission probability mark each vertex and edge as shown below.  The next step is to delete all the vertices and edges with probability zero, also the vertices which do not lead to the endpoint are removed. Also, we will mention-  Now there are only two paths that lead to the end, let us calculate the probability associated with each path. <S>→N→M→N→N→<E> = 3/4*1/9*3/9*1/4*1/4*2/9*1/9*4/9*4/9= 0.00000846754 <S>→N→M→N→V→<E>= 3/4*1/9*3/9*1/4*3/4*1/4*1*4/9*4/9= 0.00025720164 Clearly, the probability of the second sequence is much higher and hence the HMM is going to tag each word in the sentence according to this sequence. The Viterbi algorithm is a dynamic programming algorithm for finding the most likely sequence of hidden states—called the Viterbi path—that results in a sequence of observed events, especially in the context of Markov information sources and hidden Markov models (HMM). Source: Wikipedia In the previous section, we optimized the HMM and bought our calculations down from 81 to just two. Now we are going to further optimize the HMM by using the Viterbi algorithm. Let us use the same example we used before and apply the Viterbi algorithm to it.  Consider the vertex encircled in the above example. There are two paths leading to this vertex as shown below along with the probabilities of the two mini-paths.  Now we are really concerned with the mini path having the lowest probability. The same procedure is done for all the states in the graph as shown in the figure below  As we can see in the figure above, the probabilities of all paths leading to a node are calculated and we remove the edges or path which has lower probability cost. Also, you may notice some nodes having the probability of zero and such nodes have no edges attached to them as all the paths are having zero probability. The graph obtained after computing probabilities of all paths leading to a node is shown below:  To get an optimal path, we start from the end and trace backward, since each state has only one incoming edge, This gives us a path as shown below  As you may have noticed, this algorithm returns only one path as compared to the previous method which suggested two paths. Thus by using this algorithm, we saved us a lot of computations. After applying the Viterbi algorithm the model tags the sentence as following- - Will as a noun
- Can as a model
- Spot as a verb
These are the right tags so we conclude that the model can successfully tag the words with their appropriate POS tags. In this section, we are going to use Python to code a POS tagging model based on the HMM and Viterbi algorithm.  As seen above, using the Viterbi algorithm along with rules can yield us better results. This brings us to the end of this article where we have learned how HMM and Viterbi algorithm can be used for POS tagging. If you wish to learn more about Python and the concepts of ML, upskill with Great Learning’s PG Program Artificial Intelligence and Machine Learning .  Top Free Courses Guide to Predictive Analytics: Definition, Core Concepts, Tools, and Use Cases Local Search Algorithm For AI: Everything You Need To Know 2024’s Leading IT Courses For Aspiring Tech Enthusiasts Top 10 In-Demand AI Jobs Roles and Skills For 2024 OpenAI Unveils GPT-4o: A Leap in AI Capabilities What is Artificial Intelligence in 2024?Leave a comment cancel reply. Your email address will not be published. Required fields are marked * Save my name, email, and website in this browser for the next time I comment.  POS tag (disambiguation) This page is about the POS tag, the full morphological tag with information about the part of speech and also number, gender, case, tense and other grammatical categories. For information about the POS attribute, the simplified tag containing only the part-of-speech information but not the additional morphological and grammatical informaion, see POS. This blog post defines what POS tags are, explains manual and automatic POS tagging and points readers to Sketch Engine where they can have their texts tagged automatically in many languages. What is a POS tag?A POS tag (or part-of-speech tag) is a label assigned to each token (word) in a text corpus to indicate the part of speech and often also other grammatical categories such as tense, number (plural/singular), case etc. POS tags are used in corpus searches and in text analysis tools and algorithms. A set of all POS tags used in a corpus is called a tagset . Tagsets for different languages are typically different. They can be completely different for unrelated languages and very similar for similar languages, but this is not always the rule. Tagsets can also go to a different level of detail. Basic tagsets may only include tags for the most common parts of speech (N for noun, V for verb, A for adjective etc.). It is, however, more common to go into more detail and distinguish between nouns in singular and plural, verbal conjugations, tenses, aspect, voice and much more. Individual researchers might even develop their own very specialized tagsets to accommodate their research needs. How can I…?Pos-tag my data. Upload your data/text into Sketch Engine to pos-tag and lemmatize them automatically. Then download the processed data. use my own POS tagsData can be annotated manually to introduce specific tags or attributes or data annotated automatically can be post-edited. see some tagsetsAll tagsets used in Sketch Engine are published online.  A concordance from Sketch Engine with POS tags displayed. What are POS tags used for?POS tags make it possible for automatic text processing tools to take into account which part of speech each word is. This facilitates the use of linguistic criteria in addition to statistics. For languages where the same word can have different parts of speech, e.g. work in English, POS tags are used to distinguish between the occurrences of the word when used as a noun or verb. POS tags are also used to search for examples of grammatical or lexical patterns without specifying a concrete word, e.g. to find examples of any plural noun not preceded by an article. Or both of the above can be combined, e.g. find the word help used as a noun followed by any verb in the past tense.   POS taggingPOS tagging is often also referred to as annotation or POS annotation . Manual annotationAnnotation by human annotators is rarely used nowadays because it is an extremely laborious process. For best results, more than one annotator is needed and attention must be paid to annotator agreement. This is often facilitated by the use of a specialized annotation software which does not assign POS tags but checks for any inconsistencies between annotators. When the software identifies a word (token) with different POS tags from each annotator, the annotators must find a resolution on how to annotate the word or might decide to expand the tagset to accommodate the new situation. Nowadays, manual annotation is typically used to annotate a small corpus to be used as training data for the development of a new automatic POS tagger. Annotating modern multi-billion-word corpora manually is unrealistic and automatic tagging is used instead. Automatic POS annotationDue to the size of modern corpora, the only viable tagging option is an automatic annotation. The tool that does the tagging is called a POS tagger, or simply a tagger. It can work with a high level of accuracy reaching up to 98 % and the mistakes are typically only limited to phenomena of less interest such as misspelt words, rare usage or interjections (e.g. yuppeeee might be tagged incorrectly). Ambiguity also poses a problem. In the sentence Time flies ., it is difficult to tell if it is made up of noun + verb or verb + noun. The latter meaning Use a stopwatch to measure (the movement of) insects . :-) Despite certain inaccuracies, modern tools are able to annotate a vast majority of the corpus correctly and the mistakes they make hardly ever cause problems when using the corpus. During the development of an automatic POS tagger, a small sample (at least 1 million words) of manually annotated training data is needed. The tagger uses it to “learn” how the language should be tagged. It works also with the context of the word in order to assign the most appropriate POS tag. Automatic taggers can only be as good as the quality of the training data. If the training data contain errors or inconsistencies originating from low annotator agreement, data annotated by such taggers will also reflect these problems. Taggers for each language can be mutually unrelated tools and each one can use different approaches, algorithms, programming languages and configurations. Apart from those, there are also tools which can be trained to process more than one language. The core software stays the same, but a different language model is used for each language. How to POS tag your data?Diy approach – open source pos taggers. Many POS taggers are available for download on the internet and are often open source. Their use may, however, require adequate (often high-level) technical skill of installing and configuring them. Ready-made POS tagging solutionsThe easiest way to tag your data for parts of speech is to use a ready-made solution such as uploading your texts to Sketch Engine, which already contains POS taggers for many languages. Any text the user uploads are tagged (and often also lemmatized) automatically. No technical knowledge or IT skills are required to have the data tagged. The tagged data can be analysed and searched in Sketch Engine or downloaded for use with other tools.  Topics and genres in corpora Case sensitive and insensitive corpus analysis Words, tags, lemmas, lemposes, lowercase Build a corpus from the web The best term extraction Automatic thesaurus Corpus annotation and structures Most frequent or most typical collocations?For learners of languages.  A Course in Lexicography and Lexical Computing term extraction learn sketch engine  A Comprehensive Guide to Part-of-Speech TaggingPart-of-speech tagging is a fundamental task in natural language processing that involves assigning a grammatical category to each word in a piece of text. In this article, we explore various aspects of part-of-speech tagging, including its applications, different approaches, and the impact of context and training data. We also discuss the potential uses of part-of-speech tagging for search engine optimization (SEO) and its role in identifying and correcting grammatical errors. What is Part-of-Speech Tagging and How is it Used in Natural Language Processing?How do different approaches to part-of-speech tagging (e.g. rule-based, statistical, hybrid) compare in terms of accuracy and complexity, how does the context in which a word is used affect its part-of-speech tag, how can part-of-speech tagging be used to disambiguate homographs, how does the part-of-speech tagging of a word influence its syntactic role in a sentence, how does the use of different training data sets impact the performance of a part-of-speech tagging system, can part-of-speech tagging be used to identify the sentiment or emotion expressed in a piece of text, how does the performance of part-of-speech tagging systems vary across different languages and writing styles, how can part-of-speech tagging be used to improve search engine optimization (seo), can part-of-speech tagging be used to identify the most important keywords in a piece of text for seo purposes, how does the part-of-speech of a keyword impact its effectiveness for seo, how search engine models use part-of-speech tagging. Part-of-speech tagging is a process of assigning a grammatical category, such as noun, verb, or adjective, to each word in a piece of text. This task is essential for natural language processing applications, such as information extraction, machine translation , and text summarization . There are various approaches to part-of-speech tagging, including rule-based, statistical, and hybrid methods, each with its own strengths and limitations. The accuracy of part-of-speech tagging can be influenced by factors such as the context in which a word is used and the quality of the training data. In addition to its role in natural language processing, part-of-speech tagging can also be useful for search engine optimization (SEO) by identifying important keywords and optimizing their density and grammatical role in a piece of text. In this article, we will delve into these and other aspects of part-of-speech tagging to gain a better understanding of this important task in natural language processing. Part-of-speech (POS) tagging is a common task in natural language processing (NLP) that involves labeling the words in a text with their corresponding part of speech. This process is also known as grammatical tagging or word-category disambiguation. There are several different parts of speech that a word can belong to, such as nouns, verbs, adjectives, adverbs, and pronouns. Each part of speech plays a specific role in a sentence and conveys a specific meaning. For example, nouns typically refer to people, places, or things, while verbs describe actions or states of being. Adjectives describe nouns or pronouns, and adverbs describe verbs, adjectives, or other adverbs. POS tagging is used in NLP for a variety of purposes. One common use is to disambiguate word meanings and to identify the role that a word plays in a sentence. For example, the word "book" can be a noun (e.g., "I am reading a book") or a verb (e.g., "I will book a hotel room"). By correctly identifying the part of speech of a word, a natural language processing system can better understand the meaning of a sentence and the relationships between the words within it. Another use of POS tagging is to improve the accuracy of language models . Language models are used to predict the likelihood of a sequence of words occurring in a language. By accurately labeling the parts of speech of the words in a text, a language model can make more accurate predictions about the structure and meaning of the text. POS tagging is also used in information retrieval and information extraction tasks, such as search engines and question answering systems. By accurately labeling the parts of speech of the words in a text, these systems can better understand the relationships between words and the meaning of the text as a whole. There are several different approaches to POS tagging, including rule-based, stochastic, and machine learning-based methods . Rule-based POS tagging involves manually creating a set of rules for labeling each word based on its context and characteristics. Stochastic POS tagging involves using statistical methods to predict the part of speech of a word based on the words that come before and after it in a sentence. Machine learning-based POS tagging involves training a machine learning model on a large annotated dataset and using the trained model to predict the part of speech of a word in a new text. One of the challenges of POS tagging is that words can have multiple possible parts of speech depending on the context in which they are used. For example, the word "run" can be a verb (e.g., "I like to run") or a noun (e.g., "I went for a run this morning"). To accurately tag the part of speech of a word, a natural language processing system must consider the context in which the word is used and the words that come before and after it in a sentence. In summary, POS tagging is a common task in natural language processing that involves labeling the words in a text with their corresponding part of speech. It is used to disambiguate word meanings, improve the accuracy of language models, and support information retrieval and information extraction tasks. There are several different approaches to POS tagging, including rule-based, stochastic, and machine learning-based methods. Part-of-speech (POS) tagging is the process of marking each word in a text with its corresponding part of speech. This is an important task in natural language processing (NLP) as it helps to identify the roles that words play in a sentence and can aid in tasks such as syntactic parsing and named entity recognition . There are several approaches to POS tagging, including rule-based, statistical, and hybrid methods. Rule-based POS tagging approaches rely on a set of predefined rules to determine the part of speech of a given word. These rules are usually based on the morphological and syntactic properties of the word, such as its suffix, prefix, and surrounding context. Rule-based POS taggers can be highly accurate, particularly for well-formed and grammatically correct texts. However, they can struggle with out-of-vocabulary (OOV) words, words that are not in the training data, and text that is poorly written or contains errors. Additionally, rule-based taggers can be difficult to develop and maintain, as they require a large set of rules and manual annotation of a training corpus. Statistical POS tagging approaches, on the other hand, rely on machine learning algorithms to learn the patterns and features that determine the part of speech of a word from a large annotated training corpus. These approaches are typically based on supervised learning techniques, where the algorithms are trained on a labeled dataset and then make predictions on unseen data. Statistical POS taggers can be highly accurate and can handle OOV words and text with errors more effectively than rule-based taggers. However, they require a large annotated training corpus and can be computationally intensive. Hybrid POS tagging approaches combine elements of both rule-based and statistical methods. These approaches often use a combination of rules and machine learning algorithms to make POS tagging decisions. Hybrid approaches can often achieve high accuracy while also being able to handle OOV words and text with errors more effectively than rule-based taggers. However, they can also be more complex to develop and maintain than either rule-based or statistical taggers alone. In terms of accuracy, statistical POS taggers are generally considered to be the most accurate, followed by hybrid approaches, and then rule-based taggers. This is because statistical approaches are able to learn from a large annotated training corpus and can handle OOV words and text with errors more effectively than rule-based taggers. However, the accuracy of a POS tagger will depend on the quality of the training data and the complexity of the task. For example, a POS tagger trained on a large annotated corpus of formal written language may perform better on formal written text than on informal spoken language. In terms of complexity, rule-based taggers can be more straightforward to develop and maintain, as they rely on a set of predefined rules. However, they can be difficult to scale and may require extensive manual annotation of a training corpus. Statistical and hybrid taggers, on the other hand, can be more complex to develop and maintain, as they rely on machine learning algorithms and may require a larger training corpus. However, they can be more scalable and can often achieve higher accuracy than rule-based taggers. In summary, different approaches to POS tagging have their own strengths and limitations. Rule-based taggers can be highly accurate but can struggle with OOV words and text with errors. Statistical taggers can be highly accurate and handle OOV words and text with errors more effectively, but they require a large annotated training corpus and can be computationally intensive. Hybrid taggers can often achieve high accuracy and handle OOV words and text with errors more effectively, but they can be more complex to develop and maintain. The choice of which approach to use will depend on the specific requirements and constraints of the task at hand. For example, if computational resources are limited or if the task requires a high degree of interpretability, a rule-based or hybrid approach may be more appropriate. On the other hand, if accuracy is the primary concern and computational resources are not an issue, a statistical approach may be the best choice. It is also worth noting that recent advances in deep learning have led to the development of neural network-based POS taggers, which can achieve state-of-the-art accuracy on many NLP tasks. These approaches typically rely on large amounts of annotated data and can be computationally intensive, but they have the advantage of being able to automatically learn complex patterns and features from the data. In conclusion, different approaches to POS tagging have their own trade-offs in terms of accuracy and complexity. Rule-based taggers can be accurate but may struggle with OOV words and text with errors, while statistical taggers can be highly accurate but require a large annotated training corpus and can be computationally intensive. Hybrid taggers can offer a good balance between accuracy and complexity, but they may still require a large annotated training corpus and can be more complex to develop and maintain. Neural network-based taggers can achieve state-of-the-art accuracy but are also computationally intensive and require a large annotated training corpus. The choice of approach will depend on the specific requirements and constraints of the task at hand. The context in which a word is used can significantly affect its part-of-speech (POS) tag, as the POS of a word is determined by its function within a sentence. For example, the word "run" can be used as a verb (to move quickly) or as a noun (a continuous period of activity). In the sentence "I will run to the store," "run" is a verb, but in the sentence "I went for a run this morning," "run" is a noun. One way in which context can affect the POS of a word is through the use of determiners, such as "the" or "a." For example, the word "book" can be used as a noun or a verb. When used as a noun, it can be modified with a determiner, such as in the sentence "I am reading a book." In this sentence, "book" is a noun because it is modified by the determiner "a." However, in the sentence "I will book a flight," "book" is a verb because it is not modified by a determiner. Another factor that can affect the POS of a word is the presence of modifiers, such as adjectives or adverbs. For example, the word "clean" can be used as an adjective or a verb. In the sentence "I will clean the room," "clean" is a verb because it is not modified by an adjective. However, in the sentence "I need a clean towel," "clean" is an adjective because it modifies the noun "towel." The tense of a verb can also affect its POS. For example, the word "have" can be used as a verb or as an auxiliary verb. In the sentence "I have a car," "have" is a verb because it is used in the present tense. However, in the sentence "I had a car," "have" is an auxiliary verb because it is used to form the past tense. The presence of prepositions can also affect the POS of a word. For example, the word "on" can be used as a preposition or as an adverb. In the sentence "I will put the book on the table," "on" is a preposition because it relates the noun "book" to the noun "table." However, in the sentence "I will turn on the light," "on" is an adverb because it modifies the verb "turn." The position of a word within a sentence can also affect its POS. For example, the word "that" can be used as a pronoun or as a conjunction. In the sentence "I know that you are coming," "that" is a conjunction because it connects the clauses "I know" and "you are coming." However, in the sentence "I gave the book to the person that I met," "that" is a pronoun because it refers back to the noun "person." In conclusion, the context in which a word is used can significantly affect its POS tag. This is because the POS of a word is determined by its function within a sentence, and various factors such as determiners, modifiers, verb tense, prepositions, and sentence position can all affect this function. As a result, it is important to consider the context in which a word is used in order to accurately determine its POS. Homographs are words that are spelled the same, but have different meanings. These words can cause confusion when used in a sentence, as the context may not be clear which meaning is intended. Part-of-speech (POS) tagging is a technique that can be used to disambiguate homographs, or assign the correct meaning to a homograph based on its context within a sentence. One way that POS tagging can be used to disambiguate homographs is through the use of context clues. For example, if the word "bass" is used in a sentence about music, it is likely that it refers to the low-frequency sound produced by a musical instrument. However, if the word "bass" is used in a sentence about fishing, it is likely that it refers to a type of fish. By examining the surrounding words and context, a POS tagger can accurately assign the appropriate meaning to the homograph. Another way that POS tagging can be used to disambiguate homographs is through the use of word sense disambiguation algorithms. These algorithms analyze the context of a word and use machine learning techniques to assign the most likely meaning to the homograph. For example, if the word "bass" is used in a sentence about music, the algorithm may consider factors such as the presence of other musical terms or the topic of the text. If the word "bass" is used in a sentence about fishing, the algorithm may consider factors such as the presence of other fishing terms or the location of the text. By analyzing these contextual clues, the algorithm can accurately assign the appropriate meaning to the homograph. POS tagging can also be used to disambiguate homographs through the use of word vectors. Word vectors are numerical representations of words that capture their meanings and relationships with other words. By examining the relationships between a homograph and other words in the sentence, a POS tagger can assign the appropriate meaning to the homograph. For example, if the word "bass" is used in a sentence with words such as "guitar" and "drum," it is likely that it refers to the low-frequency sound produced by a musical instrument. However, if the word "bass" is used in a sentence with words such as "rod" and "reel," it is likely that it refers to a type of fish. POS tagging can also be used to disambiguate homographs through the use of syntactic cues . Syntactic cues are the rules and patterns that govern the arrangement of words in a sentence. By examining the syntactic structure of a sentence, a POS tagger can assign the appropriate meaning to a homograph. For example, if the word "bass" is used as a verb in a sentence, it is likely that it refers to the low-frequency sound produced by a musical instrument. However, if the word "bass" is used as a noun in a sentence, it is likely that it refers to a type of fish. Overall, POS tagging is a powerful tool for disambiguating homographs. By examining the context, word sense disambiguation algorithms, word vectors, and syntactic cues, a POS tagger can accurately assign the appropriate meaning to a homograph, eliminating confusion and improving the overall clarity of a text. This is especially important in fields such as natural language processing and machine translation , where accurate disambiguation of homographs is essential for understanding the intended meaning of a text. Part-of-speech tagging is a process in which words are assigned a specific grammatical category, or part of speech, based on their syntax and function within a sentence. These categories include nouns, verbs, adjectives, adverbs, and so on. The part-of-speech tagging of a word plays a significant role in its syntactic role in a sentence, as it determines how the word interacts with other words and how it contributes to the overall structure and meaning of the sentence. For example, consider the sentence "The cat chased the mouse." In this sentence, "cat" is a noun, "chased" is a verb, and "mouse" is a noun. The part-of-speech tagging of these words determines their syntactic roles in the sentence. "Cat" is the subject of the sentence, as it is the one performing the action of chasing. "Chased" is the verb, which specifies the action being performed. "Mouse" is the object of the verb, as it is the one being chased. This is similar to the subject-predicate-object concept of semantic triples . The part-of-speech tagging of a word also influences its syntactic role in a sentence by determining its grammatical function. For example, consider the sentence "She gave the book to him." In this sentence, "she" is a pronoun and "him" is a pronoun. These words are functioning as the subject and object of the verb "gave," respectively. "Book" is a noun and is functioning as the direct object of the verb, as it is the thing being given. In addition to determining the syntactic roles of words within a sentence, part-of-speech tagging also plays a role in the overall structure of a sentence. For example, consider the sentence "The boy ran home." In this sentence, "the" is a determiner, "boy" is a noun, and "ran" is a verb. These words are arranged in a specific order to convey the meaning of the sentence. If the words were rearranged, the meaning of the sentence would change. For example, "Home the boy ran" would not make sense, as the word order is incorrect. Another way that the part-of-speech tagging of a word can influence its syntactic role in a sentence is through the use of affixes. Affixes are prefixes and suffixes that are added to a word to change its meaning or grammatical function. For example, consider the word "run." If we add the suffix "-er," the word becomes "runner," which is now a noun instead of a verb. The part-of-speech tagging of a word can change based on the affixes that are added to it, which in turn affects its syntactic role in a sentence. In conclusion, the part-of-speech tagging of a word plays a crucial role in its syntactic role in a sentence. It determines how the word interacts with other words, its grammatical function, and the overall structure of the sentence. Understanding the part-of-speech tagging of a word can help us better understand its role in a sentence and how it contributes to the meaning of the sentence as a whole. Part-of-speech (POS) tagging is the process of labeling words in a text with their corresponding grammatical category, such as noun, verb, adjective, etc. POS tagging is an important task in natural language processing (NLP) as it helps identify the structure and meaning of a text. The performance of a POS tagging system is heavily dependent on the training data used to build the system. There are two main types of training data that can be used for POS tagging: annotated corpora and unannotated text. Annotated corpora are texts that have been manually labeled with POS tags. These corpora are typically large and diverse, and they provide a reliable source of labeled data for training a POS tagging system. The advantage of using annotated corpora is that they provide accurate and comprehensive information about the structure and meaning of the text. This allows the POS tagging system to learn and accurately classify words in the text. However, annotated corpora are also time-consuming and costly to create, as they require manual labeling by experts. Additionally, annotated corpora may not be representative of the types of texts that the POS tagging system will encounter in real-world applications. This can limit the system's performance and generalizability. Unannotated text, on the other hand, is a type of training data that has not been manually labeled. Instead, the POS tagging system must rely on algorithms to identify and classify words based on their context and usage. Unannotated text is typically more readily available than annotated corpora, and it can be used to train a POS tagging system more quickly and at a lower cost. However, the performance of a POS tagging system trained on unannotated text is typically lower than one trained on annotated corpora. This is because unannotated text lacks the detailed and accurate labeling provided by annotated corpora, which can lead to errors and inaccuracies in the POS tagging system. Additionally, unannotated text may contain errors or ambiguities that can further degrade the performance of the system. Another factor that can impact the performance of a POS tagging system is the size and diversity of the training data. A larger and more diverse training set can provide the system with a wider range of examples and improve its ability to accurately classify words in different contexts. On the other hand, a small or homogenous training set may not provide sufficient examples for the system to learn from, resulting in poor performance. Finally, the performance of a POS tagging system can also be impacted by the algorithms and techniques used to classify words in the text. Some approaches, such as rule-based systems, may be more accurate but also more complex and time-consuming to develop and maintain. Other approaches, such as machine learning-based systems, may be faster and more efficient but may also be less accurate and require more data to train effectively. In conclusion, the use of different training data sets can significantly impact the performance of a POS tagging system. Annotated corpora provide reliable and accurate labels for training, but they may be costly and time-consuming to create. Unannotated text is more readily available but may not be as accurate or representative of real-world texts. The size and diversity of the training data, as well as the algorithms and techniques used, can also impact the system's performance. Ultimately, the most effective training data set for a POS tagging system will depend on the specific needs and goals of the system. Part-of-speech (POS) tagging is a common technique used in natural language processing (NLP) to identify the grammatical role of each word in a sentence. It involves assigning a specific tag, such as noun, verb, adjective, etc., to each word in a text. POS tagging can be used to analyze the structure and meaning of a text, as well as to improve the performance of NLP algorithms such as language translation or text classification . One potential use of POS tagging is to identify the sentiment or emotion expressed in a piece of text. Sentiment analysis is the process of identifying the overall attitude or opinion of an author towards a particular topic or entity, which can be positive, negative, or neutral. Emotion analysis is the process of identifying the emotional states or feelings of an author, such as happiness, sadness, anger, or fear. There are several ways in which POS tagging can be used to identify the sentiment or emotion expressed in a text. One approach is to use specific POS tags as indicators of sentiment or emotion. For example, words that are tagged as adjectives or adverbs often carry emotional content and can be used to infer the sentiment or emotion of a text. For example, words such as "happy," "sad," "angry," or "fearful" are often used to express emotion, and their presence in a text can be used to infer the sentiment or emotion of the author. Another approach is to use the context and syntactic structure of a text to identify sentiment or emotion. For example, words that are used in conjunction with negation words such as "not" or "never" can reverse the sentiment of a text. For example, the phrase "I am not happy" indicates a negative sentiment, while the phrase "I am happy" indicates a positive sentiment. Similarly, the use of intensifiers such as "very" or "extremely" can increase the intensity of a sentiment or emotion, while the use of diminishers such as "slightly" or "somewhat" can decrease the intensity. In addition to using specific POS tags and syntactic structure, sentiment and emotion can also be inferred from the overall sentiment or emotion of a text. For example, a text that is predominantly positive in sentiment is likely to express a positive emotion, while a text that is predominantly negative in sentiment is likely to express a negative emotion. This can be achieved by analyzing the overall distribution of positive and negative words in a text and using this information to infer the sentiment or emotion of the text. Despite the potential of POS tagging to identify sentiment or emotion in a text, it is important to note that this approach has its limitations. One limitation is that sentiment and emotion are often subjective and can vary from person to person. This means that the same text may be interpreted differently by different people, making it difficult to accurately identify the sentiment or emotion of a text using POS tagging. Another limitation is that sentiment and emotion are often conveyed through more than just words. Nonverbal cues such as tone of voice, facial expressions, and body language can also convey sentiment and emotion, and these cues are not captured by POS tagging. This means that POS tagging may not always be able to accurately identify the sentiment or emotion of a text, particularly if the text is spoken rather than written. In conclusion, while POS tagging can be used to identify the sentiment or emotion expressed in a piece of text, it is not a foolproof method and has its limitations. It is important to consider these limitations when using POS tagging for sentiment or emotion analysis, and to use other methods such as nonverbal cues or contextual analysis to supplement the results of POS tagging. Part-of-speech (POS) tagging is a process in natural language processing (NLP) that involves identifying and labeling the grammatical category of each word in a given text. This is a crucial step in many NLP tasks, including parsing, information extraction, and machine translation. However, the performance of POS tagging systems can vary significantly across different languages and writing styles. One key factor that affects the performance of POS tagging systems is the complexity of the grammar and syntax of the target language. For example, languages with complex inflectional systems, such as German or Russian, may be more challenging to tag accurately due to the large number of possible inflections for each word. On the other hand, languages with simpler inflectional systems, such as English or Spanish, may be easier to tag. Another factor that can impact the performance of POS tagging systems is the degree of standardization and consistency in the language. Some languages, such as English, have relatively stable and well-defined grammatical rules, while others, such as Chinese, have more flexible and context-dependent grammars. This can make it more difficult to accurately tag words in languages with less standardization. The level of morphological complexity can also affect the performance of POS tagging systems. Some languages, such as Arabic or Hebrew, have highly inflected verb forms and nouns with a wide range of case endings, which can make it challenging to accurately tag these words. In contrast, languages with simpler morphologies, such as French or Italian, may be easier to tag. The writing style of a text can also impact the performance of POS tagging systems. For example, text written in a formal or academic style may be easier to tag accurately due to its more standardized and predictable language use. In contrast, text written in a colloquial or informal style may be more challenging to tag due to its use of slang, jargon, and other non-standard language forms. Another factor that can affect the performance of POS tagging systems is the presence of non-standard or ambiguous words. For example, words that are used in multiple senses or that have multiple possible part-of-speech categories may be more difficult to tag accurately. This can be especially challenging in languages with large vocabularies or that allow for a high degree of word formation, such as English. Finally, the quality and quantity of annotated training data can also impact the performance of POS tagging systems. For example, systems that are trained on larger and more diverse datasets may be able to generalize better to new texts and languages. However, training data that is poorly annotated or that does not adequately represent the target language or writing style may lead to poor performance. In summary, the performance of POS tagging systems can vary significantly across different languages and writing styles. Factors such as the complexity of the grammar and syntax, the degree of standardization and consistency, the level of morphological complexity, the writing style, and the presence of non-standard or ambiguous words can all affect the accuracy of these systems. Additionally, the quality and quantity of annotated training data can impact their generalization ability. Part-of-speech tagging, also known as POS tagging, is a process in which a program assigns a specific part of speech to each word in a given text. This includes words such as nouns, verbs, adjectives, and adverbs. This process can be used to improve search engine optimization (SEO) in a number of ways. First and foremost, part-of-speech tagging can help search engines better understand the content of a webpage. When a search engine crawls a webpage, it looks for specific keywords and phrases that are relevant to the user's search query. By using part-of-speech tagging, the search engine can better understand the context in which these keywords and phrases are used, and this can help it to more accurately rank the webpage in its search results. For example, if a webpage contains the phrase "the quick brown fox," the search engine might not understand the context in which this phrase is used. However, if the webpage is tagged with the parts of speech "article, adjective, adjective, noun," the search engine can more accurately understand that the phrase is being used to describe a quick and brown fox, rather than being used as a random collection of words. In addition to helping search engines understand the content of a webpage, part-of-speech tagging can also be used to optimize the content itself . By using specific parts of speech in the right way, it is possible to make the content more appealing to search engines and users alike. For example, by using descriptive adjectives, it is possible to make the content more interesting and engaging. Similarly, by using strong verbs, it is possible to make the content more actionable and compelling. By optimizing the content in this way, it is possible to improve the SEO of the webpage and increase its chances of ranking highly in the search results. Another way in which part-of-speech tagging can be used to improve SEO is through keyword optimization. By using POS tagging, it is possible to identify the most important keywords in a given text and ensure that they are used in a way that is most likely to be noticed by search engines. For example, if a webpage contains the keyword "dog," it is important to use this keyword in a way that is most likely to be noticed by search engines. By using POS tagging, it is possible to identify the most important occurrences of the keyword and ensure that they are used in a way that is most likely to be noticed by search engines. In addition to keyword optimization, part-of-speech tagging can also be used to improve the overall readability and clarity of a webpage. By using POS tagging, it is possible to identify any ambiguous or confusing words or phrases and replace them with more straightforward alternatives. This can help to improve the overall user experience and make the webpage more appealing to search engines. Finally, part-of-speech tagging can also be used to improve the overall structure and organization of a webpage. By using POS tagging, it is possible to identify the most important parts of the webpage and ensure that they are given appropriate emphasis. This can help to make the webpage more compelling and engaging, and can improve its chances of ranking highly in the search results. In conclusion, part-of-speech tagging is a powerful tool that can be used to improve search engine optimization in a number of ways. By helping search engines understand the content of a webpage, optimizing the content itself, optimizing keywords, improving readability and clarity, and improving the overall structure and organization of a webpage, it is possible to significantly improve the SEO of a webpage and increase its chances of ranking highly in the search results. Part-of-speech tagging, also known as POS tagging, is the process of identifying and labeling the parts of speech in a piece of text. This is usually done using natural language processing algorithms that analyze the syntax and grammar of a text to determine the roles and functions of each word in a sentence. One potential use of POS tagging in the context of search engine optimization (SEO) is to identify the most important keywords in a piece of text. In SEO, keywords are the specific terms or phrases that people use when searching for information online. By identifying and targeting these keywords in your content, you can improve the visibility and ranking of your website in search engine results. To use POS tagging for SEO purposes, you would first need to analyze the text of your website or blog post and identify the most important keywords. This can be done manually or using a tool that helps you find relevant keywords based on the topic of your content. Once you have identified your target keywords, you can use POS tagging to determine the parts of speech of these words and see how they are used in the text. For example, if a keyword is a noun, it might be more important for SEO purposes than if it is a verb or an adjective. This is because nouns often carry more meaning and are more likely to be used as search terms by users. Additionally, you can use POS tagging to identify the grammatical role of each keyword in the text. For example, if a keyword is used as the subject of a sentence, it is likely to be more important than if it is used as an object or modifier. This is because the subject of a sentence is usually the main focus of the sentence, and therefore more likely to be used as a search term. Another way that POS tagging can be used to identify important keywords for SEO purposes is by analyzing the frequency and context of each keyword in the text. Keywords that appear more frequently or in more prominent positions within the text are likely to be more important for SEO purposes than those that are used less frequently or in less prominent positions. Finally, you can use POS tagging to identify the syntactic patterns in which your keywords are used. For example, if a keyword is used in a specific phrase or sentence structure, it may be more important for SEO purposes than if it is used in a different context. Overall, part-of-speech tagging can be a useful tool for identifying the most important keywords in a piece of text for SEO purposes. By analyzing the parts of speech, grammatical roles, frequency, and context of your keywords, you can better understand how they are used in your content and optimize them for search engines. While it is only one aspect of SEO, part-of-speech tagging can help you to create more effective and targeted content that is more likely to rank well in search engine results. Keywords are an essential component of search engine optimization (SEO) because they help search engines understand the content of a webpage and rank it accordingly. The part-of-speech of a keyword can significantly impact its effectiveness for SEO because it determines how the keyword is used in the content and how it is interpreted by search engines. First and foremost, it is important to understand the different parts of speech that exist in the English language. These include nouns, verbs, adjectives, adverbs, pronouns, and prepositions. Each of these parts of speech serves a specific function in a sentence and has a unique impact on the meaning and structure of the content . For example, nouns are used to name people, places, things, or ideas, while verbs describe actions, states, or occurrences. Adjectives describe nouns or pronouns, while adverbs modify verbs, adjectives, or other adverbs. Pronouns take the place of nouns or other pronouns, while prepositions link nouns or pronouns to other words in a sentence. In terms of SEO, the part-of-speech of a keyword can have a significant impact on its effectiveness. For example, if a keyword is a noun, it is likely to be more effective when used as the primary focus of the content. This is because search engines tend to prioritize content that is centered around a specific topic or subject, and using a noun as a keyword helps to clarify the topic of the content. On the other hand, if a keyword is a verb or an adjective, it is likely to be more effective when used to describe or modify the primary focus of the content. This is because these parts of speech help to provide additional context and detail to the content, which can help search engines understand the content more accurately. Additionally, using keywords in their various forms (e.g., singular or plural, present or past tense) can also impact their effectiveness for SEO. For example, using a keyword in its plural form may be more effective if the content is discussing multiple instances of the keyword, while using it in its present tense may be more effective if the content is discussing current events or trends. It is also worth noting that the part-of-speech of a keyword can impact its effectiveness for SEO in relation to the structure and organization of the content. For example, using a keyword as the subject of a sentence can help to give it more emphasis and make it more noticeable to search engines. Similarly, using a keyword as the predicate of a sentence (i.e., the part of the sentence that follows the subject and verb) can help to give it more context and make it more relevant to the content. Overall, the part-of-speech of a keyword plays a crucial role in its effectiveness for SEO. By understanding the different parts of speech and how they impact the meaning and structure of content, you can optimize your use of keywords and improve the chances that your content will rank highly in search engine results. It is important to consider the part-of-speech of a keyword when selecting it for your content, as well as how you use it in the content itself, in order to achieve the best possible results for your SEO efforts. Part-of-speech tagging is a crucial aspect of search engine models and is used in a variety of ways to help SEO professionals understand things like topic clusters , semantic SEO , and more. One of the main ways that part-of-speech tagging is used in search engines is to identify the role that each word plays in a given sentence or piece of content. This is important because it allows the search engine to understand the context and meaning of each word, which is essential for accurately ranking and organizing search results. It is a tenant of natural language processing and is modeled via Market Brew's Query Layer and Similar Words System.  In addition to helping the search engine understand the context and meaning of individual words, part-of-speech tagging is also used to identify and extract named entities from content. In Market Brew, this is modeled through the Spotlight Algorithm, which uses natural language processing and part-of-speech tagging to do named entity extraction and disambiguation.  Part-of-speech tagging is also used in search engines to help identify and understand topic clusters . Market Brew models this in its Spotlight Focus Algorithm, which attempts to combine named entity extraction with relevant topic analysis and incoming link structure, to provide a set of topics that define a web page.  Overall, part-of-speech tagging is a crucial aspect of search engine models and is used in a variety of ways to help SEO professionals understand and optimize content for search engines. By accurately identifying the role that each word plays in a sentence or piece of content, search engine models are able to better understand the context and meaning of the content and provide a more accurate representation of semantic algorithms within search engines. Ready to Take Control of Your SEO?See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition. Schedule a free discovery call today and discover how we engineer SEO success. U.S. Patent Nos. 8,447,751 and 9,245,037 Market Brew™, MarketBrew.com and marketbrew.ai. All rights reserved. Privacy Policy: marketbrew.ai/privacy-policy Word Classes and Part-of-Speech Tagging in NLPPart-of-speech (POS) tagging is an important Natural Language Processing (NLP) concept that categorizes words in the text corpus with a particular part of speech tag (e.g., Noun, Verb, Adjective, etc.) POS tagging could be the very first task in text processing for further downstream tasks in NLP, like speech recognition, parsing, machine translation, sentiment analysis, etc. The particular POS tag of a word can be used as a feature by various Machine Learning algorithms used in Natural Language Processing. IntroductionSimply put, In Parts of Speech tagging for English words, we are given a text of English words we need to identify the parts of speech of each word. Example Sentence : Learn NLP from Scaler Learn -> ADJECTIVE NLP -> NOUN from -> PREPOSITION Scaler -> NOUN Although it seems easy, Identifying the part of speech tags is much more complicated than simply mapping words to their part of speech tags. Why Difficult ? Words often have more than one POS tag. Let’s understand this by taking an easy example. In the below sentences focus on the word “back” : | Sentence | POS tag of word ” |
|---|
| The ” door | ADJECTIVE | | On my ” | NOUN | | Win the voters ” | ADVERB | | Promised to ” the bill | VERB |
The relationship of “back” with adjacent and related words in a phrase, sentence, or paragraph is changing its POS tag. It is quite possible for a single word to have a different part of speech tag in different sentences based on different contexts. That is why it is very difficult to have a generic mapping for POS tags. If it is difficult, then what approaches do we have? Before discussing the tagging approaches, let us literate ourselves with the required knowledge about the words, sentences, and different types of POS tags. Word ClassesIn grammar, a part of speech or part-of-speech (POS) is known as word class or grammatical category, which is a category of words that have similar grammatical properties. The English language has four major word classes: Nouns, Verbs, Adjectives, and Adverbs . Commonly listed English parts of speech are nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunction, interjection, numeral, article, and determiners. These can be further categorized into open and closed classes. Closed ClassClosed classes are those with a relatively fixed/number of words, and we rarely add new words to these POS, such as prepositions. Closed class words are generally functional words like of, it, and, or you, which tend to be very short, occur frequently, and often have structuring uses in grammar. Example of closed class- Determiners: a, an, the Pronouns: she, he, I, others Prepositions: on, under, over, near, by, at, from, to, with Open Classes are mostly content-bearing, i.e., they refer to objects, actions, and features; it's called open classes since new words are added all the time. By contrast, nouns and verbs, adjectives, and adverbs belong to open classes; new nouns and verbs like iPhone or to fax are continually being created or borrowed. Example of open class- Nouns: computer, board, peace, school Verbs: say, walk, run, belong Adjectives: clean, quick, rapid, enormous Adverbs: quickly, softly, enormously, cheerfully The problem is (as discussed above) many words belong to more than one word class. And to do POS tagging, a standard set needs to be chosen. We Could pick very simple/coarse tagsets such as Noun (NN) , Verb (VB) , Adjective (JJ) , Adverb (RB) , etc. But to make tags more dis-ambiguous, the commonly used set is finer-grained, University of Pennsylvania’s “UPenn TreeBank tagset” , having a total of 45 tags. | Tag | Description | Example | Tag | Description | Example |
|---|
| CC | Coordin. Conjunction | and, but, or | SYM | Symbol | +%, & | | CD | Cardinal number | one, two, three | TO | "to" | to | | DT | Determiner | a, the | UH | Interjection | ah, oops | | EX | Existential 'there' | there | VB | Verb, base form | eat | | FW | Foreign word | mea culpa | VBD | Verb, past tense | ate | | IN | Preposition/sub-conj | of, in, by | VBG | Verb, gerund | eating | | JJ | Adjective | yellow | VBN | Verb, past participle | eaten | | JJR | Adj., comparative | bigger | VBP | Verb, non-3 sg pres | eat | | JJS | Adj., superlative | wildest | VBZ | Verb, 3 sg pres | eats | | LS | List item marker | 1, 2, One | WDT | Wh-determiner | which, that | | MD | Modal | can, should | WP | Wh-pronoun | what, who | | NN | Noun, sing. or mass | llama | WP$ | Possessive wh- | whose | | NNS | Noun, plural | llamas | WRB | Wh-adverb | how, where | | NNP | Proper noun, singular | IBM | $ | Dollar sign | $ | | NNPS | Proper noun, plural | Carolinas | # | Pound sign | # | | PDT | Predeterminer | all, both | "، | Left quote | ( or ) | | POS | Possessive ending | 's | " | Right quote | ( or ) | | PRP | Personal pronoun | I, you, he | ( | Left parenthesis | ([,(,{,<) | | PRP$ | Possessive pronoun | your, one's | ) | Right parenthesis | (],),},>) | | RB | Adverb | quickly, never | , | Comma | | | RBR | Adverb, comparative | faster | . | Sentence-final punc | (. ! ?) | | RBS | Adverb, superlative | fastest | : | Mid-sentence punc | (: ; ...) | | RP | Particle | up, off | | | |
What Are Parts of Speech Tagging in NLP?Part-of-speech tagging is the process of assigning a part of speech to each word in a text. The input is a sequence x 1 , x 2 , . . . , x n x_1, x_2,..., x_n x 1 , x 2 , . . . , x n of (tokenized) words, and the output is a sequence y 1 , y 2 , . . . , y n y_1, y_2,..., y_n y 1 , y 2 , . . . , y n of POS tags, each output y i y_i y i corresponding exactly to one input x i x_i x i .  Tagging is a disambiguation task; words are ambiguous i.e. have more than one a possible part of speech, and the goal is to find the correct tag for the situation. For example, a book can be a verb ( book that flight) or a noun (hand me that book ). The goal of POS tagging is to resolve these ambiguities, choosing the proper tag for the context. POS tagging Algorithms Accuracy: The accuracy of existing State of the Art algorithms of part-of-speech tagging is extremely high. The accuracy can be as high as ~ 97% , which is also about the human performance on this task, at least for English. We’ll discuss algorithms/techniques for this task in the upcoming sections, but first, let’s explore the task. Exactly how hard is it? Let's consider one of the popular electronic collections of text samples, Brown Corpus . It is a general language corpus containing 500 samples of English, totaling roughly one million words. In Brown Corpus : 85-86% words are unambiguous - have only 1 POS tag 14-15% words are ambiguous - have 2 or more POS tags Particularly ambiguous common words include that, back, down, put, and set . The word back itself can have 6 different parts of speech (JJ, NN, VBP, VB, RP, RB) depending on the context. Nonetheless, many words are easy to disambiguate because their different tags aren’t equally likely. For example, "a" can be a determiner or the letter "a" , but the determiner sense is much more likely. This idea suggests a useful baseline, i.e., given an ambiguous word, choose the tag which is most frequent in the corpus. This is a key concept in the Frequent Class tagging approach . Let’s explore some common baseline and more sophisticated POS tagging techniques. Rule-Based TaggingRule-based tagging is the oldest tagging approach where we use contextual information to assign tags to unknown or ambiguous words. The rule-based approach uses a dictionary to get possible tags for tagging each word. If the word has more than one possible tag, then rule-based taggers use hand-written rules to identify the correct tag. Since rules are usually built manually, therefore they are also called Knowledge-driven taggers. We have a limited number of rules, approximately around 1000 for the English language. One of example of a rule is as follows: Sample Rule: If an ambiguous word “X” is preceded by a determiner and followed by a noun , tag it as an adjective ; A nice car: nice is an ADJECTIVE here. Limitations/Disadvantages of Rule-Based Approach: - High development cost and high time complexity when applying to a large corpus of text
- Defining a set of rules manually is an extremely cumbersome process and is not scalable at all
Stochastic POS TaggingStochastic POS Tagger uses probabilistic and statistical information from the corpus of labeled text (where we know the actual tags of words in the corpus) to assign a POS tag to each word in a sentence. This tagger can use techniques like Word frequency measurements and Tag Sequence Probabilities . It can either use one of these approaches or a combination of both. Let’s discuss these techniques in detail. Word Frequency MeasurementsThe tag encountered most frequently in the corpus is the one assigned to the ambiguous words(words having 2 or more possible POS tags). Let’s understand this approach using some example sentences : Ambiguous Word = “play” Sentence 1 : I play cricket every day. POS tag of play = VERB Sentence 2 : I want to perform a play . POS tag of play = NOUN The word frequency method will now check the most frequently used POS tag for “ play ”. Let’s say this frequent POS tag happens to be VERB ; then we assign the POS tag of "play” = VERB The main drawback of this approach is that it can yield invalid sequences of tags. Tag Sequence ProbabilitiesIn this method, the best tag for a given word is determined by the probability that it occurs with “n” previous tags. Simply put, assume we have a new sequence of 4 words, w 1 w 2 w 3 w 4 w_1 ~w_2~ w_3 ~w_4 w 1 w 2 w 3 w 4 And we need to identify the POS tag of w 4 w_4 w 4 . If n = 3, we will consider the POS tags of 3 words prior to w4 in the labeled corpus of text Let’s say the POS tags for w 1 w_1 w 1 = NOUN, w 2 w_2 w 2 = VERB , w 3 w_3 w 3 = DETERMINER In short, N, V, D: NVD Then in the labeled corpus of text, we will search for this NVD sequence. Let’s say we found 100 such NVD sequences. Out of these - 10 sequences have the POS of the next word is NOUN 90 sequences have the POS of the next word is VERB Then the POS of the word w 4 w_4 w 4 = VERB The main drawback of this technique is that sometimes the predicted sequence is not Grammatically correct. Now let’s discuss some properties and limitations of the Stochastic tagging approach : - This POS tagging is based on the probability of the tag occurring (either solo or in sequence)
- It requires labeled corpus, also called training data in the Machine Learning lingo
- There would be no probability for the words that don’t exist in the training data
- It uses a different testing corpus (unseen text) other than the training corpus
- It is the simplest POS tagging because it chooses the most frequent tags associated with a word in the training corpus
Transformation-Based Learning Tagger: TBLTransformation-based tagging is the combination of Rule-based & stochastic tagging methodologies. In Layman's terms; The algorithm keeps on searching for the new best set of rules given input as labeled corpus until its accuracy saturates the labeled corpus. Algorithm takes following Input : - a tagged corpus
- a dictionary of words with the most frequent tags
Output : Sequence of transformation rules Example of sample rule learned by this algorithm: Rule : Change Noun(NN) to Verb(VB) when previous tag is To(TO) E.g.: race has the following probabilities in the Brown corpus - Probability of tag is NOUN given word is race P(NN | race) = 98% Probability of tag is VERB given word is race P(VB | race) = 0.02 Given sequence: is expected to race tomorrow First tag race with NOUN (since its probability of being NOUN is 98% ) Then apply the above rule and retag the POS of race with VERB (since just the previous tag before the “race” word is TO ) The Working of the TBL AlgorithmStep 1: Label every word with the most likely tag via lookup from the input dictionary. Step 2: Check every possible transformation & select one which most improves tagging accuracy. Similar to the above sample rule, other possible (maybe worst transformations) rules could be - - Change Noun(NN) to Determiner(DT) when previous tag is To(TO)
- Change Noun(NN) to Adverb(RB) when previous tag is To(TO)
- Change Noun(NN) to Adjective(JJ) when previous tag is To(TO)
Step 3: Re-tag corpus by applying all possible transformation rules Repeat Step 1,2,3 as many times as needed until accuracy saturates or you reach some predefined accuracy cutoff. Advantages and Drawbacks of the TBL Algorithm- We can learn a small set of simple rules, and these rules are decent enough for basic POS tagging
- Development, as well as debugging, is very easy in TBL because the learned rules are easy to understand
- Complexity in tagging is reduced because, in TBL, there is a cross-connection between machine-learned and human-generated rules
Despite being a simple and somewhat effective approach to POS tagging, TBL has major disadvantages. - TBL algorithm training/learning time complexity is very high, and time increases multi-fold when corpus size increases
- TBL does not provide tag probabilities
Hidden Markov Model POS Tagging: HMMHMM is a probabilistic sequence model, i.e., for POS tagging a given sequence of words, it computes a probability distribution over possible sequences of POS labels and chooses the best label sequence. This makes HMM model a good and reliable probabilistic approach to finding POS tags for the sequence of words. We’ll explore the important aspects of HMM in this section; we’ll see a few mathematical equations in an easily understandable manner. Motivation: Before diving deep into the HMM model concepts let’s first understand the elementary First Order Markov Model (or Markov Chain) with real-life examples. Assume we have three types of weather conditions: sunny, rainy, and foggy. The problem at hand is to predict the next day’s weather using the previous day's weather. Let q n = variable denoting the weather on the n th day We want to find the probability of q n given weather conditions of previous {n-1} days. This can be mathematically written as : P ( q n ∣ q n − 1 , q n − 2 , . . . . . . . . . . . . . , q 1 ) = ? P(q_n | q_{n-1}, q_{n-2} ,............., q_1) = ? P ( q n ∣ q n − 1 , q n − 2 , . . . . . . . . . . . . . , q 1 ) = ? According to first-order Markov Assumption - The weather condition on the nth day is only dependent on the weather of (n-1)th day. i.e. tomorrow’s weather is only dependent on today's weather conditions only. So the above equation boils down to the following: P ( q n ∣ q n − 1 , q n − 2 , . . . . . . . . . . . . . , q 1 ) = P ( q n ∣ q n − 1 ) P(q_n | q_{n-1}, q_{n-2} ,............., q_1) = P(q_n | q_{n-1}) P ( q n ∣ q n − 1 , q n − 2 , . . . . . . . . . . . . . , q 1 ) = P ( q n ∣ q n − 1 ) Consider the example below for probability computation :  P(Tomorrow’s weather = “Rainy” | Today’s weather = “Sunny” ) = 0.05 P(Tomorrow’s weather = “Rainy” | Today’s weather = “Rainy” ) = 0.6 Let's solve a simple Question ? Given that today’s weather is sunny, what is the probability that tomorrow will be sunny and the day after will be rainy? Mathematically P ( q 2 = s u n n y , q 3 = r a i n y ∣ q 1 = s u n n y ) P(q_2 = sunny, q_3 = rainy | q_1 = sunny) P ( q 2 = s u n n y , q 3 = r a i n y ∣ q 1 = s u n n y ) ? Let’s do simple calculations : P ( q 2 = s u n n y , q 3 = r a i n y ∣ q 1 = s u n n y ) P(q_2 = sunny, q_3 = rainy | q_1 = sunny) P ( q 2 = s u n n y , q 3 = r a i n y ∣ q 1 = s u n n y ) = P ( q 3 = r a i n y ∣ q 2 = s u n n y , q 1 = s u n n y ) × P ( q 2 = s u n n y ∣ q 1 = s u n n y ) = P(q_3 = rainy | q_2 = sunny, q_1 = sunny) × P(q_2 = sunny | q_1 = sunny) = P ( q 3 = r a i n y ∣ q 2 = s u n n y , q 1 = s u n n y ) × P ( q 2 = s u n n y ∣ q 1 = s u n n y ) {using first-order Markov Assumption} = P ( q 3 = r a i n y ∣ q 2 = s u n n y ) × P ( q 2 = s u n n y ∣ q 1 = s u n n y ) P(q_3 = rainy | q_2 = sunny) × P(q_2 = sunny | q_1 = sunny) P ( q 3 = r a i n y ∣ q 2 = s u n n y ) × P ( q 2 = s u n n y ∣ q 1 = s u n n y ) = 0 . 0 5 × 0 . 8 = 0.05 × 0.8 = 0 . 0 5 × 0 . 8 = 0 . 0 4 = 0.04 = 0 . 0 4 Hidden Markov ModelA Markov chain is useful when we need to compute a probability for a sequence of observable events. In many cases, the events we are interested in are hidden, i.e., we don’t observe them directly. For example, we don’t normally observe part-of-speech tags in a text. Rather, we see words and must infer the tags from the word sequence. We call the tags hidden because they are not observed. A hidden Markov model (HMM) allows us to talk about both observed events (like words that we see in the input) and hidden events (like part-of-speech tags). Simply in HMM, we consider the following; Words : Observed POS tags : Hidden HMM is a Probabilistic model; we find the most likely sequence of tags T for a sequence of words W W = w 1 . . . . . w n − − − − − − − − w o r d s i n t h e s e q u e n c e ( o b s e r v e d ) W = w_1. . . . . w_n --------words in the sequence (observed) W = w 1 . . . . . w n − − − − − − − − w o r d s i n t h e s e q u e n c e ( o b s e r v e d ) T = t 1 . . . . . t n − − − − − − − − − − t h e c o r r e s p o n d i n g P O S t a g s ( h i d d e n / u n k n o w n ) T = t_1. . . . .t_n ---------- the corresponding POS tags (hidden/unknown) T = t 1 . . . . . t n − − − − − − − − − − t h e c o r r e s p o n d i n g P O S t a g s ( h i d d e n / u n k n o w n ) Objective of HMM: We want to find out the probabilities of possible tag sequences given word sequences. i.e. P(T | W ) And select the tag sequence that has the highest probability Mathematically we write it like this; a r g m a x T P ( T ∣ W ) argmax_T~ P~(~T~ |~ W~ ) a r g m a x T P ( T ∣ W ) Using the Bayes Theorem ; P ( T ∣ W ) P(T | W ) P ( T ∣ W ) can be written as : P ( T ∣ W ) = P ( W ∣ T ) ∗ P ( T ) / P ( W ) P(T | W ) = P(W | T) * P(T) / P(W) P ( T ∣ W ) = P ( W ∣ T ) ∗ P ( T ) / P ( W ) P(W) : Probability of Word sequence remain same So we can just approximate** P(T | W)** as : P ( T ∣ W ) = P ( W ∣ T ) ∗ P ( T ) P~(~T~ |~ W~ )~ =~ P~(~W~ |~ T~)~ *~ P~(~T~) P ( T ∣ W ) = P ( W ∣ T ) ∗ P ( T ) We have already stated that W and T are word and tag sequences. Therefore we can write the above equation as follows: P ( T ∣ W ) = P ( w 1 > . . . . . w n ∣ t 1 . . . . . t n ) ∗ P ( t 1 > . . . . . t n ) − − − − − m a i n e q u a t i o n P(T | W ) = P(w_1> . . . . . w_n | t_1 . . . . . t_n) * P(t_1> . . . . . t_n) - - - - - {main~ equation} P ( T ∣ W ) = P ( w 1 > . . . . . w n ∣ t 1 . . . . . t n ) ∗ P ( t 1 > . . . . . t n ) − − − − − m a i n e q u a t i o n Let’s break down the component of this main equation. First Part of Main Equation P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = P ( w ∣ t 1 . . . . . t n ) ∗ P ( w 2 ∣ t 1 . . . . . t n ) . . . . . . . . . . . . . . . . P ( w n ∣ t 1 . . . . . t n ) P(w_1 . . . . . w_n | t_1 . . . . . t_n) = P(w | t_1 . . . . . t_n) * P(w_2 | t_1 . . . . . t_n)................ P(w_n | t_1 . . . . . t_n) P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = P ( w ∣ t 1 . . . . . t n ) ∗ P ( w 2 ∣ t 1 . . . . . t n ) . . . . . . . . . . . . . . . . P ( w n ∣ t 1 . . . . . t n ) Using the first-order Markov assumption, The probability of a word appearing depends only on its own POS tag. P ( w 1 ∣ t 1 . . . . . t n ) = P ( w 1 ∣ t 1 P(w_1 | t_1 . . . . . t_n) = P(w_1 | t_1 P ( w 1 ∣ t 1 . . . . . t n ) = P ( w 1 ∣ t 1 P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = P ( w 1 ∣ t 1 ) ∗ P ( w 2 ∣ t 2 ) ∗ . . . . . . . . . . . . . . . . ∗ P ( w n ∣ t n ) P(w_1 . . . . . w_n | t_1 . . . . . t_n) = P(w_1 | t_1) * P(w_2 | t_2) * ................ * P(w_n | t_n) P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = P ( w 1 ∣ t 1 ) ∗ P ( w 2 ∣ t 2 ) ∗ . . . . . . . . . . . . . . . . ∗ P ( w n ∣ t n ) P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = ∗ ∏ i = 1 n ∗ P ( w i ∣ t i ) P(w_1 . . . . . w_n | t_1 . . . . . t_n) =* \prod_{i=1}^{n}*P(w_i | t_i) P ( w 1 . . . . . w n ∣ t 1 . . . . . t n ) = ∗ ∏ i = 1 n ∗ P ( w i ∣ t i ) Second Part of Main Equation P ( t 1 . . . . . t n ) = ? P(t_1 . . . . . t_n) = ? P ( t 1 . . . . . t n ) = ? The probability of a tag is dependent only on the previous tag rather than the entire tag sequence - Also called Bigram assumption P ( t 1 . . . . . t n ) = ∗ ∏ i = 1 n ∗ P ( t i ∣ t i − 1 ) P(t_1 . . . . . t_n) =* \prod_{i=1}^{n}*P(t_i | t_{i-1} ) P ( t 1 . . . . . t n ) = ∗ ∏ i = 1 n ∗ P ( t i ∣ t i − 1 ) Therefore the main equation becomes : P ( T ∣ W ) = ∗ ∏ i = 1 n ∗ P ( w i ∣ t i ) ∗ ∏ i = 1 n ∗ P ( t i ∣ t i − 1 ) P(T | W) =* \prod_{i=1}^{n}*P(w_i | t_i )* \prod_{i=1}^{n}*P(t_i | t_{i-1} ) P ( T ∣ W ) = ∗ ∏ i = 1 n ∗ P ( w i ∣ t i ) ∗ ∏ i = 1 n ∗ P ( t i ∣ t i − 1 ) For possible POS tag sequences (T), we compute this probability and consider that tag sequence that gives the maximum value of quantity. ∏ i = 1 n P ( w 1 ∣ t i < / s u b > ) \prod_{i=1}^{n}P(w_1 | t_i</sub> ) ∏ i = 1 n P ( w 1 ∣ t i < / s u b > ) : Word likelihood probabilities or emission probability ∏ i = 1 n P ( t i ∣ t i − 1 ) \prod_{i=1}^{n}P(t_i | t_{i-1} ) ∏ i = 1 n P ( t i ∣ t i − 1 ) : Tag Transition probabilities The computation of the above probabilities requires a dynamic programming approach, and the algorithm is called The Viterbi Algorithm . Understanding the Viterbi algorithm requires another article in itself. Below is a simple example of the computation of Word likelihood probabilities and Tag Transition probabilities from the Brown corpus - Tag Transition probabilities p ( t i ∣ t i − 1 ) p\left(t_i \mid t_{i-1}\right) p ( t i ∣ t i − 1 ) Word Likelihood probabilities p ( w i ∣ t i ) p\left(w_i \mid t_i\right) p ( w i ∣ t i ) Tagging Unknown WordsIt is very much possible that we encounter new/unseen words while tagging sentences/sequences of words. All of the approaches/algorithms discussed above will fail if this happens. For example, on average new words are added to newspapers/language 20+ per month. Few Hacks/Techniques to Tackle New Words: - Assume they are nouns (most of the new words we see falls into the NOUN (NN) POS
- Use capitalisation, suffixes, etc. This works very well for morphologically complex
- We could look at the new word's internal structure, such as assigning NOUNS (NNS) for words ending in 's.'
- For probabilistic-based models, new word probabilities are zero, and there are smoothing techniques. A naïve technique is to add a small frequency count (say 1) to all words, including unknown words
In this article, we discussed a very high-level overview of POS tagging a sequence of words/sentences without deep diving into too much math, technical jargon, and code. We discussed the following in this article: - Understood what POS tagging is, why this is very useful in NLP, also why POS tagging difficult
- We have understood the word classes and semantic structure of sentences and seen a popular POS tagset from the University of Pennsylvania’s “UPenn Treebank tagset.”
- We discussed basic Rule based tagging and Stochastic tagging approaches
- Introduced Transformation based tagging, which is the combination of Rule-based & stochastic tagging approaches
- Then, finally, we discussed important aspects of the very popular POS tagging approach Hidden Markov Model .
A deep dive into part-of-speech tagging using the Viterbi algorithm By Sachin Malhotra by Sachin Malhotra and Divya Godayal  Welcome back, Caretaker! In case you’ve forgotten the problem we were trying to tackle in the previous article, let us revise it for you. So there’s this naughty kid Peter and he’s going to pester his new caretaker, you! As a caretaker, one of the most important tasks for you is to tuck Peter in bed and make sure he is sound asleep. Once you’ve tucked him in, you want to make sure that he’s actually asleep and not up to some mischief. You cannot, however, enter the room again, as that would surely wake Peter up. All you can hear are the noises that might come from the room. Either the room is quiet or there is noise coming from the room. These are your observations. All you have as the caretaker are: - a set of observations, which is basically a sequence containing noise or quiet over time, and
- A state diagram provided by Peter’s mom — who happens to be a neurological scientist — that contains all the different sets of probabilities that you can use to solve the problem defined below.
The problemGiven the state diagram and a sequence of N observations over time, we need to tell the state of the baby at the current point in time. Mathematically, we have N observations over times t0, t1, t2 .... tN . We want to find out if Peter would be awake or asleep, or rather which state is more probable at time tN+1 . In case any of this seems like Greek to you, go read the previous article to brush up on the Markov Chain Model, Hidden Markov Models, and Part of Speech Tagging.  In that previous article , we had briefly modeled the problem of Part of Speech tagging using the Hidden Markov Model. The problem of Peter being asleep or not is just an example problem taken up for a better understanding of some of the core concepts involved in these two articles. At the core, the articles deal with solving the Part of Speech tagging problem using the Hidden Markov Models. So, before moving on to the Viterbi Algorithm , let’s first look at a much more detailed explanation of how the tagging problem can be modeled using HMMs. Generative Models and the Noisy Channel ModelA lot of problems in Natural Language Processing are solved using a supervised learning approach. Supervised problems in machine learning are defined as follows. We assume training examples (x(1), y(1)) . . . (x(m) , y(m)) , where each example consists of an input x(i) paired with a label y(i) . We use X to refer to the set of possible inputs, and Y to refer to the set of possible labels. Our task is to learn a function f : X → Y that maps any input x to a label f(x). In tagging problems, each x(i) would be a sequence of words X1 X2 X3 …. Xn(i) , and each y(i) would be a sequence of tags Y1 Y2 Y3 … Yn(i) (we use n(i)to refer to the length of the i’th training example). X would refer to the set of all sequences x1 . . . xn, and Y would be the set of all tag sequences y1 . . . yn. Our task would be to learn a function f : X → Y that maps sentences to tag sequences. An intuitive approach to get an estimate for this problem is to use conditional probabilities. p(y | x) which is the probability of the output y given an input x. The parameters of the model would be estimated using the training samples. Finally, given an unknown input x we would like to find f(x) = arg max(p(y | x)) ∀y ∊ Y This here is the conditional model to solve this generic problem given the training data. Another approach that is mostly adopted in machine learning and natural language processing is to use a generative model . Rather than directly estimating the conditional distribution p(y|x) , in generative models we instead model the joint probability p(x, y) over all the (x, y) pairs. We can further decompose the joint probability into simpler values using Bayes’ rule:  - p(y) is the prior probability of any input belonging to the label y.
- p(x | y) is the conditional probability of input x given the label y.
We can use this decomposition and the Bayes rule to determine the conditional probability.  Remember, we wanted to estimate the function The reason we skipped the denominator here is because the probability p(x) remains the same no matter what the output label being considered. And so, from a computational perspective, it is treated as a normalization constant and is normally ignored. Models that decompose a joint probability into terms p(y) and p(x|y) are often called noisy-channel models . Intuitively, when we see a test example x, we assume that it has been generated in two steps: - first, a label y has been chosen with probability p(y)
- second, the example x has been generated from the distribution p(x|y). The model p(x|y) can be interpreted as a “channel” which takes a label y as its input, and corrupts it to produce x as its output.
Generative Part of Speech Tagging ModelLet us assume a finite set of words V and a finite sequence of tags K. Then the set S will be the set of all sequence, tags pairs <x1, x2, x3 ... xn, y1, y2, y3, ..., yn> such that n > 0 ∀x ∊ V a nd ∀y ∊ K . A generative tagging model is then the one where  Given a generative tagging model, the function that we talked about earlier from input to output becomes  Thus for any given input sequence of words, the output is the highest probability tag sequence from the model. Having defined the generative model, we need to figure out three different things: - How exactly do we define the generative model probability p(<x1, x2, x3 ... xn, y1, y2, y3, ..., y n>)
- How do we estimate the parameters of the model, and
- How do we efficiently calculate
 Let us look at how we can answer these three questions side by side, once for our example problem and then for the actual problem at hand: part of speech tagging. Defining the Generative ModelLet us first look at how we can estimate the probability p(x1 .. xn, y1 .. yn) using the HMM. We can have any N-gram HMM which considers events in the previous window of size N. The formulas provided hereafter are corresponding to a Trigram Hidden Markov Model. Trigram Hidden Markov ModelA trigram Hidden Markov Model can be defined using - A finite set of states.
- A sequence of observations.
- q(s|u, v) Transition probability defined as the probability of a state “s” appearing right after observing “u” and “v” in the sequence of observations.
- e(x|s) Emission probability defined as the probability of making an observation x given that the state was s.
Then, the generative model probability would be estimated as  As for the baby sleeping problem that we are considering, we will have only two possible states: that the baby is either awake or he is asleep. The caretaker can make only two observations over time. Either there is noise coming in from the room or the room is absolutely quiet. The sequence of observations and states can be represented as follows:  Coming on to the part of speech tagging problem, the states would be represented by the actual tags assigned to the words. The words would be our observations. The reason we say that the tags are our states is because in a Hidden Markov Model, the states are always hidden and all we have are the set of observations that are visible to us. Along similar lines, the sequence of states and observations for the part of speech tagging problem would be  Estimating the model’s parametersWe will assume that we have access to some training data. The training data consists of a set of examples where each example is a sequence consisting of the observations, every observation being associated with a state. Given this data, how do we estimate the parameters of the model? Estimating the model’s parameters is done by reading various counts off of the training corpus we have, and then computing maximum likelihood estimates:  We already know that the first term represents transition probability and the second term represents the emission probability. Let us look at what the four different counts mean in the terms above. - c(u, v, s) represents the trigram count of states u, v and s. Meaning it represents the number of times the three states u, v and s occurred together in that order in the training corpus.
- c(u, v) following along similar lines as that of the trigram count, this is the bigram count of states u and v given the training corpus.
- c(s → x) is the number of times in the training set that the state s and observation x are paired with each other. And finally,
- c(s) is the prior probability of an observation being labelled as the state s.
Let us look at a sample training set for the toy problem first and see the calculations for transition and emission probabilities using the same. The BLUE markings represent the transition probability, and RED is for emission probability calculations. Note that since the example problem only has two distinct states and two distinct observations, and given that the training set is very small, the calculations shown below for the example problem are using a bigram HMM instead of a trigram HMM. Peter’s mother was maintaining a record of observations and states. And thus she even provided you with a training corpus to help you get the transition and emission probabilities. Transition Probability Example: Emission Probability Example: That was quite simple, since the training set was very small. Let us look at a sample training set for our actual problem of part of speech tagging. Here we can consider a trigram HMM, and we will show the calculations accordingly. We will use the following sentences as a corpus of training data (the notation word/TAG means word tagged with a specific part-of-speech tag).  The training set that we have is a tagged corpus of sentences. Every sentence consists of words tagged with their corresponding part of speech tags. eg:- eat/VB means that the word is “eat” and the part of speech tag in this sentence in this very context is “VB” i.e. Verb Phrase. Let us look at a sample calculation for transition probability and emission probability just like we saw for the baby sleeping problem. Transition ProbabilityLet’s say we want to calculate the transition probability q(IN | VB, NN). For this, we see how many times we see a trigram (VB,NN,IN) in the training corpus in that specific order. We then divide it by the total number of times we see the bigram (VB,NN) in the corpus. Emission ProbabilityLet’s say we want to find out the emission probability e(an | DT). For this, we see how many times the word “an” is tagged as “DT” in the corpus and divide it by the total number of times we see the tag “DT” in the corpus.  So if you look at these calculations, it shows that calculating the model’s parameters is not computationally expensive. That is, we don’t have to do multiple passes over the training data to calculate these parameters. All we need are a bunch of different counts, and a single pass over the training corpus should provide us with that. Let’s move on and look at the final step that we need to look at given a generative model. That step is efficiently calculating  We will be looking at the famous Viterbi Algorithm for this calculation. Finding the most probable sequence — Viterbi AlgorithmFinally, we are going to solve the problem of finding the most likely sequence of labels given a set of observations x1 … xn. That is, we are to find out  The probability here is expressed in terms of the transition and emission probabilities that we learned how to calculate in the previous section of the article. Just to remind you, the formula for the probability of a sequence of labels given a sequence of observations over “n” time steps is  Before looking at an optimized algorithm to solve this problem, let us first look at a simple brute force approach to this problem. Basically, we need to find out the most probable label sequence given a set of observations out of a finite set of possible sequences of labels. Let’s look at the total possible number of sequences for a small example for our example problem and also for a part of speech tagging problem. Say we have the following set of observations for the example problem. We have two possible labels {Asleep and Awake}. Some of the possible sequence of labels for the observations above are: In all we can have 2³ = 8 possible sequences. This might not seem like very many, but if we increase the number of observations over time, the number of sequences would increase exponentially. This is the case when we only had two possible labels. What if we have more? As is the case with part of speech tagging. For example, consider the sentence and assuming that the set of possible tags are {D, N, V}, let us look at some of the possible tag sequences: Here, we would have 3³ = 27 possible tag sequences. And as you can see, the sentence was extremely short and the number of tags weren’t very many. In practice, we can have sentences that might be much larger than just three words. Then the number of unique labels at our disposal would also be too high to follow this enumeration approach and find the best possible tag sequence this way. So the exponential growth in the number of sequences implies that for any reasonable length sentence, the brute force approach would not work out as it would take too much time to execute. Instead of this brute force approach, we will see that we can find the highest probable tag sequence efficiently using a dynamic programming algorithm known as the Viterbi Algorithm. Let us first define some terms that would be useful in defining the algorithm itself. We already know that the probability of a label sequence given a set of observations can be defined in terms of the transition probability and the emission probability. Mathematically, it is  Let us look at a truncated version of this which is  and let us call this the cost of a sequence of length k. So the definition of “r” is simply considering the first k terms off of the definition of probability where k ∊ {1..n} and for any label sequence y1…yk. Next we have the set S(k, u, v) which is basically the set of all label sequences of length k that end with the bigram (u, v) i.e.  Finally, we define the term π(k, u, v) which is basically the sequence with the maximum cost.  The main idea behind the Viterbi Algorithm is that we can calculate the values of the term π(k, u, v) efficiently in a recursive, memoized fashion. In order to define the algorithm recursively, let us look at the base cases for the recursion. Since we are considering a trigram HMM, we would be considering all of the trigrams as a part of the execution of the Viterbi Algorithm. Now, we can start the first trigram window from the first three words of the sentence but then the model would miss out on those trigrams where the first word or the first two words occurred independently. For that reason, we consider two special start symbols as * and so our sentence becomes And the first trigram we consider then would be ( , , x1) and the second one would be (*, x1, x2). Now that we have all our terms in place, we can finally look at the recursive definition of the algorithm which is basically the heart of the algorithm.  This definition is clearly recursive, because we are trying to calculate one π term and we are using another one with a lower value of k in the recurrence relation for it.  Every sequence would end with a special STOP symbol. For the trigram model, we would also have two special start symbols “*” in the beginning. Have a look at the pseudo-code for the entire algorithm.  The algorithm first fills in the π(k, u, v) values in using the recursive definition. It then uses the identity described before to calculate the highest probability for any sequence. The running time for the algorithm is O(n|K|³), hence it is linear in the length of the sequence, and cubic in the number of tags. NOTE: We would be showing calculations for the baby sleeping problem and the part of speech tagging problem based off a bigram HMM only. The calculations for the trigram are left to the reader to do themselves. But the code that is attached at the end of this article is based on a trigram HMM. It’s just that the calculations are easier to explain and portray for the Viterbi algorithm when considering a bigram HMM instead of a trigram HMM. Therefore, before showing the calculations for the Viterbi Algorithm, let us look at the recursive formula based on a bigram HMM.  This one is extremely similar to the one we saw before for the trigram model, except that now we are only concerning ourselves with the current label and the one before, instead of two before. The complexity of the algorithm now becomes O(n|K|²). Calculations for Baby Sleeping ProblemNow that we have the recursive formula ready for the Viterbi Algorithm, let us see a sample calculation of the same firstly for the example problem that we had, that is, the baby sleeping problem, and then for the part of speech tagging version. Note that when we are at this step, that is, the calculations for the Viterbi Algorithm to find the most likely tag sequence given a set of observations over a series of time steps, we assume that transition and emission probabilities have already been calculated from the given corpus. Let’s have a look at a sample of transition and emission probabilities for the baby sleeping problem that we would use for our calculations of the algorithm.  The baby starts by being awake, and remains in the room for three time points, t1 . . . t3 (three iterations of the Markov chain). The observations are: quiet, quiet, noise. Have a look at the following diagram that shows the calculations for up to two time-steps. The complete diagram with all the final set of values will be shown afterwards.  We have not shown the calculations for the state of “asleep” at k = 2 and the calculations for k = 3 in the above diagram to keep things simple. Now that we have all these calculations in place, we want to calculate the most likely sequence of states that the baby can be in over the different given time steps. So, for k = 2 and the state of Awake, we want to know the most likely state at k = 1 that transitioned to Awake at k = 2. (k = 2 represents a sequence of states of length 3 starting off from 0 and t = 2 would mean the state at time-step 2. We are given the state at t = 0 i.e. Awake).  Clearly, if the state at time-step 2 was AWAKE, then the state at time-step 1 would have been AWAKE as well, as the calculations point out. So, the Viterbi Algorithm not only helps us find the π(k) values, that is the cost values for all the sequences using the concept of dynamic programming, but it also helps us to find the most likely tag sequence given a start state and a sequence of observations. The algorithm, along with the pseudo-code for storing the back-pointers is given below.  Calculations for the Part of Speech Tagging ProblemLet us look at a slightly bigger corpus for the part of speech tagging and the corresponding Viterbi graph showing the calculations and back-pointers for the Viterbi Algorithm. Here is the corpus that we will consider:  Now take a look at the transition probabilities calculated from this corpus.  Here, q0 → VB represents the probability of a sentence starting off with the tag VB, that is the first word of a sentence being tagged as VB. Similarly, q0 → NN represents the probability of a sentence starting with the tag NN. Notice that out of 10 sentences in the corpus, 8 start with NN and 2 with VB and hence the corresponding transition probabilities. As for the emission probabilities, ideally we should be looking at all the combinations of tags and words in the corpus. Since that would be too much, we will only consider emission probabilities for the sentence that would be used in the calculations for the Viterbi Algorithm. The emission probabilities for the sentence above are:  Finally, we are ready to see the calculations for the given sentence, transition probabilities, emission probabilities, and the given corpus.  So, is that all there is to the Viterbi Algorithm ? Take a look at the example below. The bucket below each word is filled with the possible tags seen next to the word in the training corpus. The given sentence can have the combinations of tags depending on which path we take. But there is a catch. Can you figure out what that is?  Were you able to figure it out? Let me tell you what it is. There might be some path in the computation graph for which we do not have a transition probability. So our algorithm can just discard that path and take the other path.  In the above diagram, we discard the path marked in red since we do not have q(VB|VB). The training corpus never has a VB followed by VB . So in the Viterbi calculations, we end up taking q(VB|VB) = 0. And if you’ve been following the algorithm along closely, you would find that a single 0 in the calculations would make the entire probability or the maximum cost for a sequence of tags / labels to be 0. This however means that we are ignoring the combinations which are not seen in the training corpus. Is that the right way to approach the real world examples? Consider a small tweak in the above sentence.  In this sentence we do not have any alternative path. Even if we have Viterbi probability until we reach the word “like”, we cannot proceed further. Since both q(VB|VB) = 0 and q(VB|IN) = 0. What do we do now? The corpus that we considered here was very small. Consider any reasonably sized corpus with a lot of words and we have a major problem of sparsity of data. Take a look below.  That means that we can have a potential 68 billion bigrams but the number of words in the corpus are just under a billion. That is a huge number of zero transition probabilities to fill up. The problem of sparsity of data is even more elaborate in case we are considering trigrams. To solve this problem of data sparsity, we resort to a solution called Smoothing. The idea behind Smoothing is just this: - Discount — the existing probability values somewhat and
- Reallocate — this probability to the zeroes
In this way, we redistribute the non zero probability values to compensate for the unseen transition combinations. Let us consider a very simple type of smoothing technique known as Laplace Smoothing. Laplace smoothing is also known as one count smoothing. You will understand exactly why it goes by that name in a moment. Let’s revise how the parameters for a trigram HMM model are calculated given a training corpus.  The possible values that can go wrong here are - c(u, v, s) is 0
- c(u, v) is 0
- We get an unknown word in the test sentence, and we don’t have any training tags associated with it.
All these can be solved via smoothing. So the Laplace smoothing counts would become  Here V is the total number of tags in our corpus and λ is basically a real value between 0 and 1. It acts like a discounting factor. A λ = 1 value would give us too much of a redistribution of values of probabilities. For example:  Too much of a weight is given to unseen trigrams for λ = 1 and that is why the above mentioned modified version of Laplace Smoothing is considered for all practical applications. The value of the discounting factor is to be varied from one application to another. Note that λ = 1 would only create a problem if the vocabulary size is too large. For a smaller corpus, λ = 1 would give us a good performance to start off with. A thing to note about Laplace Smoothing is that it is a uniform redistribution, that is, all the trigrams that were previously unseen would have equal probabilities. So, suppose we are given some data and we observe that - Frequency of trigram is zero
- Frequency of trigram is also zero
- Uniform distribution over unseen events means: P(thing|gave, the) = P(think|gave, the)
Does that reflect our knowledge about English use? P(thing|gave, the) > P(think|gave, the) ideally, but uniform distribution using Laplace smoothing will not consider this. This means that millions of unseen trigrams in a huge corpus would have equal probabilities when they are being considered in our calculations. That is probably not the right thing to do. However, it is better than to consider the 0 probabilities which would lead to these trigrams and eventually some paths in the Viterbi graph getting completely ignored. But this still needs to be worked upon and made better. There are, however, a lot of different types of smoothing techniques that improve upon the basic Laplace Smoothing technique and help overcome this problem of uniform distribution of probabilities. Some of these techniques are: - Good-Turing estimate
- Jelinek-Mercer smoothing (interpolation)
- Katz smoothing (backoff)
- Witten-Bell smoothing
- Absolute discounting
- Kneser-Ney smoothing
To read more on these different types of smoothing techniques in more detail, refer to this tutorial. Which smoothing technique to choose highly depends upon the type of application at hand, the type of data being considered, and also on the size of the data set. If you have been following along this lengthy article, then I must say  Let’s move on and look at a slight optimization that we can do to the Viterbi algorithm that can reduce the number of computations and that also makes sense for a lot of data sets out there. Before that, however, look at the pseudo-code for the algorithm once again.  If we look closely, we can see that for every trigram of words, we are considering all possible set of tags. That is, if the number of tags are V, then we are considering |V|³ number of combinations for every trigram of the test sentence. Ignore the trigram for now and just consider a single word. We would be considering all of the unique tags for a given word in the above mentioned algorithm. Consider a corpus where we have the word “kick” which is associated with only two tags, say {NN, VB} and the total number of unique tags in the training corpus are around 500 (it’s a huge corpus).  Now the problem here is apparent. We might end up assigning a tag that doesn’t make sense with the word under consideration, simply because the transition probability of the trigram ending at the tag was very high, like in the example shown above. Also, it would be computationally inefficient to consider all 500 tags for the word “kick” if it only ever occurs with two unique tags in the entire corpus. So, the optimization we do is that for every word, instead of considering all the unique tags in the corpus, we just consider the tags that it occurred with in the corpus . This would work because, for a reasonably large corpus, a given word would ideally occur with all the various set of tags with which it can occur (most of them at-least). Then it would be reasonable to simply consider just those tags for the Viterbi algorithm. As far as the Viterbi decoding algorithm is concerned, the complexity still remains the same because we are always concerned with the worst case complexity. In the worst case, every word occurs with every unique tag in the corpus, and so the complexity remains at O(n|V|³) for the trigram model and O(n|V|²) for the bigram model. For the recursive implementation of the code, please refer to DivyaGodayal/HMM-POS-Tagger _HMM-POS-Tagger — An HMM based Part of Speech Tagger implementation using Laplace Smoothing and Trigram HMMs_github.com The recursive implementation is done along with Laplace Smoothing. For the iterative implementation, refer to edorado93/HMM-Part-of-Speech-Tagger _HMM-Part-of-Speech-Tagger — An HMM based Part of Speech Tagger_github.com This implementation is done with One-Count Smoothing technique which leads to better accuracy as compared to the Laplace Smoothing. A lot of snapshots of formulas and calculations in the two articles are derived from [here](http://1. http://www.cs.columbia.edu/~mcollins/courses/nlp2011/notes/hmms.pdf). Do let us know how this blog post helped you, and point out the mistakes if you find some while reading the article in the comments section below. Also, please recommend (by clapping) and spread the love as much as possible for this post if you think this might be useful for someone. If you read this far, thank the author to show them you care. Say Thanks Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started - Get started
- Installation
- Models & Languages
- Facts & Figures
- New in v3.7
- New in v3.6
- New in v3.5
- POS Tagging
- Lemmatization
- Dependency Parse
- Named Entities
Entity LinkingTokenization. Sentence Segmentation- Mappings & Exceptions
- Vectors & Similarity
Language Data- Rule-based Matching
- Processing Pipelines
- Embeddings & Transformers
- Large Language Models new
- Training Models
- Layers & Model Architectures
- spaCy Projects
- Saving & Loading
- Visualizers
- Project Templates
- v2.x Documentation
- Custom Solutions
Linguistic FeaturesProcessing raw text intelligently is difficult: most words are rare, and it’s common for words that look completely different to mean almost the same thing. The same words in a different order can mean something completely different. Even splitting text into useful word-like units can be difficult in many languages. While it’s possible to solve some problems starting from only the raw characters, it’s usually better to use linguistic knowledge to add useful information. That’s exactly what spaCy is designed to do: you put in raw text, and get back a Doc object, that comes with a variety of annotations. Part-of-speech tagging Needs modelAfter tokenization, spaCy can parse and tag a given Doc . This is where the trained pipeline and its statistical models come in, which enable spaCy to make predictions of which tag or label most likely applies in this context. A trained component includes binary data that is produced by showing a system enough examples for it to make predictions that generalize across the language – for example, a word following “the” in English is most likely a noun. Linguistic annotations are available as Token attributes . Like many NLP libraries, spaCy encodes all strings to hash values to reduce memory usage and improve efficiency. So to get the readable string representation of an attribute, we need to add an underscore _ to its name: Editable Code spaCy v 3.7 · Python 3 · via Binder| Text | Lemma | POS | Tag | Dep | Shape | alpha | stop |
|---|
| Apple | apple | | | | | | | | is | be | | | | | | | | looking | look | | | | | | | | at | at | | | | | | | | buying | buy | | | | | | | | U.K. | u.k. | | | | | | | | startup | startup | | | | | | | | for | for | | | | | | | | $ | $ | | | | | | | | 1 | 1 | | | | | | | | billion | billion | | | | | | |
Using spaCy’s built-in displaCy visualizer , here’s what our example sentence and its dependencies look like: Inflectional morphology is the process by which a root form of a word is modified by adding prefixes or suffixes that specify its grammatical function but do not change its part-of-speech. We say that a lemma (root form) is inflected (modified/combined) with one or more morphological features to create a surface form. Here are some examples: | Context | Surface | Lemma | POS | Morphological Features |
|---|
| I was reading the paper | reading | read | | | | I don’t watch the news, I read the paper | read | read | | , , | | I read the paper yesterday | read | read | | , , |
Morphological features are stored in the MorphAnalysis under Token.morph , which allows you to access individual morphological features. Statistical morphology v 3.0 Needs modelspaCy’s statistical Morphologizer component assigns the morphological features and coarse-grained part-of-speech tags as Token.morph and Token.pos . Rule-based morphologyFor languages with relatively simple morphological systems like English, spaCy can assign morphological features through a rule-based approach, which uses the token text and fine-grained part-of-speech tags to produce coarse-grained part-of-speech tags and morphological features. - The part-of-speech tagger assigns each token a fine-grained part-of-speech tag . In the API, these tags are known as Token.tag . They express the part-of-speech (e.g. verb) and some amount of morphological information, e.g. that the verb is past tense (e.g. VBD for a past tense verb in the Penn Treebank) .
- For words whose coarse-grained POS is not set by a prior process, a mapping table maps the fine-grained tags to a coarse-grained POS tags and morphological features.
Lemmatization v 3.0spaCy provides two pipeline components for lemmatization: - The Lemmatizer component provides lookup and rule-based lemmatization methods in a configurable component. An individual language can extend the Lemmatizer as part of its language data .
- The EditTreeLemmatizer v 3.3 component provides a trainable lemmatizer.
The data for spaCy’s lemmatizers is distributed in the package spacy-lookups-data . The provided trained pipelines already include all the required tables, but if you are creating new pipelines, you’ll probably want to install spacy-lookups-data to provide the data when the lemmatizer is initialized. Lookup lemmatizerFor pipelines without a tagger or morphologizer, a lookup lemmatizer can be added to the pipeline as long as a lookup table is provided, typically through spacy-lookups-data . The lookup lemmatizer looks up the token surface form in the lookup table without reference to the token’s part-of-speech or context. Rule-based lemmatizer Needs modelWhen training pipelines that include a component that assigns part-of-speech tags (a morphologizer or a tagger with a POS mapping ), a rule-based lemmatizer can be added using rule tables from spacy-lookups-data : The rule-based deterministic lemmatizer maps the surface form to a lemma in light of the previously assigned coarse-grained part-of-speech and morphological information, without consulting the context of the token. The rule-based lemmatizer also accepts list-based exception files. For English, these are acquired from WordNet . Trainable lemmatizer Needs modelThe EditTreeLemmatizer can learn form-to-lemma transformations from a training corpus that includes lemma annotations. This removes the need to write language-specific rules and can (in many cases) provide higher accuracies than lookup and rule-based lemmatizers. Dependency Parsing Needs modelspaCy features a fast and accurate syntactic dependency parser, and has a rich API for navigating the tree. The parser also powers the sentence boundary detection, and lets you iterate over base noun phrases, or “chunks”. You can check whether a Doc object has been parsed by calling doc.has_annotation("DEP") , which checks whether the attribute Token.dep has been set returns a boolean value. If the result is False , the default sentence iterator will raise an exception. Noun chunksNoun chunks are “base noun phrases” – flat phrases that have a noun as their head. You can think of noun chunks as a noun plus the words describing the noun – for example, “the lavish green grass” or “the world’s largest tech fund”. To get the noun chunks in a document, simply iterate over Doc.noun_chunks . | Text | root.text | root.dep_ | root.head.text |
|---|
| Autonomous cars | cars | | shift | | insurance liability | liability | | shift | | manufacturers | manufacturers | | toward |
Navigating the parse treespaCy uses the terms head and child to describe the words connected by a single arc in the dependency tree. The term dep is used for the arc label, which describes the type of syntactic relation that connects the child to the head. As with other attributes, the value of .dep is a hash value. You can get the string value with .dep_ . | Text | Dep | Head text | Head POS | Children |
|---|
| Autonomous | | cars | | | | cars | | shift | | Autonomous | | shift | | shift | | cars, liability, toward | | insurance | | liability | | | | liability | | shift | | insurance | | toward | | shift | | manufacturers | | manufacturers | | toward | | |
Because the syntactic relations form a tree, every word has exactly one head . You can therefore iterate over the arcs in the tree by iterating over the words in the sentence. This is usually the best way to match an arc of interest – from below: If you try to match from above, you’ll have to iterate twice. Once for the head, and then again through the children: To iterate through the children, use the token.children attribute, which provides a sequence of Token objects. Iterating around the local treeA few more convenience attributes are provided for iterating around the local tree from the token. Token.lefts and Token.rights attributes provide sequences of syntactic children that occur before and after the token. Both sequences are in sentence order. There are also two integer-typed attributes, Token.n_lefts and Token.n_rights that give the number of left and right children. You can get a whole phrase by its syntactic head using the Token.subtree attribute. This returns an ordered sequence of tokens. You can walk up the tree with the Token.ancestors attribute, and check dominance with Token.is_ancestor | Text | Dep | n_lefts | n_rights | ancestors |
|---|
| Credit | | | | holders, submit | | and | | | | holders, submit | | mortgage | | | | account, Credit, holders, submit | | account | | | | Credit, holders, submit | | holders | | | | submit |
Finally, the .left_edge and .right_edge attributes can be especially useful, because they give you the first and last token of the subtree. This is the easiest way to create a Span object for a syntactic phrase. Note that .right_edge gives a token within the subtree – so if you use it as the end-point of a range, don’t forget to +1 ! | Text | POS | Dep | Head text |
|---|
| Credit and mortgage account holders | | | submit | | must | | | submit | | submit | | | submit | | their | | | requests | | requests | | | submit |
The dependency parse can be a useful tool for information extraction , especially when combined with other predictions like named entities . The following example extracts money and currency values, i.e. entities labeled as MONEY , and then uses the dependency parse to find the noun phrase they are referring to – for example "Net income" → "$9.4 million" . Visualizing dependenciesThe best way to understand spaCy’s dependency parser is interactively. To make this easier, spaCy comes with a visualization module. You can pass a Doc or a list of Doc objects to displaCy and run displacy.serve to run the web server, or displacy.render to generate the raw markup. If you want to know how to write rules that hook into some type of syntactic construction, just plug the sentence into the visualizer and see how spaCy annotates it. Disabling the parserIn the trained pipelines provided by spaCy, the parser is loaded and enabled by default as part of the standard processing pipeline . If you don’t need any of the syntactic information, you should disable the parser. Disabling the parser will make spaCy load and run much faster. If you want to load the parser, but need to disable it for specific documents, you can also control its use on the nlp object. For more details, see the usage guide on disabling pipeline components . Named Entity RecognitionspaCy features an extremely fast statistical entity recognition system, that assigns labels to contiguous spans of tokens. The default trained pipelines can identify a variety of named and numeric entities, including companies, locations, organizations and products. You can add arbitrary classes to the entity recognition system, and update the model with new examples. Named Entity Recognition 101A named entity is a “real-world object” that’s assigned a name – for example, a person, a country, a product or a book title. spaCy can recognize various types of named entities in a document, by asking the model for a prediction . Because models are statistical and strongly depend on the examples they were trained on, this doesn’t always work perfectly and might need some tuning later, depending on your use case. Named entities are available as the ents property of a Doc : | Text | Start | End | Label | Description |
|---|
| Apple | 0 | 5 | | Companies, agencies, institutions. | | U.K. | 27 | 31 | | Geopolitical entity, i.e. countries, cities, states. | | $1 billion | 44 | 54 | | Monetary values, including unit. |
Using spaCy’s built-in displaCy visualizer , here’s what our example sentence and its named entities look like: Accessing entity annotations and labelsThe standard way to access entity annotations is the doc.ents property, which produces a sequence of Span objects. The entity type is accessible either as a hash value or as a string, using the attributes ent.label and ent.label_ . The Span object acts as a sequence of tokens, so you can iterate over the entity or index into it. You can also get the text form of the whole entity, as though it were a single token. You can also access token entity annotations using the token.ent_iob and token.ent_type attributes. token.ent_iob indicates whether an entity starts, continues or ends on the tag. If no entity type is set on a token, it will return an empty string. | Text | ent_iob | ent_iob_ | ent_type_ | Description |
|---|
| San | | | | beginning of an entity | | Francisco | | | | inside an entity | | considers | | | | outside an entity | | banning | | | | outside an entity | | sidewalk | | | | outside an entity | | delivery | | | | outside an entity | | robots | | | | outside an entity |
Setting entity annotationsTo ensure that the sequence of token annotations remains consistent, you have to set entity annotations at the document level . However, you can’t write directly to the token.ent_iob or token.ent_type attributes, so the easiest way to set entities is to use the doc.set_ents function and create the new entity as a Span . Keep in mind that Span is initialized with the start and end token indices, not the character offsets. To create a span from character offsets, use Doc.char_span : Setting entity annotations from arrayYou can also assign entity annotations using the doc.from_array method. To do this, you should include both the ENT_TYPE and the ENT_IOB attributes in the array you’re importing from. Setting entity annotations in CythonFinally, you can always write to the underlying struct if you compile a Cython function. This is easy to do, and allows you to write efficient native code. Obviously, if you write directly to the array of TokenC* structs, you’ll have responsibility for ensuring that the data is left in a consistent state. Built-in entity typesVisualizing named entities. The displaCy ENT visualizer lets you explore an entity recognition model’s behavior interactively. If you’re training a model, it’s very useful to run the visualization yourself. To help you do that, spaCy comes with a visualization module. You can pass a Doc or a list of Doc objects to displaCy and run displacy.serve to run the web server, or displacy.render to generate the raw markup. For more details and examples, see the usage guide on visualizing spaCy . Named Entity exampleTo ground the named entities into the “real world”, spaCy provides functionality to perform entity linking, which resolves a textual entity to a unique identifier from a knowledge base (KB). You can create your own KnowledgeBase and train a new EntityLinker using that custom knowledge base. As an example on how to define a KnowledgeBase and train an entity linker model, see this tutorial using spaCy projects . Accessing entity identifiers Needs modelThe annotated KB identifier is accessible as either a hash value or as a string, using the attributes ent.kb_id and ent.kb_id_ of a Span object, or the ent_kb_id and ent_kb_id_ attributes of a Token object. Tokenization is the task of splitting a text into meaningful segments, called tokens . The input to the tokenizer is a unicode text, and the output is a Doc object. To construct a Doc object, you need a Vocab instance, a sequence of word strings, and optionally a sequence of spaces booleans, which allow you to maintain alignment of the tokens into the original string. During processing, spaCy first tokenizes the text, i.e. segments it into words, punctuation and so on. This is done by applying rules specific to each language. For example, punctuation at the end of a sentence should be split off – whereas “U.K.” should remain one token. Each Doc consists of individual tokens, and we can iterate over them: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| Apple | is | looking | at | buying | U.K. | startup | for | $ | 1 | billion |
First, the raw text is split on whitespace characters, similar to text.split(' ') . Then, the tokenizer processes the text from left to right. On each substring, it performs two checks: Does the substring match a tokenizer exception rule? For example, “don’t” does not contain whitespace, but should be split into two tokens, “do” and “n’t”, while “U.K.” should always remain one token. Can a prefix, suffix or infix be split off? For example punctuation like commas, periods, hyphens or quotes. If there’s a match, the rule is applied and the tokenizer continues its loop, starting with the newly split substrings. This way, spaCy can split complex, nested tokens like combinations of abbreviations and multiple punctuation marks. While punctuation rules are usually pretty general, tokenizer exceptions strongly depend on the specifics of the individual language. This is why each available language has its own subclass, like English or German , that loads in lists of hard-coded data and exception rules. Algorithm details: How spaCy's tokenizer works ¶spaCy introduces a novel tokenization algorithm that gives a better balance between performance, ease of definition and ease of alignment into the original string. After consuming a prefix or suffix, we consult the special cases again. We want the special cases to handle things like “don’t” in English, and we want the same rule to work for “(don’t)!“. We do this by splitting off the open bracket, then the exclamation, then the closed bracket, and finally matching the special case. Here’s an implementation of the algorithm in Python optimized for readability rather than performance: The algorithm can be summarized as follows: - Iterate over space-separated substrings.
- Check whether we have an explicitly defined special case for this substring. If we do, use it.
- Look for a token match. If there is a match, stop processing and keep this token.
- Otherwise, try to consume one prefix. If we consumed a prefix, go back to #3, so that the token match and special cases always get priority.
- If we didn’t consume a prefix, try to consume a suffix and then go back to #3.
- If we can’t consume a prefix or a suffix, look for a URL match.
- If there’s no URL match, then look for a special case.
- Look for “infixes” – stuff like hyphens etc. and split the substring into tokens on all infixes.
- Once we can’t consume any more of the string, handle it as a single token.
- Make a final pass over the text to check for special cases that include spaces or that were missed due to the incremental processing of affixes.
Global and language-specific tokenizer data is supplied via the language data in spacy/lang . The tokenizer exceptions define special cases like “don’t” in English, which needs to be split into two tokens: {ORTH: "do"} and {ORTH: "n't", NORM: "not"} . The prefixes, suffixes and infixes mostly define punctuation rules – for example, when to split off periods (at the end of a sentence), and when to leave tokens containing periods intact (abbreviations like “U.S.”). Should I change the language data or add custom tokenizer rules? ¶Tokenization rules that are specific to one language, but can be generalized across that language , should ideally live in the language data in spacy/lang – we always appreciate pull requests! Anything that’s specific to a domain or text type – like financial trading abbreviations or Bavarian youth slang – should be added as a special case rule to your tokenizer instance. If you’re dealing with a lot of customizations, it might make sense to create an entirely custom subclass. Adding special case tokenization rulesMost domains have at least some idiosyncrasies that require custom tokenization rules. This could be very certain expressions, or abbreviations only used in this specific field. Here’s how to add a special case rule to an existing Tokenizer instance: The special case doesn’t have to match an entire whitespace-delimited substring. The tokenizer will incrementally split off punctuation, and keep looking up the remaining substring. The special case rules also have precedence over the punctuation splitting. Debugging the tokenizerA working implementation of the pseudo-code above is available for debugging as nlp.tokenizer.explain(text) . It returns a list of tuples showing which tokenizer rule or pattern was matched for each token. The tokens produced are identical to nlp.tokenizer() except for whitespace tokens: Customizing spaCy’s Tokenizer classLet’s imagine you wanted to create a tokenizer for a new language or specific domain. There are six things you may need to define: - A dictionary of special cases . This handles things like contractions, units of measurement, emoticons, certain abbreviations, etc.
- A function prefix_search , to handle preceding punctuation , such as open quotes, open brackets, etc.
- A function suffix_search , to handle succeeding punctuation , such as commas, periods, close quotes, etc.
- A function infix_finditer , to handle non-whitespace separators, such as hyphens etc.
- An optional boolean function token_match matching strings that should never be split, overriding the infix rules. Useful for things like numbers.
- An optional boolean function url_match , which is similar to token_match except that prefixes and suffixes are removed before applying the match.
You shouldn’t usually need to create a Tokenizer subclass. Standard usage is to use re.compile() to build a regular expression object, and pass its .search() and .finditer() methods: If you need to subclass the tokenizer instead, the relevant methods to specialize are find_prefix , find_suffix and find_infix . Modifying existing rule setsIn many situations, you don’t necessarily need entirely custom rules. Sometimes you just want to add another character to the prefixes, suffixes or infixes. The default prefix, suffix and infix rules are available via the nlp object’s Defaults and the Tokenizer attributes such as Tokenizer.suffix_search are writable, so you can overwrite them with compiled regular expression objects using modified default rules. spaCy ships with utility functions to help you compile the regular expressions – for example, compile_suffix_regex : Similarly, you can remove a character from the default suffixes: The Tokenizer.suffix_search attribute should be a function which takes a unicode string and returns a regex match object or None . Usually we use the .search attribute of a compiled regex object, but you can use some other function that behaves the same way. The prefix, infix and suffix rule sets include not only individual characters but also detailed regular expressions that take the surrounding context into account. For example, there is a regular expression that treats a hyphen between letters as an infix. If you do not want the tokenizer to split on hyphens between letters, you can modify the existing infix definition from lang/punctuation.py : For an overview of the default regular expressions, see lang/punctuation.py and language-specific definitions such as lang/de/punctuation.py for German. Hooking a custom tokenizer into the pipelineThe tokenizer is the first component of the processing pipeline and the only one that can’t be replaced by writing to nlp.pipeline . This is because it has a different signature from all the other components: it takes a text and returns a Doc , whereas all other components expect to already receive a tokenized Doc . To overwrite the existing tokenizer, you need to replace nlp.tokenizer with a custom function that takes a text and returns a Doc . | Argument | Type | Description |
|---|
| | | The raw text to tokenize. | | | | The tokenized document. |
Example 1: Basic whitespace tokenizerHere’s an example of the most basic whitespace tokenizer. It takes the shared vocab, so it can construct Doc objects. When it’s called on a text, it returns a Doc object consisting of the text split on single space characters. We can then overwrite the nlp.tokenizer attribute with an instance of our custom tokenizer. Example 2: Third-party tokenizers (BERT word pieces)You can use the same approach to plug in any other third-party tokenizers. Your custom callable just needs to return a Doc object with the tokens produced by your tokenizer. In this example, the wrapper uses the BERT word piece tokenizer , provided by the tokenizers library. The tokens available in the Doc object returned by spaCy now match the exact word pieces produced by the tokenizer. Custom BERT word piece tokenizerTraining with custom tokenization v 3.0. spaCy’s training config describes the settings, hyperparameters, pipeline and tokenizer used for constructing and training the pipeline. The [nlp.tokenizer] block refers to a registered function that takes the nlp object and returns a tokenizer. Here, we’re registering a function called whitespace_tokenizer in the @tokenizers registry . To make sure spaCy knows how to construct your tokenizer during training, you can pass in your Python file by setting --code functions.py when you run spacy train . functions.pyRegistered functions can also take arguments that are then passed in from the config. This allows you to quickly change and keep track of different settings. Here, the registered function called bert_word_piece_tokenizer takes two arguments: the path to a vocabulary file and whether to lowercase the text. The Python type hints str and bool ensure that the received values have the correct type. To avoid hard-coding local paths into your config file, you can also set the vocab path on the CLI by using the --nlp.tokenizer.vocab_file override when you run spacy train . For more details on using registered functions, see the docs in training with custom code . Using pre-tokenized textspaCy generally assumes by default that your data is raw text . However, sometimes your data is partially annotated, e.g. with pre-existing tokenization, part-of-speech tags, etc. The most common situation is that you have pre-defined tokenization . If you have a list of strings, you can create a Doc object directly. Optionally, you can also specify a list of boolean values, indicating whether each word is followed by a space. If provided, the spaces list must be the same length as the words list. The spaces list affects the doc.text , span.text , token.idx , span.start_char and span.end_char attributes. If you don’t provide a spaces sequence, spaCy will assume that all words are followed by a space. Once you have a Doc object, you can write to its attributes to set the part-of-speech tags, syntactic dependencies, named entities and other attributes. Aligning tokenizationspaCy’s tokenization is non-destructive and uses language-specific rules optimized for compatibility with treebank annotations. Other tools and resources can sometimes tokenize things differently – for example, "I'm" → ["I", "'", "m"] instead of ["I", "'m"] . In situations like that, you often want to align the tokenization so that you can merge annotations from different sources together, or take vectors predicted by a pretrained BERT model and apply them to spaCy tokens. spaCy’s Alignment object allows the one-to-one mappings of token indices in both directions as well as taking into account indices where multiple tokens align to one single token. Here are some insights from the alignment information generated in the example above: - The one-to-one mappings for the first four tokens are identical, which means they map to each other. This makes sense because they’re also identical in the input: "i" , "listened" , "to" and "obama" .
- The value of x2y.data[6] is 5 , which means that other_tokens[6] ( "podcasts" ) aligns to spacy_tokens[5] (also "podcasts" ).
- x2y.data[4] and x2y.data[5] are both 4 , which means that both tokens 4 and 5 of other_tokens ( "'" and "s" ) align to token 4 of spacy_tokens ( "'s" ).
Merging and splittingThe Doc.retokenize context manager lets you merge and split tokens. Modifications to the tokenization are stored and performed all at once when the context manager exits. To merge several tokens into one single token, pass a Span to retokenizer.merge . An optional dictionary of attrs lets you set attributes that will be assigned to the merged token – for example, the lemma, part-of-speech tag or entity type. By default, the merged token will receive the same attributes as the merged span’s root. If an attribute in the attrs is a context-dependent token attribute, it will be applied to the underlying Token . For example LEMMA , POS or DEP only apply to a word in context, so they’re token attributes. If an attribute is a context-independent lexical attribute, it will be applied to the underlying Lexeme , the entry in the vocabulary. For example, LOWER or IS_STOP apply to all words of the same spelling, regardless of the context. Splitting tokensThe retokenizer.split method allows splitting one token into two or more tokens. This can be useful for cases where tokenization rules alone aren’t sufficient. For example, you might want to split “its” into the tokens “it” and “is” – but not the possessive pronoun “its”. You can write rule-based logic that can find only the correct “its” to split, but by that time, the Doc will already be tokenized. This process of splitting a token requires more settings, because you need to specify the text of the individual tokens, optional per-token attributes and how the tokens should be attached to the existing syntax tree. This can be done by supplying a list of heads – either the token to attach the newly split token to, or a (token, subtoken) tuple if the newly split token should be attached to another subtoken. In this case, “New” should be attached to “York” (the second split subtoken) and “York” should be attached to “in”. Specifying the heads as a list of token or (token, subtoken) tuples allows attaching split subtokens to other subtokens, without having to keep track of the token indices after splitting. | Token | Head | Description |
|---|
| | | Attach this token to the second subtoken (index ) that will be split into, i.e. “York”. | | | | Attach this token to in the original , i.e. “in”. |
If you don’t care about the heads (for example, if you’re only running the tokenizer and not the parser), you can attach each subtoken to itself: Overwriting custom extension attributesIf you’ve registered custom extension attributes , you can overwrite them during tokenization by providing a dictionary of attribute names mapped to new values as the "_" key in the attrs . For merging, you need to provide one dictionary of attributes for the resulting merged token. For splitting, you need to provide a list of dictionaries with custom attributes, one per split subtoken. A Doc object’s sentences are available via the Doc.sents property. To view a Doc ’s sentences, you can iterate over the Doc.sents , a generator that yields Span objects. You can check whether a Doc has sentence boundaries by calling Doc.has_annotation with the attribute name "SENT_START" . spaCy provides four alternatives for sentence segmentation: - Dependency parser : the statistical DependencyParser provides the most accurate sentence boundaries based on full dependency parses.
- Statistical sentence segmenter : the statistical SentenceRecognizer is a simpler and faster alternative to the parser that only sets sentence boundaries.
- Rule-based pipeline component : the rule-based Sentencizer sets sentence boundaries using a customizable list of sentence-final punctuation.
- Custom function : your own custom function added to the processing pipeline can set sentence boundaries by writing to Token.is_sent_start .
Default: Using the dependency parse Needs modelUnlike other libraries, spaCy uses the dependency parse to determine sentence boundaries. This is usually the most accurate approach, but it requires a trained pipeline that provides accurate predictions. If your texts are closer to general-purpose news or web text, this should work well out-of-the-box with spaCy’s provided trained pipelines. For social media or conversational text that doesn’t follow the same rules, your application may benefit from a custom trained or rule-based component. spaCy’s dependency parser respects already set boundaries, so you can preprocess your Doc using custom components before it’s parsed. Depending on your text, this may also improve parse accuracy, since the parser is constrained to predict parses consistent with the sentence boundaries. Statistical sentence segmenter v 3.0 Needs modelThe SentenceRecognizer is a simple statistical component that only provides sentence boundaries. Along with being faster and smaller than the parser, its primary advantage is that it’s easier to train because it only requires annotated sentence boundaries rather than full dependency parses. spaCy’s trained pipelines include both a parser and a trained sentence segmenter, which is disabled by default. If you only need sentence boundaries and no parser, you can use the exclude or disable argument on spacy.load to load the pipeline without the parser and then enable the sentence recognizer explicitly with nlp.enable_pipe . Rule-based pipeline componentThe Sentencizer component is a pipeline component that splits sentences on punctuation like . , ! or ? . You can plug it into your pipeline if you only need sentence boundaries without dependency parses. Custom rule-based strategyIf you want to implement your own strategy that differs from the default rule-based approach of splitting on sentences, you can also create a custom pipeline component that takes a Doc object and sets the Token.is_sent_start attribute on each individual token. If set to False , the token is explicitly marked as not the start of a sentence. If set to None (default), it’s treated as a missing value and can still be overwritten by the parser. Here’s an example of a component that implements a pre-processing rule for splitting on "..." tokens. The component is added before the parser, which is then used to further segment the text. That’s possible, because is_sent_start is only set to True for some of the tokens – all others still specify None for unset sentence boundaries. This approach can be useful if you want to implement additional rules specific to your data, while still being able to take advantage of dependency-based sentence segmentation. Mappings & Exceptions v 3.0The AttributeRuler manages rule-based mappings and exceptions for all token-level attributes. As the number of pipeline components has grown from spaCy v2 to v3, handling rules and exceptions in each component individually has become impractical, so the AttributeRuler provides a single component with a unified pattern format for all token attribute mappings and exceptions. The AttributeRuler uses Matcher patterns to identify tokens and then assigns them the provided attributes. If needed, the Matcher patterns can include context around the target token. For example, the attribute ruler can: - provide exceptions for any token attributes
- map fine-grained tags to coarse-grained tags for languages without statistical morphologizers (replacing the v2.x tag_map in the language data )
- map token surface form + fine-grained tags to morphological features (replacing the v2.x morph_rules in the language data )
- specify the tags for space tokens (replacing hard-coded behavior in the tagger)
The following example shows how the tag and POS NNP / PROPN can be specified for the phrase "The Who" , overriding the tags provided by the statistical tagger and the POS tag map. Word vectors and semantic similaritySimilarity is determined by comparing word vectors or “word embeddings”, multi-dimensional meaning representations of a word. Word vectors can be generated using an algorithm like word2vec and usually look like this: banana.vectorPipeline packages that come with built-in word vectors make them available as the Token.vector attribute. Doc.vector and Span.vector will default to an average of their token vectors. You can also check if a token has a vector assigned, and get the L2 norm, which can be used to normalize vectors. The words “dog”, “cat” and “banana” are all pretty common in English, so they’re part of the pipeline’s vocabulary, and come with a vector. The word “afskfsd” on the other hand is a lot less common and out-of-vocabulary – so its vector representation consists of 300 dimensions of 0 , which means it’s practically nonexistent. If your application will benefit from a large vocabulary with more vectors, you should consider using one of the larger pipeline packages or loading in a full vector package, for example, en_core_web_lg , which includes 685k unique vectors . spaCy is able to compare two objects, and make a prediction of how similar they are . Predicting similarity is useful for building recommendation systems or flagging duplicates. For example, you can suggest a user content that’s similar to what they’re currently looking at, or label a support ticket as a duplicate if it’s very similar to an already existing one. Each Doc , Span , Token and Lexeme comes with a .similarity method that lets you compare it with another object, and determine the similarity. Of course similarity is always subjective – whether two words, spans or documents are similar really depends on how you’re looking at it. spaCy’s similarity implementation usually assumes a pretty general-purpose definition of similarity. What to expect from similarity resultsComputing similarity scores can be helpful in many situations, but it’s also important to maintain realistic expectations about what information it can provide. Words can be related to each other in many ways, so a single “similarity” score will always be a mix of different signals , and vectors trained on different data can produce very different results that may not be useful for your purpose. Here are some important considerations to keep in mind: - There’s no objective definition of similarity. Whether “I like burgers” and “I like pasta” is similar depends on your application . Both talk about food preferences, which makes them very similar – but if you’re analyzing mentions of food, those sentences are pretty dissimilar, because they talk about very different foods.
- The similarity of Doc and Span objects defaults to the average of the token vectors. This means that the vector for “fast food” is the average of the vectors for “fast” and “food”, which isn’t necessarily representative of the phrase “fast food”.
- Vector averaging means that the vector of multiple tokens is insensitive to the order of the words. Two documents expressing the same meaning with dissimilar wording will return a lower similarity score than two documents that happen to contain the same words while expressing different meanings.
Adding word vectorsCustom word vectors can be trained using a number of open-source libraries, such as Gensim , FastText , or Tomas Mikolov’s original Word2vec implementation . Most word vector libraries output an easy-to-read text-based format, where each line consists of the word followed by its vector. For everyday use, we want to convert the vectors into a binary format that loads faster and takes up less space on disk. The easiest way to do this is the init vectors command-line utility. This will output a blank spaCy pipeline in the directory /tmp/la_vectors_wiki_lg , giving you access to some nice Latin vectors. You can then pass the directory path to spacy.load or use it in the [initialize] of your config when you train a model. How to optimize vector coverage ¶To help you strike a good balance between coverage and memory usage, spaCy’s Vectors class lets you map multiple keys to the same row of the table. If you’re using the spacy init vectors command to create a vocabulary, pruning the vectors will be taken care of automatically if you set the --prune flag. You can also do it manually in the following steps: - Start with a word vectors package that covers a huge vocabulary. For instance, the en_core_web_lg package provides 300-dimensional GloVe vectors for 685k terms of English.
- If your vocabulary has values set for the Lexeme.prob attribute, the lexemes will be sorted by descending probability to determine which vectors to prune. Otherwise, lexemes will be sorted by their order in the Vocab .
- Call Vocab.prune_vectors with the number of vectors you want to keep.
Vocab.prune_vectors reduces the current vector table to a given number of unique entries, and returns a dictionary containing the removed words, mapped to (string, score) tuples, where string is the entry the removed word was mapped to and score the similarity score between the two words. Removed wordsIn the example above, the vector for “Shore” was removed and remapped to the vector of “coast”, which is deemed about 73% similar. “Leaving” was remapped to the vector of “leaving”, which is identical. If you’re using the init vectors command, you can set the --prune option to easily reduce the size of the vectors as you add them to a spaCy pipeline: This will create a blank spaCy pipeline with vectors for the first 10,000 words in the vectors. All other words in the vectors are mapped to the closest vector among those retained. Adding vectors individuallyThe vector attribute is a read-only numpy or cupy array (depending on whether you’ve configured spaCy to use GPU memory), with dtype float32 . The array is read-only so that spaCy can avoid unnecessary copy operations where possible. You can modify the vectors via the Vocab or Vectors table. Using the Vocab.set_vector method is often the easiest approach if you have vectors in an arbitrary format, as you can read in the vectors with your own logic, and just set them with a simple loop. This method is likely to be slower than approaches that work with the whole vectors table at once, but it’s a great approach for once-off conversions before you save out your nlp object to disk. Adding vectorsEvery language is different – and usually full of exceptions and special cases , especially amongst the most common words. Some of these exceptions are shared across languages, while others are entirely specific – usually so specific that they need to be hard-coded. The lang module contains all language-specific data, organized in simple Python files. This makes the data easy to update and extend. The shared language data in the directory root includes rules that can be generalized across languages – for example, rules for basic punctuation, emoji, emoticons and single-letter abbreviations. The individual language data in a submodule contains rules that are only relevant to a particular language. It also takes care of putting together all components and creating the Language subclass – for example, English or German . The values are defined in the Language.Defaults . | Name | Description |
|---|
| List of most common words of a language that are often useful to filter out, for example “and” or “I”. Matching tokens will return for . |
| Special-case rules for the tokenizer, for example, contractions like “can’t” and abbreviations with punctuation, like “U.K.”. |
| Regular expressions for splitting tokens, e.g. on punctuation or special characters like emoji. Includes rules for prefixes, suffixes and infixes. |
| Character classes to be used in regular expressions, for example, Latin characters, quotes, hyphens or icons. |
| Custom functions for setting lexical attributes on tokens, e.g. , which includes language-specific words like “ten” or “hundred”. |
| Functions that compute views of a object based on its syntax. At the moment, only used for . |
| Custom lemmatizer implementation and lemmatization tables. |
Creating a custom language subclassIf you want to customize multiple components of the language data or add support for a custom language or domain-specific “dialect”, you can also implement your own language subclass. The subclass should define two attributes: the lang (unique language code) and the Defaults defining the language data. For an overview of the available attributes that can be overwritten, see the Language.Defaults documentation. The @spacy.registry.languages decorator lets you register a custom language class and assign it a string name. This means that you can call spacy.blank with your custom language name, and even train pipelines with it and refer to it in your training config . Registering a custom language - Natural Language Processing Tutorial
- NLP - Introduction
- NLP - Linguistic Resources
- NLP - Word Level Analysis
- NLP - Syntactic Analysis
- NLP - Semantic Analysis
- NLP - Word Sense Disambiguation
- NLP - Discourse Processing
- NLP - Part of Speech (PoS) Tagging
- NLP - Inception
- NLP - Information Retrieval
- NLP - Applications of NLP
- NLP - Python
- Natural Language Processing Resources
- NLP - Quick Guide
- NLP - Useful Resources
- NLP - Discussion
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
Part of Speech (PoS) TaggingTagging is a kind of classification that may be defined as the automatic assignment of description to the tokens. Here the descriptor is called tag, which may represent one of the part-of-speech, semantic information and so on. Now, if we talk about Part-of-Speech (PoS) tagging, then it may be defined as the process of assigning one of the parts of speech to the given word. It is generally called POS tagging. In simple words, we can say that POS tagging is a task of labelling each word in a sentence with its appropriate part of speech. We already know that parts of speech include nouns, verb, adverbs, adjectives, pronouns, conjunction and their sub-categories. Most of the POS tagging falls under Rule Base POS tagging, Stochastic POS tagging and Transformation based tagging. Rule-based POS TaggingOne of the oldest techniques of tagging is rule-based POS tagging. Rule-based taggers use dictionary or lexicon for getting possible tags for tagging each word. If the word has more than one possible tag, then rule-based taggers use hand-written rules to identify the correct tag. Disambiguation can also be performed in rule-based tagging by analyzing the linguistic features of a word along with its preceding as well as following words. For example, suppose if the preceding word of a word is article then word must be a noun. As the name suggests, all such kind of information in rule-based POS tagging is coded in the form of rules. These rules may be either − Context-pattern rules Or, as Regular expression compiled into finite-state automata, intersected with lexically ambiguous sentence representation. We can also understand Rule-based POS tagging by its two-stage architecture − First stage − In the first stage, it uses a dictionary to assign each word a list of potential parts-of-speech. Second stage − In the second stage, it uses large lists of hand-written disambiguation rules to sort down the list to a single part-of-speech for each word. Properties of Rule-Based POS TaggingRule-based POS taggers possess the following properties − These taggers are knowledge-driven taggers. The rules in Rule-based POS tagging are built manually. The information is coded in the form of rules. We have some limited number of rules approximately around 1000. Smoothing and language modeling is defined explicitly in rule-based taggers. Stochastic POS TaggingAnother technique of tagging is Stochastic POS Tagging. Now, the question that arises here is which model can be stochastic. The model that includes frequency or probability (statistics) can be called stochastic. Any number of different approaches to the problem of part-of-speech tagging can be referred to as stochastic tagger. The simplest stochastic tagger applies the following approaches for POS tagging − Word Frequency ApproachIn this approach, the stochastic taggers disambiguate the words based on the probability that a word occurs with a particular tag. We can also say that the tag encountered most frequently with the word in the training set is the one assigned to an ambiguous instance of that word. The main issue with this approach is that it may yield inadmissible sequence of tags. Tag Sequence ProbabilitiesIt is another approach of stochastic tagging, where the tagger calculates the probability of a given sequence of tags occurring. It is also called n-gram approach. It is called so because the best tag for a given word is determined by the probability at which it occurs with the n previous tags. Properties of Stochastic POST TaggingStochastic POS taggers possess the following properties − This POS tagging is based on the probability of tag occurring. It requires training corpus There would be no probability for the words that do not exist in the corpus. It uses different testing corpus (other than training corpus). It is the simplest POS tagging because it chooses most frequent tags associated with a word in training corpus. Transformation-based TaggingTransformation based tagging is also called Brill tagging. It is an instance of the transformation-based learning (TBL), which is a rule-based algorithm for automatic tagging of POS to the given text. TBL, allows us to have linguistic knowledge in a readable form, transforms one state to another state by using transformation rules. It draws the inspiration from both the previous explained taggers − rule-based and stochastic. If we see similarity between rule-based and transformation tagger, then like rule-based, it is also based on the rules that specify what tags need to be assigned to what words. On the other hand, if we see similarity between stochastic and transformation tagger then like stochastic, it is machine learning technique in which rules are automatically induced from data. Working of Transformation Based Learning(TBL)In order to understand the working and concept of transformation-based taggers, we need to understand the working of transformation-based learning. Consider the following steps to understand the working of TBL − Start with the solution − The TBL usually starts with some solution to the problem and works in cycles. Most beneficial transformation chosen − In each cycle, TBL will choose the most beneficial transformation. Apply to the problem − The transformation chosen in the last step will be applied to the problem. The algorithm will stop when the selected transformation in step 2 will not add either more value or there are no more transformations to be selected. Such kind of learning is best suited in classification tasks. Advantages of Transformation-based Learning (TBL)The advantages of TBL are as follows − We learn small set of simple rules and these rules are enough for tagging. Development as well as debugging is very easy in TBL because the learned rules are easy to understand. Complexity in tagging is reduced because in TBL there is interlacing of machinelearned and human-generated rules. Transformation-based tagger is much faster than Markov-model tagger. Disadvantages of Transformation-based Learning (TBL)The disadvantages of TBL are as follows − Transformation-based learning (TBL) does not provide tag probabilities. In TBL, the training time is very long especially on large corpora. Hidden Markov Model (HMM) POS TaggingBefore digging deep into HMM POS tagging, we must understand the concept of Hidden Markov Model (HMM). Hidden Markov ModelAn HMM model may be defined as the doubly-embedded stochastic model, where the underlying stochastic process is hidden. This hidden stochastic process can only be observed through another set of stochastic processes that produces the sequence of observations. For example, a sequence of hidden coin tossing experiments is done and we see only the observation sequence consisting of heads and tails. The actual details of the process - how many coins used, the order in which they are selected - are hidden from us. By observing this sequence of heads and tails, we can build several HMMs to explain the sequence. Following is one form of Hidden Markov Model for this problem −  We assumed that there are two states in the HMM and each of the state corresponds to the selection of different biased coin. Following matrix gives the state transition probabilities − $$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$ a ij = probability of transition from one state to another from i to j. a 11 + a 12 = 1 and a 21 + a 22 =1 P 1 = probability of heads of the first coin i.e. the bias of the first coin. P 2 = probability of heads of the second coin i.e. the bias of the second coin. We can also create an HMM model assuming that there are 3 coins or more. This way, we can characterize HMM by the following elements − N, the number of states in the model (in the above example N =2, only two states). M, the number of distinct observations that can appear with each state in the above example M = 2, i.e., H or T). A, the state transition probability distribution − the matrix A in the above example. P, the probability distribution of the observable symbols in each state (in our example P1 and P2). I, the initial state distribution. Use of HMM for POS TaggingThe POS tagging process is the process of finding the sequence of tags which is most likely to have generated a given word sequence. We can model this POS process by using a Hidden Markov Model (HMM), where tags are the hidden states that produced the observable output, i.e., the words . Mathematically, in POS tagging, we are always interested in finding a tag sequence (C) which maximizes − C = C 1 , C 2 , C 3 ... C T W = W 1 , W 2 , W 3 , W T On the other side of coin, the fact is that we need a lot of statistical data to reasonably estimate such kind of sequences. However, to simplify the problem, we can apply some mathematical transformations along with some assumptions. The use of HMM to do a POS tagging is a special case of Bayesian interference. Hence, we will start by restating the problem using Bayes’ rule, which says that the above-mentioned conditional probability is equal to − (PROB (C 1 ,..., CT) * PROB (W 1 ,..., WT | C 1 ,..., CT)) / PROB (W 1 ,..., WT) We can eliminate the denominator in all these cases because we are interested in finding the sequence C which maximizes the above value. This will not affect our answer. Now, our problem reduces to finding the sequence C that maximizes − PROB (C 1 ,..., CT) * PROB (W 1 ,..., WT | C 1 ,..., CT) (1) Even after reducing the problem in the above expression, it would require large amount of data. We can make reasonable independence assumptions about the two probabilities in the above expression to overcome the problem. First AssumptionThe probability of a tag depends on the previous one (bigram model) or previous two (trigram model) or previous n tags (n-gram model) which, mathematically, can be explained as follows − PROB (C 1 ,..., C T ) = Π i=1..T PROB (C i |C i-n+1 …C i-1 ) (n-gram model) PROB (C 1 ,..., CT) = Π i=1..T PROB (C i |C i-1 ) (bigram model) The beginning of a sentence can be accounted for by assuming an initial probability for each tag. PROB (C 1 |C 0 ) = PROB initial (C 1 ) Second AssumptionThe second probability in equation (1) above can be approximated by assuming that a word appears in a category independent of the words in the preceding or succeeding categories which can be explained mathematically as follows − PROB (W 1 ,..., W T | C 1 ,..., C T ) = Π i=1..T PROB (W i |C i ) Now, on the basis of the above two assumptions, our goal reduces to finding a sequence C which maximizes Π i=1...T PROB(C i |C i-1 ) * PROB(W i |C i ) Now the question that arises here is has converting the problem to the above form really helped us. The answer is - yes, it has. If we have a large tagged corpus, then the two probabilities in the above formula can be calculated as − PROB (C i=VERB |C i-1=NOUN ) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2) PROB (W i |C i ) = (# of instances where W i appears in C i ) /(# of instances where C i appears) (3) Subscribe to the PwC NewsletterJoin the community, add a new evaluation result row, part-of-speech tagging. 215 papers with code • 15 benchmarks • 26 datasets Part-of-speech tagging (POS tagging) is the task of tagging a word in a text with its part of speech. A part of speech is a category of words with similar grammatical properties. Common English parts of speech are noun, verb, adjective, adverb, pronoun, preposition, conjunction, etc. | Vinken | , | 61 | years | old | | NNP | , | CD | NNS | JJ | Benchmarks Add a Result | Trend | Dataset | Best Model | --> Paper | Code | Compare | | | | SALE-BART encoder | --> | | | | | | BiLSTM-LAN | --> | | | | | | ACE | --> | | | | | | PretRand | --> | | | | | | ACE | --> | | | | | | ACE | --> | | | | | | Trankit | --> | | | | | | CamemBERT | --> | | | | | | CamemBERT | --> | | | | | | CamemBERT | --> | | | | | | CamemBERT | --> | | | | | | da_dacy_large_tft-0.0.0 | --> | | | | | | mGPT | --> | | | | | | Bi-LSTM-CRF + Flair Embeddings + CamemBERT (oscar−138gb−base) Embeddings | --> | | | | | | MyBert | --> | | |  Latest papersMulti-modal multi-granularity tokenizer for chu bamboo slip scripts.  This study presents a multi-modal multi-granularity tokenizer specifically designed for analyzing ancient Chinese scripts, focusing on the Chu bamboo slip (CBS) script used during the Spring and Autumn and Warring States period (771-256 BCE) in Ancient China. DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical DomainThis limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling TasksHowever, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. Multi-Task Learning for Front-End Text Processing in TTSfacebookresearch/llama-hd-dataset • 12 Jan 2024 We propose a multi-task learning (MTL) model for jointly performing three tasks that are commonly solved in a text-to-speech (TTS) front-end: text normalization (TN), part-of-speech (POS) tagging, and homograph disambiguation (HD). Def2Vec: Extensible Word Embeddings from Dictionary Definitionsvincenzo-scotti/def_2_vec • ICNLSP 2023 Def2Vec introduces a novel paradigm for word embeddings, leveraging dictionary definitions to learn semantic representations. PuoBERTa: Training and evaluation of a curated language model for Setswanadsfsi/puoberta • 13 Oct 2023 Natural language processing (NLP) has made significant progress for well-resourced languages such as English but lagged behind for low-resource languages like Setswana. The Uncertainty-based Retrieval Framework for Ancient Chinese CWS and POSAutomatic analysis for modern Chinese has greatly improved the accuracy of text mining in related fields, but the study of ancient Chinese is still relatively rare. RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spanswebspellchecker/unlp-2023-shared-task • 19 Sep 2023 The text editing tasks, including sentence fusion, sentence splitting and rephrasing, text simplification, and Grammatical Error Correction (GEC), share a common trait of dealing with highly similar input and output sequences. DiscoverPath: A Knowledge Refinement and Retrieval System for Interdisciplinarity on Biomedical Researchynchuang/discoverpath • 4 Sep 2023 The exponential growth in scholarly publications necessitates advanced tools for efficient article retrieval, especially in interdisciplinary fields where diverse terminologies are used to describe similar research. FonMTL: Towards Multitask Learning for the Fon LanguageMultitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. | 






IMAGES
VIDEO
COMMENTS
Statistical POS Tagging. Utilizing probabilistic models, statistical part-of-speech (POS) tagging is a computer linguistics technique that places grammatical categories on words inside a text. If rule-based tagging uses massive annotated corpora to train its algorithms, statistical tagging uses machine learning.
In corpus linguistics, part-of-speech tagging (POS tagging or PoS tagging or POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context — i.e., its relationship with adjacent and ...
Part-of-speech tagging is an important, early example of a sequence classification task in NLP: a classification decision at any one point in the sequence makes use of words and tags in the local context. A dictionary is used to map between arbitrary types of information, such as a string and a number: freq['cat'] = 12.
Part of Speech (POS) is a way to describe the grammatical function of a word. In Natural Language Processing (NLP), POS is an essential building block of language models and interpreting text. ... Let's start with some simple examples of POS tagging with three common Python libraries: NLTK, TextBlob, and Spacy. We'll do the absolute basics ...
Part-of-speech (POS) tagging is a process that assigns a part of speech (noun, verb, adjective, etc.) to each word in a given text.This technique is used to understand the role of words in a sentence and is a critical component of many natural language processing (NLP) applications. In this article, we will explore the basics of POS tagging, its importance, and the techniques and tools used ...
Let's take a very simple example of parts of speech tagging. import spacy. sp = spacy.load('en_core_web_sm') As usual, in the script above we import the core spaCy English model. Next, we need to create a spaCy document that we will be using to perform parts of speech tagging. sen = sp(u"I like to play football.
8.3 Part-of-Speech Tagging. part-of-speech tagging. ambiguousambiguity resolutionPart-of-speech tagging is the process of assigning a part-of-speech marker to each word in an input text.3 The input to a tagging algorithm is a sequence of (tokenized) words and a tagset, and the output is a s.
Part-of-speech tagging. In corpus linguistics, part-of-speech tagging (POS tagging or PoS tagging or POST), also called grammatical tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, [1] based on both its definition and its context. A simplified form of this is commonly taught to ...
Part-of-speech (POS) tagging is fundamental in natural language processing (NLP) and can be done in Python. It involves labelling words in a sentence with their corresponding POS tags. POS tags indicate the grammatical category of a word, such as noun, verb, adjective, adverb, etc. The goal of POS tagging is to determine a sentence's ...
need much larger tag sets for tagging to be useful, and will contain many more distinct word forms in corpora of the same size. They often have much lower accuracies. Also: POS tagging accuracy on English text from other domains can be significantly lower. 16
Back in elementary school, we have learned the differences between the various parts of speech tags such as nouns, verbs, adjectives, and adverbs. Associating each word in a sentence with a proper POS (part of speech) is known as POS tagging or POS annotation. POS tags are also known as word classes, morphological classes, or lexical tags.
A POS tag (part-of-speech tag) is a label showing the part of speech of each token (word) in a text corpus. POS tags are assigned automatically by a POS tagger. ... During the development of an automatic POS tagger, a small sample (at least 1 million words) of manually annotated training data is needed.
A. Part-of-Speech (POS) tagging is a preprocessing step in natural language processing (NLP) that involves assigning a grammatical category or part-of-speech label (such as noun, verb, adjective, etc.) to each word in a sentence. It serves several purposes as a preprocessing step: 1.
Part-of-speech tagging is a fundamental task in natural language processing that involves assigning a grammatical category to each word in a piece of text. In this article, we explore various aspects of part-of-speech tagging, including its applications, different approaches, and the impact of context and training data. We also discuss the potential uses of part-of-speech tagging for search ...
Overview. Part-of-speech (POS) tagging is an important Natural Language Processing (NLP) concept that categorizes words in the text corpus with a particular part of speech tag (e.g., Noun, Verb, Adjective, etc.) POS tagging could be the very first task in text processing for further downstream tasks in NLP, like speech recognition, parsing, machine translation, sentiment analysis, etc.
Coming on to the part of speech tagging problem, the states would be represented by the actual tags assigned to the words. The words would be our observations. ... As is the case with part of speech tagging. For example, consider the sentence. the dog barks and assuming that the set of possible tags are {D, N, V}, let us look at some of the ...
Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss. bplank/bilstm-aux • ACL 2016 Bidirectional long short-term memory (bi-LSTM) networks have recently proven successful for various NLP sequence modeling tasks, but little is known about their reliance to input representations, target languages, data set size, and label noise.
The part-of-speech tagger assigns each token a fine-grained part-of-speech tag. In the API, these tags are known as Token.tag. They express the part-of-speech (e.g. verb) and some amount of morphological information, ... for example, the lemma, part-of-speech tag or entity type. By default, the merged token will receive the same attributes as ...
Part of Speech (PoS) Tagging - Tagging is a kind of classification that may be defined as the automatic assignment of description to the tokens. Here the descriptor is called tag, which may represent one of the part-of-speech, semantic information and so on. ... For example, suppose if the preceding word of a word is article then word must be a ...
Part-of-speech tagging (POS tagging) is the task of tagging a word in a text with its part of speech. A part of speech is a category of words with similar grammatical properties. Common English parts of speech are noun, verb, adjective, adverb, pronoun, preposition, conjunction, etc.